在Hive中连接运算的转化方法及装置与流程
【
技术领域:
】本发明涉及数据处理领域,具体涉及一种在hive中连接运算的转化方法及装置。
背景技术:
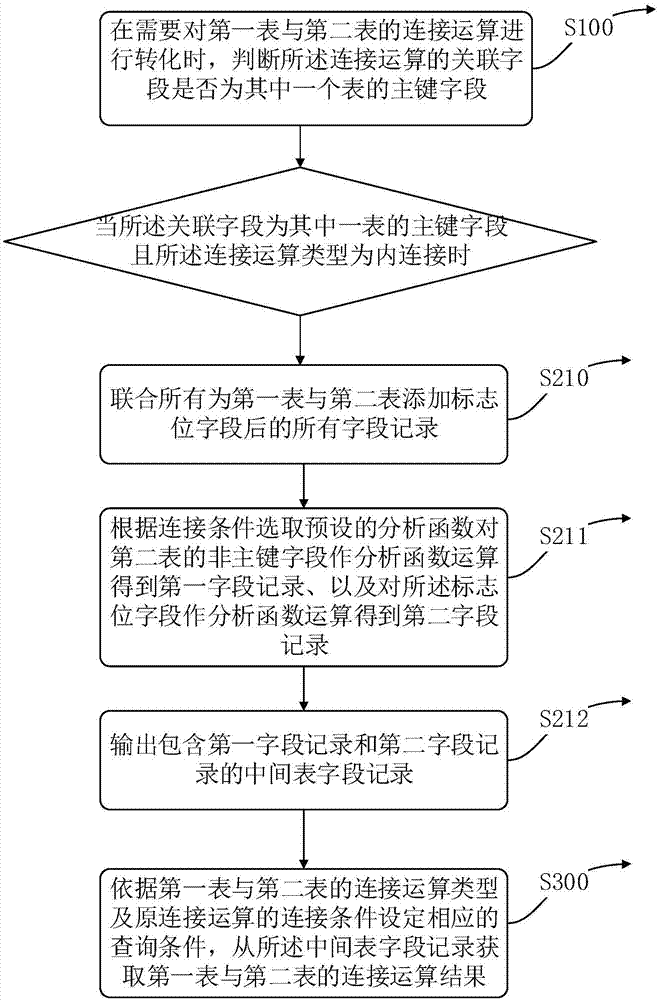
:结构化查询语言(structuredquerylanguage)简称sql,是一种数据库查询和程序设计语言,用于存取数据以及查询、更新和管理数据库系统。在数据库查询中,往往涉及join运算,join是sql中的连接查询,连接查询是数据库中最主要的查询之一,连接查询包括内连接、外连接和交叉连接等,通过连接运算符可以实现多个表查询。在大数据时代,在进行大数据计算时,基于hadoop(一个由apache基金会所开发的分布式系统基础架构)的数据仓库工具hive将结构化的数据文件映射为一张张数据库表,并将sql语句转化为任务在hadoop上运行;在大数据计算时,涉及大量的连接查询,但由于连接运算的效率比较低,尤其随着数据量的增长,连接运算的效率更是越来越低,无法满足数据量巨大的大数据运算所需的高效率要求。技术实现要素:本发明的目的在于提供一种在hive中连接运算的转化方法及装置,将进行数据库操作时的连接运算转化为非连接运算,以此提高数据库查询效率。为实现该目的,本发明采用如下技术方案:第一方面,本发明的一个实施例提供了一种在hive中连接运算的转化方法,包括如下步骤:在需要对第一表与第二表的连接运算进行转化时,判断所述连接运算的关联字段是否为其中一个表的主键字段;当所述关联字段为其中一个表的主键字段时,从已联合所有第一表与第二表的字段记录中对预设字段作分析函数运算,以获取对应的中间表字段记录;依据第一表与第二表的连接运算类型及原连接运算的连接条件设定相应的查询条件,从所述中间表字段记录获取第一表与第二表的连接运算结果。进一步的,所述方法还包括,当所述关联字段同为两个表的主键字段时,从已联合所有第一表与第二表的字段记录中对预设字段作聚合函数运算,以获取对应的中间表字段记录。具体的,所述连接运算类型包括内连接及外连接,所述外连接包括左外连接和右外连接。具体的,当所述关联字段为其中一表的主键字段且所述连接运算类型为内连接时,所述从已联合所有第一表与第二表的字段记录中对预设字段作分析函数运算,以获取对应的中间表字段记录的步骤,包括:联合所有为第一表与第二表添加标志位字段后的所有字段记录,所述预设字段包括第二表的非主键字段及所述标志位字段;根据连接条件选取预设的分析函数对第二表的非主键字段作分析函数运算得到第一字段记录、以及对所述标志位字段作分析函数运算得到第二字段记录;输出包含第一字段记录和第二字段记录的中间表字段记录;当所述关联字段为其中一个表的主键字段且所述连接运算类型为外连接时,定义左外连接的左表为主表及右表为副表,或右外连接的右表为主表及左表为副表,所述从已联合所有第一表与第二表的字段记录中对预设字段作分析函数运算以获取对应的中间表字段记录的步骤,包括:联合所有为主表与副表添加标志位字段后的所有字段记录,所述预设字段包括副表的非主键字段;根据连接条件选取预设的分析函数对副表的非主键字段作分析函数运算得到第三字段记录;输出包含第三字段记录的中间表字段记录。具体的,当所述关联字段同为两个表的主键字段且所述连接运算类型为内连接时,所述从已联合所有第一表与第二表的字段记录中对预设字段作聚合函数运算以获取中间表字段记录的步骤,包括:联合所有为第一表与第二表添加标志位字段后的所有字段记录,所述预设字段包括第一表与第二表的非主键字段;根据所述关联字段对联合所有的结果记录进行分组;对分组后的非主键字段作聚合函数运算得到对应的非主键字段记录;输出包含所述对应的非主键字段记录的中间表字段记录;当所述关联字段同为两个表的主键字段且所述连接运算类型为外连接时,定义左外连接的左表为主表及右表为副表、或右外连接的右表为主表及左表为副表,所述从已联合所有第一表与第二表的字段记录中对预设字段作聚合函数运算以获取对应的中间表字段记录的步骤,包括:联合所有为主表与副表添加标志位字段后的所有字段记录,所述预设字段包括副表的非主键字段及所述标志位字段;根据所述关联字段对联合所有的结果记录进行分组;对分组后的副表的非主键字段作聚合函数运算得到第四字段记录及对标识为字段作聚合函数运算得到第五标志位字段记录;输出包含第四字段记录及第五标志位字段记录的中间表字段记录。