匹配职能部门的方法、装置及计算机设备与流程
本发明涉及通讯领域,特别是涉及一种匹配职能部门的方法、装置及计算机设备。
背景技术:
现有市民在向市政部门报案,以获取想要知道的职能部门对应的信息时,需要人工接通市民的呼入电话,并人工分析报案内容,分发到相应区域相关职能部门。例如,当用户向市政部门反映垃圾随处倾倒问题,则需要人工将该问题进行分析,查找到对应的智能部门。整个过程全程都需要人工参与,人工成本较高,且市政服务效率较低,不利于市政建设。
技术实现要素:
本发明提供一种匹配职能部门的方法、装置及计算机设备,用以解决现有技术的如下问题:现有市政服务系统工作时,全程都需要人工参与,人工成本较高,且市政服务效率较低,不利于市政建设。
为解决上述技术问题,一方面,本发明提供一种匹配职能部门的方法,其特征在于,包括:获取报案文本信息,得到所述报案文本信息对应的地名信息;根据预设语义相似度算法在预设地名数据库中搜索与所述地名信息相匹配的地名;
根据匹配到的地名和预先输入的报案类别到预设映射数据库中搜索对应的职能部门。
可选的,所述根据预设语义相似度算法在预设地名数据库中搜索与所述地名信息相匹配的地名,包括:分别计算所述地名信息与所述预设地名数据库中各标准地名的语义相似度,将大于预设相似度阈值且最大的语义相似度对应的标准地名作为与所述地名信息相匹配的地名。
可选的,所述根据匹配到的地名和预先输入的报案类别到预设映射数据库中搜索对应的职能部门之前,还包括:对预设的报案类别训练样本集采用分类算法训练,得到报案类别分类器,其中,所述训练样本集包括多个报案类别的样本;获取所述报案文本信息中的报案类别相关文本信息;将所述报案类别相关文本信息输入所述报案类别分类器,得到所述预先输入的报案类别。
可选的,所述分类算法包括以下一种或几种:朴素贝叶斯nb分类算法、支持向量机svm分类算法、k最邻近knn分类算法和随机森林分类算法。
可选的,所述报案文本信息包括:报案时呼入电话的语音数据转换后对应的文本信息,或者,报案时发送的文本信息。
可选的,获取报案文本信息,得到所述报案文本信息对应的地名信息,包括:按照预定分词方法对所述报案文本信息进行分词处理,得到分词结果;对所述分词结果进行地名词性标注,得到地名词集;
对所述地名词集进行命名实体识别,得到地名实体;将所述地名实体对应的地名词作为该地名实体的所述地名信息。
可选的,所述预定分词方法至少包括以下之一:字典双向最大匹配法,hmm方法和crf方法。
可选的,根据预设语义相似度算法在预设地名数据库中搜索与所述地名信息相匹配的地名,包括:s11,获取所述地名信息中最低等级的地名词;s12,所述预设地名数据库中包括标准地名,根据所述地名词按预设语义相似度算法在预设地名数据库中搜索与获取到的所述地名信息相匹配的所述标准地名,其中,所述标准地名为以最低等级的标准地名词命名的地名。
可选的,在s12之后还包括:s13,在未搜索到相匹配的地名的情况下,获取所述地名词的上一个等级的地名词,并根据获取到的所述地名词执行s12过程,直到搜索到相匹配的标准地名为止。
可选的,s12的根据所述地名词按预设语义相似度算法在预设地名数据库中搜索与获取到的所述地名信息相匹配的标准地名,包括:分别计算所述地名词与所述预设地名数据库中各标准地名的语义相似度,将大于预设相似度阈值且最大的语义相似度对应的标准地名作为与所述地名信息相匹配的地名。
可选的,s11包括:按照所述报案文本信息输入顺序将所述地名信息的地名词进行排列,得到所述地名词列表;若所述地名词为英文,则获取所述地名词列表中第一个地名词作为最低等级的地名词;若所述地名词为中文,则获取所述地名词列表中最后一个地名词作为最低等级的地名词;
