视频封面的提供方法及装置与流程
本申请涉及计算机技术领域,特别是涉及视频封面的提供方法及装置。
背景技术:
我们在视频网站中看视频时,会在相关网页中看到每个视频都有一个视频封面,视频封面对应图片的质量高低是吸引用户点击视频的重要因素,尤其对于当下比较火的短视频而言,视频封面对应图片的质量尤为重要。
现有视频封面的选取方案,通常是按照固定时间点(比如,将一个视频按时长平均分割为若干份子视频,将每份子视频开始播放的时间点作为固定时间点,等等),从该视频中截取图片作为视频封面的候选图片以供用户从中选择,但是如此获得的视频封面的图片经常会出现模糊、离焦等问题,或者画面过于简单、不含有有意义的物体或对象等。
随着深度机器学习技术的迅猛发展,以及深度机器学习技术在图像和语音的识别处理方面取得的巨大进展,为了解决上述选取视频封面方案中的问题,YouTube提出了的基于深度机器学习技术的视频缩略图自动生成方案,可采用深度神经网络(DNN,Deep Neural Network),将用户上传的作为视频封面的图片作为“高质量”训练集,将从视频文件中随机截取的图片作为“低质量”训练集,然后预先使用所述“高质量”训练集和“低质量”训练集进行基于DNN的机器学习模型的训练,以得到训练好的DNN机器学习模型。在视频缩略图生成过程中,可先从视频文件中随机截取图片(比如,一秒截取一帧),然后使用上述预先训练好的DNN机器学习模型对截取到的图片进行打分,再从得分最高的图片(可能是若干幅)中选取最好的一幅图片来作为视频封面。经过人工评估,也即通过评估人来对比DNN机器学习模型产生的视频封面与按照固定时间点来截取图片的方案所产生的视频封面,65%的人认为DNN机器学习模型产生的视频封面的图片更好。
但是,此种方案也会存在以下不足之处:
首先,直接将用户上传的图片作为“高质量”训练集,将从视频中按照固定时间点截取的图片作为“低质量”训练集,会引入大量的“脏数据”也就是说,用户上传的图片中可能会存在很多质量不好的图片,从视频中按照固定时间点截取的图片中也可能会存在很多质量不错的图片,因此,这种包含“脏数据”的训练集,会直接导致训练出的机器学习模型达不到很好的分类效果;
其次,当视频文件时长较长时,此种截图方式,会使得截取到的图片的重复度比较高,最后提供给用户的视频封面图片很有可能是一些重复度比较高的图片。
技术实现要素:
本申请提供了视频封面的提供方法及装置,不但可保证不遗漏视频文件中的所有重要场景,又可降低提供的视频封面候选图片中的图片重复度,提升候选图片的质量,更便于用户从中选取到更为适合的视频封面。
本申请提供了如下方案:
一种视频封面的提供方法,包括:
接收用户上传的视频文件,根据视频文件中相邻帧内容的变化情况确定场景变换关键帧并对所述场景变换关键帧对应的图片进行截取;
通过预先训练好的用于图片分类的机器学习模型为截取到的图片进行打分并排序;
根据排序将得分高的预置幅数图片作为视频封面的候选图片提供给用户,以便用户从所述候选图片中进行视频封面的选择。
可选的,还包括:
接收用户对所述候选图片中任一图片的选择指令;
将用户选择的图片确定为视频封面。
可选的,根据视频文件中相邻帧内容的变化情况确定场景变换关键帧并对所述场景变换关键帧对应的图片进行截取,包括:
判断视频文件中相邻两帧内容变化是否超出预置的变化阈值;
将超出预置变化阈值的帧确定为场景变换关键帧;
对场景变换关键帧对应的图片进行截取,并将截取到的图片组成场景变换关键帧图片集合。
可选的,对用于图片分类的机器学习模型的训练,包括:
确定用于机器学习模型训练的图片数据;
将所述图片数据在卷积神经网络CNN的机器学习模型中做迭代训练,并在迭代训练过程中调整卷积神经网络的权值,以在CNN机器学习模型的基础上得到用于图片分类的CNN机器学习模型;
对所述用于图片分类的CNN机器学习模型进行评估;
若评估通过,则训练结束并将所述用于图片分类的CNN机器学习模型作为训练好的用于图片分类的CNN机器学习模型。
可选的,还包括:
