基于模糊隶属度稀疏重构的半监督人脸识别方法及系统与流程
本发明属于模式识别领域,尤其涉及一种基于模糊隶属度稀疏重构的半监督人脸识别方法及系统。
背景技术:
随着计算机技术和图像处理技术的快速发展,人脸识别由于其广泛的应用,得到众多研究者的关注,成为现代模式识别技术研究中的一个重要方面。
然而,标记人脸图像既费时又费力,考虑到简单易得的未标记人脸图像,可以充分利用标记人脸图像中的标记信息以及未标记人脸图像中的特征信息对未标记人脸图像进行分类,这种学习方案称为半监督的学习。
其中基于图的半监督学习是其中一类学习方案,基于图的半监督学习使用点表示数据,边表示数据与相应类别之间的权重。数据权值较大的类属于此类的概率大于其他类,基于这种假设可以进行图像分类,而且基于图的半监督学习满足流形假设,并在数据的本征低维空间实现效果很好。
基于图的半监督学习的效果主要取决于数据对之间的相似度定义。其中最常见的相似度量方法是欧式空间的基于高斯核函数的度量方法,基于这种方法的方案有LNP(线性近邻传播)基于这个假设-每个数据可以被它的k个近邻所近似线性重构,去计算线性空间的数据相似度;SIS(稀疏诱导相似测量)利用稀疏表示技术去计算稀疏相似度,SIS与LNP相比使用稀疏过完备编码的时候不需要预先定义近邻个数。
考虑到稀疏表示技术可以避免KNN(k近邻)以及ε-ball的参数选择问题。SIS(稀疏诱导相似度量)使用稀疏诱导相似度测量的方法用来标记传播,并重新定义相似度测量方法,这种方法使用某个数据本身剩余的数据去稀疏线性重构数据本身,将得到的稀疏系数作为数据对之间的相似度;LPSN(标记传播稀疏近邻)在原始空间中使用稀疏表示技术去获得稀疏编码,并将稀疏编码用到数据标签的重构中;MLRR(流形低秩表示)使用增强的低秩稀疏数据表示方法进行实现数据相似度测量。
以上几种方法都可以充分获取数据之间的局部与全局的特征,但是数据的稀疏重构残差被忽略掉了,而数据的残差是基于稀疏表示的半监督学习的关键性因素,这样会降低半监督方法的分类识别精度。
技术实现要素:
为了解决现有技术的缺点,本发明提供一种基于模糊隶属度稀疏重构的半监督人脸识别方法及系统。本发明方法使用了隶属度函数并利用稀疏重构残差迭代计算测试数据的隶属度,而且保持了数据的流形结构。
一种基于模糊隶属度稀疏重构的半监督人脸识别方法,包括:
获取人脸图像数据集;人脸图像数据集包括训练样本子集和测试样本子集;训练样本子集的样本为类别标签已知的人脸图像,测试样本子集的样本为类别标签未知的人脸图像;
根据训练样本已知的类别标签,获得训练样本子集的模糊隶属度初始化矩阵;计算测试样本关于类别标签的重构残差,获得测试样本子集的模糊隶属度初始化矩阵;进一步得到人脸图像数据集关于类别标签的模糊隶属度初始化矩阵;
求解所有测试样本的稀疏系数,进而得到测试样本子集的稀疏解矩阵;
根据模糊隶属度初始化矩阵以及测试样本子集的稀疏解矩阵,迭代求解更新人脸图像数据集关于类别标签的模糊隶属度矩阵;
获取每个测试样本的最大隶属度所对应的类别标签即可完成测试样本的分类。
本发明使用模糊隶属度函数并且将常常忽略的重构残差放入隶属度函数中进行计算测试样本的隶属度,在流形空间中隐式地保持数据结构,充分考虑数据之间的局部和全局特征,提高了图像识别准确度。
在获得训练样本子集的模糊隶属度初始化矩阵的过程中,首先预先确定类别标签,然后判断训练样本子集内的训练样本是否属于预先确定的类别标签,若是,则相应训练样本模糊隶属度为1;否则,相应训练样本模糊隶属度为0。
测试样本子集的模糊隶属度初始化矩阵中,测试样本关于标签类别的模糊隶属度为两个数作商的比值;其中,除数为测试样本关于相应标签类别残差的倒数,被除数为测试样本关于所有标签类别的重构残差倒数的累和。
