一种基于多模型融合策略的能源效率评价方法与流程
本发明涉及基于多模型融合策略的能源效率评价方法。
背景技术:
随着能源问题与环境问题的日益突出,能源效率评价方法也日益受到重视。国际上许多学者都从不同角度研究了能源利用效率的改进和节能潜力。以中国为例,近些年经济保持了高速强劲的发展,但经济增长方式仍然十分粗放,资源和能源消耗高、利用率低、环境污染严重的现状仍然是不争的事实,能源利用效率在国际上仍然处于落后阶段。目前,中国以煤炭为主的不合理能源消费结构,严重影响了整个能源体系中的能源利用效率,对社会可持续发展构成挑战。因此,需要理清能源效率的关键影响因素,并定量分析各因素的影响程度。目前对能源利用效率的定量研究,大多基于数据包络分析方法(DEA)对能源效率值进行评价研究。有的学者还在测算出全要素能源效率基础上研究了产业结构、技术进步、对外开放程度等因素对能源效率的影响。然而,由于中国地区复杂性和空间发展不均衡性,有很多学者利用地区间、省份之间的能源面板数据,分析不同区域或省份间能源效率大小,并取得了行之有效的计算方法和评价方法。因此,采用不同能源指标计算能源效率,无法真实反映影响能源效率的实际因素。
技术实现要素:
本发明的目的是为了解决现有能源效率计算特征难以选择,以及模型评价结果不准的问题,提出一种基于多模型融合策略的能源效率评价方法。
一种基于多模型融合策略的能源效率评价方法包括以下步骤:
本发明分类建模的主体策略如下:对数据进行特征值的标准化预处理,以便于正确进行特征选择。在此基础上,对数据集合进行类别标注,给出类标签以供分类算法学习得到训练集。然后,通过比较分析得到本发明可以使用的多分类器融合的分类模型,并能够在预测中使用。
步骤一:将数据进行归一化处理,得到归一化训练集;
步骤二:对步骤一得到的归一化训练集进行特征选择;
步骤三:根据步骤一和步骤二建立多分类器融合的评价模型,得到能源效率评价的分 类结果;
步骤四:对步骤三得到的分类结果进行聚类分析,得到最终的聚类结果。
本发明的有益效果为:
本发明提出了一种基于多模型融合策略的能源绩效评价方法,不仅建立了基于多分类器融合策略的的分类模型,并用于能源效率值的高低预测;而且还建立了多聚类分析方法的融合模型,可将能源效率高的省份与效率低的省份区分开来。然后以中国能源利用效率评价为例进行算例研究:首先,收集24省份9年的相关能源效率数据,并使用2种特征识别方法确定了能源效率的关键影响因素;进一步,对所建立的分类融合模型的拟合度进行对比分析,并用于对能源效率高低的预测;然后,基于多模型融合聚类策略,进一步将能源效率高的省份与效率低的省份精确区分开来。最后,针对所总结出的中国整体能源效率发展问题,给出了相应的改进策略建议。实验结果表明:多模型融合策略相对单一模型方法具有更好的分类预测及聚类分析效果。因此,本发明具有较好的实际应工程应用价值。
1)能够对计算能源效率的备选特征进行有效筛选,找出其中影响能源效率的相对主要因素。
2)对我国各省之间能源效率建立三种单一分类器模型和多分类器融合模型,分类及预测的算例结果显示:多分类器融合模型的能源效率分类预测效果要比单一模型的分类预测效果要好,能够对能源效率值的高低进行更准确的分类。
3)基于多模型融合聚类分析方法,发现了我国各地区的能源效率的差异性及变化规律,能够相适应地给出原因分析和发展建议。
附图说明
图1为基于三种分类器并行融合策略流程图。
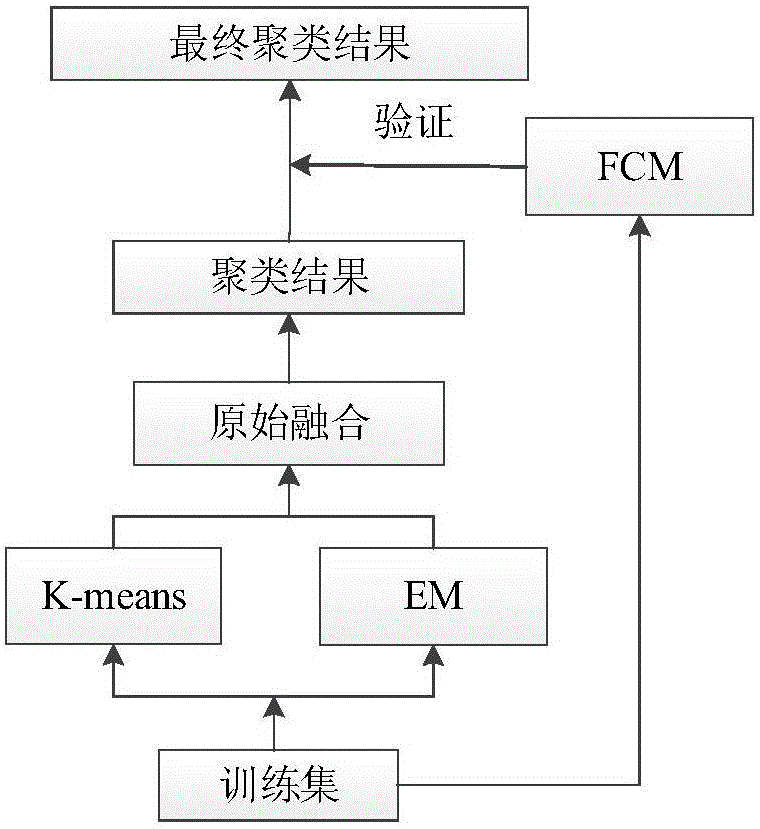
图2为多模型融合聚类分析策略流程图。
具体实施方式
具体实施方式一:一种基于多模型融合策略的能源效率评价方法的具体步骤为:
步骤一:将数据进行归一化处理,得到归一化训练集;
步骤二:对步骤一得到的归一化训练集进行特征选择;
步骤三:根据步骤一和步骤二建立多分类器融合的评价模型,得到能源效率评价的分类结果;
