将现实世界比例应用于虚拟内容的制作方法
背景
混合现实是一种允许将虚拟图像与现实世界物理环境相混合的技术。用户可佩戴透视、头戴式、混合现实显示设备来查看显示在用户的视野中的现实对象和虚拟对象的混合图像。创建虚拟内容并与虚拟内容一起工作可能是有挑战性的,因为虚拟内容不具有固有的单位比例(scale)。内容创建者通常在创建内容时定义其自己的比例,并期望他人使用相同的比例来消费该内容。这进而导致难以理解虚拟内容比例和现实世界比例之间的关系。其在尝试使用有限的2d显示器来查看虚拟内容时还要复杂,并且还可使得进行详尽的内容编辑变得困难。
概述
本技术的各实施例涉及一种用于从虚拟内容内的查看视角查看、探索、体验虚拟内容以及与虚拟内容进行交互的系统和方法。实际上,用户被缩小并被插入到虚拟内容中,使得用户可体验虚拟内容的实物大小视图。用于在虚拟环境内创建虚拟对象的系统一般包括耦合至至少一个处理单元的透视、头戴式显示设备。处理单元与(诸)头戴式显示设备协作能够显示用户正作用于的或以其他方式希望体验的虚拟工件。
本技术允许用户选择查看虚拟工件的模式,在本文中被称为沉浸模式。在沉浸模式中,用户能够选择虚拟化身,该虚拟化身可以是用户放置在虚拟工件中或虚拟工件附近的某处的该用户的经缩小的模型。那时,向用户显示的视图是来自该化身的视角的视图。实际上,用户被收缩并沉浸在虚拟内容中。用户可在实物大小比例上查看、探索、体验虚拟内容中的工件以及与其进行交互,例如与以同用户在现实世界中的大小一比一的大小比例出现的工件进行交互。
除了得到对虚拟工件的实物大小视角外,以沉浸模式查看虚拟工件还在用户与工件的交互方面提供了更大的精度。例如,在从实际的现实世界空间查看虚拟工件时(在本文中被称为现实世界模式),用户从多个小虚拟件中选择一个小虚拟件并与其进行交互的能力可受到限制。然而,当处于沉浸模式时,用户正在查看工件的实物大小的比例,并且能够以更大的精度与各小件进行交互。
提供本概述以便以简化的形式介绍以下在详细描述中进一步描述的一些概念。本概述并非旨在标识出要求保护的主题的关键特征或必要特征,亦非旨在用作辅助确定要求保护的主题的范围。
附图简述
图1是包括现实和虚拟对象的虚拟现实环境的图解。
图2是头戴式显示单元的一个实施例的透视图。
图3是头戴式显示单元的一个实施例的一部分的侧视图。
图4是头戴式显示单元的各组件的一个实施例的框图。
图5是与头戴式显示单元相关联的处理单元的各组件的一个实施例的框图。
图6是与头戴式显示单元相关联的处理单元的各软件组件的一个实施例的框图。
图7是示出与本系统的头戴式显示单元相关联的一个或多个处理单元的操作的流程图。
图8-12是图7的流程图中所示的各步骤的示例的更详细的流程图。
图13-16解说用户通过现实世界模式查看虚拟环境中的工件的示例。
图17-19解说根据本技术的各方面的从沉浸模式内查看到的虚拟环境的示例。
详细描述
现在将参考各附图描述本技术的各实施例,这些图一般涉及用于在混合现实环境中通过虚拟对象的沉浸式视图来查看、探索、体验这些虚拟对象并与其进行交互的系统和方法(本文中也被称为全息图)。在各实施例中,该系统和方法可使用移动混合现实组装件来生成三维混合现实环境。混合现实组装件包括耦合到具有相机和显示元件的头戴式显示设备(或其他合适的装置)的移动处理单元。
处理单元可执行经缩放的沉浸软件应用,该应用允许用户通过将用户控制的化身插入到虚拟内容中并从该化身的视角显示该虚拟内容来使他或她自己沉浸在该虚拟内容中。如以下所描述的,用户可用现实世界模式和沉浸模式两者来与虚拟工件的虚拟对象进行交互。
头戴式显示设备的显示元件在一定程度上是透明的,使得用户可透过该显示元件看到在该用户的视野(fov)内的现实世界对象。该显示元件还提供将虚拟图像投影到该用户的fov中以使得所述虚拟图像也可出现在现实世界对象旁边的能力。在现实世界模式中,系统自动地跟踪用户所看之处,从而该系统可确定将虚拟图像插入到该用户的fov中的何处。一旦该系统知晓要将该虚拟图像投影至何处,就使用该显示元件投影该图像。
在沉浸模式中,用户将用户控制的化身放置在虚拟内容中。该虚拟内容包括(诸)虚拟工件和附属于(诸)虚拟工件的区域。虚拟工件可以是部分构造虚拟对象,或在其正被创建时用户可查看到的对象的集合。虚拟工件也可以是完整虚拟对象,或用户正在查看的对象的集合。
当以沉浸模式操作时,系统跟踪用户正在看现实世界中的何处,并随后使用经缩放的沉浸矩阵将虚拟内容的经显示视图变换到虚拟化身的经缩放的视角。用户在现实世界中的移动导致在沉浸式视图中化身的查看视角的相应经缩放改变。这些特征在以下被解释。
在各实施例中,处理单元可构建包括房间或其它环境中的用户、现实世界对象和虚拟三维对象的x、y、z笛卡尔位置的环境的三维模型。该三维模型可由移动处理单元自身或者同其他处理设备合作工作来生成,如此后所解释的。
在现实世界模式中,经由头戴式显示设备从该头戴式显示设备的视角以及用户自己的眼睛向用户显示虚拟内容。该视角在本文中被称为现实世界视图。在沉浸模式中,查看视角被缩放、旋转、转换到虚拟内容内的位置和定向。该查看视角在本文中被称为沉浸视图。
从概念上讲,沉浸视图是一旦化身被用户定位在虚拟内容内并在虚拟内容内被设定大小,该化身将“看见”的视图。用户可如以下所解释的那样移动化身,使得化身在沉浸视图中“看见”的虚拟内容改变。因此,在本文中,有时沉浸视图是按照化身对虚拟内容的视图或视角来描述的。然而,从软件视角来说,如以下所解释的,沉浸视图是从笛卡尔空间中的点xi,yi,zi开始的视锥体以及从该点开始的单位向量(俯仰i,偏航i和滚转i)。如以下还解释的,那个点和单位向量是从由用户在虚拟内容中设置的化身的初始位置和定向以及由用户设置的化身的经缩放的大小中导出的。
如以下所描述的,用户可用现实世界模式和沉浸模式两者来与虚拟工件的虚拟对象进行交互。如本文中所使用的,术语“交互”包含物理和口头姿势两者。物理姿势包括用户使用他或她的手指、手和/或其他身体部位执行由混合现实系统识别为使该系统执行预定义动作的用户命令的预定义姿势。这样的预定义姿势可包括但不限于头部瞄准、眼睛瞄准(注视)、指向、抓握、推动、重设大小和塑造虚拟对象。
物理交互可进一步包括用户对虚拟对象的接触。例如,用户可将他或她的手定位在三维空间中与虚拟对象的位置相对应的位置处。用户可此后执行诸如抓握或推动之类的姿势,该姿势被混合现实系统解释,并且相应的动作对虚拟对象执行,例如该对象可被抓握并可此后被拿在用户的手中,或者该对象可被推动并且被移动与推动运动的程度相对应的量。作为进一步示例,用户可通过推动虚拟按钮来与虚拟按钮进行交互。
用户还可以用他的或她的眼睛来与虚拟对象物理地交互。在一些实例中,眼睛注视数据标识用户正关注于fov中的何处,并且因而可以标识用户正在看某一特定虚拟对象。持续的眼睛注视,或者一次眨眼或眨眼序列,因而可以是用户借助来选择一个或多个虚拟对象的物理交互。
