一种基于池化时间序列特征表示的细胞分裂事件识别方法与流程
本发明涉及细胞分裂事件检测领域,尤其涉及一种基于池化时间序列特征表示的细胞分裂事件识别方法。
背景技术:
细胞生命规律的探索是生物医学研究中的一个重要方面。为了实现人为可控的细胞培养,以解决医学中的相关难题,为疾病的预防、诊断和治疗服务,细胞工程应运而生。干细胞增殖期的有丝分裂行为分析是一项很重要的指标,比如在癌症检查的评估中,及组织工程学等领域,之前,这项工作只能依靠生物学家的人工注释,工作量浩大,消耗大量的人力物力。为了解决高通量的细胞数据分析,提高效率,降低各方面的损耗,自动的细胞分裂事件检测和定位就显得十分迫切和必要。
细胞分裂事件检测是基于数字图像处理、计算机视觉和机器学习等技术,借助于计算机处理技术,自动识别和定位分裂事件的研究。目前,在显微镜图像序列下的细胞分裂事件检测技术主要分为三类:基于特征的方法、基于轨迹的方法和基于图模型的方法。基于特征的方法通过对图像序列的处理提取局部特征直接检测细胞分裂状态,Li等人[1]把细胞分裂事件当成时空域中一个局部事件来进行检测,应用级联分类器对三维Haar-like特征描述的图像序列所构成的体积滑动窗口进行分类,Siva等人[2]直接利用时域信息描述细胞形变特征,此类方法依赖于大量的训练数据且忽略了序列动态特征,缺乏检测的特异性定位。基于轨迹的方法通常依赖于细胞跟踪,在跟踪得到细胞轨迹的基础上,根据分裂过程中的细胞形态的变化或是母细胞与子细胞之间的帧关系,利用预定义的规则鉴别出发生分裂的细胞[3][4],Dzyubachyk等人[5]进一步修改扩展了耦合活性表面算法,利用细胞迁移和增殖的多层集合提升了算法的鲁棒性和适应性。Yang等人[6]通过基于水平集的细胞跟踪方法完成细胞群落分离和细胞分裂识别,研究活体细胞图像。因为细胞跟踪本身就是一个极具挑战性的任务,所以过于依赖跟踪会使得识别定位的结果很难做到真实、准确。同时由于细胞分裂事件的发生是一个稀疏而分散的过程,通过逐帧跟踪细胞来研究细胞分裂必将以高计算成本为代价,显然这不是明智之举。基于图模型的方法减轻了跟踪方法的负担,通过图模型的学习直接完成细胞分裂的识别和定位。Ecodes等人[7]使用环形检测来定位母细胞和两个子细胞。Gallardo等人[8]基于细胞形状和外观特征采用了隐马尔科夫模型来对候选序列进行分类。El-Labban等人[9]利用动态时间规整(Dynamic Time Warping,DTW)根据参考信号调整样本特征的时域信号完成细胞周期的自动标记,并在此基础上进一步引入半马尔科夫模型(Semi-Markov Model,SMM)提高细胞周期标记的准确率[10]。Huh等人[11]提出了利用事件检测条件随机场(Event Detection Conditional Random Field,EDCRF)模型同时识别和定位细胞分裂的方法。Liu等人[12]进一步将最大边缘隐条件随机场(Hidden Conditional Random Field,HCRF)模型与最大边缘SMM相结合,加强对细胞分裂事件的识别力度的同时定位细胞分裂过程中的四个明显阶段。
细胞分裂事件检测领域目前面临的主要挑战为:
1)特征描述:不同类型的细胞通常呈现不同的外观且在分裂过程中会发生剧烈的形态学变化,但当前的底层视觉特征并不能够有效描述细胞间的这些差异。
2)模型学习:目前特征描述和模型学习都是单独进行的,尚不清楚提取的视觉特征能否促进模型对序列结构的学习。
3)跨域识别定位:由于不同种类细胞的个体或群体性差异,以及不同显微镜下所得到的细胞图像的模式差异,使得细胞分裂状态的表现存在极大不同。与此同时,细胞体外培养的难度依旧较大,且用于实验研究的有效细胞数据很难获取,目前可用于科学研究的细胞序列数据并不多见。
技术实现要素:
本发明提供了一种基于池化时间序列特征表示的细胞分裂事件识别方法,本发明避免了对序列的每一帧进行分析,而是将整个序列在空域和时域上联合作为整体,保留了帧与帧之间的时域关系,提高了序列分类预测结果,可以应用于多种视频序列内容分析,详见下文描述:
一种基于池化时间序列特征表示的细胞分裂事件识别方法,所述细胞分裂事件识别方法包括以下步骤:
在样本数据库中,提取样本相关特征,将所有样本特征的集合定义为初始特征库;
初始特征矩阵的每一横向维度为一个时间序列,将多种池化算子应用于时间金字塔结构,将池化后的结果级联为一个向量,作为样本的最终表示;