更进一步的,在联合所有第一表与第二表的字段记录时,对于存在于第一表而不存在于第二表、和存在于第二表而不存在于第一标的字段记录以null表示。具体的,所述标志位字段用于表征字段记录的来源表。进一步的,所述方法还包括步骤:根据所述第一表与第二表的连接运算结果选取所需查询的字段记录。更进一步的,所述方法还包括步骤:将所述选取的字段记录作为新表的字段记录以供与第三表做连接运算及连接运算的转化。第二方面,本发明的另一个实施例中提供了一种在hive中连接运算的转化装置,其在计算机上运行,包括:判断模块:用于在需要对第一表与第二表的连接运算进行转化时,判断所述连接运算的关联字段是否为其中一个表的主键字段;获取模块:用于当所述关联字段为其中一个表的主键字段时,从已联合所有第一表与第二表的字段记录中对预设字段作分析函数运算,以获取对应的中间表字段记录;输出模块:用于依据第一表与第二表的连接运算类型及原连接运算的连接条件设定相应的查询条件,从所述中间表字段记录获取第一表与第二表的连接运算结果。与现有技术相比,本发明具备如下优点:本发明的一个实施例中,针对在大数据中面临所处理的数据量越来越大,计算难度越来越大,计算效率要求越来越高的问题,提出了一种在hive中连接运算的转化方法。在判断连接运算的两个表的关联字段为其中一个表的主键字段的条件下,利用联合所有运算及分析函数巧妙地将连接运算转化为非连接运算,以此规避数据处理中常用的连接运算,避免作连接运算的两个表数据量巨大而导致连接效率低下或几乎无法运算的问题,提高数据库的查询效率,降低终端运算压力。同时,在连接运算的两个表的关联字段同为两个表的主键字段的条件下,利用联合所有运算及聚合函数巧妙地将连接运算转化为非连接运算,同样以此规避连接运算,提高数据库查询效率。显然,上述有关本发明优点的描述是概括性的,更多的优点描述将体现在后续的实施例揭示中,以及,本领域技术人员也可以本发明所揭示的内容合理地发现本发明的其他诸多优点。本发明附加的方面和优点将在下面的描述中部分给出,这些将从下面的描述中变得明显,或通过本发明的实践了解到。【附图说明】图1为本发明在hive中连接运算的转化方法的一种实施例的流程示意图;图2为本发明基于关联字段为其中一个表的主键字段的一种实施例的流程示意图;图3为本发明基于关联字段为其中一个表的主键字段的另一种实施例的流程示意图;图4为本发明在hive中连接运算的转化方法的另一实施例的流程示意图;图5为本发明基于关联字段同为两个表的主键字段的一种实施例的流程示意图;图6为本发明基于关联字段同为两个表的主键字段的另一种实施例的流程示意图;图7是本发明hive中连接运算的转化装置的一种实施例的模块化示意图。【具体实施方式】下面详细描述本发明的实施例,所述实施例的示例在附图中示出,其中自始至终相同或类似的标号表示相同或类似的元件或具有相同或类似功能的元件。下面通过参考附图描述的实施例是示例性的,仅用于解释本发明,而不能解释为对本发明的限制。本
技术领域:
技术人员可以理解,除非另外定义,这里使用的所有术语(包括技术术语和科学术语),具有与本发明所属领域中的普通技术人员的一般理解相同的意义。还应该理解的是,诸如通用字典中定义的那些术语,应该被理解为具有与现有技术的上下文中的意义一致的意义,并且除非像这里一样被特定定义,否则不会用理想化或过于正式的含义来解释。需要说明的是,本发明的一个实施例中提出了一种在hive中连接运算的转化方法,可以通过编程将该方法实现为计算机程序在终端设备上实现,所述终端设备包括但不限于计算机、网络主机、单个网络服务器、多个网络服务器集或多个服务器构成的云。第一方面,如图1所示是本发明的一个实施例中在hive中连接运算的转化方法的流程示意图,包括步骤s100-s300。步骤s100:在需要对第一表与第二表的连接运算进行转化时,判断所述连接运算的关联字段是否为其中一个表的主键字段。在数据库管理系统中,当检索数据需要对存放在多个表中的不同实体的信息进行查询时,需要通过连接运算实现多个表的连接查询,连接查询是数据库管理系统中最主要的查询之一,连接运算的类型主要包括内连接、外连接及交叉连接。在本发明实施例中,在需要对两个表进行连接运算以实现两个表的连接查询时将所述连接运算转化为非连接运算,以此提高数据库查询效率。具体的,在本方案的一个实施例中首先判断第一表与第二表的连接运算的关联字段是否为其中一个表的主键字段,所述关联字段是连接查询中表中含义相同的字段,在连接运算时根据关联字段之间的运算关系构成连接条件以实现两个表的连接运算。在本实施例中关联字段也即为第一表与第二表中含义相同的字段;所述主键字段是表中的一个或多个字段,主键字段的值用于唯一地标识表中的一条记录。步骤s200:当所述连接运算的关联字段为其中一个表的主键字段时,从已联合所有第一表与第二表的字段记录中对预设字段作分析函数运算以获取中间表字段记录。步骤s300:根据第一表与第二表的连接运算类型及连接条件,设定相应的查询条件从所述中间表字段记录获取第一表与第二表的连接运算结果。当连接运算的关联字段为第一表或第二表的主键字段时,首先对第一表和第二表的字段作联合所有运算得到联合所有运算结果,然后对联合所有运算结果中的预设字段作分析函数运算,所述预设字段包括第一表或第二表的主键字段、非主键字段或下述的标志位字段,以此可以获得包含关联字段、第一表的非主键字段、第二表的非主键字段及对预设字段做分析函数运算后的中间表字段记录。然后,根据第一表与第二表的连接运算类型及原连接运算的连接条件设定相应的查询条件以从所述中间表字段记录中获取第一表与第二表的连接运算结果,至此将第一表与第二表的连接运算转化为非连接运算,不再需要直接对第一表与第二表进行连接运算,避免连接运算效率低下的问题,提高数据库查询效率,降低终端运算压力;最后再根据所述第一表与第二表的连接运算结果选取所需查询的字段记录。本发明的一个实施例中,所述连接运算类型包括内连接(join/innerjoin)和外连接,所述外连接包括左外连接(leftjoin)及右外连接(rightjoin)。表1-1表示关联字段为其中一个表的主键字段的示意性实施例,并示出了表dw_a、表dw_b的表结构,表dw_b、dw_a分别为本发明实施例所述的第一表和第二表。其中,表dw_a与表dw_b的关联字段为key_1、key_2,并且,key_1、key_2是表dw_a的主键字段。表1-1dw_a与dw_b的表结构如表1-2所示是表dw_a、表dw_b的字段记录。表dw_a的字段记录如下:key_1key_2col_a_1011102113024表dw_b的字段记录如下:key_1key_2col_b_1col_b_20132102120132133表1-2dw_a与dw_b的表记录如图2所示是本发明基于关联字段为其中一个表的主键字段的一种实施例,当所述关联字段为其中一个表的主键字段且所述连接运算类型为内连接时,步骤s200包括步骤s210-s212:步骤s210:联合所有为第一表与第二表添加标志位字段后的所有字段记录;步骤s211:根据连接条件选取预设的分析函数对第二表的非主键字段作分析函数运算得到第一字段记录、以及对所述标志位字段作分析函数运算得到第二字段记录;步骤s212:输出包含第一字段记录和第二字段记录的中间表字段记录;步骤s300:依据第一表与第二表的连接运算类型及原连接运算的连接条件设定相应的查询条件,从所述中间表字段记录获取第一表与第二表的连接运算结果。