一种改进的并行通道卷积神经网络训练方法与流程
本发明属于深度学习以及大数据技术领域,具体涉及一种改进的并行通道卷积神经网络训练方法。
背景技术:
随着社会的发展,大数据时代的来临,与之相关的技术不断发展和创新。深度学习因其能利用海量数据并通过更深层网络的训练提高分类正确率,在近年来取得一些列突破性进展。学者们都试图通过增加卷积神经网络的规模来提升其性能,而增加网络规模最简单的方式就是增加“深度”。
然而基于传统卷积神经网络的结构搭建的深度网络,随着网络层数的增加,精度会达到饱和,甚至降低。文献“romeroa,ballasn,kahouse,etal.fitnets:hintsforthindeepnets[j].arxivpreprintarxiv:1412.6550,2014.”中提出一种多阶段训练方法,先分别训练多个浅层网络,最后将多个浅层网络进行组合,从而实现一个深层网络。这样做需要人为地分别对多个网络参数进行调节,耗时耗力,且分别训练多个浅层网络会丢失网络之间的关联信息,将对网络最后的性能产生影响。文献“leecy,xies,gallagherp,etal.deeply-supervisednets[c]//proceedingsoftheeighteenthinternationalconferenceonartificialintelligenceandstatistics.2015:562-570”则在深度卷积神经网络的隐藏层引入了多个辅助分类器,该方法虽然可以一定程度地补偿深层网络误差反向传导时的梯度消失问题,但是引入的辅助分类器也会对网络最后的精度产生影响。
更深度的网络无法训练的问题一直没有从根本上解决,所提出的网络结构仍然是基于传统卷积神经网络设计的,只是在训练过程中使用了各种优化技巧,如:更好的网络初始化参数、更高效的激励函数等。
技术实现要素:
为了解决上述问题,本发明的目的在于提供一种改进的并行通道卷积神经网络训练方法。
为了达到上述目的,本发明提供的改进的并行通道卷积神经网络训练方法包括按顺序进行的下列步骤:
1)分别利用直连和卷积两个并行通道对卷积神经网络中的数据进行特征提取,得到直连通道特征矩阵和卷积通道特征矩阵;
2)将步骤1)得到的两个特征矩阵进行合并,并输入到最大池化层和均值池化层进行数据降维;
3)重复步骤1)、步骤2),得到最终特征矩阵;
4)将上述步骤3)得到的最终特征矩阵进行全局平均池化并输入全连接层变为一维特征矩阵,并利用softmax分类器对一维特征矩阵进行分类而对卷积神经网络进行训练,计算此次网络训练的损失值;
5)利用误差反向传播算法进行梯度计算,计算各层误差项和权值梯度;
6)根据步骤4)中所得损失值判断网络是否收敛,如不收敛,依据步骤5)中获得的权值梯度调整卷积神经网络初始化参数并重新进行训练,如已收敛则输出网络训练结果。
在步骤1)中,所述的分别利用直连和卷积两个并行通道对卷积神经网络中的数据进行特征提取,得到直连通道特征矩阵和卷积通道特征矩阵的方法是:首先,将数据分别输入直连通道和卷积通道;然后在直连通道中直接将数据映射为直连通道特征矩阵作为输出,在卷积通道上利用多个卷积层对数据进行卷积操作,每个卷积层的输入是上一个卷积层的输出,将最后一个卷积层输出矩阵作为卷积通道的特征矩阵。
在步骤2)中,所述的将步骤1)得到的两个特征矩阵进行合并,并输入到最大池化层和均值池化层进行数据降维的方法是:首先,将直连通道所得特征矩阵和卷积通道所得特征矩阵进行合并,即得到多个特征矩阵的集合;然后分别将所得特征矩阵输入最大池化层和均值池化层,在最大池化层,使用滤波器取滤波器内值的最大值,在均值池化层使用滤波器取滤波器内的平均值。
在步骤4)中,所述的将上述步骤3)得到的最终特征矩阵进行全局平均池化并输入全连接层变为一维特征矩阵,并利用softmax分类器对一维特征矩阵进行分类而对卷积神经网络进行训练,计算此次网络训练的损失值的方法是:首先,对最终特征矩阵进行全局平均池化,使用和最终特征矩阵大小一致的滤波器计算特征矩阵中数据的平均值;然后,输入全连接层,全连接层中每个神经元分别对全局平均池化后的特征矩阵中的数据进行非线性变换得到一维特征矩阵;最后,将一维特征矩阵输入softmax分类器进行分类。