若评估未通过,则对用于图片分类的CNN机器学习模型中采用算法的参数进行调整,以便将所述图片数据在参数调整后的用于图片分类的CNN机器学习模型中继续做迭代训练,并在迭代训练过程中调整卷积神经网络的权值,直至得到的用于图片分类的CNN机器学习模型评估通过。
可选的,所述确定用于机器学习模型训练的图片数据,包括:
获取基础图片数据集;
获取基础图片数据集中图片的色彩特征参数值;
根据所述色彩特征参数值将基础图片数据集中不符合预置条件的图片去除,以获得用于机器学习模型训练的图片数据。
可选的,所述基础图片数据集包括:含有用户上传图片的第一数据集及含有按预置时间间隔随机截取的图片的第二数据集;
所述色彩特征参数值包括色调值、饱和度值及亮度值;
根据所述色彩特征参数值将基础图片数据集中不符合预置条件的图片去除,以获得用于机器学习模型训练的图片数据,包括:
根据预置的色彩特征权重,对每幅图片的色彩特征参数值做加权和计算,以获得每幅图片对应的色彩特征数值;
将所述第一数据集中色彩特征数值低于第一预置分值的图片及所述第二数据集中色彩特征数值高于第二预置分值的图片进行去除,分别获得第一类型数据集及第二类型数据集,以作为用于机器学习模型训练的图片数据。
可选的,所述基础图片数据集包括:含有用户上传图片的第一数据集及含有按预置时间间隔随机截取的图片的第二数据集;
所述色彩特征参数值包括色调值、饱和度值及RGB值;
根据所述色彩特征参数值将基础图片数据集中不符合预置条件的图片去除,以获得用于机器学习模型训练的图片数据,包括:
将所述第一数据集中色调值低于第一预置色调阈值的图片及所述第二数据集中色调值高于第二预置色调阈值的图片进行去除;
将所述第一数据集中饱和度值低于第一预置饱和度阈值的图片及所述第二数据集中饱和度值高于第二预置饱和度阈值的图片进行去除;
根据所述RGB值将所述第一数据集中的黑白图片进行去除;
将第一数据集以及第二数据集中保留下来的图片分别确定为第一类型数据集及第二类型数据集,以作为用于机器学习模型训练的图片数据。
可选的,在将所述第一数据集中色彩特征数值低于第一预置分值的图片及所述第二数据集中色彩特征数值高于第二预置分值的图片进行去除之后,还包括:
分别对第一数据集及第二数据集中剩余图片之间的相似度进行判断,并根据判断结果从相似度达到预置相似度阈值的图片中选取一幅图片进行保留,以便将第一数据集及第二数据集中保留下来的图片分别作为所述第一类型数据集及第二类型数据集。
一种视频封面的提供装置,包括:
截图单元,用于接收用户上传的视频文件,并根据视频文件中相邻帧内容的变化情况确定场景变换关键帧并对所述场景变换关键帧对应的图片进行截取;
打分单元,用于通过预先训练好的用于图片分类的机器学习模型为截取到的图片进行打分并排序;
候选图片提供单元,用于根据排序将得分高的预置幅数图片作为视频封面的候选图片提供给用户,以便用户从所述候选图片中进行视频封面的选择。
可选的,还包括:
指令接收单元,用于接收用户对所述候选图片中任一图片的选择指令;
视频封面确定单元,用于将用户选择的图片确定为视频封面。
可选的,所述截图单元,具体用于:
判断视频文件中相邻两帧内容变化是否超出预置的变化阈值;
将超出预置变化阈值的帧确定为场景变换关键帧;
对场景变换关键帧对应的图片进行截取,并将截取到的图片组成场景变换关键帧图片集合。
根据本申请提供的具体实施例,本申请公开了以下技术效果:
通过本申请实施例,当接收到用户上传的视频文件后,可根据视频文件中相邻帧内容的变化情况确定场景变换帧,并对所述场景变换帧对应的图片进行截取,然后可通过预先训练好的用于图片分类的机器学习模型为截取到的图片进行打分并排序,再根据排序将得分高的预置幅数图片作为视频封面的候选图片提供给用户,以便用户从所述候选图片中进行视频封面的选择。以此,既可保证不遗漏视频文件中的所有重要场景,又可降低提供的视频封面候选图片中的图片重复度,提升候选图片的质量,更便于用户从中选取到更为适合的视频封面。
当然,实施本申请的任一产品并不一定需要同时达到以上所述的所有优点。
附图说明