其中,在联合所有第一表与第二表的所有字段记录时,对于存在于第一表而不存在于第二表、和存在于第二表而不存在于第一标的字段记录以null表示,并且利用所述标志位字段表征字段记录的来源表,最后再根据所述第一表与第二表的连接运算结果选取所需查询的字段记录。例如,现需要将表dw_b、表dw_a中具有相同关联字段的记录关联起来。利用现有的内连接运算的算法如下:selectkey_1,key_2,a.col_a_1,b.col_b_1,b.col_b_2fromdw_bbjoindw_aaona.key_1=b.key_1anda.key_2=b.key_2;根据本实施例方案将所述内连接运算进行转化,转化后的算法如下:其中,首先为表dw_b与表dw_a添加标志位字段flag,并定义表dw_a的标志位字段记录为1,表dw_b的标志位字段记录为0,然后联合所有为第一表与第二表添加标志位字段后的所有字段记录,即unionall所对应的2个select语句;由于连接条件为a.key_1=b.key_1anda.key_1=b.key_2,即表dw_b与表dw_a中具有相同key_1、key_1的记录,因此所述预设字段即为第二表的非主键字段及所述标志位字段,因此选取分析函数max(x)over(partitionbykey_1,key_2)x对表dw_a的非主键字段col_a_1作分析函数运算,该分析函数是将与本行的key_1、key_2相同的记录的col_a_1字段汇总在一起再进行聚合函数max运算,如此便从表dw_a中获取了字段col_a_1作为第一字段记录,同样地,对所述标志位字段作分析函数运算得到第二字段记录以用于表明字段记录存在于表dw_a;然后输出一个虚拟的中间表,其包含了所述第一字段记录及第二字段记录;最后设定表征记录存在于表dw_b且“key_1、key_2”存在于表dw_a的查询条件“whereflag=0andaflag=1”从所述中间表记录获取表dw_b与表dw_a的内连接运算结果;最后select出所需的字段记录即可。本实施例所输出的结果为:key_1key_2col_a_1col_b_1col_b_20113210221如图3所示是本发明基于关联字段为其中一个表的主键字段的另一种实施例,当所述关联字段为其中一个表的主键字段且所述连接运算类型为外连接时,定义左外连接的左表为主表、右外连接的右表为主表,如dw_aleftjoindw_b,表dw_a即为主表,dw_arightjoindw_b,表dw_b即为主表,相应的,另一个表即为副表,在本实施例中,步骤s200包括步骤s220-s223:步骤s220:联合所有为主表与副表添加标志位字段后的所有字段记录;步骤s221:根据连接条件选取预设的分析函数对副表的非主键字段作分析函数运算得到第三字段记录;步骤s222:输出包含第三字段记录的中间表字段记录;步骤s300:依据第一表与第二表的连接运算类型及原连接运算的连接条件设定相应的查询条件,从所述中间表字段记录获取第一表与第二表的连接运算结果。同样的,在联合所有第一表与第二表的所有字段记录时,对于存在于第一表而不存在于第二表和存在于第二表而不存在于第一标的字段记录以null表示,并且利用所述标志位字段表征字段记录的来源表,最后再根据所述第一表与第二表的连接运算结果选取所需查询的字段记录。例如,现需要将表dw_b的col_b_1、col_b_2同表dw_a的col_a_1关联起来并保留表dw_b的字段记录。