在迭代求解更新人脸图像数据集关于类别标签的模糊隶属度矩阵的过程中,
根据测试样本子集的稀疏解矩阵,计算每个测试样本关于类别标签的重构残差;
根据每个测试样本关于类别标签的重构残差,得到测试样本的更新后模糊隶属度,进一步得到测试样本子集更新后的模糊隶属度矩阵;
训练样本子集的模糊隶属度初始化矩阵不变,合并训练样本子集的模糊隶属度和测试样本子集更新后的模糊隶属度矩阵,得到人脸图像数据集关于类别标签的更新后的模糊隶属度矩阵。
本发明将常常忽略的重构残差放入隶属度函数中进行计算测试样本的隶属度,在流形空间中隐式地保持数据结构,充分考虑数据之间的局部和全局特征。本发明方法使用了隶属度函数并利用稀疏重构残差迭代计算测试数据的隶属度,而且保持了数据的流形结构。
在迭代求解更新人脸图像数据集关于类别标签的模糊隶属度矩阵的过程中,若满足本次求取的模糊隶属度矩阵与前一次求取的模糊隶属度矩阵作差后得到的矩阵中的所有元素的绝对值均小于预设阈值,则迭代结束;或者迭代次数大于最大的迭代次数,则迭代结束。
一种基于模糊隶属度稀疏重构的半监督人脸识别系统,包括人脸识别服务器,所述人脸识别服务器包括:
人脸图像数据集获取模块,其用于获取人脸图像数据集;人脸图像数据集包括训练样本子集和测试样本子集;训练样本子集的样本为类别标签已知的人脸图像,测试样本子集的样本为类别标签未知的人脸图像;
模糊隶属度初始化矩阵初始化模块,其用于根据训练样本已知的类别标签,获得训练样本子集的模糊隶属度初始化矩阵;计算测试样本关于类别标签的重构残差,获得测试样本子集的模糊隶属度初始化矩阵;进一步得到人脸图像数据集关于类别标签的模糊隶属度初始化矩阵;
稀疏解矩阵求解模块,其用于求解所有测试样本的稀疏系数,进而得到测试样本子集的稀疏解矩阵;
模糊隶属度矩阵更新模块,其用于根据模糊隶属度初始化矩阵以及测试样本子集的稀疏解矩阵,迭代求解更新人脸图像数据集关于类别标签的模糊隶属度矩阵;
类别标签获取模块,其用于获取每个测试样本的最大隶属度所对应的类别标签即可完成测试样本的分类。
所述模糊隶属度初始化矩阵初始化模块包括训练样本子集的模糊隶属度初始化矩阵初始化模块,其用于首先预先确定类别标签,然后判断训练样本子集内的训练样本是否属于预先确定的类别标签,若是,则相应训练样本模糊隶属度为1;否则,相应训练样本模糊隶属度为0。
所述模糊隶属度初始化矩阵初始化模块还包括测试样本子集的模糊隶属度初始化矩阵初始化模块,其用于将两个数作商求取测试样本关于标签类别的模糊隶属度;其中,除数为测试样本关于相应标签类别残差的倒数,被除数为测试样本关于所有标签类别的重构残差倒数的累和。
所述模糊隶属度矩阵更新模块还用于根据测试样本子集的稀疏解矩阵,计算每个测试样本关于类别标签的重构残差;
根据每个测试样本关于类别标签的重构残差,得到测试样本的更新后模糊隶属度,进一步得到测试样本子集更新后的模糊隶属度矩阵;
训练样本子集的模糊隶属度初始化矩阵不变,合并训练样本子集的模糊隶属度和测试样本子集更新后的模糊隶属度矩阵,得到人脸图像数据集关于类别标签的更新后的模糊隶属度矩阵。
所述基于模糊隶属度稀疏重构的半监督人脸识别系统还包括显示装置,所述显示装置与人脸识别服务器相连;所述显示装置用于显示每个测试样本的最大隶属度所对应的类别标签。
本发明的有益效果是:
本发明充分利用了全局和局部的图像特征并将稀疏残差用于模糊稀疏隶属度的计算中。由于人脸数字图像本身具有流形结构,将重构残差与数据模糊隶属度相结合求解数据隶属度可以将重构残差考虑到标记传播中,考虑重构残差的标记比只考虑稀疏编码或者仅考虑数据相似度的标记传播具有更多的判定信息,因此可以提高图像识别准确度。