分别计算训练集和测试集的核矩阵,应用支持向量机作为分类器,获取最终的预测结果。
所述细胞分裂事件识别方法还包括:采集细胞候选子序列,将所有候选子序列定义为构成样本数据库。
所述多种池化算子具体为:最大池化算子、和池化算子、以及引入时间序列梯度直方图概念的池化算子。
所述时间序列梯度直方图概念的池化算子具体为:
其中,表示在[ts,te]时间段的正梯度算子,表示在[ts,te]时间段的负梯度算子,表示在[ts,te]时间段的另一种正梯度算子,表示在[ts,te]时间段的另一种负梯度算子,表示在一定范围内时间点t的正梯度值,表示在一定范围内时间点t的负梯度值,∧为逻辑与。
所述将池化后的结果级联为一个向量,作为样本的最终表示的步骤具体为:
其中,表示在时间段内将第j种池化算子应用于第i个时间序列fi(t)。
本发明提供的技术方案的有益效果是:
1、本发明避免了对序列的每一帧进行分析,而是将整个序列在空域和时域上联合作为整体,保留了帧与帧之间的时域关系;
2、采用时间金字塔结构,使得序列的时域信息表征更加精细;
3、池化时间序列表示(Pooled Time Series,PoT)框架适用于任何类型的单帧特征描述子,具有广泛的适用性。
附图说明
图1为一种基于池化时间序列特征表示的细胞分裂事件识别方法的流程图;
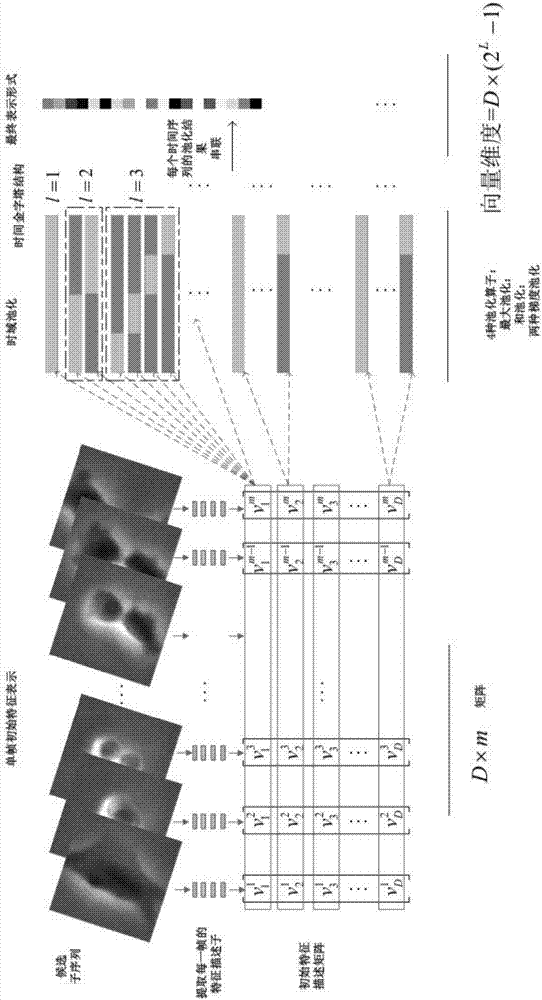
图2为PoT表示方法框架图;
图3为C2C12成骨干细胞群落细胞的一帧图像样例;
其中,本发明提取的样本是从很多连续的帧分割然后按照时间顺序拼接而成的。
图4为细胞候选子序列正负样本样例图;
(a)为正样本;(b)为负样本,从上到下分别为:只含背景;含有普通细胞;含有部分分裂期细胞。
图5为时间金字塔结构总层数L对识别结果的影响对比图。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚,下面对本发明实施方式作进一步地详细描述。
实施例1
研究表明:捕捉初始特征描述子在每一帧之间的变化信息使得对于序列的研究更加精细,本发明实施例提出了基于池化时间序列特征表示的细胞分裂事件识别方法,参见图1,详见下文描述:
101:在样本数据库中,提取样本相关特征,将所有样本特征的集合定义为初始特征库;
102:初始特征矩阵的每一横向维度为一个时间序列,将多种池化算子应用于时间金字塔结构,将池化后的结果级联为一个向量,作为样本的最终表示;
103:分别计算训练集和测试集的核矩阵,应用支持向量机作为分类器,获取最终的预测结果。
其中,在步骤101之前,该细胞分裂事件识别方法还包括:采集细胞候选子序列,将所有候选子序列定义为构成样本数据库。
其中,步骤102中的多种池化算子具体为:
最大池化算子、和池化算子、以及引入时间序列梯度直方图概念的池化算子。
时间序列梯度直方图概念的池化算子具体为:
其中,表示在[ts,te]时间段的正梯度算子,表示在[ts,te]时间段的负梯度算子,表示在[ts,te]时间段的另一种正梯度算子,表示在[ts,te]时间段的另一种负梯度算子,表示在一定范围内时间点t的正梯度值,表示在一定范围内时间点t的负梯度值,∧为逻辑与。
其中,步骤102中的将池化后的结果级联为一个向量,作为样本的最终表示的步骤具体为:
其中,表示在时间段内将第j种池化算子应用于第i个时间序列fi(t)。
如上所述,本发明实施例避免了对序列的每一帧进行分析,而是将整个序列在空域和时域上联合作为整体,保留了帧与帧之间的时域关系,提高了序列分类预测结果,可以应用于多种视频序列内容分析。
实施例2
下面结合具体的计算公式、附图对实施例1中的方案进行进一步地介绍,详见下文描述:
201:采集细胞候选子序列,构成样本数据库;
本方法中候选子序列长度为23帧,每一帧大小为50*50像素,所有候选子序列构成样本数据库。本发明实施例的数据集C2C12是成骨干细胞群落(ATTC,Manassas,VA),可以分化为造骨细胞和肌细胞。
图2给出了一帧图像样例,提取的样本是从很多连续的帧分割然后按照时间顺序拼接而成的。C2C12中每个序列包含1013张图片,获取图像之后,生物学研究者使用带有用户图形界面的标注工具在图像序列中手动标注细胞分裂事件。对于每个细胞分裂事件,标注者以两个子细胞间的边界清晰可见作为阶段3(分裂形成子细胞)的开始,标定这一边界中心位置。这些人工标记的中心位置及对应在第几帧的信息用数学的方法表示为一个三维向量,标记的数目即为一个序列中分裂事件的数量,这些信息称为真实数据(ground truth),训练集正负样本的标签就是与真实数据比较而产生的。