步骤四:对步骤三得到的分类结果进行聚类分析,得到最终的聚类结果。
具体实施方式二:本实施方式与具体实施方式一不同的是:所述步骤一中的数据具体 包括:一次能源生产量、能源消耗总量、能源消费弹性系数、GDP、能源工业投资额、单位生产总值能耗、资本存量、和二氧化硫排放系数。
其它步骤及参数与具体实施方式一相同。
具体实施方式三:本实施方式与具体实施方式一或二不同的是:所述步骤一中将数据进行归一化处理,得到归一化训练集的具体过程为:
收集全国多个省市自治区的面板数据,将数据进行标准化的预处理。数据的标准化是将数据按比例缩放,去除数据的单位限制,将其转化为无量纲的纯数值,便于进行比较和加权。0-1标准化(也叫归一化)是数据标准化最典型的方法,通过对原始数据的线性变换使结果落到[0,1]区间。考虑到本发明使用的数据集中的特征值均为正值,所以使用简化后的转换函数来对每个分量进行归一化。若有N个样本,对每个样本第m个特征进行处理,其表达形式如公式(1)所示:
预处理后的特征值分布在[0,1]区间,其中所述xim*为第i个样本的第m个特征归一化后的值,xim为第i个样本的第m个特征原始值。
其它步骤及参数与具体实施方式一或二相同。
具体实施方式四:本实施方式与具体实施方式一至三之一不同的是:所述步骤二中对步骤一得到的归一化训练集进行特征选择的具体过程为:
考虑影响能源效率的各种因素,建立特征空间,收集相应数据,样本数据进行无量纲化处理,进行特征选择。为了使特征选择的结果更加准确,本发明采用将信息增益和核主成份分析相结合的融合策略选取最终的特征。首先,利用信息增益计算得到特征排序,然后利用主成份分析方法做校核计算。
采用将信息增益和核主成份分析相结合的融合方法选取特征;即利用信息增益得到不同特征对应的信息增益,由大到小进行排序,得到特征相对重要性排序,利用主成份分析方法做校核计算。
核主成分分析KPCA是主成分分析PCA的非线性扩展,KPCA是在通过映射函数Φ把原始向量映射到高维空间F,在F上进行PCA分析,可以最大限度地抽取指标的信息。假设x1,x2,……xM为训练样本,用{xi}表示输入空间。KPCA方法的基本思想是通过某种隐式方式将输入空间映射到某个高维空间(常称为特征空间),并且在特征空间中实现主 成分分析PCA。
假设相应的映射为Φ,核函数K通过映射Φ将隐式的实现从点x到F的映射,并且由此映射而得的特征空间中数据满足中心化的条件[15],即
则特征空间中的协方差矩阵为:
现求C的特征值λ≥0和特征向量V∈F\{0},Cν=λν,并考虑到所有的特征向量可表示为Φ(x1),Φ(x2),...,Φ(xM)的线性则有
其中,v=1,2,...,M。定义M×M维矩阵K,能得到特征值和特征向量,对于测试样本在特征向量空间Vk的投影为
将内积用核函数替换则有
并且,可以进一步将核矩阵修正为
其它步骤及参数与具体实施方式一至三之一相同。
具体实施方式五:本实施方式与具体实施方式一至四之一不同的是:所述利用信息增益计算得到特征排序的具体过程为:
特征选择就是通过搜索数据集中的所有可能的特征集合,按照某种规则选取一组有效的特征以降低特征空间的维数。同时,通过去除特征空间的一些冗余信息来避免这些信息对分类预测的影响,从而提高分类算法的预测准确率和计算效率。信息增益(IG)是进行特征选择的最常用方法。
其中,在信息增益中,衡量标准是看特征能够为分类系统带来多少信息,带来的信息越多,该特征越重要。对一个特征而言,系统有它和没它时信息量将发生变化,而前后信息量的差值就是这个特征给系统带来的信息量。所谓信息量,就是熵。
设特征空间为X,样本第m个特征Xm,其信息增益IG(Xm)为:
IG(Xm)=H(C)-H(C|Xm)
其中C代表所需分类类别,H(C)代表C类所对应的信息熵,H(C|Xm)代表在特征Xm条件下,类所属为C时的信息熵;
假如类别C的取值为n种,每一种取到的概率为p(Cj),j=1,2,...,n,H(C)为:
其它步骤及参数与具体实施方式一至四之一相同。
具体实施方式六:本实施方式与具体实施方式一至五之一不同的是:所述步骤三中根据步骤一和步骤二建立多分类器融合的评价模型(即为训练后的决策树算法中的J48模型、基于规则的分类算法中的LogitBoost模型、基于元学习策略的JRip型学习器三者之间的并序融合),得到能源效率评价的分类结果的具体过程为:
本发明选择三种在很多领域都有良好分类效果的算法,包括决策树算法、基于规则的分类算法和基于元学习策略的元学习器。
决策树又称判定树,是以实例为基础的归纳学习算法,从一组无次序、无规则的元组中推理出决策树表示形式的分类规则。它采用自顶向下的递归方式,在决策树的内部节点进行属性值的比较,并根据不同的属性值从该节点向下分支。树中的每个非叶节点(包括根节点)对应训练样本集中一个非类别属性的测试,非叶节点的每个分支对应属性的一个测试结果,每个叶子节点则代表一个类或类分布。从根到叶节点的一条路径对应一条分类规则,整个决策树就对应着一组析取表达式规则。本发明使用广泛的C4.5算法。C4.5算法是针对早先的ID3算法进行改进而提出的,它采用基于信息增益率的方法选择测试属性,信息增益率等于信息增益对分割信息量的比值。本发明中,C4.5用J48决策树实现。
基于规则的分类是使用一组if…then规则来进行分类的方法。本发明使用JRip分类器建立规则,通过RIPPER算法来实现。RIPPER算法采用基于类的排序方案,属于同一类的规则在规则集合中一起出现,然后这些规则根据它们所属的类信息一起排序。同一类的规则间的相对顺序并不重要,因为它们属于同一类。该算法直接从数据中提取规则,在提取规则时,类y的所有训练记录被看作是正例,其他类的训练记录被看作反例。
元学习是在学习结果的基础上进行再学习或多次学习而得到最终结果。后经Freud和Schapire改进的一种机器学习方法Adboost算法则在实际中广泛应用。其基本思想是:基 于现有样本数据集构建一个基础的“弱分类器”,反复调用该“弱分类器”,通过对每轮错判的样本赋予更大的权重,使其更关注那些难判的样本,经过多轮循环,最终采用加权的方法将各轮的“弱分类器”合成“强分类器”。
多分类器融合策略总体上可以归纳为串序融合与并序融合。由于并行融合分类方式可以避免串序融合顺序不同而造成的分类结果不一致问题,各种分类器之间不存在相互影响的问题。因此,本发明选择并序融合的方式对期刊影响因子的各种属性进行分类,在并序融合分类器设计中,不同分类器的结果可能差生偏差,这就需要投票给出最终结果。简单投票方式是一种非常直观和高效的策略,不同分类器之间的权重是一致的,使得分类结果可解释较强。为了使得数据分类平均效果更好,需要对数据选择更加随机,因而本发明采用了十字交叉运算的形式选取数据。分类结果是10次分类的平均值,而且不同基分类器之间互不影响的。基于上述三种常用基分类器的多模型融合策略,如下图1所示。
对能源效率的分析归结为两类问题,即将数据集中的实例分为高能源效率和低能源效率两类,将分类数设为2,列标签值取0和1,0代表高能源效率,1代表低能源效率。
分类算法很多,本发明选择三种在很多领域都有良好分类效果的算法,包括决策树算法、基于规则的分类算法和基于元学习策略的元学习器,将三者进行有效融合,从而获得更加优化的基于多分类器融合的评价模型。
采用10折交叉验证的方法对获得的对步骤一和步骤二中所获的训练集分别进行J48、LogitBoost、JRip三种方法的分类模型训练,以保证模型泛化性能。
之后采取并序融合的方式,因为不同分类器的结果可能产生偏差,采取投票的方式给出最终结果。简单投票方式是一种非常直观和高效的策略,不同分类器之间的权重是一致的,使得分类结果可解释较强,分类结果为10次测试所得分类结果的平均值。