所述获取所述地名词的上一个等级的地名词,包括:若所述地名词为英文,则获取所述地名词列表中当前地名词的下一个地名词;若所述地名词为中文,则获取所述地名词列表中当前地名词的上一个地名词。
可选的,根据匹配到的地名和预先输入的报案类别到预设映射数据库中搜索对应的职能部门之后,还包括以下一步或几步:将所述职能部门的电话反馈至所述报案文本信息对应的用户终端;为所述报案文本信息对应的用户终端呼叫所述职能部门;将报案信息发送到所述职能部门的终端。
另一方面,本发明还提供一种匹配职能部门的装置,包括:处理模块,用于获取报案文本信息,得到所述报案文本信息对应的地名信息;
匹配模块,用于根据预设语义相似度算法在预设地名数据库中搜索与所述地名信息相匹配的地名;搜索模块,用于根据匹配到的地名和预先输入的报案类别到预设映射数据库中搜索对应的职能部门。
可选的,所述匹配模块,具体用于:分别计算所述地名信息与所述预设地名数据库中各标准地名的语义相似度,将大于预设相似度阈值且最大的语义相似度对应的标准地名作为与所述地名信息相匹配的地名。
可选的,还包括:训练模块,用于对预设的报案类别训练样本集采用分类算法训练,得到报案类别分类器,其中,所述训练样本集包括多个报案类别的样本;获取所述报案文本信息中的报案类别相关文本信息;将所述报案类别相关文本信息输入所述报案类别分类器,得到所述预先输入的报案类别。
可选的,所述分类算法包括以下一种或几种:朴素贝叶斯nb分类算法、支持向量机svm分类算法、k最邻近knn分类算法和随机森林分类算法。
可选的,所述报案文本信息包括:报案时呼入电话的语音数据转换后对应的文本信息,或者,报案时发送的文本信息。
可选的,所述处理模块,包括:分词单元,用于按照预定分词方法对所述报案文本信息进行分词处理,得到分词结果;词性标注单元,用于对所述分词结果进行地名词性标注,得到地名词集;实体识别单元,用于对所述地名词集进行命名实体识别,得到地名实体;将所述地名实体对应的地名词作为该地名实体的所述地名信息。
可选的,所述预定分词方法至少包括以下之一:字典双向最大匹配法,hmm方法和crf方法。
可选的,所述匹配模块,包括:最低等级地名获取单元,用于获取所述地名信息中最低等级的地名词;标准地名获取单元,用于所述预设地名数据库中包括标准地名,根据所述地名词按预设语义相似度算法在预设地名数据库中搜索与获取到的所述地名信息相匹配的所述标准地名,其中,所述标准地名为以最低等级的标准地名词命名的地名。
可选的,所述匹配模块,具体还包括上一等级地名获取单元,用于在标准地名获取单元获取到的所述地名信息相匹配的所述标准地名之后执行:在未搜索到相匹配的地名的情况下,获取所述地名词的上一个等级的地名词,并将获取到的所述地名词输入标准地名获取单元,直到搜索到相匹配的标准地名为止。
可选的,执行标准地名获取单元时,根据所述地名词按预设语义相似度算法在预设地名数据库中搜索与获取到的所述地名信息相匹配的标准地名,包括:分别计算所述地名词与所述预设地名数据库中各标准地名的语义相似度,将大于预设相似度阈值且最大的语义相似度对应的标准地名作为与所述地名信息相匹配的地名。
可选的,最低等级地名获取单元,包括:顺序排列子单元,用于按照所述报案文本信息输入顺序将所述地名信息的地名词进行排列,得到所述地名词列表;首地名词识别子单元,用于若所述地名词为英文,则获取所述地名词列表中第一个地名词作为最低等级的地名词;若所述地名词为中文,则获取所述地名词列表中最后一个地名词作为最低等级的地名词;
所述上一等级地名获取单元,包括:语言等级地名词识别子单元,用于若所述地名词为英文,则获取所述地名词列表中当前地名词的下一个地名词;若所述地名词为中文,则获取所述地名词列表中当前地名词的上一个地名词;循环匹配子单元,用于将获取到的所述地名词输入标准地名获取单元,直到搜索到相匹配的标准地名为止。