最终构成的样本数据库样例参见图4,其中,正样本的提取过程:根据真实数据的位置信息和时间信息[x,y,t],其中x和y为人工标记的中心位置的坐标,t表示这一中心位置在第几帧。
提取正样本时,在连续23帧如图2所示的图像上,时间上以t为中心帧,前后各取11帧,空间上以[x,y]为中心,用边长为50像素的正方形,用正方形将这样的区域分割出来,然后按照时间顺序拼接为一个23帧长的候选子序列,作为正样本。一个正样本包含一个完整的细胞分裂事件,一个完整的分裂事件包含4个阶段:
阶段1:细胞准备分裂。在此阶段细胞外形保持正常,但运动速度降低;
阶段2:细胞开始分裂。在此阶段细胞形状变小、收缩聚拢、亮度增加;
阶段3:分裂形成子细胞。此阶段中两个子细胞可见且相互粘附,形成“8”字形;
阶段4:分离完成。此阶段中两个子细胞相互分开。
负样本的提取过程:负样本为不是分裂事件的候选子序列,在原始序列上随机撒种,随机撒种的过程中避开真实数据,则得到的[x,y,t]不会有和真实数据完全重合的部分,按照相同的方法提取出对应的候选子序列,这样,得到的大部分子序列都是背景不包含任何细胞,为了使负样本具有代表性,按照一定的比例进行筛选,最终形成的负样本包含三种类型:只有背景的;只含有普通细胞的;含有部分分裂期细胞。
202:在样本数据库中,提取样本相关特征,将所有样本特征的集合定义为初始特征库;
其中,每个样本的特征为一个D×23的矩阵,D为特征维度,23为子序列帧长,将所有样本特征的集合定义为初始特征库。本发明实施例中的初始特征库包括Gist和Sift两种特征,很多研究表明,这两种特征能够较好地描述细胞的外形特征,通常被应用于此类研究中。其中,Gist特征为180*23的矩阵,Sift特征为128*23的矩阵。则初始特征库的数学表示为A={A1,...,Am,...AM},Am∈RD×23,,M表示样本数目,Am表示一个样本的初始特征,R表示实数空间。
203:初始特征矩阵的每一横向维度为一个时间序列,将多种池化算子应用于时间金字塔结构,将池化后的结果级联为一个向量,作为一个样本的最终表示;
其中,特征表示就是将一系列的初始特征描述子概括为一个向量,用这个单一向量来表示样本序列,它能够将高维描述转化为一个更易于处理的单一向量,这个向量就作为分类器的输入,现有的特征表示方法有词袋(Bag of Words,BoW),PoT特征表示方法框架参见图2。
首先,对于一个样本,得到其初始特征描述,将每一帧的初始特征描述子定义为其中t表示为第t帧,PoT表示方法将V1,V2,...V23,定义为一系列时间序列:{f1(t),...,fD(t)},也就是说,每一个时间序列fi(t)即为第i个初始特征值,则其次,获得时间序列的时间金字塔结构:ts=21-l*(k-1),te=21-l*k,l∈{1,2,...,L},k∈{1,2,...,2l},其中,L表示时间金字塔结构的总层数,l表示当前层,k表示当前层的第几个时间段,ts表示一个时间段的起点,te表示一个时间段的终点。
最后,将多种池化方法应用于每个金字塔时间结构的每一个时间段[ts,te],本发明实施例应用到的池化算子有最大池化(max pooling),和池化(sum pooling)及两种类型的梯度池化(gradient pooling)。
最大池化算子定义为:
和池化算子定义为:
除了以上两种传统的池化算子,还引入“时间序列梯度直方图”池化的概念,来计算正梯度和负梯度的数量:
另外,还介绍了另一种算子,用于计算正梯度和负梯度的和值:
其中
上述公式中,表示在[ts,te]时间段的正梯度算子,表示在[ts,te]时间段的负梯度算子,表示在[ts,te]时间段的另一种正梯度算子,表示在[ts,te]时间段的另一种负梯度算子,表示在一定范围内时间点t的正梯度值,表示在一定范围内时间点t的负梯度值。
经过以上步骤后,得到最终表示形式为:
其中,表示在时间段内将第j种池化算子应用于第i个时间序列fi(t)。最终表示是将多种池化算子应用于多个时间段后的结果级联起来,是一个向量的形式。
204:分别计算训练集和测试集的核矩阵,应用支持向量机(support vector machine,SVM)作为分类器,并得到最终的预测结果。
