一种用于斜齿轮设计中的数据挖掘方法与流程
本发明属于斜齿轮设计技术领域,特别涉及一种用于斜齿轮设计中的数据挖掘方法。
背景技术:
斜齿轮传动作为机械传动中一种重要的传动方式,它被广泛用于交通运输,机器制造,航空航天等各领域中,因此斜齿轮的设计质量对整个齿轮传动系统的性能起着至关重要的作用,传统的斜齿轮设计方法是一件较为繁琐且重复量大的工作。
数据挖掘(英语:Data mining),又译为资料探勘、数据采矿。它是数据库知识发现(英语:Knowledge-Discovery in Databases,简称:KDD)中的一个步骤。数据挖掘一般是指从大量的数据中通过算法搜索隐藏于其中信息的过程。数据挖掘通常与计算机科学有关,并通过统计、在线分析处理、情报检索、机器学习、专家系统(依靠过去的经验法则)和模式识别等诸多方法来实现上述目标。
利用数据挖掘技术,建立了斜齿轮实例库和规则库,缩短了产品的设计和研发周期,适应了现代产品设计快速发展的节奏,为新产品的研发提供了参考依据。
技术实现要素:
本发明要解决的技术问题为:是为了克服现有技术的上述缺陷,提出了一种用于斜齿轮设计中的数据挖掘方法,缩短了产品的设计和研发周期,适应了现代产品设计快速发展的节奏,为新产品的研发提供了参考依据。
本发明采用的技术方案为:一种用于斜齿轮设计中的数据挖掘方法,如图1所示,其特征在于实现步骤如下:
步骤一、根据机械工业标准和技术规范、斜齿轮设计规则和经验准则、斜齿轮设计专业知识,对斜齿轮设计知识进行分类,包括斜齿轮基本设计、机械特性和制造工艺等参数;
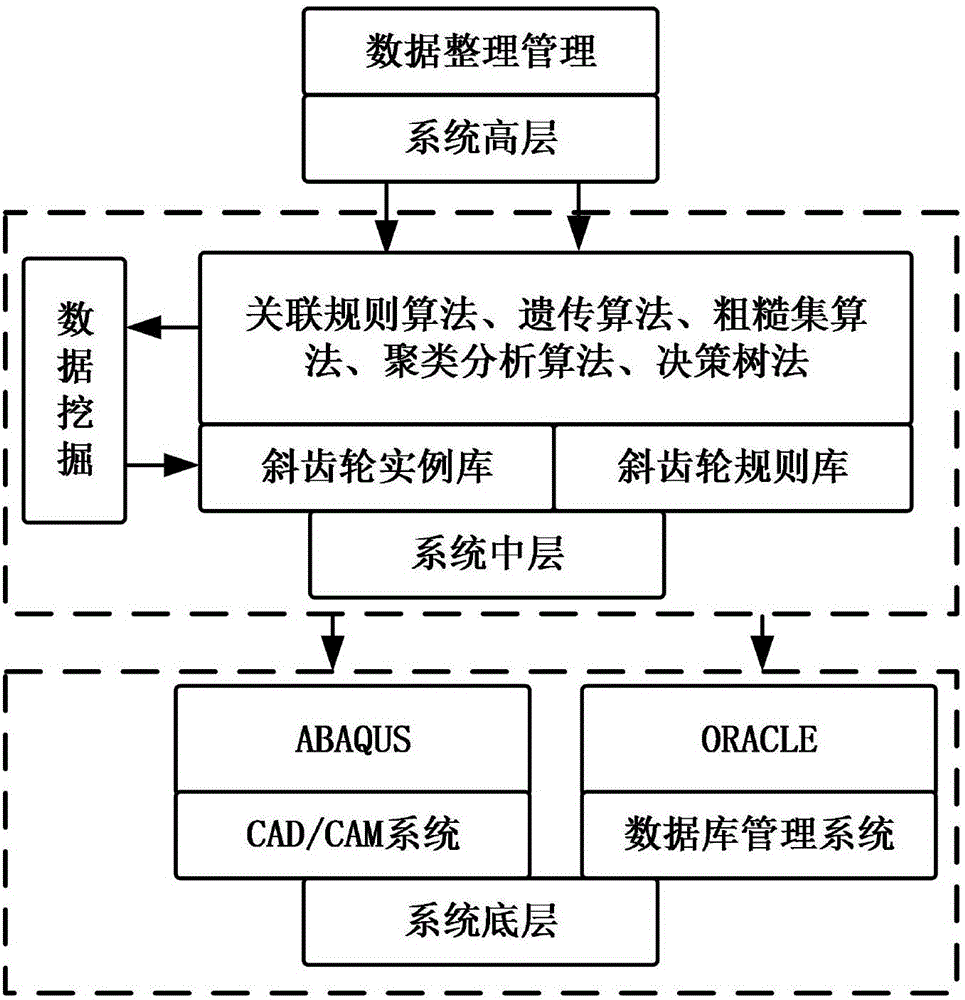
步骤二、搭建斜齿轮设计数据挖掘框架,如图2所示,系统底层为通用系统层,主要负责斜齿轮的参数化建模及有限元分析,提供数据的查询、存储和编辑功能;系统中层为CAD/CAM数据挖掘层,利用数据挖掘算法,基于斜齿轮实例推理算法,根据各实例间的相似度分析,设计者提取感兴趣的实例,并分析相关设计准则、方法,为新产品的设计提供设计依据,将新的设计方法及规则存入规则库;系统高层为设计工具层,主要是引导设计者管理设计知识,添加、编辑和删除等操作,引导用户快速完成设计任务,提高设计效率;
步骤三、建立斜齿轮实例库,如图3所示,实例的表达技术形式是产品信息模型的具体体现,依据分层递阶的产品信息模型,斜齿轮实例组成描述如下:
Case={ID,Code,Index,Matter,Model Topology,Assembly}
其中,ID为实例的唯一标识码,Code代表编码,Index为实例索引,产品实例内容(Matter)由各标准零件和自制零件的名称、所属类别、主要规则参数和存储路径组成,各零件的顺序表达了产品设计时的各零件的生成顺序,即设计过程Model Topology表达实例的几何拓扑信息,Assembly是产品实例的装配关联信息;
