基于主成分分析与支持向量机的变压器绝缘状态评估方法与流程
本发明属于电力变压器设备状态检测技术领域,特别涉及一种基于主成分分析与参数寻优支持向量机的变压器绝缘状态评估方法。
背景技术:
随着电网容量的增大和用户对供电可靠性要求的提高,电力设施维修费用占电力成本的比例也在不断提高,电力设备状态维修管理的重要性日益显现。如何采取合理的维修策略与制定正确的维修计划,以保证在不降低可靠性的前提下节省维修费用,成为电力部门面临的重要课题。状态检修是以设备的当前实际工作状况为依据,通过先进的状态监测手段、可靠的评价手段与寿命的预测手段来判断设备的状态,并根据分析诊断结果在设备性能下降到一定程度或故障将要发生之前进行维修。然而由于变压器是一个固体、液体复合绝缘的复杂系统,其老化、故障机理复杂,具有不确定性,因此,变压器绝缘状态评估是一项复杂而艰巨的任务。
支持向量机是数据挖掘中的一项新技术。它具有严格的理论和数学基础,基于结构风险最小化原则,其泛化能力优越,算法具有全局最优性。将支持向量机应用到变压器绝缘状态评估中,可以可靠地寻找出变压器各项指标数据与变压器运行状态的之间的联系和规律。
主成分分析是一种基于多元统计分析的数据压缩与信息提取技术,通过构造新的变量组来降低原始数据空间维数,再从新的映射空间提取统计特征向量,来反映原始数据空间的数据特性,使问题变的更加简单、直观。
技术实现要素:
本发明的目的在于提供一种基于主成分分析与参数寻优支持向量机的变压器绝缘状态评估方法,该方法可以通过变压器的相关指标数据判断出变压器的运行状态,并且具有较高的准确率和可靠度。
为了达到上述目的,本发明所采用的技术方案是:
基于主成分分析与支持向量机的变压器绝缘状态评估方法,评估步骤如下:
步骤一、分别获取变压器油中溶解气体数据、变压器电气试验数据以及绝缘油特性试验数据作为训练支持向量机的输入数据;获取变压器对应的绝缘状态等级数据作为训练支持向量机的输出数据;
步骤二、用半岭模型对各项输入数据进行预评估并实现数据的归一化;
半岭模型的评分函数包括降半岭模型评分函数与升半岭模型评分函数两种,其公式分别为:
其中,a和b是模型的阈值,分别对应每项变压器评分参数的初始值和注意值;x是评分参数的实际测量值,f(x)为评分的结果值;对于f(x)数值越大越好的指标,采用升半岭模型,反之采用降半岭模型;
将步骤一所述的输入数据分别作为步骤二对应公式的自变量x的值,求得因变量f(x)的值即为该项数据的预评估结果;预评估结果f(x)的取值范围在0到1之间;
步骤三、利用主成分分析法对预评估后的输入数据进行降维处理,得到新的输入样本集;
步骤四、用改进的粒子群算法对支持向量机的核函数参数g和惩罚参数c进行寻优;
其中,粒子群算法的改进内容为,设置可以非线性自适应调整的惯性权重w,从而更好地平衡局部和全局搜索能力;惯性权重w描述了粒子上一代速度对当前代速度的影响水平,对其采用改进的非线性递减算法,通过在粒子群算法早期加快惯性权重的递减速度,使该算法更快地进入局部搜索;改进后粒子群算法的速度更新公式及惯性权重w的表达式分别如下:
式中,v为当前粒子的速度;x为当前粒子的位置;p为个体最优位置;g为全局最优位置;c1、c2为学习因子,分别用于调节粒子向个体最优位置p和全局最优位置g飞行的步长;r1、r2为介于[0,1]之间的随机数;k为当前迭代次数;i为当前粒子标号;d是维数的标号;w为惯性权重,它描述了粒子上一代速度对当前代速度的影响水平;kmax为最大允许迭代次数;k为当前的迭代次数;wmax和wmin分别是最大惯性权重和最小惯性权重;
步骤五、用降维处理后的输入样本集与变压器对应的绝缘状态等级数据训练支持向量机,得到最终的支持向量机模型;
步骤六、用最终的支持向量机模型处理待评估的变压器溶解气体数据、变压器电气试验数据以及绝缘油特性试验数据,从而获得变压器的绝缘状态等级。
所述步骤一中,所述变压器油中溶解气体数据包括H2、C2H2、CH4、C2H6、C2H4、总烃等各种气体的含量,总烃的产气速率以及CO2与CO气体含量的比值;所述变压器电气试验数据包括变压器介质损耗因数、绕组泄漏电流、绝缘电阻、吸收比、绕组直流电阻相间差;所述绝缘油特性试验数据包括绝缘油介损、油中含水量、糠醛含量;所述变压器绝缘状态等级数据包括优秀、良好、注意、异常、严重五种状态。
所述步骤三中,利用主成分分析法对预评估后的输入数据进行降维处理的步骤为:
a)计算m维样本数据的线性组合相关系数矩阵R:
首先求取m维样本数据X的均值向量μ,其中m维样本数据X=(X1,X2,…Xm)T,Xi=(Xi1,Xi2,…Xin)表示第i组输入样本数据的值,其中i表示样本序号,i=1,2,…n,n表示总样本数;其次对所得的样本数据X去均值化,得到去均值后的样本向量然后对样本向量构建协方差矩阵即得到相关系数矩阵R;
b)计算相关系数矩阵R的特征值与特征向量:
求出相关系数矩阵R的特征值λi(i=1,2,…,m),并将λi按从大到小的顺序排列,即λ1≥λ2≥…≥λm≥0,λi的大小表示对应的主成分对变压器评估特征的贡献程度;然后分别求出对应于特征值λi的特征向量;
c)确定累计贡献率ci,当累计贡献率ci≥ρ时,取前k个特征向量Wk=[w1,w2…,wk],作为子空间的基,其中ρ为常数,取ρ≥85%;其中,
d)确定所提取的k个主成分为其中k<n,F即为用主成分分析法降维后的新的样本集。
所述步骤四中,用改进的粒子群算法对支持向量机的核函数参数g和惩罚参数c进行优化的过程如下:
过程1:初始化粒子群粒子的位置和速度,并初始化支持向量机的参数:惩罚参数c和RBF核函数参数g;
过程2:评价粒子群中每个粒子的适应度,计算每个粒子的适应度函数;
过程3:对于每个粒子,将其当前位置的适应度与其经历过的最好位置pbest的适应度作比较,选择适应度最大时的位置作为当前粒子的最好位置pbest;
过程4:对每个粒子,将其适应度与经历过的全局最好位置gbest的适应度作比较,如果粒子的适应度更好则重新设置gbest;
过程5:用改进的粒子速度更新公式更新粒子的位置和速度;
过程6:当迭代次数或者适应值满足条件,则终止迭代,获得优化最佳的支持向量机参数;否则返回步骤过程3。
本发明的有益效果在于:
(1)本发明利用主成分分析与参数寻优支持向量机相结合的方法对变压器绝缘状态进行评估,能够更加准确、可靠地识别变压器的状态等级,从而为变压器的维修策略提供依据。
(2)本发明用主成分分析法对对变压器评估数据的样本集进行降维处理,可以剔除无效特征、提取有效特征,提高评估结果的精度。
(3)本发明用改进的粒子群算法对支持向量机的参数进行寻优,参数寻优过程自适应性好、简单、高效。改进的粒子群算法的惯性权重可以非线性地自适应调整,从而更好地平衡其全局搜索与局部搜索能力。
(4)本发明用半岭模型对变压器的原始数据进行预评估,降低了原始数据冗余信息的干扰,提高了评估数据的有效性。
附图说明
图1为本发明的变压器绝缘状态评估方法的流程图。
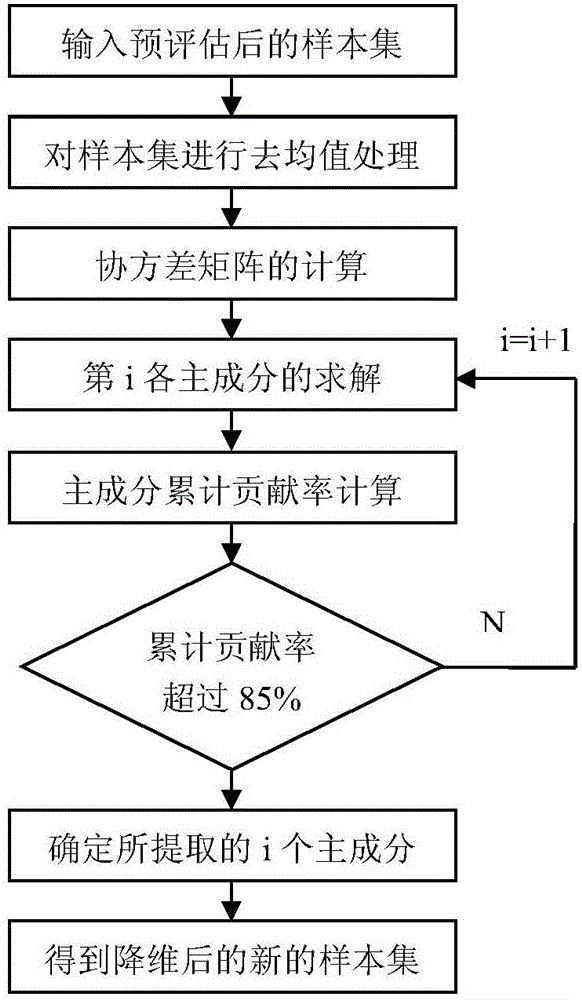
图2为本发明中用主成分分析法对样本数据进行降维处理的流程图。
图3为本发明中改进的粒子群算法的流程图。
具体实施方式
下面结合附图和具体实施方式对本发明进行详细说明。
本发明一种基于主成分分析与支持向量机的变压器绝缘状态评估方法,其流程图如图1所示,具体按照以下步骤实施:
步骤一、分别获取变压器油中溶解气体数据、变压器电气试验数据以及绝缘油特性试验数据作为训练支持向量机的输入数据;获取变压器对应的状态等级数据作为训练支持向量机的输出数据;
其中,变压器油中溶解气体数据包括H2、C2H2、CH4、C2H6、C2H4、总烃等各种气体的含量,总烃的产气速率以及CO2与CO气体含量的比值;变压器电气试验数据包括变压器介质损耗因数、绕组泄漏电流、绝缘电阻、吸收比、绕组直流电阻相间差;绝缘油特性试验数据包括绝缘油介损、油中含水量、糠醛含量;变压器绝缘状态等级数据包括优秀、良好、注意、异常、严重五种状态,分别用数字1、2、3、4、5表示;变压器绝缘状态等级与其数字代码、状态描述以及对应的维修策略如下表所示:
步骤二、用半岭模型对各项输入数据进行预评估并实现数据的归一化;
半岭模型的评分函数包括降半岭模型评分函数与升半岭模型评分函数两种,其公式分别为:
其中,a和b是模型的阈值,分别对应每项变压器评分参数的初始值和注意值;x是评分参数的实际测量值,f(x)为评分的结果值。对于f(x)数值越大越好的指标,采用升半岭模型,反之采用降半岭模型。
将步骤一所述的输入数据分别作为步骤二对应公式的自变量x的值,求得因变量f(x)的值即为该项数据的预评估结果。预评估结果f(x)的取值范围在0到1之间。
步骤三、利用主成分分析法对预评估后的输入数据进行降维处理,得到新的输入样本集;
如图2所示,利用主成分分析法对预评估后的m维样本数据进行降维处理的步骤为:
a)计算m维样本数据的线性组合相关系数矩阵R:
首先求取m维样本数据X的均值向量μ,其中m维样本数据X=(X1,X2,…Xm)T,Xi=(Xi1,Xi2,…Xin)表示第i组输入样本数据的值,其中i表示样本序号,i=1,2,…n,n表示总样本数;其次对所得的样本数据X去均值化,得到去均值后的样本向量然后对样本向量向量构建协方差矩阵即得到相关系数矩阵R;
b)计算相关系数矩阵R的特征值与特征向量:
求出相关系数矩阵R的特征值λi(i=1,2,…,m),并将λi按从大到小的顺序排列,即λ1≥λ2≥…≥λm≥0,λi的大小表示对应的主成分对变压器评估特征的贡献程度;然后分别求出对应于特征值λi的特征向量;
c)确定累计贡献率ci,当累计贡献率ci≥ρ时,优选地取前k个特征向量Wk=[w1,w2…,wk],作为子空间的基,其中ρ为常数,一般取ρ≥85%;其中,
d)确定所提取的k个主成分为其中k<n,F即为用主成分分析法降维后的新的样本集。
步骤四、用改进的粒子群算法对支持向量机的核函数参数g和惩罚参数c进行寻优;
如图3所示,用改进的粒子群算法对支持向量机的核函数参数g和惩罚参数c进行优化的过程如下:
过程1:初始化粒子群粒子的位置和速度,并初始化支持向量机的参数:惩罚参数c和RBF核函数参数g;
过程2:评价粒子群中每个粒子的适应度,计算每个粒子的适应度函数;
适应度函数选择支持向量机的输出分类决策函数,其公式为:
其中,a1为每个训练样本所对应的拉格朗日系数;占K(zi,z)为核函数(K(zi,z)=exp(-|zi-z|2/g2));C为惩罚参数,b为偏置。
过程3:对于每个粒子,将其当前位置的适应度与其经历过的最好位置pbest的适应度作比较,选择适应度最大时的位置作为当前粒子的最好位置pbest;
过程4:对每个粒子,将其适应度与经历过的全局最好位置gbest的适应度作比较,如果粒子的适应度更好则重新设置gbest;
过程5:用改进的粒子速度更新公式更新粒子的位置和速度;
其中,粒子群算法的改进内容为,设置可以非线性自适应调整的惯性权重w,从而更好地平衡局部和全局搜索能力。惯性权重w描述了粒子上一代速度对当前代速度的影响水平,对其采用改进的非线性递减算法,通过在粒子群算法早期加快惯性权重的递减速度,使该算法更快地进入局部搜索。改进后粒子群算法的速度更新公式及惯性权重w的表达式分别如下:
式中,v为当前粒子的速度;x为当前粒子的位置;p为个体最优位置;g为全局最优位置;c1、c2为学习因子,分别用于调节粒子向个体最优位置p和全局最优位置g飞行的步长;r1、r2为介于[0,1]之间的随机数;k为当前迭代次数;i为当前粒子标号;d是维数的标号;w为惯性权重,它描述了粒子上一代速度对当前代速度的影响水平;kmax为最大允许迭代次数;k为当前的迭代次数;wmax和wmin分别是最大惯性权重和最小惯性权重;
过程6:当迭代次数或者适应值满足条件,则终止迭代,获得优化最佳的支持向量机参数;否则返回步骤过程3。
步骤五、用降维处理后的输入样本集与变压器对应的状态等级数据训练支持向量机,得到最终的支持向量机模型;
步骤六、用该支持向量机模型处理待评估的变压器溶解气体数据、变压器电气试验数据以及绝缘油特性试验数据,从而获得变压器的绝缘状态等级。
最后,对变压器绝缘状态评估实例进行分析,选取50组变压器样本数据训练支持向量机,对另外6组变压器数据进行评估,最终,其评估结果与变压器的实际状态一致。
上面虽然结合附图对本发明的具体实施方式进行了描述,但并非对本发明保护范围的限制,在本发明的技术方案的基础上,本领域技术人员不需要付出创造性劳动即可做出的各种修改或变形仍在本发明的保护范围以内。
- 还没有人留言评论。精彩留言会获得点赞!