利用现有的外连接运算的算法如下:selectb.key_1,b.key_2,a.col_a_1,b.col_b_1,b.col_b_2fromdw_bbleftjoindw_aaona.key_1=b.key_1anda.key_2=b.key_2;根据本实施例方案将所述外连接运算进行转化,转化后的算法如下:其中,为表dw_b与表dw_a添加标志位字段flag,并定义表dw_a的标志位字段记录为1,表dw_b的标志位字段记录为0,然后联合所有为第一表与第二表添加标志位字段后的所有字段记录,即unionall所对应的2个select语句;由于连接条件为a.key_1=b.key_1anda.key_1=b.key_2,即表dw_b与表dw_a中具有相同key_1、key_1的记录,所述预设字段为副表的非主键字段,因此选取分析函数max(x)over(partitionbykey_1,key_2)x对表dw_a的非主键字段col_a_1作分析函数运算,该分析函数是将与本行的key_1、key_2相同的记录的col_a_1字段汇总在一起再进行聚合函数max运算,如此便从表dw_a中获取了字段col_a_1作为第三字段记录;然后输出一个虚拟的中间表,其包含了所述第三字段记录;最后设定表征记录来源于主表的查询条件“whereflag=0”从所述中间表记录获取表dw_b与表dw_a的外连接运算结果;最后select出所需的字段记录即可。本实施例所输出的结果为:key_1key_2col_a_1col_b_1col_b_2011321022120null1321null33本发明还包括关联字段同为两个表的主键字段的情况,当所述关联字段同为两个表的主键字段时,本发明实施例的流程示意图如图4所示,包括如下步骤:步骤s100:在需要对第一表与第二表的连接运算进行转化时,判断所述连接运算的关联字段是否为其中一个表的主键字段;步骤s2000:当所述关联字段同为两个表的主键字段时,从已联合所有第一表与第二表的字段记录中对预设字段作聚合函数运算,以获取对应的中间表字段记录;步骤s300:依据第一表与第二表的连接运算类型及原连接运算的连接条件设定相应的查询条件,从所述中间表字段记录获取第一表与第二表的连接运算结果。同样的,本发明实施例中,所述连接运算的类型包括内连接(join/innerjoin)和外连接,所述外连接包括左外连接(leftjoin)及右外连接(rightjoin)。所述预设字段包括第一表或第二表的主键字段、非主键字段或下述的标志位字段。表1-3表示关联字段同为两个表的主键字段的示意性实施例,并示出了表dw_a、表dw_b的表结构,表dw_a、dw_b分别为本发明实施例所述的第一表和第二表。其中,表dw_a与表dw_b的关联字段为key_1、key_2,并且,key_1、key_2同为表dw_a与表dw_b的主键字段。表1-3dw_a与dw_b的表结构如表1-4所示是表dw_a、表dw_b的字段记录。表dw_a的字段记录如下:表dw_b的字段记录如下:key_1key_2col_b_1col_b_20132102120132133表1-4dw_a与dw_b的表记录如图5所示是本发明基于关联字段同为两个表的主键字段的一种实施例,当所述关联字段同为两个表的主键字段且所述连接运算类型为内连接时,步骤s2000包括步骤s2010-s2013。步骤s2010:联合所有为第一表与第二表添加标志位字段后的所有字段记录;步骤s2011:根据所述关联字段对联合所有的结果记录进行分组;步骤s2012:对分组后的非主键字段作聚合函数运算得到对应的非主键字段记录;步骤s2013:输出包含所述对应的非主键字段记录的中间表字段记录;步骤s300:依据第一表与第二表的连接运算类型及原连接运算的连接条件设定相应的查询条件,从所述中间表字段记录获取第一表与第二表的连接运算结果。其中,在联合所有第一表与第二表的所有字段记录时,对于存在于第一表而不存在于第二表和存在于第二表而不存在于第一标的字段记录以null表示,并且利用所述标志位字段表征字段记录的来源表,最后再根据所述第一表与第二表的连接运算结果选取所需查询的字段记录。例如,现需要将表dw_a的col_a_1同表dw_b的col_b_1、col_b_2关联起来。