所述的斜齿轮实例库分为标准件实例库、齿廓修行实例库、齿向修形实例库和变形齿轮实例库;
步骤四、建立斜齿轮规则库,斜齿轮的规则主要包括斜齿轮的设计规则,分为规则序号、条件部分和结论部分;
步骤五、斜齿轮检索,如图4所示,实例索引基于CBR理论进行设计,针对实例信息的设计特征、产品特征和加工特征,根据特征信息,推出斜齿轮的索引词汇,见表1;
表1实例索引词汇
本发明与现有技术相比的优点在于:
(1)、本发明缩短了产品的设计和研发周期,适应了现代产品设计快速发展的节奏,为新产品的研发提供了参考依据;
(2)、本发明结合数据挖掘技术,使得设计更加高效精准,使得信息更加全面,避免了不必要的浪费。
附图说明
图1为本发明方法实现流程图;
图2为本发明中数据挖掘平台框图;
图3为本发明中斜齿轮分类;
图4为本发明中CBR检索流程图。
具体实施方式
为了清楚说明本方案的技术特点,下面通过一个具体的实施方式,并结合其附图对本方案进行阐述。
本发明一种用于斜齿轮设计中的数据挖掘方法,具体步骤如下:
步骤一、根据机械工业标准和技术规范、斜齿轮设计规则和经验准则、斜齿轮设计专业知识,对斜齿轮设计知识进行分类,包括斜齿轮基本设计、机械特性和制造工艺等参数;
步骤二、搭建斜齿轮设计数据挖掘框架,如图2所示,系统底层为通用系统层,主要负责斜齿轮的参数化建模及有限元分析,提供数据的查询、存储和编辑功能;系统中层为CAD/CAM数据挖掘层,利用数据挖掘算法,基于斜齿轮实例推理算法,根据各实例间的相似度分析,设计者提取感兴趣的实例,并分析相关设计准则、方法,为新产品的设计提供设计依据,将新的设计方法及规则存入规则库;系统高层为设计工具层,主要是引导设计者管理设计知识,添加、编辑和删除等操作,引导用户快速完成设计任务,提高设计效率;
步骤三、建立斜齿轮实例库,如图3所示,实例的表达技术形式是产品信息模型的具体体现,依据分层递阶的产品信息模型,斜齿轮实例组成描述如下:
Case={ID,Code,Index,Matter,Model Topology,Assembly}
其中,ID为实例的唯一标识码,Code代表编码,Index为实例索引,产品实例内容(Matter)由各标准零件和自制零件的名称、所属类别、主要规则参数和存储路径组成,各零件的顺序表达了产品设计时的各零件的生成顺序,即设计过程Model Topology表达实例的几何拓扑信息,Assembly是产品实例的装配关联信息;
斜齿轮齿廓修形实例库中的一个实例表达如下:
Case1={Helical Gear_001,HGPM001,HGPM,m=0.5,z=34,α=20°,h_a=1,c=0.25,β=30°,tip=0,root=0,NULL,Precision=8,Material=45,Path=D:./Helical Gear/Data Mining,Profile Modification,NULL}