用户可替换地或附加地使用口头姿势来与虚拟对象进行交互,口头姿势为诸如举例来说被该混合现实系统识别为使该系统执行预定义动作的用户命令的口述单词或短语。口头姿势可连同物理姿势一起使用以与虚拟环境中的一个或多个虚拟对象交互。
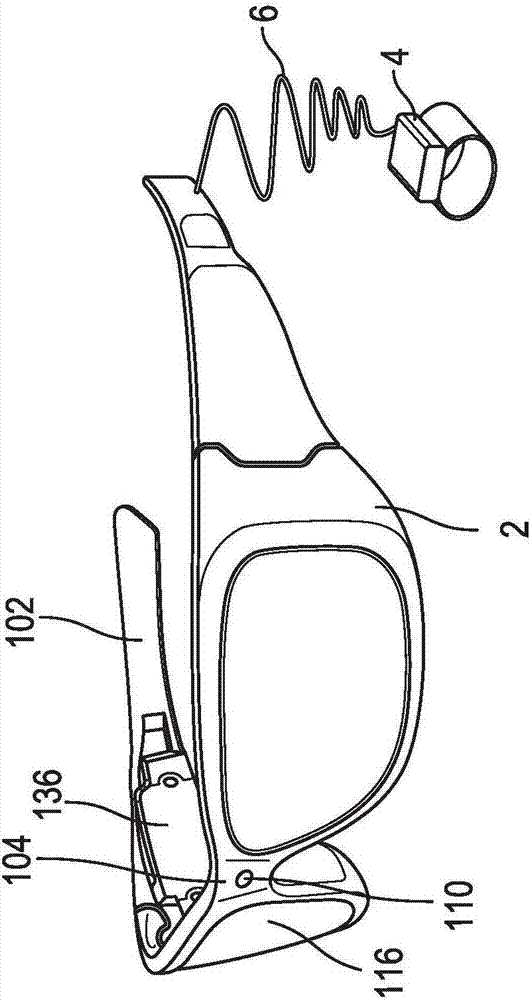
图1解说了用于通过将虚拟内容21与每一用户的fov内的现实内容23融合来向用户提供混合现实体验的混合现实环境10。图1示出两个用户18a和18b,每一用户均佩戴头戴式显示设备2,并且每一用户均在查看调整到其视角的虚拟内容21。应理解,图1中示出的特定虚拟内容仅作为示例,并且可以是形成如以下所解释的虚拟工件的各种各样的虚拟对象中的任一者。如图2中所示出的,每一头戴式显示设备2可包括其自己的处理单元4或例如经由软线6与其自己的处理单元4通信。头戴式显示设备可替换地与处理单元4无线地通信。在进一步实施例中,处理单元4可被集成到头戴式显示设备2中。在一个实施例中为眼镜形状的头戴式显示设备2被佩戴在用户的头上,使得用户可以透过显示器进行观看,并且从而具有该用户前方的空间的实际直接视图。下面提供头戴式显示设备2和处理单元4的更多细节。
在处理单元4没有被并入头戴式显示设备2中的情况下,处理单元4可以是例如佩戴在用户的手腕上或储放在用户的口袋中的小型便携式设备。处理单元4可包括执行诸如游戏应用、非游戏应用等应用的硬件组件和/或软件组件。在一个实施例中,处理单元4可包括可执行存储在处理器可读存储设备上的用于执行本文中描述的过程的指令的处理器,如标准化处理器、专用处理器、微处理器等。在各实施例中,处理单元4与一个或多个远程计算系统无线地(例如,wifi、蓝牙、红外、或其他无线通信手段)通信。这些远程计算系统可包括计算机、游戏系统或控制台或远程服务提供者。
头戴式显示设备2和处理单元4可彼此协作以在混合现实环境10中向用户呈现虚拟内容21。以下解释了用于构建虚拟对象的本系统的细节。现将参考图2-6来解释使得能够构建虚拟对象的移动头戴式显示设备2和处理单元4的细节。
图2和3示出了头戴式显示设备2的透视图和侧视图。图3仅仅示出了头戴式显示设备2的右侧,其包括具有镜腿102和鼻梁104的那部分。在鼻梁104中置入了话筒110用于记录声音以及将音频数据传送给处理单元4,如下所述。在头戴式显示设备2的前方是朝向房间的视频相机112,该视频相机112可以捕捉视频和静止图像。那些图像被传送至处理单元4,如下所述。
头戴式显示设备2的镜架的一部分将围绕显示器(显示器包括一个或多个透镜)。为了示出头戴式显示设备2的组件,未描绘围绕显示器的镜架部分。该显示器包括光导光学元件115、不透明滤光器114、透视透镜116和透视透镜118。在一个实施例中,不透明度滤光器114处于透视透镜116之后并与其对齐,光导光学元件115处于不透明度滤光器114之后并与其对齐,而透视透镜118处于光导光学元件115之后并与其对齐。透视透镜116和118是眼镜中使用的标准镜片,并且可根据任何验光单(包括无验光单)来制作。在一个实施例中,透视透镜116和118可由可变处方透镜取代。不透明度滤光器114滤除自然光(要么以每像素为基础,要么均匀地)以增强虚拟图像的对比度。光导光学元件115将人造光引导到眼睛。下面提供不透光滤光器114和光导光学元件115的更多细节。
在镜腿102处或镜腿102内安装有图像源,该图像源(在一个实施例中)包括用于对虚拟图像进行投影的微显示器120、以及用于将图像从微显示器120引导到光导光学元件115中的透镜122。在一个实施例中,透镜122是准直透镜。
控制电路136提供支持头戴式显示设备2的其他组件的各种电子装置。控制电路136的更多细节在下文参照图4提供。处于镜腿102内部或安装到镜腿102的是耳机130、惯性测量单元132、以及温度传感器138。在图4中所示的一个实施例中,惯性测量单元132(或imu132)包括惯性传感器,诸如三轴磁力计132a、三轴陀螺仪132b以及三轴加速度计132c。惯性测量单元132感测头戴式显示设备2的位置、定向和突然加速度(俯仰、滚转和偏航)。除了磁力计132a、陀螺仪132b和加速度计132c之外或者取代磁力计132a、陀螺仪132b和加速度计132c,imu132还可包括其他惯性传感器。
微显示器120通过透镜122来投影图像。存在着可被用于实现微显示器120的不同的图像生成技术。例如,微显示器120可以使用透射投影技术来实现,其中光源由光学活性材料来调制,用白光从背后照亮。这些技术通常使用具有强大背光和高光能量密度的lcd型显示器来实现。微显示器120还可使用反射技术来实现,其中外部光被光学活性材料反射并调制。取决于该技术,照明是由白光源或rgb源来向前点亮的。数字光处理(dlp)、硅上液晶(lcos)、以及来自qualcomm有限公司的
光导光学元件115将来自微显示器120的光传送到佩戴头戴式显示设备2的用户的眼睛140。光导光学元件115还允许如箭头142所描绘的那样将光从头戴式显示设备2的前方通过光导光学元件115传送到眼睛140,从而除了接收来自微显示器120的虚拟图像之外还允许用户具有头戴式显示设备2的前方的空间的实际直接视图。从而,光导光学元件115的壁是透视的。光导光学元件115包括第一反射表面124(例如镜面或其他表面)。来自微显示器120的光穿过透镜122并入射在反射表面124上。反射表面124反射来自微显示器120的入射光,使得光通过内反射被陷在包括光导光学元件115的平面基底内。在基底的表面上进行若干次反射之后,被陷的光波到达选择性反射表面126的阵列。注意,五个表面中只有一个表面被标记为126以防止附图太过拥挤。反射表面126将从基底出射并入射在这些反射表面上的光波耦合进用户的眼睛140。
由于不同光线将以不同视角传播并弹离衬底的内部,因此这些不同的光线将以不同视角击中各个反射面126。因此,不同光线将被所述反射面中的不同反射面从基底反射出。关于哪些光线将被哪个表面126从基底反射出的选择是通过选择表面126的合适视角来设计的。光导光学元件的更多细节可在于2008年11月20日公开的题为“substrate-guidedopticaldevices”(基底导向的光学设备)的美国专利公开号2008/0285140中找到。在一个实施例中,每只眼睛将具有其自己的光导光学元件115。当头戴式显示设备2具有两个光导光学元件时,每只眼睛都可以具有其自己的微显示器120,该微显示器120可以在两只眼睛中显示相同图像或者在两只眼睛中显示不同图像。在另一实施例中,可以存在将光反射到两只眼睛中的一个光导光学元件。