附图说明
图1是本发明的基于模糊隶属度稀疏重构的半监督人脸识别方法流程图;
图2为初始化样本数据模糊隶属度矩阵构造示意图;
图3是本发明的基于模糊隶属度稀疏重构的半监督人脸识别系统实施例一结构示意图;
图4是本发明的基于模糊隶属度稀疏重构的半监督人脸识别系统实施例二结构示意图。
具体实施方式
下面结合附图与实施例对本发明做进一步说明:
本发明提供了一种基于图的人脸数字图像的半监督识别方法。在传统的基于图的半监督方法中,要么只使用简单的相似度测量方法,要么在执行标记传播的时候在一个分类任务中简单地考虑数据的全局和局部两种结构特征。本发明提出的方案使用模糊隶属度函数并且将常常忽略的重构残差放入隶属度函数中进行计算测试样本的隶属度,在流形空间中隐式地保持数据结构,充分考虑数据之间的局部和全局特征。
本发明的基于图的人脸数字图像的半监督识别方法的思路为:
首先,初始化所有样本的关于所有对应类别标签的隶属度矩阵;
然后计算测试样本关于所有类别标签的稀疏重构残差;
再定义迭代修改隶属度的方法并经过迭代求解得到测试样本关于所有类别的隶属度矩阵,获取每个测试样本的最大隶属度所对应的类别标签即可完成测试样本的分类。
图1是本发明的基于模糊隶属度稀疏重构的半监督人脸识别方法流程图,如图所示的基于模糊隶属度稀疏重构的半监督人脸识别方法,包括:
步骤1:获取人脸图像数据集;人脸图像数据集包括训练样本子集和测试样本子集;训练样本子集的样本为类别标签已知的人脸图像,测试样本子集的样本为类别标签未知的人脸图像。
在具体实施过程中:
获取人脸图像数据集X=[Xl Xu],每一个样本为xi∈Rq{i=1,2,...,n},n为样本个数,样本维数为q,其中为训练样本集,为测试样本集,nl为训练样本个数,nu为测试样本个数;
步骤2:根据训练样本已知的类别标签,获得训练样本子集的模糊隶属度初始化矩阵;计算测试样本关于类别标签的重构残差,获得测试样本子集的模糊隶属度初始化矩阵;进一步得到人脸图像数据集关于类别标签的模糊隶属度初始化矩阵。
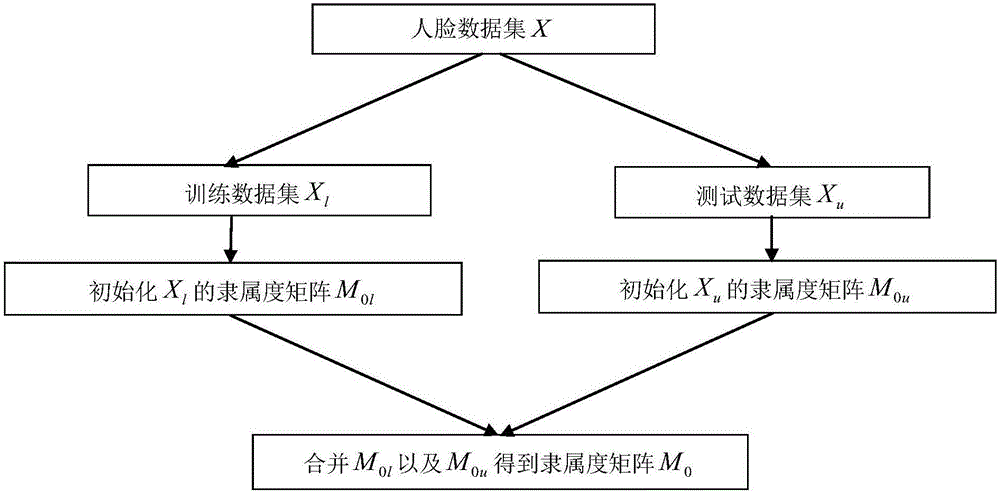
图2为初始化样本数据模糊隶属度矩阵构造示意图,具体方法为:
(1)首先分别对训练样本和测试样本初始化模糊隶属度矩阵,定义类别集合C={1,2,...,c},以及训练样本集模糊隶属度矩阵其中对于训练样本集数据xi∈Xl,c为大于1的正整数;可以使用下式初始化训练样本的模糊隶属度矩阵M0l,其中,mij0为模糊隶属度矩阵M0l的元素:
其中mij0表示第0次迭代的时候第i个训练样本的第j类的隶属度,p是某类别。
(2)对于测试样本集数据xk∈Xu,可以根据下式获得测试样本的模糊隶属度初始化矩阵M0u,其中,mkj0为模糊隶属度矩阵M0l的元素:
其中mkj0表示第0次迭代的时候第k个测试样本xk的第j类的隶属度,errkj0为第k个测试样本xk对应第j类样本集Xj的初始重构残差,errkjo=||xk-Xjα′||2;第j类样本集Xj内的样本的类别标签均为第j类;α′为第k个测试样本xk相对于第j类样本集Xj的稀疏系数。
在具体实施过程中,使用下式求解第k个测试样本xk相对于第j类样本集Xj的稀疏系数:
min||xk-Xjα′||2+γ′||α′||1(k∈1,2,....nu;j∈C)
其中γ′表示对α′的约束防止过拟合系数,γ′为常系数。
(3)合并M0l以及M0u得到人脸图像数据集关于类别标签的模糊隶属度初始化矩阵M0:
其中
步骤3:求解所有测试样本的稀疏系数,进而得到测试样本子集的稀疏解矩阵。