可选的,还包括:执行模块,用于将所述职能部门的电话反馈至所述报案文本信息对应的用户终端,为所述用户终端呼叫所述职能部门,和/或,将报案信息发送到所述职能部门的终端。
另一方面,本发明还提供一种计算机存储介质,存储有计算机程序,所述计算机程序被处理器执行时实现上述的一种匹配职能部门的方法的步骤。
另一方面,本发明还提供一种计算机设备,包括存储器、处理器及存储在存储器上并可以在处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现上述的一种匹配职能部门的方法的步骤。
本发明有益效果如下:
本发明获取市政服务系统的报案文本信息,以得到报案文本信息对应的地名信息,根据预设语义相似度算法在预设地名数据库中搜索与地名信息相匹配的地名,并结合预先输入的报案类别来搜索报案文本信息对应的职能部门,整个过程自动确定地名信息,自动匹配地名,自动搜索职能部门,无需人工参与,节省了大量的人工成本,特别是对于市政服务,市民可以较为快速的获取到报案内容的回馈,提高了市政服务效率,有利于市政建设,解决了现有技术的如下问题:现有服务系统工作时,全程都需要人工参与,人工成本较高,特别是对于市政服务,市政服务效率较低,不利于市政建设
附图说明
图1是本发明第一实施例中匹配职能部门的方法的流程图;
图2是本发明第二实施例中匹配职能部门的装置的结构示意图;
图3是本发明第三实施例中计算机设备匹配职能部门的流程图。
具体实施方式
为了解决现有技术的如下问题:现有市政服务系统工作时,全程都需要人工参与,人工成本较高,且市政服务效率较低,不利于市政建设;本发明提供了一种匹配职能部门的方法、装置及计算机设备,以下结合附图以及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不限定本发明。
本发明第一实施例提供了一种匹配职能部门的方法,该方法的流程如图1所示,包括步骤s102至s106:
s102,获取报案文本信息,得到报案文本信息对应的地名信息;
s104,根据预设语义相似度算法在预设地名数据库中搜索与地名信息相匹配的地名;
s106,根据匹配到的地名和预先输入的报案类别到预设映射数据库中搜索对应的职能部门。
本发明实施例获取的报案文本信息可以为市政服务系统的报案文本信息,以得到报案文本信息对应的地名信息,根据预设语义相似度算法在预设地名数据库中搜索与地名信息相匹配的地名,并结合预先输入的报案类别来搜索报案文本信息对应的职能部门,整个过程自动确定地名信息,自动匹配地名,自动搜索职能部门,无需人工参与,节省了大量的人工成本,市民可以较为快速的获取到报案内容的回馈,提高了服务效率,有利于市政建设,解决了现有技术的如下问题:现有服务系统工作时,全程都需要人工参与,人工成本较高,特别是对于市政服务,市政服务效率较低,不利于市政建设。
实现的过程中,在根据预设语义相似度算法在预设地名数据库中搜索与地名信息相匹配的地名时,可以分别计算地名信息与预设地名数据库中各标准地名的语义相似度,将大于预设相似度阈值且最大的语义相似度对应的标准地名作为与地名信息相匹配的地名。其中,标准地名为以最低等级的标准地名词命名的地名或为完整地名,当标准地名为完整地名时,可以用完整地名信息与标准地名做相似度计算。
在根据匹配到的地名和预先输入的报案类别到预设映射数据库中搜索对应的职能部门之前,还可以对预设的报案类别训练样本集采用分类算法训练,得到报案类别分类器,其中,训练样本集包括多个报案类别的样本;获取报案文本信息中的报案类别相关文本信息;将报案类别相关文本信息输入报案类别分类器,得到预先输入的报案类别。其中,分类算法包括以下一种或几种:朴素贝叶斯nb分类算法、支持向量机svm分类算法、k最邻近knn分类算法和随机森林分类算法。