与光导光学元件115对齐的不透明滤光器114要么均匀地、要么以每像素为基础来选择性地阻挡自然光,以免其穿过光导光学元件115。于2010年9月21日提交的bar-zeev等人的题为“opacityfilterforsee-throughmounteddisplay(用于透视安装显示器的不透明度滤光器)”的美国专利公开号2012/0068913中提供了不透明度滤光器114的示例的细节。然而,一般而言,不透明滤光器114的一实施例可以是透视lcd面板、电致变色膜(electrochromicfilm)或能够充当不透明滤光器的类似设备。不透明度滤光器114可以包括致密的像素网格,其中每个像素的透光率能够在最小和最大透光率之间被单独地控制。尽管0-100%的透光率范围是理想的,然而更受限的范围也是可接受的,诸如例如每像素约50%到90%。
在用代理为现实世界对象进行z-缓冲(z-buffering)之后,可以使用来自渲染流水线的阿尔法值的掩码(mask)。当系统为混合现实显示器渲染场景时,该系统记录哪些现实世界对象处于哪些虚拟对象之前,如同下面解释的。如果虚拟对象处于现实世界对象之前,则不透明度对于该虚拟对象的覆盖区域而言可以是开启的。如果虚拟对象(虚拟地)处于现实世界对象之后,则不透明度以及该像素的任何颜色都可被关闭,使得对于现实光的该相应区域(其大小为一个像素或更多)而言,用户将会看到现实世界对象。覆盖将是以逐像素为基础的,所以该系统可以处置虚拟对象的一部分处于现实世界对象之前、该虚拟对象的一部分处于现实世界对象之后、以及该虚拟对象的一部分与现实世界对象相重合的情况。对这种用途而言,最期望的是能够以低的成本、功率和重量来从0%开始直至100%不透明度的显示器。此外,不透明度滤光器可以比如用彩色lcd或用诸如有机led等其他显示器来以彩色进行呈现。
头戴式显示设备2还包括用于跟踪用户的眼睛的位置的系统。如下面将会解释的那样,该系统将跟踪用户的位置和定向,使得该系统可以确定用户的fov。然而,人类将不会感知到他们前方的一切。而是,用户的眼睛将被导向该环境的一子集。因此,在一个实施例中,该系统将包括用于跟踪用户的眼睛的位置以便细化对该用户的fov的测量的技术。例如,头戴式显示设备2包括眼睛跟踪组件134(图3),该眼睛跟踪组件134具有眼睛跟踪照明设备134a和眼睛跟踪相机134b(图4)。在一个实施例中,眼睛跟踪照明设备134a包括一个或多个红外(ir)发射器,这些红外发射器向眼睛发射ir光。眼睛跟踪相机134b包括一个或多个感测反射的ir光的相机。通过检测角膜的反射的已知成像技术,可以标识出瞳孔的位置。例如,参见于2008年7月22日颁发的题为“headmountedeyetrackinganddisplaysystem”(头戴式眼睛跟踪和显示系统)的美国专利号7,401,920。此类技术可以定位眼睛的中心相对于跟踪相机的位置。一般而言,眼睛跟踪涉及获得眼睛的图像并使用计算机视觉技术来确定瞳孔在眼眶内的位置。在一个实施例中,跟踪一只眼睛的位置就足够了,因为双眼通常一致地移动。然而,单独地跟踪每只眼睛是可能的。
在一个实施例中,该系统将使用以矩形布置的4个irled和4个ir光电检测器,使得在头戴式显示设备2的透镜的每个角处存在一个irled和ir光电检测器。来自led的光从眼睛反射离开。由在4个ir光电检测器中的每个处所检测到的红外光的量来确定瞳孔方向。也就是说,眼睛中眼白相对于眼黑的量将确定对于该特定光电检测器而言从眼睛反射离开的光量。因此,光电检测器将具有对眼睛中的眼白或眼黑的量的度量。从这4个采样中,该系统可确定眼睛的方向。
另一替代方案是如上面所讨论的那样使用4个红外led,但是在头戴式显示设备2的透镜的一侧上使用一个红外ccd。ccd可使用小镜子和/或透镜(鱼眼),以使得ccd可对来自眼镜框的可见眼睛的多达75%成像。然后,该ccd将感测图像并且使用计算机视觉来找出该图像,就像上文所讨论的那样。因此,尽管图3示出了具有一个ir发射器的一个部件,但是图3的结构可以被调整为具有4个ir发射器和/或4个ir传感器。也可以使用多于或少于4个的ir发射器和/或多于或少于4个的ir传感器。
用于跟踪眼睛的方向的另一实施例基于电荷跟踪。此概念基于以下观察:视网膜携带可测量的正电荷而角膜具有负电荷。传感器被安装在用户的耳朵旁(靠近耳机130)以检测眼睛在转动时的电势并且高效地实时读出眼睛正在干什么。也可以使用用于跟踪眼睛的其他实施例。
图3仅仅示出了头戴式显示设备2的一半。完整的头戴式显示设备可包括另一组透视透镜、另一不透明度滤光器、另一光导光学元件、另一微显示器120、另一透镜122、面向房间的相机、眼睛跟踪组装件134、耳机、和温度传感器。
图4是描绘了头戴式显示设备2的各个组件的框图。图5是描述处理单元4的各种组件的框图。头戴式显示设备2(其组件在图4中被描绘)被用于通过将一个或多个虚拟图像无缝地与用户对现实世界的视图融合来向用户提供虚拟体验。另外,图4的头戴式显示设备组件包括跟踪各种状况的许多传感器。头戴式显示设备2将从处理单元4接收关于虚拟图像的指令,并且将把传感器信息提供回给处理单元4。处理单元4将确定在何处以及在何时向用户提供虚拟图像并相应地将指令发送给图4的头戴式显示设备。
图4的组件中的一些(例如朝向房间的相机112、眼睛跟踪相机134b、微显示器120、不透明滤光器114、眼睛跟踪照明134a、耳机130和温度传感器138)是以阴影示出的,以指示这些设备中的每个都存在两个,其中一个用于头戴式显示设备2的左侧,而一个用于头戴式显示设备2的右侧。图4示出与电源管理电路202通信的控制电路200。控制电路200包括处理器210、与存储器214(例如d-ram)进行通信的存储器控制器212、相机接口216、相机缓冲器218、显示驱动器220、显示格式化器222、定时生成器226、显示输出接口228、以及显示输入接口230。
在一个实施例中,控制电路200的组件都通过专用线路或一个或多个总线彼此进行通信。在另一实施例中,控制电路200的各组件与处理器210通信。相机接口216提供到两个朝向房间的相机112的接口,并且将从朝向房间的相机所接收到的图像存储在相机缓冲器218中。显示驱动器220将驱动微显示器120。显示格式化器222向控制不透明滤光器114的不透明度控制电路224提供关于微显示器120上所正显示的虚拟图像的信息。定时生成器226被用来为该系统提供定时数据。显示输出接口228是用于将图像从朝向房间的相机112提供给处理单元4的缓冲器。显示输入接口230是用于接收诸如要在微显示器120上显示的虚拟图像之类的图像的缓冲器。显示输出接口228和显示输入接口230与作为到处理单元4的接口的带接口232通信。