在具体实施过程中,对每一个测试样本xk,使用下式求解稀疏系数:
min||xk-Xα||2+γ||α1||(k∈1,2,...,nu)
其中xk已被从X中移除,将所有获得的稀疏系数α组成一个系数矩阵Scoeff∈Rn×n,其中系数α∈Rn×1表示X中的每个样本对xk的贡献率;γ表示对α的约束防止过拟合系数,γ为常系数。
步骤4:根据模糊隶属度初始化矩阵以及测试样本子集的稀疏解矩阵,迭代求解更新人脸图像数据集关于类别标签的模糊隶属度矩阵。
在实施过程中,迭代修改测试样本的模糊隶属度,其中t为迭代次数,t为大于或等于1的正整数。
使用上面得到的系数矩阵Scoeff计算测试样本xk与每一类相关的重构残差。
第k个测试样本xk对应第j类样本集Xj的重构残差errkjt:
errkjt=||xk-XjWjt-1α2||
其中Wjt-1表示第t-1次迭代的时候xk对应第j类的隶属度;Xj为第j类样本集。
根据以上得到的重构残差errkjt去优化下式:
可以得到更新后的测试样本的隶属度:
更新隶属度矩阵:
使用mkjt去更新Mtu,Mtl=M0l,可以得到新的隶属度矩阵
直到满足Mt-Mt-1后得到的矩阵中的所有元素的绝对值均小于预设阈值,则迭代结束;或者当前迭代次数大于最大的迭代次数,则迭代结束。
步骤5:获取每个测试样本的最大隶属度所对应的类别标签即可完成测试样本的分类。
对第t次迭代得到的测试样本的隶属度矩阵根据下式进行处理得到最终的分类结果。
下面以具体实验来验证本发明的该人脸识别方法:
以所使用的YaleB数据集为例,在所使用的数据集中每一个人为一个类别,这时候C={1,2,...,38}。本发明中使用的是5倍交叉验证,将样本数据集随机均匀地分成5份,每次取其中一份作为测试样本集Xu,其余四份则作为Xl,实验可以重复5次。
以人脸数据集(YaleB)中的图像数据进行验证,YaleB人脸数据库中包含38个人,共有2414个已知数据类型的样本,像素为32*32。实验采用5倍交叉验证,将所有数据随机均匀分成10份,每次选取一组作为测试数据,其余的作为训练数据,实验重复5次取5次的平均值作为最终的识别准确率,准确率如表1所示。
表1识别方法比较
本发明分别以采用率为10%、20%、30%、40%、50%和60%的情况下,比较本发明的该识别方法与LNP、SIS、LPSN和MLRR识别方法的识别率,从表1可看出本发明的该识别方法与其他识别方法相比,具有更高的识别率。其中,LNP为Local Neighborhood Patterns的简称,全称为局部邻域模式方法;SIS为Sparsity Induced Similarity measure for label propagation的简称,全称为基于稀疏相似度量的标记传播方法;LPSN为Label propagation through sparse neighborhood的简称,全称为稀疏紧邻标记传播方法;MLRR为manifold low-rank representation的简称,全称为流形低秩表示方法。
本发明充分利用了全局和局部的图像特征并将稀疏残差用于模糊稀疏隶属度的计算中。由于人脸数字图像本身具有流形结构,将重构残差与数据模糊隶属度相结合求解数据隶属度可以将重构残差考虑到标记传播中,考虑重构残差的标记比只考虑稀疏编码或者仅考虑数据相似度的标记传播具有更多的判定信息,因此可以提高图像识别准确度。
图3是本发明的基于模糊隶属度稀疏重构的半监督人脸识别系统实施例一结构示意图。如图3所示的基于模糊隶属度稀疏重构的半监督人脸识别系统,包括人脸识别服务器,所述人脸识别服务器包括:人脸图像数据集获取模块、模糊隶属度初始化矩阵初始化模块、稀疏解矩阵求解模块、模糊隶属度矩阵更新模块和类别标签获取模块。