为了更清楚地说明本申请实施例或现有技术中的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本申请的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1是本申请实施例提供的方法流程图;
图2是本申请实施例提供的方法中对用于图片分类的机器学习模型的训练流程图;
图3-1至图3-3是本申请实施例提供的方法中的实验数据示意图;
图4是本申请实施例提供的装置示意图。
具体实施方式
下面将结合本申请实施例中的附图,对本申请实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本申请一部分实施例,而不是全部的实施例。基于本申请中的实施例,本领域普通技术人员所获得的所有其他实施例,都属于本申请保护的范围。
参看图1,本申请实施例首先提供了一种视频封面的提供方法,可以包括以下步骤:
S101,接收用户上传的视频文件,并根据视频文件中相邻帧内容的变化情况确定场景变换关键帧并对所述场景变换关键帧对应的图片进行截取。
通常情况下,视频网站不但能够将其对应服务器中内置的视频文件提供给用户观看,还可以在接收到任一用户上传的视频文件后提供给用户观看。在本实施例中,当接收到用户上传的视频文件之后,可先确定视频文件中的场景变换情况(也可以理解为镜头发生切换的情况),在本实施例中,比如可获得视频文件中相邻帧的内容变化情况,判断相邻两帧内容变化是否超出预置的变化阈值,并且把超出预置变化阈值的帧确定为场景变换关键帧,然后可对确定的场景变换关键帧对应的图片进行截取,并可进一步将截取到的所有图片组成场景变换关键帧图片集合,以在后续步骤中使用,以此来保证不遗漏视频文件中场景变换时的场景(也可认为是重要场景),又可降低截取到图片的重复度。
在实际应用中,也可通过视频文件中的码率变化来判断视频文件中的场景变换情况,然后根据场景变换情况从视频文件中进行图片的截取,以得到场景变换时对应的截图,通过此种截图方式,可尽可能的保证不遗漏视频文件中所有重要场景,又可降低截取到图片的重复度。
此外,也可以使用其他方式来确定视频文件中的场景变换情况,例如我们还可以通过图片的灰度直方图特征、尺度不变特征变换(SIFT,Scale-Invariant Feature Transform)特征等对视频文件中图片的相似度进行判断,比如,可先按照预置的频率截取图片(比如,2秒一帧等),然后根据现有关于判断图片相似度的技术对截取到的图片之间的相似度进行判断,根据判断结果对相似度高(比如相似度达到预设的相似度值)的图片只保留一张,这样也可达到确定视频文件中的场景变化情况的目的。
S102,通过预先训练好的用于图片分类的机器学习模型为截取到的图片进行打分并排序。
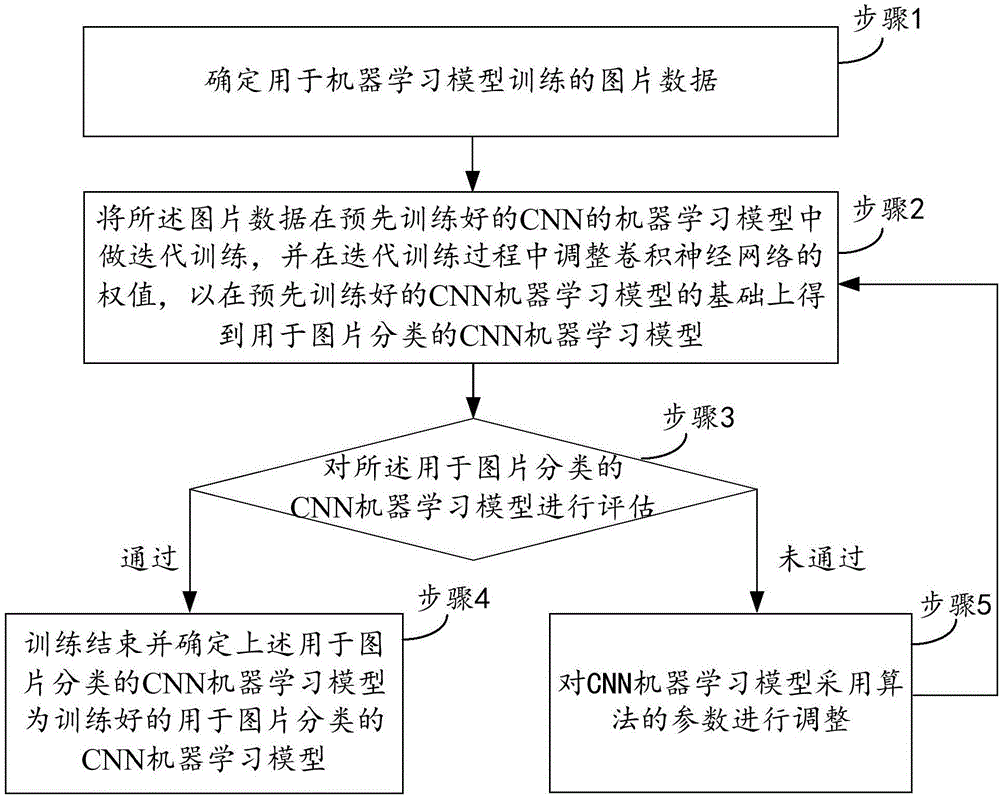
参看图2所示,在本实施例中,对用于图片分类的机器学习模型的训练过程,可包括如下步骤:
步骤1,确定用于机器学习模型训练的图片数据。
本实施例中,可使用深度机器学习模型(其中包括有监督学习与无监督学习.不同的学习框架下建立的学习模型不同),比如可采用深度学习卷积神经网络(CNN,Convolutional Neural Network),一种深度的有监督学习的机器学习模型,当然,根据实际需要也可采用其他适合的深度机器学习模型。
通常情况下,用于机器学习模型训练的数据可分为三个部分:训练数据集(training data),测试数据集(testing data),验证数据集(validation data),这三部分数据的比例可设置为80%,10%,10%。对于有监督学习的机器学习模型来说,获取用于训练的数据是最重要的环节之一,高质量的数据是机器学习模型训练的关键。
基于此,在具体实现时,为了确定用于机器学习模型训练的图片数据,可先获取基础图片数据集,其中,所述基础图片数据集可包括:含有用户上传图片的第一数据集及含有按预置时间间隔随机截取的图片的第二数据集。