在步骤5)中,所述的利用误差反向传播算法进行梯度计算,计算各层误差项和权值梯度的方法是:首先,根据softmax分类器结果计算最后一层损失值并作为最后一层的误差项;然后,利用误差反向传播算法的链式法则计算各层误差项,第l个卷积层的第i个特征矩阵的误差项为:
m为l+1层的特征矩阵个数,
最后,利用公式
在步骤6)中,所述的根据步骤4)中所得损失值判断网络是否收敛,如不收敛,依据步骤5)中获得的权值梯度调整卷积神经网络初始化参数并重新进行训练,如已收敛则输出网络训练结果的方法是:首先,将分类结果和实际值比对并计算差值而作为损失值;然后将损失值和实现设定的分类阈值做比较,如小于分类阈值则判定网络收敛,否则不收敛;最后,如收敛输出网络结果,否则根据公式
本发明提供的改进的并行通道卷积神经网络训练方法的优点在于:1)通过直连通道的引入可保证数据在网络中的流通性,克服了深层卷积神经网络训练时梯度不稳定的难题,可训练更深层的网络;2)利用最大池化和均值池化,可使两次特征提取间的特征矩阵维度保持一致且可结合两种池化方法的优点。
附图说明
图1为本发明提供的改进的并行通道卷积神经网络训练方法流程图。
图2为特征提取部分的并行通道结构图;
图3为双池化层示意图;
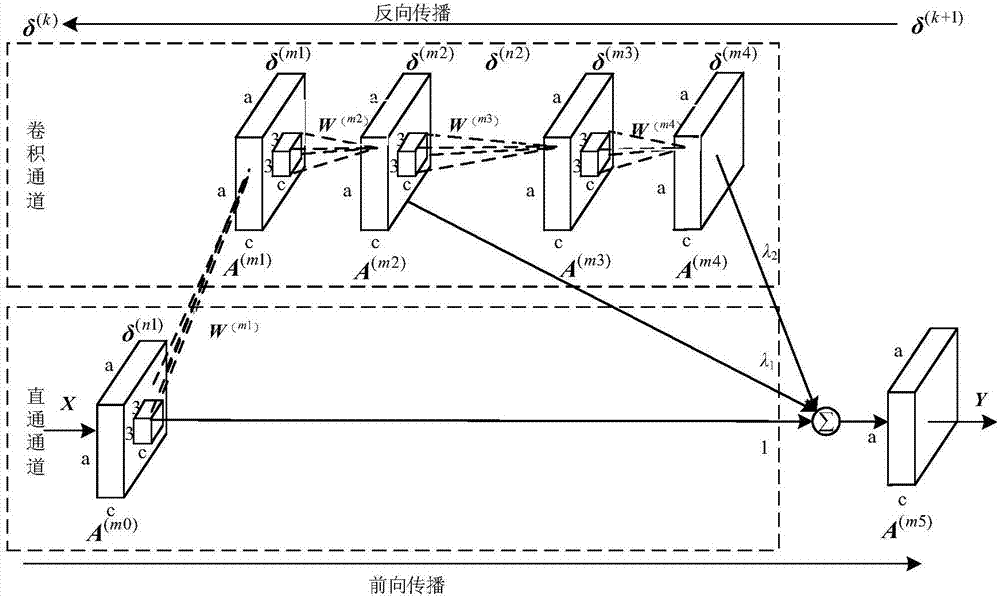
图4为并行通道卷积神经网络误差项计算示意图;
图5为在cifar-10数据集上不同池化方式的性能比较;
图6为本发明在cifar-10数据集上训练正确率随迭代次数的变化曲线。
具体实施方式
下面结合附图和具体实施例对本发明提供的改进的并行通道卷积神经网络训练方法进行详细说明。
如图1所示,本发明提供的改进的并行通道卷积神经网络训练方法包括按顺序进行的下列步骤:
1)分别利用直连和卷积两个并行通道对卷积神经网络中的数据进行特征提取,得到直连通道特征矩阵和卷积通道特征矩阵;
将由数万张大小为32×32的彩色图像组成的数据集输入到卷积神经网络中,本发明采用由6万张大小为32×32的彩色图像组成的cifar-10数据集,然后分别利用直连和卷积两个并行通道对数据集中的数据进行特征提取,并行通道结构详见图2。在直连通道中,使用映射函数y=x提取直连通道特征矩阵;在卷积通道中,所有卷积核尺寸为3×3、步长为1且都仅仅使用了权重项来对上一层输出特征矩阵进行卷积,没有使用偏置项,故第l层的第j幅卷积响应特征矩阵
式中,m表示上一层输出特征矩阵的集合;
对卷积响应特征矩阵上每一个神经元利用relu激活函数进行非线性变换,得到第l层特征矩阵为
2)将步骤1)得到的两个特征矩阵进行合并,并输入到最大池化层和均值池化层进行数据降维;
在进行特征矩阵合并时,将每两个卷积层得到的特征矩阵和直连通道特征矩阵做一次累加,记为一个累加模块。为方便描述,将两个卷积层记为一个卷积模块,每两个累加模块记为一个结构快,并对卷积模块所得特征矩阵加入卷积衰减因子,则每个结构块所得特征矩阵定义如下:
y=λ1hn1(x,{w(n1)})+λ2hn2[hn1(x,{w(n1)}),{w(n2)}]+x(3)
式中,x和y分别表示结构块的输入和输出数据;λ1和λ2即为“卷积衰减因子”,是一个需要提前设置的常量,这里为每个卷积模块都分别设置了不同大小的卷积衰减因子;w(n1)和w(n2)分别表示两次累加时特征矩阵权值参数的集合,是需要训练的参数;hn1(·)和hn2(·)分别表示第一次累加和第二次累加的等效转换函数。
其中,第一次累加的等效转换函数hn1(·)的表达式为:
hn1(x,{w(n1)})=w(m2)⊙f(w(m1)⊙x)(4)
第二次累加的等效转换函数hn2(·)的表达式为:
hn2(yn1,{w(n2)})=w(m4)⊙f(w(m3)⊙yn1)(5)