电源管理电路202包括电压调节器234、眼睛跟踪照明驱动器236、音频dac和放大器238、话筒前置放大器和音频adc240、温度传感器接口242、以及时钟发生器244。电压调节器234通过带接口232从处理单元4接收电力,并将该电力提供给头戴式显示设备2的其他组件。每个眼睛跟踪照明驱动器236都如上面所述的那样为眼睛跟踪照明134a提供ir光源。音频dac和放大器238向耳机130输出音频信息。话筒前置放大器和音频adc240提供用于话筒110的接口。温度传感器接口242是用于温度传感器138的接口。电源管理电路202还向三轴磁力计132a、三轴陀螺仪132b以及三轴加速度计132c提供电能并从其接收回数据。
图5是描述处理单元4的各种组件的框图。图5示出与电源管理电路306通信的控制电路304。控制电路304包括:中央处理单元(cpu)320、图形处理单元(gpu)322、高速缓存324、ram326、与存储器330(例如d-ram)进行通信的存储器控制器328、与闪存334(或其他类型的非易失性存储)进行通信的闪存控制器332、通过带接口302和带接口232与头戴式显示设备2进行通信的显示输出缓冲器336、通过带接口302和带接口232与头戴式显示设备2进行通信的显示输入缓冲器338、与用于连接到话筒的外部话筒连接器342进行通信的话筒接口340、用于连接到无线通信设备346的pciexpress接口、以及(一个或多个)usb端口348。在一个实施例中,无线通信设备346可包括启用wi-fi的通信设备、蓝牙通信设备、红外通信设备等。usb端口可以用于将处理单元4对接到处理单元计算系统22,以便将数据或软件加载到处理单元4上以及对处理单元4进行充电。在一个实施例中,cpu320和gpu322是用于确定在何处、何时以及如何向用户的视野内插入虚拟三维对象的主要力量。以下提供更多的细节。
电源管理电路306包括时钟发生器360、模数转换器362、电池充电器364、电压调节器366、头戴式显示器电源376、以及与温度传感器374进行通信的温度传感器接口372(其可能位于处理单元4的腕带上)。模数转换器362被用于监视电池电压、温度传感器,以及控制电池充电功能。电压调节器366与用于向该系统提供电力的电池368进行通信。电池充电器364被用来在从充电插孔370接收到电力时(通过电压调节器366)对电池368进行充电。hmd电源376向头戴式显示设备2提供电力。
图6解说了包括显示设备2的面向房间的相机112和处理单元4上的一些软件模块的移动混合现实组装件30的高级框图。这些软件模块中的一些或全部可替换地被实现在头戴式显示设备2的处理器210上。如图所示,面向房间的相机112向头戴式显示设备2中的处理器210提供图像数据。在一个实施例中,面向房间的相机112可包括深度相机、rgb相机和ir光组件以捕捉场景的图像数据。如以下所解释的,面向房间的相机112可包括少于全部的这些组件。
例如使用飞行时间分析,ir光组件可将红外光发射到场景上,并且可随后使用传感器(未示出)用例如深度相机和/或rgb相机来检测从场景中的一个或多个对象的表面反向散射的光。在一些实施例中,可以使用脉冲红外光,使得可以测量出射光脉冲与相应入射光脉冲之间的时间,并且将其用于确定从面向房间的相机112到场景中的对象(包括例如用户的手)上的特定位置的物理距离。另外,在其他示例实施例中,可以将出射光波的相位与入射光波的相位相比较来确定相移。然后可以使用该相移来确定从捕捉设备到目标或对象上的特定位置的物理距离。
根据另一示例性实施例,可以使用飞行时间分析来通过经由包括例如快门式光脉冲成像在内的各种技术分析反射光束随时间的强度来间接地确定从面向房间的相机112到对象上的特定位置的物理距离。
在另一示例实施例中,面向房间的相机112可使用结构化光来捕捉深度信息。在这样的分析中,图案化光(即,被显示为诸如网格图案、条纹图案、或不同图案之类的已知图案的光)可经由例如ir光组件被投影到场景上。在落到场景中的一个或多个目标或对象的表面上以后,作为响应,图案可以变为变形的。图案的这种变形可由例如3-d相机和/或rgb相机(和/或其他传感器)来捕捉,并可随后被分析以确定从面向房间的相机112到对象上的特定位置的物理距离。在一些实现中,ir光组件从深度和/或rgb相机移位,使得可以使用三角测量来确定与深度和/或rgb相机的距离。在一些实现中,面向房间的相机112可包括感测ir光的专用ir传感器或具有ir滤波器的传感器。
应理解,本技术可在没有深度相机、rgb相机和ir光组件中的每一者的情况下感测对象和对象的三维位置。在各实施例中,面向房间的相机112可例如只与标准图像相机(rgb或黑白)一起工作。这样的实施例可通过单独或组合使用的各种图像跟踪技术来操作。例如,单个、标准图像面向房间的相机112可使用特征标识和跟踪。即,使用来自标准相机的图像数据,有可能提取场景的感兴趣区域或特征。通过查找那些相同的特征达某一时间段,可在三维空间中确定针对对象的信息。
在各实施例中,头戴式显示设备2可包括两个间隔开的标准图像面向房间的相机112。在该实例中,到场景中对象的深度可依据两个相机的立体效果来确定。每一相机都可成像某一重叠的特征集,并且深度可从其视野中的视差差异中被计算出。
一种用于确定未知环境内具有位置信息的现实世界模型的进一步方法被称为同时定位和映射(slam)。slam的一个示例题为“systemsandmethodsforlandmarkgenerationforvisualsimultaneouslocalizationandmapping”(用于可视同时定位和映射的地标生成的系统和方法)的美国专利no.7,774,158中被公开。此外,来自imu的数据可被用于更准确地解释视觉跟踪数据。
处理单元4可包括现实世界建模模块452。使用以上所描述的来自(诸)面向前面的相机112的数据,现实世界建模模块能够将场景中的各对象(包括用户的一只或两只手)映射到三维参考帧。以下描述了现实世界建模模块的进一步细节。
为了跟踪用户在场景内的位置,可从图像数据中识别用户。处理单元4可实现骨架识别和跟踪模块448。题为“skeletaljointrecognitionandtrackingsystem(骨架关节识别和跟踪系统)”的美国专利公开no.2012/0162065中公开了骨架跟踪模块448的一示例。这样的系统还可跟踪用户的手。然而,在各实施例中,处理单元4还可执行手部识别和跟踪模块450。该模块450接收来自面向房间的相机112的图像数据,并且能够标识fov中的用户的手以及用户的手的位置。题为“systemforrecognizinganopenorclosedhand(用于识别张开或闭合的手的系统)”的美国专利公开no.2012/0308140中公开了手部识别和跟踪模块450的一示例。一般来说,模块450可检查图像数据以辨别可以为手指、手指之间的间距以及在手指并在一起的情况下的指间的对象的宽度和长度,以便标识并跟踪处于其各位置的用户的手。