在现有视频网站中,视频封面有两个主要产生渠道:一个是上传视频的用户自己上传一张图片作为视频封面,再一个是前述的系统按预置时间间隔随机截取图片并从中选取若干幅图片提供给用户选择,用户从中选取一幅图片作为视频封面。一方面,用户自己上传的图片一般都是精心挑选的质比较好的图片,但是其中也不排除会存在一些看上去并不是很好的图片,我们可以将此类图片作为第一数据集(也可理解为是质量相对高的数据集);另一方面,系统由于是以随机方式截取图片,基于此,提供给用户做选择的图片质量会良莠不齐,但是其中也不排除会存在一些质量不错的图片,我们可以将此类图片做为第二数据集(也可以理解为质量相对低的数据集),在本实施例中,我们可以将第一数据集及第二数据集确定为用于机器学习模型训练的基础图片数据。
在获取到上述基础图片数据后,可进一步获取基础图片数据集中图片的色彩特征参数值(比如可包括色调值、饱和度值、亮度值、RGB值等),然后可根据所述色彩特征参数值将基础图片数据集中不符合预置条件的图片去除,以获得用于机器学习模型训练的图片数据。
视频封面的选取是一项主观性很强的工作,没有一个客观的评判准则,一张图片的质量好坏,往往与人的主观因素相关较大,不同的人会有不同的观点和偏好,比如丰富的色彩、醒目的人或物体、图片的清晰度、对比度、饱和度等等都是影响一幅图片好坏的因素。
因此,在一种实现方式中,我们可先获取基础图片数据集中图片的色彩特征参数值,该色彩特征参数值可包括HSV(Hue(色调),Saturation(饱和度),Luminence(亮度))值等,然后可通过获取到的色调值、饱和度值、亮度值等来计算图片的色彩特征数值,比如可包括图片的颜色饱和度、明亮度、对比度等色彩特征数值。当然,根据实际需要,也可以通过获取HSL(Hue(色相),Saturation(饱和度),Luminence(亮度))值等来替换上述HSV值,以进行后续步骤。
我们可预先根据以往的经验对上述色彩特征参数值进行色彩特征权重设置,比如:色彩饱和度权重为0.7、亮度权重为1、色调值权重为0.8,等等。然后,我们就可以根据预先设置的色彩特征权重,对每幅图片对应的色彩特征参数值进行加权和计算,以得到每幅图片对应的的色彩特征数值,也就是说,每幅图片对应一个色彩特征数值。
接下来,可根据每幅图片的色彩特征数值,将所述第一数据集中色彩特征数值低于第一预置分值的图片(色彩特征数值较低的、质量不好的图片)进行去除,以获得第一类型数据集(比如可为高质量数据),以及将所述第二数据集中色彩特征数值高于第二预置分值的图片(色彩特征数值较高的、质量不错的图片)进行去除,以获得第二类型数据集(比如可为低质量数据),并可将第一类型数据集及第二类型数据集作为用于机器学习模型训练的图片数据。
在另一种实现方式中,我们可先获取基础图片数据集中图片的色彩特征参数值,该色彩特征参数值可包括Hue(色调)值,Saturation(饱和度)值,RGB((Red(红),Green(绿),Blue(蓝))值,然后可分别通过获取到的色调值、饱和度值、RGB值对不符合预置条件的图片去除。
在具体实现时,可将所述第一数据集中色调值低于第一预置色调阈值的图片及所述第二数据集中色调值高于第二预置色调阈值的图片进行去除,也即,将第一数据集中色调相对较差的图片及第二数据集中色调相对较好的图片进行去除,以减少第一数据集及第二数据集中的图片数量,进而降低机器学习模型训练的运算量,减少运算时间,提升运算速度,同时还可提升第一数据集及第二数据集中图片的质量。
然后,还可将所述第一数据集中饱和度值低于第一预置饱和度阈值的图片及所述第二数据集中饱和度值高于第二预置饱和度阈值的图片进行去除,也即,将第一数据集中色彩饱和度相对较差的图片及第二数据集中色彩饱和度相对较好的图片进行去除,以减少第一数据集及第二数据集中的图片数量,进而降低机器学习模型训练的运算量,减少运算时间,提升运算速度,同时还可提升第一数据集及第二数据集中图片的质量。