(1)人脸图像数据集获取模块,其用于获取人脸图像数据集;人脸图像数据集包括训练样本子集和测试样本子集;训练样本子集的样本为类别标签已知的人脸图像,测试样本子集的样本为类别标签未知的人脸图像。
(2)模糊隶属度初始化矩阵初始化模块,其用于根据训练样本已知的类别标签,获得训练样本子集的模糊隶属度初始化矩阵;计算测试样本关于类别标签的重构残差,获得测试样本子集的模糊隶属度初始化矩阵;进一步得到人脸图像数据集关于类别标签的模糊隶属度初始化矩阵。
模糊隶属度初始化矩阵初始化模块包括训练样本子集的模糊隶属度初始化矩阵初始化模块,其用于首先预先确定类别标签,然后判断训练样本子集内的训练样本是否属于预先确定的类别标签,若是,则相应训练样本模糊隶属度为1;否则,相应训练样本模糊隶属度为0。
模糊隶属度初始化矩阵初始化模块还包括测试样本子集的模糊隶属度初始化矩阵初始化模块,其用于将两个数作商求取测试样本关于标签类别的模糊隶属度;其中,除数为测试样本关于相应标签类别残差的倒数,被除数为测试样本关于所有标签类别的重构残差倒数的累和。
(3)稀疏解矩阵求解模块,其用于求解所有测试样本的稀疏系数,进而得到测试样本子集的稀疏解矩阵。
(4)模糊隶属度矩阵更新模块,其用于根据模糊隶属度初始化矩阵以及测试样本子集的稀疏解矩阵,迭代求解更新人脸图像数据集关于类别标签的模糊隶属度矩阵。
模糊隶属度矩阵更新模块还用于根据测试样本子集的稀疏解矩阵,计算每个测试样本关于类别标签的重构残差;
根据每个测试样本关于类别标签的重构残差,得到测试样本的更新后模糊隶属度,进一步得到测试样本子集更新后的模糊隶属度矩阵;
训练样本子集的模糊隶属度初始化矩阵不变,合并训练样本子集的模糊隶属度和测试样本子集更新后的模糊隶属度矩阵,得到人脸图像数据集关于类别标签的更新后的模糊隶属度矩阵。
(5)类别标签获取模块,其用于获取每个测试样本的最大隶属度所对应的类别标签即可完成测试样本的分类。
图4是本发明的基于模糊隶属度稀疏重构的半监督人脸识别系统实施例二结构示意图。如图4所示的基于模糊隶属度稀疏重构的半监督人脸识别系统,包括人脸识别服务器和显示装置,所述显示装置与人脸识别服务器相连;
人脸识别服务器包括:人脸图像数据集获取模块、模糊隶属度初始化矩阵初始化模块、稀疏解矩阵求解模块、模糊隶属度矩阵更新模块和类别标签获取模块。
显示装置用于显示每个测试样本的最大隶属度所对应的类别标签。其中,显示装置包括各种类型的显示屏。
本发明充分利用了全局和局部的图像特征并将稀疏残差用于模糊稀疏隶属度的计算中。由于人脸数字图像本身具有流形结构,将重构残差与数据模糊隶属度相结合求解数据隶属度可以将重构残差考虑到标记传播中,考虑重构残差的标记比只考虑稀疏编码或者仅考虑数据相似度的标记传播具有更多的判定信息,因此可以提高图像识别准确度。
本领域普通技术人员可以理解实现上述实施例方法中的全部或部分流程,是可以通过计算机程序来指令相关的硬件来完成,所述的程序可存储于计算机可读取存储介质中,该程序在执行时,可包括如上述各方法的实施例的流程。其中,所述的存储介质可为磁碟、光盘、只读存储记忆体(Read-Only Memory,ROM)或随机存储记忆体(Random AccessMemory,RAM)等。
上述虽然结合附图对本发明的具体实施方式进行了描述,但并非对本发明保护范围的限制,所属领域技术人员应该明白,在本发明的技术方案的基础上,本领域技术人员不需要付出创造性劳动即可做出的各种修改或变形仍在本发明的保护范围以内。
- 还没有人留言评论。精彩留言会获得点赞!