对步骤一中所得的归一化训练集分别进行决策树算法中的J48模型、基于规则的分类算法中的LogitBoost模型、基于元学习策略的JRip型学习器训练得到3种模型(得到的3中模型即为训练后的决策树算法中的J48模型、基于规则的分类算法中的LogitBoost模型、基于元学习策略的JRip型学习器);
以步骤二中所选择的特征作为模型输入变量,模型输出为0,1分类(其中,每种模型的训练均以步骤二中所选择的特征作为模型输入变量,0,1分类作为输出,0代表高能源效率,1代表低能源效率;采用的训练策略为10折交叉验证方法),0代表高能源效率,1代表低能源效率;采用的训练策略为10折交叉验证方法;
每当测试一个新样本,分别输入至所获得的3种模型中,得到3个结果,通过均权投 票(少数服从多数的投票方式)的方式得到分类结果。
其它步骤及参数与具体实施方式一至五之一相同。
具体实施方式七:本实施方式与具体实施方式一至六之一不同的是:所述步骤四中对步骤三得到的分类结果进行聚类分析,得到最终的聚类结果的具体过程为:
本发明选用Simple K-means、EM以及FCM三类算法作为融合基础。
Simple K-means即k均值聚类算法:首先要指定聚类的分类个数k,随机取k个样本作为初始类的中心,计算各样本与类中心的距离并进行归类,所有样本划分完成后重新计算类中心,重复这个过程直到类中心不再变化,所得的k类即最终聚类结果。
EM算法:最大期望(EM)算法是在概率模型中寻找参数最大似然估计或者最大后验估计的算法。可被看作为一个逐次逼近算法:事先并不知道模型的参数,可以随机的选择一套参数或者事先粗略地给定某个初始参数λ0,确定出对应于这组参数的最可能的状态,计算每个训练样本的可能结果的概率,在当前的状态下再由样本对参数修正,重新估计参数λ,并在新的参数下重新确定模型的状态,这样,通过多次的迭代,循环直至某个收敛条件满足为止,就可以使得模型的参数逐渐逼近真实参数。
FCM聚类方法:美国加州大学柏克莱分校的扎德教授第一次提出了“集合”的概念,经过十多年的发展,模糊集合理论渐渐被应用到各个实际应用方面。为克服非此即彼的分类缺点,出现了以模糊集合论为数学基础的聚类分析。用模糊数学的方法进行聚类分析,就是模糊聚类分析。FCM算法是一种以隶属度来确定每个数据点属于某个聚类程度的算法,是传统硬聚类算法的一种改进。
为了使聚类结果更加可信,本发明采用的多模型融合聚类分析方法如下:由于Simple K-means和EM两类算法是采用基于划分方法进行聚类的,因此选为基础聚类方法。并且,使用Make Density Based Clusterer对两种算法进行包装,使之能够为每个聚类拟合一个离散分布或一个对称的正态分布。实现从整体到局部逐渐聚类,局部搜索能力强,收敛速度快。将两者相同的聚类结果挑选出来作为初步融合聚类结果,然后利用FCM聚类方法进行校核计算,给出最终的融合聚类结果。具体如图2所示。
对于步骤三中分类结果中的能源高效类样本进行再分析,进行2聚类过程,进一步将高效类中的样本进行细分,筛选出其中能源效率较低者,再归至低效类,作为对步骤三的修正,以获得更加准确的结果。
选用Simple K-means、EM以及FCM三类算法作为融合基础。采用的多模型融合聚类分析方法如下:由于Simple K-means和EM两类算法是采用基于划分方法进行聚类的, 因此选为基础聚类方法。并且,使用Make Density Based Clusterer对两种算法进行包装,使之能够为每个聚类拟合一个离散分布或一个对称的正态分布。将两者相同的聚类结果挑选出来作为初步融合聚类结果,然后利用FCM聚类方法进行校核计算,给出最终的融合聚类结果。
其它步骤及参数与具体实施方式一至六之一相同。
实施例一:
算例数据样本获取及特征空间建立