此外,为了进一步提升第一数据集中的图片质量,该第一数据集图片中的黑白图片(也可认为是纯灰度图片)并非我们想要保留的,也就是说,黑白图片并不是我们想要提供给用户作为视频封面的图片,因此,根据所述RGB值将所述第一数据集中的黑白图片进行去除,也就是将第一数据集中不包含色度信息(比如,RGB中三个分量值均为0或RGB中三个分量值均为255等)的黑白图片进行去除,以此,可减少第一数据集中的图片数量,进而降低机器学习模型训练的运算量,减少运算时间,提升运算速度,同时还可提升第一数据集中图片的质量。
然后,将第一数据集以及第二数据集中保留下来的图片分别确定为第一类型数据集(即高质量数据集)及第二类型数据集(即低质量数据集),以作为用于机器学习模型训练的图片数据。
以此,可“清洗”掉现有技术中训练集中的“脏数据”(也就是不符合预置条件的图片),包括用户上传的图片中的质量不好的图片及系统随机截取的图片中质量不错的图片,以解决由于存在“脏数据”而导致训练出的机器学习模型达不到理想分类效果的问题。
在实际应用中,为了进一步降低机器学习模型训练的运算量,在根据预置的色彩特征权重,对每幅图片的色彩特征参数值做加权和计算之前,还可将每幅图片的尺寸调整为预置尺寸。
由于系统截取到的图片尺寸可能是比较大的,因此,可以在计算加权和之前对图片进行resize操作以统一调整图片的长宽比例,以符合机器学习模型的要求,比如,图片的原始尺寸为1000*2000,可通过resize操作将其尺寸调整为100*200,此操作可仅改变图片大小,而不会使图片变形失真,以此,可有效减少机器学习模型训练的运算量,提升运算速度。
在实际应用中,由于系统随机截取到的图片中会存在一些相似度很高的图片,我们还可将相似度过高的图片仅保留一张,以提高用于训练的数据集中图片的质量,并减少数据集中的图片数量。
在本实施例中,可在将所述第一数据集中色彩分值低于第一预置分值的图片及所述第二数据集中色彩分值高于第二预置分值的图片进行去除之后,对第一数据集及第二数据集中剩余图片之间的相似度进行判断,比如可通过图片的灰度直方图特征来判断图片之间的相似度,具体的,可先获取各图片的像素数据并生成各图片的直方图数据,然后对各图片的直方图数据进行归一化处理,再使用巴氏系数算法对直方图数据进行计算,最终得出各图片相似度值,其值范围可在[0,1]之间,其中,0可表示极其不同,1可表示极其相似(或相同),可根据获得到的各图片的相似度值进行相似度判断。
然后,可根据判断结果从相似度达到预置相似度阈值(比如相似度值不小于0.8)的图片中选取一幅图片进行保留,也就是说,在相似度高的图片中仅保留一幅(即其他幅图片都去除),以便将第一数据集及第二数据集中保留下来的图片分别作为所述第一类型数据集及第二类型数据集,以此,可进一步第一类型数据集及第二类型数据集中图片的数量,并且可保证第一类型数据集及第二类型数据集中图片特征覆盖的全面性,可进一步提高用于训练的数据集质量,减少图片数量,进而可降低机器学习模型训练的运算量,提升运算速度。
步骤2,将所述图片数据在预先训练好的卷积神经网络CNN的机器学习模型中做迭代训练,并在迭代训练过程中调整卷积神经网络的权值,以在预先训练好的CNN机器学习模型的基础上得到用于图片分类的CNN机器学习模型。
对于大数据集的机器学习模型的训练往往需要很长的时间,因此,我们可加入迁徙学习的思想,可采用Inception-v3定义的卷积神经网络(CNN)进行迁移学习,其中,Inception-v3是用来训练2012年ImageNet的Large Visual Recognition Challenge数据集,这是计算机视觉领域的一类标准任务,其可把整个图像集分为1000个类别,Inception-v3的top5错误率是3.46%。
在具体实现时,可在已训练好的Inception-v3定义的CNN机器学习模型中,通过不断的迭代训练及对神经网络权值的调整,以得到符合需要的用于图片分类的CNN机器学习模型,以增加模型的可扩展性和灵活性。
步骤3,对所述CNN机器学习模型进行评估。