处理单元4还可以包括姿势识别引擎454以用于接收场景中的一个或多个用户的骨架模型和/或手数据,并确定该用户是否正在执行预定义的姿势或影响在处理单元4上运行的应用的应用控制移动。关于姿势识别引擎454的更多信息可以在2009年4月13日提交的题为“gesturerecognizersystemarchitecture(姿势识别器系统架构)”的美国专利申请no.12/422,661中找到。
如上所述,用户可例如以口述命令的形式执行各种口头姿势以选择对象并可能修改那些对象。因此,本系统进一步包括语音识别引擎456。语音识别引擎456可根据各种已知技术中的任一者来操作。
在一个示例实施例中,头戴式显示设备2和处理单元4一起工作以创建用户所在的环境的现实世界模型并且跟踪该环境中各个移动的或静止的对象。此外,处理单元4通过跟踪用户18所佩戴的头戴式显示设备2的位置和定向来跟踪该头戴式显示设备2的fov。由头戴式显示设备2获得的例如来自面向房间的相机112和imu132的传感器信息被传送到处理单元4。处理单元4处理数据并更新现实世界模型。处理单元4进一步向头戴式显示设备2提供关于在何处、在何时以及如何插入任何虚拟三维对象的指令。根据本技术,处理单元4进一步实现缩放的沉浸软件引擎458,缩放的沉浸软件引擎458用于经由头戴式显示设备2从虚拟内容中的化身的视角向用户显示虚拟内容。现将参考图7的流程图更详细地描述上述操作中的每一者。
图7是处理单元4和头戴式显示设备2在离散时间段(比如为了生成、渲染和向每个用户显示单帧图像数据所花费的时间)期间的操作和交互性的高级流程图在各实施例中,数据可以以60hz的速率刷新,但是在另外的实施例中可以以更高或更低的频度刷新。
可以在步骤600配置用于将虚拟环境呈现给一个或多个用户18的系统。根据本技术的各方面,步骤600可包括从存储器检索用户的虚拟化身,诸如例如图13中示出的化身500。在各实施例中,如果尚未被存储,则化身500可由处理单元4和头戴式显示设备2在步骤604生成,如以下所解释的。化身可以是(在先前或当前时间捕捉的)用户的副本并且随后被存储。在进一步实施例中,化身不需要是用户的副本。化身500可以是另一个人或一般的人的副本。在进一步实施例中,化身500可以是除人以外的具有外观的对象。
在步骤604,处理单元4收集来自场景的数据。该数据可以是由头戴式显示设备2感测到的图像数据,且具体而言,是由面向房间的相机112、眼睛跟踪组装件134和imu132感测到的图像数据。在各实施例中,步骤604可包括扫描用户以如以下所解释的那样渲染该用户的化身以及确定该用户的高度。如以下所解释的,一旦在虚拟内容中设定了化身的大小并对其进行了放置,就可使用用户的高度来确定该化身的缩放比例。步骤604可进一步包括扫描用户在其中操作移动混合现实组装件30的房间,并确定房间的尺寸。如以下所解释的,已知的房间尺寸可被用于确定化身的经缩放的大小和位置是否将允许用户完全地探索化身被放置在其中的虚拟内容。
现实世界模型可在步骤610中被开发出,从而标识其中使用移动混合现实组装件30的空间的几何结构以及对象的几何结构和对象在场景内的位置。在各实施例中,在给定帧中生成的现实世界模型可包括该场景中用户的(诸)手、其他现实世界对象和虚拟对象的x、y和z位置。以上解释了用于收集深度和位置数据的方法。
处理单元4可接着将传感器所捕捉到的图像数据点转换为场景的正交3d现实世界模型或图。此正交3d现实世界模型可以是由头戴式显示设备相机所捕捉的所有图像数据在正交x,y,z笛卡尔坐标系中的点云图。使用将相机视图转化成正交3-d世界视图的矩阵变换等式的方法是已知的。例如参见davidh.eberly的“3dgameenginedesign:apracticalapproachtoreal-timecomputergraphics”(3d游戏引擎设计:实时计算机图形的实用方法),morgankaufman(摩根考夫曼)出版社(2000)。
在步骤612,该系统可检测并跟踪用户的骨架和/或手(如以上所描述的),并基于移动身体部位和其他移动对象的位置来更新现实世界模型。在步骤614,处理单元4确定头戴式显示设备2在场景内的x、y和z位置、定向以及fov。现在参考附图8的流程图描述步骤614的进一步细节。
在步骤700,由处理单元4分析场景的图像数据以确定用户头部位置、以及从用户的面部向外直视的面部单位向量二者。头部位置可从来自头戴式显示设备2的反馈中标识出,并且根据该反馈,可构造面部单位向量。面部单位向量可被用来定义用户的头部定向,且在一些示例中可被认为是用户的fov的中心。也可或替代地根据从头戴式显示设备2上的面向房间的相机112返回的相机图像数据来标识面部单位向量。特别而言,基于头戴式显示设备2上的相机112所看到的,处理单元4能够确定表示用户的头部定向的面部单位向量。
在步骤704,用户的头部的位置和定向还可或替代地通过如下方式来被确定:分析来自较早时间(要么在帧中较早,要么来自前一帧)的用户的头部的位置和定向,以及然后使用来自imu132的惯性信息来更新用户的头部的位置和定向。来自imu132的信息可以提供用户的头部的精确动力学数据,但是imu典型地不提供关于用户的头部的绝对位置信息。该绝对位置信息也被称为“地面实况”,其可提供自从头戴式显示设备2上的相机处获得的图像数据。
在各实施例中,用户的头部的位置和定向可以通过联合作用的步骤700和704来确定。在又一些实施例中,步骤700和704中的一者或另一者可被用来确定用户的头部的头部位置和定向。
可能发生的是,用户未向前平看。因此,除了标识出用户头部位置和定向以外,处理单元可进一步考虑用户的眼睛在其头部中的位置。该信息可由上述眼睛跟踪组件134提供。眼睛跟踪组件能够标识出用户的眼睛的位置,该位置可以被表示成眼睛单位向量,该眼睛单位向量示出了与用户的眼睛聚焦所在且向前看的位置的向左、向右、向上和/或向下的偏离(即面部单位向量)。面部单位向量可以被调整为定义用户正在看向何处的眼睛单位向量。
在步骤710,接着可以确定用户的fov。头戴式显示设备2的用户的视图范围可以基于假想用户的向上、向下、向左和向右的边界视力(peripheralvision)来预定义。为了确保针对给定用户计算得到的fov包括特定用户或许能够在该fov的范围内看到的对象,这一假想用户可不被当作具有最大可能边界视力的人。在一些实施例中,某一预定的额外fov可被添加于此以确保对给定用户捕捉足够的数据。
然后,可以通过取得视图范围并且将其中心定在调整了眼睛单位向量的任何偏离的面部单位向量周围来计算该用户在给定时刻的fov。除了定义用户在给定时刻正在看什么之外,用户的fov的这一确定还有用于确定什么可能对用户是不可见的。如以下所解释的,将对虚拟对象的处理限制于特定用户的fov内的那些区域可提高处理速度并降低延迟。
如以下还解释的,本发明可以用沉浸模式操作,其中该视图是来自用户控制的化身的视角的经缩放的视图。在一些实施例中,当以沉浸模式操作时,确定现实世界模型的fov的步骤710可被跳过。