本发明收集中国2005至2013年全国24个省市自治区(不含西藏、港澳台、吉林、黑龙江、贵州、云南、甘肃、青海)的面板数据。根据文献的研究成果,本发明所选取的特征空间包含一次能源生产量(F1)、能源消耗总量(F2)、能源消费弹性系数(F3)、GDP(F4)、能源工业投资额(F5)、单位生产总值能耗(F6)、资本存量(F7)、和二氧化硫排放系数(F8)这8个因子:
F1:生产一次能源的企业(单位)在报告期内将自然界现存的能源经过开采而产出的合格产品,如煤矿采掘的原煤,油田开采的原油,气田开采出的天然气、水电厂发的电等等。
F2:用能单位在统计报告期内实际消耗的各种能源实物量,取按规定的计算方法求和并与所需衡量单位折算后的数值。
F3:能源消费增长速度与国民经济增长速度之间比值。
F4:一个国家(国界范围内)所有常住单位在一定时期内生产的所有最终产品和服务的市场价格。GDP是国民经济核算的核心指标,也是衡量一个国家或地区总体经济状况重要指标。
F5:投入能源工业的资金总额。
F6:一定时期内,一个国家或地区每生产一个单位的国内生产总值所消耗的能源,即能源消耗总量与国内生产总值的比值。
F7:企业现存的全部资本资源,是已投入企业的各类资本的总和。它以资产形式存在又叫资产存量。根据它在生产过程中所处的状态可以划分为两类:即正在参与再生产的资产存量和处于闲置状态的资产存量包括闲置的厂房、机器设备等。
F8:每一种能源燃烧或使用过程中单位能源所产生的二氧化硫排放数量。
特征选择结果及分析
首先,对所取得样本数据进行无量纲化处理。然后,再进行特征选择计算分析。由于 能源效率的高低受到诸多因素影响,因此对能源效率的衡量要综合考虑多个指标,在此基础上,识别出关键影响因素,并据此对各地区未来能源效率的高低水平作出预测。
根据现有信息增益值选择和设置的研究结论,选择了信息增益值大于0.0025的6个特征将其排序。利用主成份分析方法进一步验证,得到的最终结果如表1所示:
表1不同特征对分类的信息增益排序
从特征选择结果可以看出:筛选出的表1中6个特征与类别属性的相关性较强,为能源效率的关键影响因素。其中,F6的影响程度最大,其次为F8,F7、F4、F1、F3这5个特征对能源效率的影响程度相近。而数据集中的F5、F2这两个特征被过滤,对能源效率几乎无影响。
分类结果及分析
本发明对能源效率的分析同样可以归结为两类问题,即将数据集中的实例分为高能源效率和低能源效率两类,所以此处将分类数设为2,列标签值取0和1,0代表高能源效率,1代表低能源效率。然后,选择F6、F8、F7、F4、F1、F3为能源效率的关键影响因素,去除数据集中F5和F2这两个属性。
选择通用衡量指标:正确率precision-rate(PR)、召回率recall-Rate(RR)和F-measure来评估实验中使用的三种分类器的性能。在计算正确率和召回率时,用到在ROC曲线分析中的四个指标:真阳性(TP)、假阳性(FP)、假阴性(FN)和真阴性(TN)。然后,取F-measure(FM)为正确率和召回率的调和平均值作为衡量分类器性能的关键指标。如表2所示,为能源效率影响因素数据集分别融合分类器及单一分类器的分类结果。其中,OVSM和MCF分别代表单一模型结果最优值和多模型融合结果。
表2数据集分别使用三种分类器的分类结果
从表2中可以发现,融合模型比比单一分类器性能更优越,也就意味着根据前文中选择的关键影响因素对能源效率进行分类处理的最好的分类器,该分类模型可用来对数据集中未包含的其他省市或其他年份的数据进行能源效率高低的预测。
预测结果及分析
收集了吉林、黑龙江、贵州、云南、甘肃、青海这六个省份2013年能源效率影响因素的数据,将6个特征值标准化后,应用上述分类模型进行预测,结果如下表3所示。
表3测试集分别使用三种分类器的预测结果
从表3中可以看出:每个省份分别使用融合分类器模型和单一分类器模型进行预测得到的结果是一致的。吉林、黑龙江、云南和甘肃均被预测为0类,属于高能源效率;而贵州、青海的预测结果为1类,即属于低能源效率。并且,融合分类模型的预测置信度要高于单一模型预测最优值,因此,此预测结果相比于单一模型更容易被采纳。