在本实施例中,首先,可通过上述10%的验证数据集进行评估,但是,这种评估方法可能无法得知CNN机器学习模型是否有过拟合的情况,有可能出现在验证数据集上的准确率很高,但在实际应用中效果并不理想的问题,以最终影响CNN机器学习模型对图片分类的准确率。
因此,还可进行人工评估,比如可随机选取一个视频文件,并从视频文件中随机截取若干幅图片(比如100幅等),通过CNN机器学习模型对这100幅图片进行打分并进行排序,然后,选取得分高的几幅(比如得分序列中的前8幅)图片与得分低的几幅(比如得分序列中的后8幅)图片进行比较,也即将模型打分最高的几张图片和打分最低的几张图片进行比较,通过比较结果对CNN机器学习模型进行评估。
在上述人工评估的基础上,还可以进行二次人工评估,比如,可任意选取一个视频文件,可以按预置时间间隔(比如每2秒一次)截取几幅图片(比如8幅图片),将该随机截取的8幅图片与上述第一次人工评估过程中选取的得分最高的8幅图片进行比较,通过比较结果对机器学习模型进行再次评估。
以此,以先通过验证数据集进行评估,再通过两次人工评估的方式,可避免机器学习模型过拟合的情况,以实现对CNN机器学习模型进行更为有效的评估,得到理想的评估效果,进而保证CNN机器学习模型对图片分类的准确率。
步骤4,若评估通过,比如可为通过验证数据集进行评估的精度可以达到第一预置百分比(比如该第一预置百分比为85%),且通过人工评估认为通过CNN机器学习模型打分后得到的高分图片更适合做为视频封面的比例可以达到第二预置百分比(比如该第二预置百分比为90%),即为评估通过,则训练结束并将所述CNN机器学习模型作为训练好的用于图片分类的CNN机器学习模型。
步骤5,若评估未通过,比如可为通过验证数据集进行评估的精度未达到第一预置百分比,且通过人工评估认为通过CNN机器学习模型打分后得到的高分图片更适合做为视频封面的比例未达到第二预置百分比),即为评估未通过。
此种情况下,则可对CNN机器学习模型所采用算法的参数进行调整,具体可根据训练过程的收敛度、训练的准确度等情况进行调整,比如可使用google的TensorBoard直观的得到神经网络是否收敛的情况,其中,Tensorboard为Tensorflow的图形化、可视化工具,Tensorboard可显示Tensorflow中由tensor和flow构成的静态图,以及训练过程中精度、偏差等分析的动态图等。
对于上述算法参数的调整,主要是对学习速率(learning rate)、批处理大小(batch size)、迭代次数(step)等参数的调整。比如,在参数调整过程中,如果学习速率过大,可能会使得卷积神经网络不收敛,处于震荡状态,此时需要减小学习速率;如果学习速率过小,收敛速度较慢,较多的迭代次数才能使得卷积神经网络达到局部极值,此时可设置较大的迭代次数或增加学习速率;另外,批处理大小也会影响到收敛情况,也可通过对批处理大小的调整以调整收敛情况。也就是说,可通过TensorBoard查看学习的详细情况,分析机器学习模型中所采用算法的参数设置不合理的地方并进行相应的调整,通过参数调整过程,以使得机器学习模型最终收敛并提升训练准确率。
在参数调整后,将所述图片数据在算法参数调整后的CNN机器学习模型中继续做迭代训练,并在迭代训练过程中调整卷积神经网络的权值,直至得到的用于图片分类的CNN机器学习模型评估通过。
S103,根据排序将得分高的预置幅数图片作为视频封面的候选图片提供给用户,以便用户从所述候选图片中进行视频封面的选择。
其中,排序可以为升序(得分从低到高)或降序(分数从高到低),在本实施例中,可选用以降序进行排序,可从序列的最前部选取得分高的预置幅数图片(比如序列中的前8幅)作为视频封面的候选图片提供给用户,以便用户从这8幅图片中选取一幅图片作为视频封面。
在具体实现时,当用户对上述候选图片中(也就是上述8幅图片中)任一图片进行点击操作时,即为接收到用户对所述图片的选择指令,可根据所述选择指令,将用户选择的图片确定为视频文件的视频封面。