为了方便描述,令yn1=hn1(x,{w(n1)}),yn2=hn2(yn1,{w(n2)}),故式(3)还可以描述成如下形式:
y=λ1yn1+λ2yn2+x(6)
为进一步对数据降维,减少深层网络计算量,对上述合并后的特征矩阵进行最大池化和均值池化,双池化方式如图3所示,两种池化方法均采用尺寸为3×3、步长为2的滤波器;其中最大池化的滤波器是过滤选择最大值,可尽可能保留特征矩阵的显著性信息;均值池化是计算滤波器中对应特征的均值,可保留特征矩阵的背景信息。通过双池化,特征矩阵个数增倍,单个矩阵的维度减半。实验显示,在cifar-10数据集上双池化的池化方式比单一池化方式可以得到更高的分类准确率,如图5所示。
3)重复步骤1)、步骤2),得到最终特征矩阵;
由于数据集中彩色图像大小为32×32,因此对特征矩阵进行两次特征提取和双池化,得到最终特征矩阵,这样可以尽可能加深网络深度。
4)将上述步骤3)得到的最终特征矩阵进行全局平均池化并输入全连接层变为一维特征矩阵,并利用softmax分类器对一维特征矩阵进行分类而对卷积神经网络进行训练,计算此次网络训练的损失值;
将上述步骤3)得到的最终特征矩阵进行全局平均池化并输入全连接层,可得特征维度为(1×1)×q的特征矩阵,使用softmax分类器对其分类,其中,q为分类类别数,对于每类有r个样本的集合可以表示为{(x(1),y(1)),(x(2),y(2)),...(x(r),y(r))},y(r)∈{1,2,…,q}。计算此次网络训练的损失值的方法是:首先,计算每个类别j出现的概率p(y=j|x);然后用hθ(x)表示q个输出概率,则函数为:
其中,hθ(x)表示卷积神经网络的输出,i为样本序号,θ为网络参数,
最后使用交叉熵作为损失函数计算损失值,其表达式为:
其中l表示损失值,1{y(i)=j}表示当y(i)=j时值为1,否则为0,r为样本数。
5)利用误差反向传播算法进行梯度计算,计算各层误差项和权值梯度;
在进行反向传播计算误差项时最后一层误差值等于损失值,即δ(0)=l,第k个累加模块的误差项等于第k+1个累加模块的误差项乘以两者之间的连接权值。故第k个累加模块误差项δ(k)为:
δ(k)=δ(n1)+δ(k+1)(9)
式中δ(k+1)为第k+1个累加模块的误差项;δ(n1)为该累加模块卷积通道的误差项。计算式(9)的关键是计算出δ(n1),然后就可以通过式(9)依次求出其余累加模块的误差项:
上式中,λ1和λ2分别为两个卷积模块的卷积衰减因子,均设置为小于1的正整数;δ(m1)、δ(m2)、δ(m3)和δ(m4)依次为图4中四个卷积层的误差项;δ(n1)和δ(n2)分别为两个卷积通道的误差项。
将式(10)中每层的误差项依次代入可以得到卷积通道的误差项:
式(11)中①式和②式正好分别为等效转换函数式(4)和式(5)的导数和,故可将式(11)简写为:
δ(n1)=[(λ2δ(k+1))*hn1′(a(m0))+λ1δ(k+1)]*hn2′(a(m2))(12)
将式(12)代入式(7),就可以逐一计算出双通道卷积神经网络所有累加模块的误差项。
根据bp链式法则和梯度计算公式
6)根据步骤4)中所得损失值判断网络是否收敛,如不收敛,依据步骤5)中获得的权值梯度调整卷积神经网络初始化参数并重新进行训练,如已收敛则输出网络训练结果。
根据步骤4)中损失函数计算的损失值,将损失值和分类阈值进行比较,如小于分类阈值则网络收敛;否则根据步骤5)中所得权值梯度按照式(14)、(15)更新权值梯度,并重新训练网络。
w(t+1):=w(t)+v(t+1)(15)
式中t表示迭代次数,v(t)是动量项,μ为动量因子,它决定了历史权重修正量对本次权重修正的贡献大小;η为学习率;λ为权重衰减系数。
本发明通过直连通道的引入,克服了深层卷积神经网络梯度不稳定的难题,可尽可能加深网络,从而提高分类准确率。从cifar-10数据集上的测试结果可知,随着卷积神经网络深度的增加,分类正确率提高,详见图6。
- 还没有人留言评论。精彩留言会获得点赞!