通过上述过程,就可以快速的获取到输入的报案类别,以便进行职能部门的匹配。
由于使用服务系统报案的用户不同,因此,报案方式也不同;有的可能通过电话呼叫报案,例如,在发生打架斗殴事件需要报警时,则可能市民用户会选择通过电话主叫呼入市政服务系统;有的可能通过发送信息进行报案,例如,当市民用户想要反应某一区域垃圾处理问题,想知道该问题归哪里负责时,则由于该问题不是迫切需要解决,因此,可能会通过向服务系统发送短信等方式报案。因此,本发明实施例在获取报案文本信息时,报案文本信息可以包括报案时呼入电话的语音数据转换后对应的文本信息,或者是报案时发送的文本信息。这样,无论用户通过哪种方式进行报案,都可以获取到对应的报案文本信息,系统处理性能增强。
本实施例通过获取报案文本信息,进而可以得到报案文本信息对应的地名信息,具体处理时,包括如下过程:
按照预定分词方法对报案文本信息进行分词处理,得到分词结果,再对分词结果进行地名词性标注,得到地名词集,例如,词性为ns的就是地名;上述过程中,分词是和词性标注一起进行的,词性标注是把分词词典中标示的每个词的词性标到分词结果里。上述预定分词方法可以是多种,例如,字典双向最大匹配法、hmm方法或crf方法等。
随后,对地名词集进行命名实体识别,得到地名实体,再将地名实体对应的地名词作为该地名实体的地名信息。实现时,地名信息里可能包括一个或多个复合地名词,当包括多个复合地名词时,例如,上海市嘉定区金沙江西路,包括三个地名词,但所指为一个地名,因此需要通过实体识别得到,实体识别得到的地名实体为包括一个地名词或多个地名词复合的地名信息。
通过上述过程,就可以从获取到的报案文本信息中得到市民用户报案涉及到的地名信息,为自动化报案提供了坚实基础。
在根据预设语义相似度算法在预设地名数据库中搜索与地名信息相匹配的地名时,由于地名信息通常情况下可能包括多个地名词,通常是采用地名信息与地名数据库中的标准地名来匹配,此处的标准地名为以最低等级的标准地名词命名的地名。所以,在实现时,需要根据报案文本信息的语言情况来确定先识别哪个地名词,具体实现过程如下:
s11,获取地名信息中最低等级的地名词。
s12,预设地名数据库中包括标准地名,根据地名词按预设语义相似度算法在预设地名数据库中搜索与获取到的地名信息相匹配的标准地名,其中,标准地名为以最低等级的标准地名词命名的地名。
s13,在未搜索到相匹配的地名的情况下,获取地名词的上一个等级的地名词,并根据获取到的地名词执行s12过程,直到搜索到相匹配的标准地名为止。
具体的,s12的分别计算地名词与预设地名数据库中各标准地名的语义相似度,将大于预设相似度阈值且最大的语义相似度对应的标准地名作为与地名信息相匹配的地名。
s11具体包括:按照报案文本信息输入顺序将地名信息的地名词进行排列,得到地名词列表;若地名词为英文,则获取地名词列表中第一个地名词作为最低等级的地名词;若地名词为中文,则获取地名词列表中最后一个地名词作为最低等级的地名词;s13中,获取地名词的上一个等级的地名词,包括:若地名词为英文,则获取地名词列表中当前地名词的下一个地名词;若地名词为中文,则获取地名词列表中当前地名词的上一个地名词。
例如,当地名信息为北京市海淀区中关村第三小学时,则该地名信息对应的多个地名词依次为“北京市,海淀区,中关村第三小学”,则在进行匹配时,从“中关村第三小学”这个地名词开始进行地名匹配,如果“中关村第三小学”这个地名词没有匹配到地名,则再使用“海淀区”进行匹配。