本发明人在研发过程中进行了大量的实验,按照上述对机器学习模型的迭代训练方法得到了6版用于图片打分的CNN机器学习模型,通过验证数据集进行评估的精度达到89.9%,通过人工评估认为通过CNN机器学习模型打分后得到的高分图片更适合做为视频封面的比例达到93.3%,通过CNN机器学习模型打分并提供的图片具有清晰度高、对比度好、色彩鲜艳丰富、含有有意义的对象(人物或物体等)等特点,比传统的视频封面选取方法更加高质高效。
参看图3-1至3-3为发明人试验的部分对比图(其中颜色并未示出),在图3-1至3-3中,上方8幅图片为打分最高的8幅图片,下方为同一视频中打分最低的8幅图片。
通过本申请实施例,当接收到用户上传的视频文件后,可根据视频文件中相邻帧内容的变化情况确定场景变换关键帧并对所述场景变换帧对应的图片进行截取,然后可通过预先训练好的用于图片分类的机器学习模型为截取到的图片进行打分并排序,再根据排序将得分高的预置幅数图片作为视频封面的候选图片提供给用户,以便用户从所述候选图片中进行视频封面的选择。以此,既可保证不遗漏视频文件中的所有重要场景,又可降低提供的视频封面候选图片中的图片重复度,提升候选图片的质量,更便于用户从中选取到更为适合的视频封面。
与前述实施例中提供的视频封面的提供方法相对应,本申请实施例还提供了一种视频封面的提供装置,参见图4,该装置可以包括:
截图单元41,用于接收用户上传的视频文件,并根据视频文件中相邻帧内容的变化情况确定场景变换关键帧并对所述场景变换关键帧对应的图片进行截取。
在具体实现时,所述截图单元41,可具体用于:
判断视频文件中相邻两帧内容变化是否超出预置的变化阈值;
将超出预置变化阈值的帧确定为场景变换关键帧;
对场景变换关键帧对应的图片进行截取,并将截取到的图片组成场景变换关键帧图片集合。
打分单元42,用于通过预先训练好的用于图片分类的机器学习模型为截取到的图片进行打分并排序。
候选图片提供单元43,用于根据排序将得分高的预置幅数图片作为视频封面的候选图片提供给用户,以便用户从所述候选图片中进行视频封面的选择。
此外,所述装置,还可包括:
指令接收单元,用于接收用户对所述候选图片中任一图片的选择指令;
视频封面确定单元,用于将用户选择的图片确定为视频文件的视频封面。
在本实施例中,对所述打分单元42中使用的用于图片分类的机器学习模型的训练过程,可包括如下步骤:
步骤1,确定用于机器学习模型训练的图片数据。
在具体实现时,可先获取基础图片数据集,所述基础图片数据集包括:含有用户上传图片的第一数据集及含有按预置时间间隔随机截取的图片的第二数据集。
然后,可获取基础图片数据集中图片的色彩特征参数值,比如包括所述色彩特征参数值包括色调值、饱和度值、亮度值、RGB值等,再根据所述色彩特征参数值将基础图片数据集中不符合预置条件的图片去除,以获得用于机器学习模型训练的图片数据。
在一种实现方式中,可在获取基础图片数据集中图片的色彩特征参数值后,该色彩特征参数值可包括HSV(Hue(色调),Saturation(饱和度),Luminence(亮度)值,根据预置的色彩特征权重,对每幅图片的色彩特征参数值做加权和计算,以获得每幅图片对应的色彩特征数值,然后将所述第一数据集中色彩特征数值低于第一预置分值的图片及所述第二数据集中色彩特征数值高于第二预置分值的图片进行去除,分别获得第一类型数据集及第二类型数据集,以作为用于机器学习模型训练的图片数据。
在另一种实现方式中,比如,可在获取基础图片数据集中图片的色彩特征参数值后,该色彩特征参数值可包括Hue(色调)值,Saturation(饱和度)值,RGB((Red(红),Green(绿),Blue(蓝))值,将所述第一数据集中色调值低于第一预置色调阈值的图片及所述第二数据集中色调值高于第二预置色调阈值的图片进行去除,接下来再将所述第一数据集中饱和度值低于第一预置饱和度阈值的图片及所述第二数据集中饱和度值高于第二预置饱和度阈值的图片进行去除。
然后,还可根据所述RGB值将所述第一数据集中的黑白图片进行去除,也就是将第一数据集中不包含色度信息(比如,RGB中三个分量值均为0或RGB中三个分量值均为255等)的黑白图片进行去除,进一步提高数据中图片的质量,降低模型训练的运算量,减少计算时间,提升运算速度。