本技术的各方面(包括从沉浸模式内查看虚拟内容的选项)可由在处理单元4上执行的缩放的沉浸软件引擎458(图6)基于经由头戴式显示设备2接收到的输入来实现。现在将参考图9-18更详细地解释经由内容生成引擎458、处理单元4和显示设备2从现实世界和沉浸模式内查看内容。尽管以下描述了由处理单元4执行的处理步骤,但应理解,这些步骤可附加地或替换地由头戴式显示设备2和/或一些其他计算设备内的处理器来执行。
如以下所解释的那样通过现实世界和沉浸模式与虚拟工件交互可通过用户执行各种预定义姿势来完成。物理和/或口头姿势可被用于选择虚拟工具(包括化身500)或工件的各部分,诸如例如通过触摸、指向、抓握或注视虚拟工具或工件的部分。物理和口头姿势可被用于修改化身或工件,诸如例如说“将化身放大20%”。这些姿势仅作为示例,并且各种各样的其他姿势可被用于与化身、其他虚拟工具和/或工件进行交互。
在步骤622,处理单元4检测用户是否正在发起沉浸模式。这样的发起可例如由于用户指向、抓握或注视化身500而被检测到,当沉浸模式中没有使用化身500时,可将其存放在虚拟工作台502(图13)上。如果在步骤622检测到对沉浸模式的选择,则处理单元4在步骤626设置并验证沉浸模式。现在将参考附图9来解释步骤626的进一步细节。
在步骤712,用户可将化身500定位在虚拟内容504中的某处,如图14所示出的。如所陈述的,虚拟内容504可包括一个或多个工件506以及在该工件之中和周围的空间。一般来说,虚拟内容504还可包括任何虚拟对象以及这样的虚拟对象周围的空间。一个或多个工件506可坐落在工作表面508上,该工作表面508可以是现实或虚拟的。化身500可在虚拟内容中被定位在工作表面508上或工件506的表面上。还构想了虚拟对象510(图15)被放置在工作表面508上作为基座,并且化身500被放置在对象510顶部以改变化身的高度并因此改变化身的视野。
一旦化身500被放置在期望位置,化身500就可被旋转(图16)和/或缩放(图17)到期望定向和大小。当化身500被放置在一表面上时,该化身可对齐该表面的一法线。即,该化身可沿着垂直于该化身所放置在其上的表面的射线定向。如果化身500被放置在水平工作表面508上,则该化身可垂直站立。如果化身500被放置在虚拟的山或其他坡度表面上,则该化身可与其放置的位置垂直地定向。可以想象,附连到工件506的悬垂部分的化身具有悬垂部分,使得化身500被颠倒定位。
化身500在虚拟内容504中的缩放是相关的,因为它可被用于在图9的步骤718中确定虚拟内容504的比例以及缩放比例。具体地,如上所述,处理单元4和头戴式设备2可协作以用现实世界坐标确定用户的高度。用户的现实世界高度与由该用户设置的化身(沿着其长轴)的大小的比较在步骤718提供缩放比例。例如,在六英尺高的用户将化身的z轴高度设置为6英寸时,这提供了12:1的缩放比例。该缩放比例仅作为示例,并且基于用户的高度和化身500在虚拟内容504中的高度设置可使用各种各样的缩放比例。一旦缩放比例被设置,该缩放比例就可被用于现实世界视图和经缩放的沉浸视图之间的所有变换,直到化身的大小被改变的时间。
图10的流程图提供用于确定缩放比例的一些细节。取代用户的高度,应理解,用户可在步骤740和744独立于用户的高度和/或为化身500设置的高度设置并指明缩放比例。还应理解,取代用户的高度,一些其他现实世界参考尺寸可由用户提供,并与化身500的设置高度一起被用于根据本技术确定缩放比例。步骤746和748示出了上述扫描用户的高度并基于测量到的用户高度和由用户设置的化身的高度来确定缩放比例的步骤。在各实施例中,虚拟标尺或其他测量工具(未示出)可沿着化身被拉伸或收缩的轴被显示在化身500旁边,以在化身被重设大小时示出化身的大小。
在本技术中可按几种方式来使用步骤718的缩放比例。例如,工件通常被创建而没有任何比例。然而,一旦缩放比例被确定,该缩放比例就可被用来提供虚拟内容504中的一个或多个工件的比例。由此,在以上示例中,在工件506包括例如具有12英寸的z轴高度的墙壁的情况下,该墙壁在现实世界尺寸中将缩放到12英尺。
缩放比例也可被用于针对用户在现实世界中的位置的给定变化来定义在化身500的视角视图中的位置的变化。具体地,当处于沉浸模式时,头戴式显示设备2从化身500的视角显示虚拟内容504的视图。该视角由现实世界中的用户控制。随着用户的头部在现实世界中平移(x、y和z)或旋转(俯仰、偏航和滚转),这导致在化身在虚拟内容504中的视角中的相应缩放改变(就好像化身正在执行与用户相同的相应移动,但根据缩放比例被缩放)。
再次参考图9,在步骤722,一个或多个沉浸矩阵的集合被生成以用于在任一给定时刻将用户在现实世界中的查看视角转换为化身在虚拟内容504中的查看视角。这些沉浸矩阵是使用缩放比例、用户在现实世界模型中的查看视角的位置(x,y,z)和定向(俯仰、偏航、滚转)以及在化身被放置在虚拟内容中时由用户设置的化身的查看视角的位置(xi,yi,zi)和定向(俯仰i,偏航i,滚转i)来生成的。当化身被定位在虚拟内容中时,位置(xi,yi,zi)可以是在化身的脸部中心(例如,在眼睛之间)的点的位置。该点可根据化身的已知位置和经缩放的高度来确定。
定向(俯仰i,偏航i,滚转i)可依据从那个点开始的被定向为垂直于化身的脸部平面的单位向量给出。在各示例中,当化身被定向为处于虚拟内容中时,面部平面可以是与化身的身体和/或头部的前表面平行的平面。如上所述,化身可对齐该化身被定位在其上的表面的一法线。面部平面可被定义为包括该法线以及用户定义的化身绕该法线的旋转位置。
一旦用户的位置和定向、化身的位置和定向以及缩放比例已知,就可确定用于在用户的视图和化身的视图之间变换的缩放变换矩阵。如以上所解释的,变换矩阵已知用于在六个自由度上将第一视图视角转换成第二视图视角。例如参见davidh.eberly的“3dgameenginedesign:apracticalapproachtoreal-timecomputergraphics”(3d游戏引擎设计:实时计算机图形的实用方法),morgankaufman(摩根考夫曼)出版社(2000)。缩放比例在沉浸(变换)矩阵中被应用,使得用户在现实世界中的查看视角的x、y、z、俯仰、偏航和/或滚转移动将导致化身在虚拟内容504中的查看视角的相应xi、yi、zi、俯仰i、偏航i和/或滚转i移动,但根据缩放比例被缩放。
由此,作为使用以上为12:1的缩放比例的简单示例,一旦在图9的步骤722定义了沉浸矩阵,如果现实世界中的用户沿着x轴迈了为18英寸的一步,则化身500的视角将沿着虚拟内容504中的x轴具有相应1.5英寸的改变。
当在现实世界中到处移动,并以沉浸模式探索虚拟内容时,可能会发生的是,在虚拟内容504中化身500的特定放置和比例导致次优体验。在图9的步骤724中,处理单元4可确认沉浸参数的有效性以确保该体验是最优的。现在将参考附图11的流程图解释步骤724的进一步细节。