当地名信息为“baihuasilu,futiandistrict,shenzhencity,guangdongprovince”时,则该地名信息对应的多个地名词依次为“baihuasilu,futiandistrict,shenzhencity,guangdongprovince”,则在进行匹配时,从“baihuasilu”这个地名词开始进行地名匹配,如果“baihuasilu”这个地名词没有匹配到地名,则再使用“futiandistrict”进行匹配,如果“futiandistrict”没有匹配到,则再使用“shenzhencity”进行匹配。
由于中文和英文对地名信息表述方式不同,即中文习惯按照省市县等由大到小顺序播报或记录地名信息,英文习惯按照县市省等由小到大顺序播报或记录地名信息,所以,本实施例针对不同报案语言需要执行不同的匹配方式,以便能够灵活的适用报案语言的类型,增强报案系统的性能。
当已经匹配到对应的地名后,就可以结合报案用户预先输入的报案类别到预设映射数据库中搜索对应的职能部门。对于该预设映射数据库,其存储着本市各个地区内各个职能部门的相关信息,比如,职能部门,坐落位置,职责等。
在根据匹配到的地名和预先输入的报案类别到预设映射数据库中搜索对应的职能部门之后还包括以下一步或几步:可以将职能部门的电话反馈至报案文本信息对应的用户终端;为用户终端呼叫职能部门;将报案信息发送到所述职能部门的终端。如果市民用户是通过呼入服务系统的方式报案,则可以直接在电话内将对应职能部门的电话进行语音播报,也可以直接为用户转接呼入电话带对应的职能部门;如果用户是通过向服务系统发送信息的方式报案,则可以以信息的方式向报案用户终端发送对应职能部门的电话。
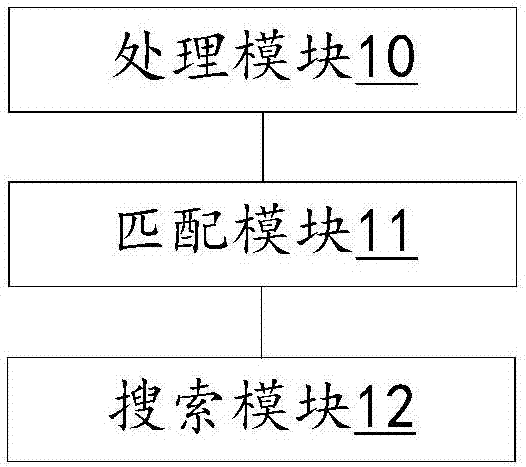
本发明第二实施例提供了一种匹配职能部门的装置,该装置的结构示意如图2所示,包括:
处理模块10,用于获取报案文本信息,得到报案文本信息对应的地名信息;匹配模块11,与处理模块10耦合,用于根据预设语义相似度算法在预设地名数据库中搜索与地名信息相匹配的地名;搜索模块12,与匹配模块11耦合,用于根据匹配到的地名和预先输入的报案类别到预设映射数据库中搜索对应的职能部门。
本发明实施例上述整个过程自动确定地名信息,自动匹配地名,自动搜索职能部门,无需人工参与,节省了大量的人工成本,市民可以较为快速的获取到报案内容的回馈,提高了服务效率,有利于市政建设,解决了现有技术的如下问题:现有服务系统工作时,全程都需要人工参与,人工成本较高,特别是对于市政服务,市政服务效率较低,不利于市政建设。
由于使用服务系统报案的用户不同,因此,报案方式也不同;有的可能通过电话呼叫报案,例如,在发生打架斗殴事件需要报警时,则可能市民用户会选择通过电话主叫呼入市政服务系统;有的可能通过发送信息进行报案,例如,当市民用户想要反应某一区域垃圾处理问题,想知道该问题归哪里负责时,则由于该问题不是迫切需要解决,因此,可能会通过向服务系统发送短信等方式报案。因此,上述报案文本信息可以是报案时呼入电话的语音数据转换后对应的文本信息,或者是报案时发送的文本信息。这样,无论用户通过哪种方式进行报案,都可以获取到对应的报案文本信息,系统处理性能增强。
上述匹配模块11,具体用于:分别计算地名信息与预设地名数据库中各标准地名的语义相似度,将大于预设相似度阈值且最大的语义相似度对应的标准地名作为与地名信息相匹配的地名。其中,标准地名为以最低等级的标准地名词命名的地名或为完整地名,当标准地名为完整地名时,可以用完整地名信息与标准地名做相似度计算。