所述的斜齿轮实例库分为标准件实例库、齿廓修行实例库、齿向修形实例库和变形齿轮实例库,见表1;
表1斜齿轮实例库部分列表
步骤四、建立斜齿轮规则库,斜齿轮的规则主要包括斜齿轮的设计规则,分为规则序号、条件部分和结论部分;
斜齿轮设计中会有许多规则,部分展示如以下:
(1)如果设计齿轮为修形齿轮,那么输出所有修形齿轮信息;
(2)如果设计螺旋角为30度的斜齿轮,那么输出所有螺旋角等于30度的斜齿轮信息;
(3)如果设计重载工况下的斜齿轮,那么输出所有重载工况下斜齿轮信息;
(4)如果齿面硬度HB=350,那么齿轮的主要失效形式为点蚀。
步骤五、斜齿轮检索,如图4所示,实例索引基于CBR理论进行设计,针对实例信息的设计特征、产品特征和加工特征,根据特征信息,推出斜齿轮的索引词汇,见表2;最近邻实例检索是CBR中最简单和普遍使用的方法。
表2实例索引词汇
相似度定义:以dist(A,B),sim(A,B)分别表示A,B之间的距离和相似度,在最近邻实例检索中sim(A,B)=1-dist(A,B)。相似度的计算实质是属性间距离的度量,则sim(A,B)应满足以下条件和性质:
sim(A,B)∈[0,1];sim(A,B)=1,当且仅当A=B,即自反性;sim(A,B)=sim(B,A),即对称性;sim(A,B)≥sim(A,C)+sim(C,B)-1,即三角不等式关系。
相似度计算:
(1)确定值的相似度sim(a,b)=1/|a-b|
(2)模糊概念的相似度
将模糊概念映射成数值来表示,如工艺性能{优,良,中,差}和{1,0.75,0.5,0.25}建立映射关系,这样模糊概念可以转化成数值进行相似度计算。
因为每个实例一般具有多个特征属性,所以相似度计算是整体相似度计算,相似度计算公式如下:
其中,ai和bi分别表示a和b两个实例具有n个特征属性,Ei表示每个特征属性的重要因子见表3。
令将要新设计的斜齿轮X(2,20,18,20,15,6,修形,左,内),根据表3中的描述,斜齿轮模数和啮合方式为必选属性,所以HG0010和HG0086不参与实例检验匹配相似度计算,根据上述公式计算,结果如下:
Sim(X,HG0030)=0.465
Sim(X,HG0050)=0.754
Sim(X,HG0053)=0.510
那么实例HG0050相似度最大,它是新设计斜齿轮X的最近邻匹配对象。
表3斜齿轮特征参数属性
本发明并不仅限于上述具体实施方式,本领域普通技术人员在本发明的实质范围内做出的变化、改型、添加或替换,也应属于本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!