在步骤750,处理单元4确定用户是否已将化身500定位在固体对象内(现实或虚拟)。如上所述,处理单元4维护现实世界中的所有现实和虚拟对象的图,并且能够确定用户何时跨现实或虚拟对象的表面定位了化身。如果在步骤750确定化身的眼睛或头部被定位在固体对象内,则处理单元4可使得头戴式显示设备2在步骤754提供该放置不合适的消息。用户可随后返回到步骤712和图9以调整化身500的放置和/或比例。
在给定用户正在其中使用移动混合现实组装件30的现实世界房间的大小的情况下,也可能发生的是,用户已将化身的比例设置得对于使用户完全地探索虚拟内容504而言太小了。作为任何数目的示例之一,用户可沿着现实世界中的y轴远离物理墙壁10英尺。然而,随着用户设置了化身500的比例,在化身的视角将到达虚拟内容的y轴边界之前,用户将需要在y方向上走15英尺。由此,在给定房间的物理边界和用户设置的比例的情况下,可能存在虚拟内容中用户将可能无法探索的部分。
因此,在图11的步骤756,处理单元4和头戴式设备2可扫描其中存在该用户的房间的大小。如所述的,该步骤可能在图7的步骤604中收集场景数据时已经被完成,并且可能不需要作为步骤724的一部分来执行。接着,在步骤760,使用已知的房间大小、缩放比例和化身500相对于(诸)工件的放置,处理单元4确定当处于沉浸模式时,用户是否将能够探索(诸)工件506的所有部分。具体地,处理单元确定现实世界中是否存在足够的物理空间来完成在沉浸模式中从化身的视角对虚拟世界的任何部分的探索。
如果物理世界中不存在足够的空间,则处理单元4可促使头戴式显示设备2提供化身500的放置和/或比例阻止对虚拟内容504进行完全探索的消息。用户可随后返回到图9中的步骤712以调整化身500的放置和/或比例。
如果在步骤724检测到化身500的放置和/或比例没有问题,则化身的初始位置和定向可在图9的步骤732中被与确定的缩放比例和沉浸矩阵存储在一起。应理解,在进一步实施例中,可忽略步骤724的用于确认沉浸参数的有效性的至少各部分。
再次参考图7,一旦沉浸模式已在步骤626被设置并被验证,处理单元4就可检测用户是否正在沉浸模式中操作。如上所述,这可在化身已经被选择并且被定位在虚拟内容504中时被检测到。在进一步实施例中,到沉浸模式的切换可由某个其他预定义的姿势来触发。如果在步骤630中以沉浸模式操作,则处理单元4可在步骤634查找离开沉浸模式的预定义姿势命令。如果在步骤630中不在以沉浸模式操作或者离开沉浸模式的命令在步骤634被接收到,则要向用户显示的视角可在步骤642被设置到现实世界视图。如此后参考步骤644-656解释的,图像可随后被渲染。
在本技术的替换实施例中,当用户在步骤634提供离开沉浸模式的命令时,几件不同的事情可相对于化身500发生。现实世界视图可被显示给用户,并且化身500被从虚拟内容移除并被返回到工作台502。
在进一步实施例中,现实世界视图可被显示给用户,并且化身500以用户选择退出沉浸模式时的视角的位置和定向被示出。具体地,如以上所讨论的,在处于沉浸模式时用户已到处移动了的情况下,化身500的位置改变相应的缩放量。使用在用户离开沉浸模式时用户的位置和定向以及沉浸矩阵,处理单元4可确定化身500在现实世界模型中的现实位置。在退出沉浸模式之际,化身可以以那个位置和定向显示。
在进一步实施例中,在退出沉浸模式之际,现实世界视图可被显示给用户,并且化身500被示为处于在用户最后进入沉浸模式时由用户设置的初始位置。如上所述,该初始位置在于步骤626设置并验证沉浸模式之际被存储在存储器中。
再次参考图7,如果用户在步骤630正以沉浸模式操作并且没有退出命令在步骤634被接收到,则该模式在步骤638被设置为沉浸模式视图。当处于沉浸模式时,头戴式显示设备2从化身的视角和定向显示虚拟内容504。该位置和定向以及化身的视图的锥体可在步骤640被设置。现在将参考附图12的流程图解释步骤640的进一步细节。
在步骤770,处理单元4可根据存储的沉浸矩阵以及在现实世界中的当前用户视角来确定当前化身视角(关于六个自由度的位置和定向)。具体地,如以上结合图8中的步骤700讨论的,处理单元4能够基于来自头戴式显示设备2的数据来确定表示用户在现实世界中的头部位置和定向的面部单位向量。在将沉浸矩阵应用于用户的x、y和z头部位置和单位向量之际,处理单元4能够确定在沉浸模式中虚拟内容的视角的xi、yi和zi位置。使用沉浸矩阵,处理单元4能够确定表示在沉浸模式中查看虚拟内容的定向的沉浸模式单位向量。
在步骤772,处理单元4可确定锥体(类似于头戴式显示设备的fov)的范围。该锥体可以以沉浸模式单位向量为中心。处理单元4还可在步骤772设置沉浸模式视图的锥体的边界。如以上结合设置现实世界视图中的fov所描述的(图8步骤710),锥体的边界可被预定义为基于假想用户的上、下、左和右周边视觉的查看范围,该范围以沉浸模式单位向量为中心。使用在步骤770和772确定的信息,处理单元4能够根据化身的视图的视角和锥体显示虚拟内容504。
可发生的是,近距离地持久查看对象(虚拟或现实)可导致眼疲劳。因此,在步骤774,处理单元可检查处于沉浸模式的视图是否太接近工件506的一部分。如果如此,则处理单元4可使得头戴式显示设备2在步骤776向用户提供进一步远离工件506移动的消息。在进一步实施例中,可省略步骤774和776。
再次参考图7,在步骤644,处理单元4可精选渲染操作使得仅仅有可能在该头戴式显示设备2的最终fov或锥体内出现的那些虚拟对象被渲染。如果用户正以现实世界模式操作,则在步骤644从用户的视角获得虚拟对象。如果用户正以沉浸模式操作,则在步骤644从化身的视角获得虚拟对象。在fov/锥体外部的其他虚拟对象的位置仍可被跟踪,但是它们不被渲染。还可设想,在进一步实施例中,步骤644可以被完全跳过且整个图像根据现实世界视图或沉浸视图来渲染。
处理单元4可接着执行渲染设置步骤648,在步骤648,使用在步骤610和614接收到的现实世界视图和fov或者使用在步骤770和772接收到的沉浸视图和锥体来执行设置渲染操作。一旦接收到虚拟对象数据,处理单元就可在步骤648对要被渲染的虚拟对象执行渲染设置操作。步骤648中的设置渲染操作可包括与要在最终fov/锥体中显示的(诸)虚拟对象相关联的常见渲染任务。这些渲染任务可包括例如阴影图生成、光照和动画。在一些实施例中,渲染设置步骤648可进一步包括对可能的绘制信息的编译,诸如要在预测的最终fov中显示的虚拟对象的顶点缓冲区、纹理和状态。
使用关于对象在3d现实世界模型中的位置的信息,处理单元4可接着在步骤654确定用户的fov或化身的锥体中的遮挡和阴影。具体地,处理单元4具有虚拟内容的对象的三维位置。对于现实世界模式,已知用户的位置以及他们对该fov中的对象的视线的情况下,处理单元4随后可确定虚拟对象是否部分或全部遮挡用户的现实或虚拟对象的视图。此外,处理单元4可确定某一现实世界对象是否部分或全部地遮挡了该用户的虚拟对象的视图。