多模型融合策略及聚类结果分析
首先,使用单一的Simple K-means和EM两种算法的聚类结果如下:
1)K-means将216个实例划分为2类。cluster0实例计140个,占全部实例数百分比为65%;cluster1实例计76个,占全部实例数百分比为35%。对数据集中数据按年份进行比较,整体情况为:cluster0类F6比cluster1低,即每生产一个单位的国内生产总值的能源消耗低;F3较cluster1低,国民经济增长速度相同的时,cluster0类实例能源消费量增长速度低;F8较cluster1相对偏低,即cluster0单位能源燃烧所产生的二氧化硫排放数量较低,可见其对环境产生的污染因素相对低。可以确定,cluster0实例为能源高效类,cluster1实例为能源低效类。
2)利用EM聚类也将216例实例划分为2类,其中cluster0实例计118个,占实例数百分比为55%;cluster1实例计98个,占实例数百分比为45%。对数据集中同年份数据进行比较,cluster0类F6和F8总体低于cluster1,即能源消耗在经济增长上得到高效的使用的同时,对环境污染程度也相对低。由此确定cluster0实例为能源低效类,cluster1实例为能源高效类。
基于图2所示的初始融合策略,得到了初步的精度较高的聚类结果如表4所示:
表4我国各省能源效率的EM聚类结果
利用FCM对EM与K-means融合后的聚类结果进一步验证分析,聚类结果与表4相符。从表中可以看出:能源低效类实例数量随时间递增,从高效转变为低效的省份居多,如辽宁、上海、浙江、湖北、湖南、四川和陕西等。长期处于能源高效状态的有北京、福建、海南、江西等省份,而山西、山东、广东的能源利用长期处于低效状态。究其原因,各地区之间的横向差异可归因于经济结构差异,以技术密集型产业为支柱产业的地区能源效率普遍高,以传统制造业和加工业等为支柱产业的能源效率普遍低。并且,虽然全国数据显示单位GDP能耗有所减少,但能源消费弹性系数一直处于波动状态,环境污染治理成本在增加,能源损失量逐年增长。究其根本,我国长期以来能源结构不合理,多以煤炭为主要能源;经济发展方式主要依靠资源消耗,而不是依靠技术进步、管理创新的方式。 因此,需要优化能源结构、转变经济增长方式、依靠科学技术,以较低的能源消费弹性系数维持较高的经济增长,才是大幅度地提高能源效率的关键。
本实施例以中国各省份9年能源效率相关数据为算例,研究了基于多模型融合策略的能源效率分析评价方法,得出了以下结论:
1)基于所收集多种文献中提到的多种影响因素,将信息增益和主成份分析方法相结合实现特征选择,找到了影响能源效率的决定因素,从八种因素中识别出六种决定因素。
2)对我国各省之间能源效率建立三种单一分类器模型和多分类器融合模型,分类及预测的算例结果显示:多分类器融合模型的能源效率分类预测效果要比单一模型的分类预测效果要好。
3)基于多模型融合聚类分析方法,发现了我国各地区的能源效率的差异性及变化规律,并给出了相应的原因分析和发展建议。
因此,中国能源效率改进的努力方向在于:着眼于能源效率关键影响因素,科学、有针对性地优化能源结构、转变经济增长方式。鼓励和支持技术发明创造(特别是能源技术领域),推动能源利用各个环节的技术创新,从而实现以较低的能源消费弹性系数维持较高的经济增长。另外,在综合考虑能源供需形势和能源利用技术的基础上,需要按照兼顾传统能源和新能源的原则进行能源消费结构优化和调整。
本发明还可有其它多种实施例,在不背离本发明精神及其实质的情况下,本领域技术人员当可根据本发明作出各种相应的改变和变形,但这些相应的改变和变形都应属于本发明所附的权利要求的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!