其中,利用上一步203中最后得到的向量表示作为SVM的输入数据,将输入数据分为训练集和测试集,利用真实数据(ground truth)分别形成训练集和测试集的标签。SVM包括训练和预测两个步骤。
首先,训练过程中,输入为训练集标签,训练样本向量表示和训练参数,输出一个训练模型。
其次,预测过程中,输入为测试集标签(用来计算准确率),测试样本向量表示,预测参数和训练得到的训练模型,输出为预测标签和准确率。
其中,本发明实施例对上述数值的取值,不做限制,本发明实施例仅以23等为例进行说明,具体实现时,根据实际应用中的需要进行设定。
综上所述,本发明实施例避免了对序列的每一帧进行分析,而是将整个序列在空域和时域上联合作为整体,保留了帧与帧之间的时域关系,提高了序列分类预测结果,可以应用于多种视频序列内容分析。
实施例3
下面结合具体的实验数据、附图对实施例1和2中的方案进行详细介绍,详见下文描述:
C2C12数据集的培养环境为DMEM细胞培养基,添加10%牛胎儿血清、1%青霉素链霉素,环境温度保持37℃恒定,周围二氧化碳浓度为5%。使用蔡司透镜(型号为Zeiss Axiovert 135TV倒置显微镜,5X,0.15N.A.)在干细胞体外培养的过程中每五分钟捕获一张细胞图像,每张图像大小为1392×1040像素,分辨率为1.3μm/pixel。C2C12共有16个序列,每个序列包含1013张图片。
本实验使用的数据库为由步骤1)提取的候选子序列,类别共两类,正类和负类,正类为分裂事件,负类不是分裂事件。训练集是从序列2中提取的,共有1013个样本,其中501个正样本,512个负样本;测试集为其他15个序列中提取的样本,每个测试集包含512个负样本和数量不等的正样本。
根据以下公式求得Recall和Precision:
其中,Recall是查全率,Precision是查准率,TP代表正确识别的样本数,FN是漏检测的样本数,FP指错误识别的样本数。
在此基础上定义F-score为:
上述三个指标取值均在0到1之间,F-score的值越接近1则表示分类器性能越好。
实验中将本方法与以下四种方法进行对比:
基于词袋(Bag of Words,BoW)特征表示的SVM模型的细胞分裂识别方法;
基于基于(Hidden Conditional Random Field,HCRF)模型的细胞分裂识别方法;
基于层级化随机场(Hierarchical Summarization of Random Field,HSRF)模型的细胞分裂识别方法;
基于隐状态条件神经场(Hidden-State Conditional Neural Fields,HSCNF)模型的细胞分裂识别方法;
由表1可知,本方法的细胞检测性能明显高于现有算法。
表1
这是因为本方法能够精确捕捉初始特征描述子在相邻帧间任何微小的变化,保留了帧之间的时域关系,更好地表征了序列。图5表明,引入时间金字塔结构,能够对时域信息表征地更加精细,当层数为1时,表示不采用金字塔结构,使用单一的时间结构,当层数为2时,识别结果明显高于单一时间结构,说明本方法的最终表示向量与时域信息密切相关。实验结果验证了本方法的可行性与优越性。
参考文献:
[1]Li K,Miller E D,Chen M,et al.Computer vision tracking of stemness.5th IEEE International Symposium on Biomedical Imaging:From Nano to Macro,2008,2008:847-850.
[2]Siva P,Brodland G W,Clausi D.Automated detection of mitosis in embryonic tissues.Fourth Canadian Conference on Computer and Robot Vision,2007.CRV'07,2007:97-104.
[3]Yang F,Mackey M A,Ianzini F,et al.Cell segmentation,tracking,and mitosis detection using temporal context.Medical Image Computing and Computer-Assisted Intervention–MICCAI2005.Springer Berlin Heidelberg,2005:302-309.