最后,将第一数据集以及第二数据集中保留下来的图片分别确定为第一类型数据集及第二类型数据集,以作为用于机器学习模型训练的图片数据。
此外,为了进一步降低模型训练的运算量,提升运算速度,还可在根据预置的色彩特征权重,对每幅图片的色彩特征参数值做加权和计算之前,将每幅图片的尺寸调整为预置尺寸,以将每幅图片都调整为模型要求的尺寸。
由于在第一数据集及第二数据集中可能存在一些相似度很高的图片,为了提高数据集中数据的质量,减少图片数量,降低模型训练的运算量,进而提升运算速度,还可在将所述第一数据集中色彩分值低于第一预置分值的图片及所述第二数据集中色彩分值高于第二预置分值的图片进行去除之后,对第一数据集及第二数据集中剩余图片之间的相似度进行判断,并根据判断结果从相似度达到预置相似度阈值的图片中选取一幅图片进行保留,以便将第一数据集及第二数据集中保留下来的图片分别作为所述第一类型数据集及第二类型数据集,以此,可得到重复度低、质量更好的数据集。
步骤2,将所述图片数据在预先训练好的卷积神经网络CNN的机器学习模型中做迭代训练,并在迭代训练过程中调整卷积神经网络的权值,以在预先训练好的CNN机器学习模型的基础上得到用于图片分类的CNN机器学习模型。
其中,所述卷积神经网络可为Inception-v3定义的卷积神经网络。
步骤3,对所述CNN机器学习模型进行评估。
步骤4,若评估通过,则训练结束并将所述用于图片分类的CNN机器学习模型作为训练好的用于图片分类的CNN机器学习模型;
步骤5,评估未通过,则对用于图片分类的CNN机器学习模型中采用算法的参数进行调整,以便将所述图片数据在参数调整后的用于图片分类的CNN机器学习模型中继续做迭代训并在迭代训练过程中调整卷积神经网络的权值,直至得到的用于图片分类的CNN机器学习模型评估通过。
通过本申请实施例,当接收到用户上传的视频文件后,可根据视频文件中相邻帧内容的变化情况确定场景变换关键帧并对所述场景变换帧对应的图片进行截取,然后可通过预先训练好的用于图片分类的机器学习模型为截取到的图片进行打分并排序,再根据排序将得分高的预置幅数图片作为视频封面的候选图片提供给用户,以便用户从所述候选图片中进行视频封面的选择。以此,既可保证不遗漏视频文件中的所有重要场景,又可降低提供的视频封面候选图片中的图片重复度,提升候选图片的质量,更便于用户从中选取到更为适合的视频封面。
通过以上的实施方式的描述可知,本领域的技术人员可以清楚地了解到本申请可借助软件加必需的通用硬件平台的方式来实现。基于这样的理解,本申请的技术方案本质上或者说对现有技术做出贡献的部分可以以软件产品的形式体现出来,该计算机软件产品可以存储在存储介质中,如ROM/RAM、磁碟、光盘等,包括若干指令用以使得一台计算机设备(可以是个人计算机,服务器,或者网络设备等)执行本申请各个实施例或者实施例的某些部分所述的方法。
本说明书中的各个实施例均采用递进的方式描述,各个实施例之间相同相似的部分互相参见即可,每个实施例重点说明的都是与其他实施例的不同之处。尤其,对于系统或系统实施例而言,由于其基本相似于方法实施例,所以描述得比较简单,相关之处参见方法实施例的部分说明即可。以上所描述的系统及系统实施例仅仅是示意性的,其中所述作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到多个网络单元上。可以根据实际的需要选择其中的部分或者全部模块来实现本实施例方案的目的。本领域普通技术人员在不付出创造性劳动的情况下,即可以理解并实施。
以上对本申请所提供的视频封面的提供方法及装置,进行了详细介绍,本文中应用了具体个例对本申请的原理及实施方式进行了阐述,以上实施例的说明只是用于帮助理解本申请的方法及其核心思想;同时,对于本领域的一般技术人员,依据本申请的思想,在具体实施方式及应用范围上均会有改变之处。综上所述,本说明书内容不应理解为对本申请的限制。
- 还没有人留言评论。精彩留言会获得点赞!