利用现有的内连接运算的算法如下:selecta.key_1,a.key_2,a.col_a_1,b.col_b_1,b.col_b_2fromdw_aajoindw_bbona.key_1=b.key_1anda.key_2=b.key_2;根据本实施例方案将所述内连接运算进行转化,转化后的算法如下:由于所需的字段记录的关联字段同时需存在于表dw_a与表dw_b,故不需要为表dw_a与表dw_b添加标志位字段,或说表dw_a与表dw_b的标志位字段记录相同,然后联合所有表dw_a与表dw_b的字段记录,即unionall所对应的2个select语句;然后根据所述关联字段对联合所有的结果记录进行分组,即groupbykey_1,key_2,本实施例中所述预设字段即为第一表与第二表非主键字段,然后对分组后的非主键字段作聚合函数运算以从分组后的记录中选取非主键记录不为null的记录,在此利用聚合函数max(x)即可选取,接着输出包含所述对应的非主键字段记录的中间表字段记录;接着设定表征非主键字段不为空的查询条件“wherecol_a_1isnotnullandcol_b_1isnotnullandcol_b_2isnotnull”从所述中间表记录获取表dw_a与表dw_b的内连接运算结果;最后select出所需的字段记录即可。本实施例所输出的结果为:key_1key_2col_a_1col_b_1col_b_20113210221如图6所示是基于关联字段同为两个表的主键字段的一种实施例,当所述关联字段同为两个表的主键字段且所述连接运算类型为外连接时,定义左外连接的左表为主表、右外连接的右表为主表,如dw_aleftjoindw_b,表dw_a即为主表,dw_arightjoindw_b,表dw_b即为主表,相应的,另一个表即为副表,在本实施例中,步骤s2000包括步骤s2020-s2023。步骤s2020:联合所有为主表与副表添加标志位字段后的所有字段记录;步骤s2021:根据所述关联字段对联合所有的结果记录进行分组;步骤s2022:对分组后的副表的非主键字段作聚合函数运算得到第四字段记录及对标识为字段作聚合函数运算得到第五标志位字段记录;步骤s2023:输出包含第四字段记录及第五标志位字段记录的中间表字段记录;步骤s300:依据第一表与第二表的连接运算类型及原连接运算的连接条件设定相应的查询条件,从所述中间表字段记录获取第一表与第二表的连接运算结果。同样的,在联合所有第一表与第二表的所有字段记录时,对于存在于第一表而不存在于第二表和存在于第二表而不存在于第一标的字段记录以null表示,并且利用所述标志位字段表征字段记录的来源表,最后再根据所述第一表与第二表的连接运算结果选取所需查询的字段记录。例如,现需要列出存在于表dw_a不存在于表dw_b的主键的记录。利用现有技术的外连接运算的算法如下:selecta.key_1,a.key_2,a.col_a_1fromdw_aaleftjoindw_bbona.key_1=b.key_1anda.key_2=b.key_2;根据本实施例方案将所述外连接运算进行转化,转化后的算法如下:其中,为表dw_b与表dw_a添加标志位字段flag,并定义表dw_a的标志位字段记录为1,表dw_b的标志位字段记录为0,然后联合所有为第一表与第二表添加标志位字段后的所有字段记录,即unionall所对应的2个select语句;然后根据所述关联字段对联合所有的结果记录进行分组,即groupbykey_1,key_2,本实施例中预设字段为副表的非主键和标识位字段,再对分组后的副表的非主键字段作聚合函数运算得到第四字段记录及对标识位字段作聚合函数运算得到第五标志位字段记录,在此利用聚合函数max(x)即可选取,接着输出包含所述对应的非主键字段记录的中间表字段记录;接着设定表征记录来源于主表的查询条件“whereflag=1”从所述中间表记录获取表dw_a与表dw_b的外连接运算结果;最后select出所需的字段记录即可。