[4]Al-Kofahi O,Radke R J,Goderie S K,et al.Report Automated Cell Lineage Construction.Cell Cycle,2006,5(3):327-335.
[5]Dzyubachyk O,van Cappellen W A,Essers J,et al.Advanced level-set-based cell tracking in time-lapse fluorescence microscopy.IEEE Transactions on Medical Imaging,2010,29(3):852-867.
[6]Yang F,Mackey M A,Ianzini F,et al.Cell segmentation,tracking,and mitosis detection using temporal context.Medical Image Computing and Computer-Assisted Intervention–MICCAI2005.Springer Berlin Heidelberg,2005:302-309.
[7]Eccles B A,Klevecz R R.Automatic digital image analysis for identification of mitotic cells in synchronous mammalian cell cultures.Analytical and quantitative cytology and histology/the International Academy of Cytology and American Society of Cytology,1986,8(2):138-147.
[8]Gallardo G M,Yang F,Ianzini F,et al.Mitotic cell recognition with hidden Markov models.Medical Imaging 2004.International Society for Optics and Photonics,2004:661-668.
[9]El-Labban A,Zisserman A,Toyoda Y,et al.Dynamic time warping for automated cell cycle labelling.Microscopic Image Analysis with Applications in Biology,2011.
[10]El-Labban A,Zisserman A,Toyoda Y,et al.Discriminative semi-markov models for automated mitotic phase labelling.2012 9th IEEE International Symposium on Biomedical Imaging(ISBI),2012:760-763.
[11]Huh S,Ker D F E,Bise R,et al.Automated mitosis detection of stem cell populations in phase-contrast microscopy images.IEEE Transactions on Medical Imaging,2011,30(3):586-596.
[12]Liu A A,Li K,Kanade T.A semi-Markov model for mitosis segmentation in time-lapse phase contrast microscopy image sequences of stem cell populations.IEEE Transactions on Medical Imaging,2012,31(2):359-369.
本领域技术人员可以理解附图只是一个优选实施例的示意图,上述本发明实施例序号仅仅为了描述,不代表实施例的优劣。
以上所述仅为本发明的较佳实施例,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!