类似地,如果正以沉浸模式操作,则确定的化身500的视角允许处理单元4根据该视角确定到锥体中的对象的视线,以及虚拟对象是否部分或全部遮挡了化身对现实或虚拟对象的视角。此外,处理单元4可确定现实世界对象是否部分或全部遮挡了化身的虚拟对象的视图。
在步骤656,处理单元4的gpu322可以接下来渲染要向该用户显示的图像。渲染操作的各部分可能已经在渲染设置步骤648中被执行并且被周期性地更新。任何被遮挡的虚拟对象可能不被渲染,或者它们可被渲染。在被渲染的情况下,被遮挡的对象将被不透明滤光器114从显示中省略,如以上所解释的。
在步骤660,处理单元4检查:是否到了该将经渲染的图像发送给头戴式显示设备2的时间、或者是否还有时间使用来自头戴式显示设备2的更新近的位置反馈数据来进一步细化图像。在使用60赫兹帧刷新率的系统中,单帧大约为16毫秒。
如果到了显示经更新的图像的时间,则针对该一个或多个虚拟对象的图像被发送至微显示器120以在恰适像素处显示,同时计入视角和遮挡。在此时,用于不透明滤光器的控制数据也从处理单元4被传送至头戴式显示设备2以控制不透明滤光器114。该头戴式显示器随后将在步骤662中向该用户显示该图像。
另一方面,在步骤660还没到发送要被显示的图像数据帧的时间的情况下,处理单元可循环回去以获得更新的传感器数据来细化对最终fov及fov中的对象的最终位置的预测。具体而言,如果在步骤660中仍旧有时间,则处理单元4可返回至步骤604以从头戴式显示设备2获得更新近的传感器数据。
上面仅以示例的方式描述了处理步骤600至662。理解到,这些步骤中的一个或多个步骤在另外的实施例中可被省略,这些步骤可以按不同次序来执行,或者可以添加附加步骤。
图18解说了在给定图17中示出的化身位置和定向的情况下,沉浸模式中的可向用户显示的虚拟内容504的视图。虚拟内容504处于沉浸模式时的视图提供实物大小视图,其中用户能够辨别内容的详细特征。此外,沉浸模式中虚拟内容的视图提供其中用户能够看见虚拟对象实物大小有多大的视角。
用户在现实世界中的移动可导致化身朝向工件506移动,并且化身对工件506的视角相应地变得更大,如图19中所示出的。用户的其他移动可导致化身远离工件506移动和/或探索虚拟内容504的其他部分。
除了从沉浸模式内查看并探索虚拟内容504外,在各实施例中,用户能够从沉浸模式内与虚拟内容504进行交互并修改虚拟内容504。用户可具有对各种虚拟工件和控件的访问权。用户可使用预定义的姿势来选择工件的一部分、作为整体的工件或多个工件506,并在此后应用虚拟工具或控件来修改工件的该部分或多个工件。作为几个示例,用户可根据所选的工具或控件来移动、旋转、上色、移除、复制、黏合、复印等(诸)工件的一个或多个所选部分。
本技术的沉浸模式的进一步优点在于它允许用户以增加的精度与虚拟内容504进行交互。作为示例,在用户正尝试例如使用指向或眼睛注视来从现实世界视图中选择虚拟内容504的一部分的情况下,头戴式显示设备的传感器能够分辨虚拟内容上可作为用户的指向或注视的主题的给定大小的区域。可发生的是,该区域可具有一个以上可选的虚拟对象,在该情况下,用户可能难以选择用户希望选择的特定对象。
然而,当以其中用户的视角被缩放到虚拟内容的尺寸的沉浸模式操作时,相同的指向或注视姿势将导致作为用户的指向或注视的主题的更小、更精确的区域。由此,用户可更容易地用更大的精度选择物品。
附加地,在沉浸模式中,可用更大的精度来执行对工件的虚拟对象的修改。作为示例,用户可希望小量移动工件中的所选虚拟对象。在现实世界模式中,最小增量移动可以是某个给定距离,并且可能发生该最小增量距离仍大于用户期望。然而,当以沉浸模式操作时,移动的最小增量距离可能比现实世界模式中小。由此,用户可能能够在沉浸模式内对虚拟对象作出更细、更精确的调整。
使用预定义的姿势命令,用户可在来自现实世界的虚拟内容504的视图和来自化身的沉浸视图的虚拟内容504的视图之间进行切换。进一步构想了用户可将多个化身500定位在虚拟内容504中。在该实例中,用户可在来自现实世界的虚拟内容504的视图和来自化身中的任一者的视角的虚拟内容504的视图之间进行切换。
总之,本技术的一示例涉及一种用于呈现虚拟环境的系统,所述虚拟环境与现实世界空间共同延伸,所述系统包括:头戴式显示设备,所述头戴式显示设备包括用于在所述虚拟环境中显示三维虚拟内容的显示单元;以及,操作地耦合到所述显示设备的处理单元,所述处理单元接收确定所述虚拟内容由所述头戴式显示设备以第一模式显示还是由所述头戴式显示设备以第二模式显示的输入,在所述第一模式中,所述虚拟内容是从所述头戴式显示设备的现实世界视角显示的,在所述第二模式中,所述虚拟内容是从所述虚拟内容内的位置和定向的经缩放视角显示的。
在另一示例中,本技术涉及一种用于呈现虚拟环境的系统,所述虚拟环境与现实世界空间共同延伸,所述系统包括:头戴式显示设备,所述头戴式显示设备包括用于在所述虚拟环境中显示三维虚拟内容的显示单元;以及,操作地耦合到所述显示设备的处理单元,所述处理单元接收以相对于所述虚拟内容的一位置和定向并以相对于所述虚拟内容缩放的大小来将虚拟化身放置在所述虚拟内容之中或周围的第一输入,所述处理单元确定来自所述头戴式显示设备的所述虚拟内容的现实世界视图和来自所述化身的视角的所述虚拟内容的沉浸视图之间的变换,所述变换基于以下来确定:所述化身的位置、定向和大小,所述头戴式显示设备的位置和定向,以及接收或确定的参考大小;所述处理单元至少接收用于在由所述头戴式显示设备显示所述现实世界视图和所述沉浸视图之间切换的第二输入。
在又一示例中,本技术涉及一种用于呈现虚拟环境的方法,所述虚拟环境与现实世界空间共同延伸,所述虚拟环境由头戴式显示设备呈现,所述方法包括:接收虚拟对象在所述虚拟内容中的一位置处的放置;(b)接收所述虚拟对象的定向;(b)接收所述虚拟对象的缩放;(d)基于所述头戴式显示器的位置和定向、在所述步骤(a)接收到的所述虚拟对象的位置以及在所述步骤(b)接收到的所述虚拟对象的定向来确定一个或多个变换矩阵的集合;(e)基于所述用户的移动在所述虚拟内容内四处移动所述虚拟对象;以及,(f)基于所述一个或多个变换矩阵的集合将所述头戴式显示设备所进行的显示从来自所述头戴式显示设备的视图变换为在所述步骤(e)移动之前和/或之后从所述虚拟对象取得的视图。
尽管用结构特征和/或方法动作专用的语言描述了本发明主题,但可以理解,所附权利要求书中定义的主题不必限于上述具体特征或动作。更确切而言,上述具体特征和动作是作为实现权利要求的示例形式公开的。本发明的范围由所附的权利要求进行定义。
- 还没有人留言评论。精彩留言会获得点赞!