本实施例所输出的结果为:key_1key_2col_a_1col_b_1col_b_20113210221111nullnull024nullnull可以理解的是,在上述选取了所需查询的字段记录后,可以将该些记录作为新表的字段记录,以供该新表与第三表作连接运算,并利用本发明实施例方案将连接运算进行转化,以此实现多个表的连接查询。终上所述,本发明的一个实施例中,针对在大数据中面临所处理的数据量越来越大,计算难度越来越大,计算效率要求越来越高的问题,提出了一种在hive中连接运算的转化方法。在判断连接运算的两个表的关联字段为其中一个表的主键字段的条件下,利用联合所有运算及分析函数巧妙地将连接运算转化为非连接运算,以此规避数据处理中常用的连接运算,避免作连接运算的两个表数据量巨大而导致连接效率低下或几乎无法运算的问题,提高数据库的查询效率,降低终端运算压力。同时,在连接运算的两个表的关联字段同为两个表的主键字段的条件下,利用联合所有运算及聚合函数巧妙地将连接运算转化为非连接运算,同样以此规避连接运算,提高数据库查询效率。进一步的,依据计算机软件的功能模块化思维,基于前述的一种在hive中连接运算的转化方法,本发明还提供一种在hive中连接运算的转化装置。具体请参阅图7,该转化装置包括:判断模块100:用于在需要对第一表与第二表的连接运算进行转化时,判断所述连接运算的关联字段是否为其中一个表的主键字段;获取模块200:用于当所述关联字段为其中一个表的主键字段时,从已联合所有第一表与第二表的字段记录中对预设字段作分析函数运算,以获取对应的中间表字段记录;输出模块300:用于依据第一表与第二表的连接运算类型及原连接运算的连接条件设定相应的查询条件,从所述中间表字段记录获取第一表与第二表的连接运算结果。在本发明的一个实施例中,在需要对两个表进行连接运算以实现两个表的连接查询时将所述连接运算转化为非连接运算,以此提高数据库查询效率,首先判断模块100判断第一表与第二表的连接运算的关联字段是否为其中一个表的主键字段,所述关联字段是连接查询中表中含义相同的字段,在连接运算时根据关联字段之间的运算关系构成连接条件以实现两个表的连接运算。在本实施例中关联字段也即为第一表与第二表中含义相同的字段;所述主键字段是表中的一个或多个字段,主键字段的值用于唯一地标识表中的一条记录。在本发明的一个实施例中,当所述关联字段为第一表或第二表的主键字段时,获取模块200首先对第一表和第二表的字段作联合所有运算得到联合所有运算结果,然后对联合所有运算结果中的预设字段作分析函数运算,所述预设字段包括第一表或第二表的主键字段、非主键字段或上述的标志位字段,以此可以获得包含关联字段、第一表的非主键字段、第二表的非主键字段及对预设字段做分析函数运算后的中间表字段记录。然后,输出模块300根据第一表与第二表的连接运算类型及连接条件设定相应的查询条件以从所述中间表字段记录中获取第一表与第二表的连接运算结果,至此将第一表与第二表的连接运算转化为非连接运算,不再需要直接对第一表与第二表进行连接运算,避免连接运算所不可避免的查询效率低下的问题,提高数据库查询效率,降低终端运算压力。最后再根据所述第一表与第二表的连接运算结果选取所需查询的字段记录。本发明针对在大数据中面临所处理的数据量越来越大,计算难度越来越大,计算效率要求越来越高的问题,提出了一种在hive中连接运算的转化方法。在判断连接运算的两个表的关联字段为其中一个表的主键字段的条件下,利用联合所有运算及分析函数巧妙地将连接运算转化为非连接运算,以此规避数据处理中常用的连接运算,避免作连接运算的两个表数据量巨大而导致连接效率低下或几乎无法运算的问题,提高数据库的查询效率,降低终端运算压力。虽然上面已经示出了本发明的一些示例性实施例,但是本领域的技术人员将理解,在不脱离本发明的原理或精神的情况下,可以对这些示例性实施例做出改变,本发明的范围由权利要求及其等同物限定。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1