上述装置还可以包括与搜索模块12耦合的训练模块,用于对预设的报案类别训练样本集采用分类算法训练,得到报案类别分类器,其中,训练样本集包括多个报案类别的样本;获取报案文本信息中的报案类别相关文本信息;将报案类别相关文本信息输入报案类别分类器,得到预先输入的报案类别。其中,分类算法包括以下一种或几种:朴素贝叶斯nb分类算法、支持向量机svm分类算法、k最邻近knn分类算法和随机森林分类算法。通过上述过程,就可以快速的获取到输入的报案类别,以便进行职能部门的匹配。
处理模块10具体包括分词单元、词性标注单元和实体识别单元。
其中,分词单元,用于用于按照预定分词方法对报案文本信息进行分词处理,得到分词结果。例如,词性为ns的就是地名;上述过程中,分词是和词性标注一起进行的,词性标注是把分词词典中标示的每个词的词性标到分词结果里。上述预定分词方法可以是多种,例如,字典双向最大匹配法、hmm方法或crf方法等。
词性标注单元,用于对分词结果进行地名词性标注,得到地名词集;对地名词集进行命名实体识别,得到地名实体。
实体识别单元,用于将地名实体对应的地名词作为该地名实体的地名信息。
实现时,地名信息里可能包括一个或多个复合地名词,当包括多个复合地名词时,例如,上海市嘉定区金沙江西路,包括三个地名词,但所指为一个地名,因此需要通过实体识别得到,实体识别得到的地名实体为包括一个地名词或多个地名词复合的地名信息。
通过上述过程,就可以从获取到的报案文本信息中得到市民用户报案涉及到的地名信息,为自动化报案提供了坚实基础。
为了简化识别地名词过程的操作,匹配模块11可以包括:
最低等级地名获取单元,用于获取地名信息中最低等级的地名词;
标准地名获取单元,用于预设地名数据库中包括标准地名,根据地名词按预设语义相似度算法在预设地名数据库中搜索与获取到的地名信息相匹配的标准地名,其中,标准地名为以最低等级的标准地名词命名的地名。
上一等级地名获取单元,用于在标准地名获取单元获取到的所述地名信息相匹配的所述标准地名之后执行:在未搜索到相匹配的地名的情况下,获取地名词的上一个等级的地名词,并将获取到的地名词输入标准地名获取单元,直到搜索到相匹配的标准地名为止。
其中,执行标准地名获取单元时,所述根据地名词按预设语义相似度算法在预设地名数据库中搜索与获取到的地名信息相匹配的标准地名,包括:分别计算地名词与预设地名数据库中各标准地名的语义相似度,将大于预设相似度阈值且最大的语义相似度对应的标准地名作为与地名信息相匹配的地名。
最低等级地名获取单元,包括顺序排列子单元和首地名词识别子单元。
其中,顺序排列子单元,用于按照报案文本信息输入顺序将地名信息的地名词进行排列,得到地名词列表;首地名词识别子单元,用于若地名词为英文,则获取地名词列表中第一个地名词作为最低等级的地名词;若地名词为中文,则获取地名词列表中最后一个地名词作为最低等级的地名词。
上一等级地名获取单元包括语言等级地名词识别子单元和循环匹配子单元。语言等级地名词识别子单元,用于获取地名词的上一个等级的地名词,包括:若地名词为英文,则获取地名词列表中当前地名词的下一个地名词;若地名词为中文,则获取地名词列表中当前地名词的上一个地名词。循环匹配子单元,用于将获取到的所述地名词输入标准地名获取单元,直到搜索到相匹配的标准地名为止。
本实施例可以针对不同报案语言需要执行不同的匹配方式,以便能够灵活的适用报案语言的类型,增强报案系统的性能。
上述装置还可以包括:执行模块,与搜索模块耦合,用于将职能部门的电话反馈至报案文本信息对应的用户终端,为用户终端呼叫职能部门,和/或,将报案信息发送到所述职能部门的终端。如果市民用户是通过呼入服务系统的方式报案,则可以直接在电话内将对应职能部门的电话进行语音播报,也可以直接为用户转接呼入电话带对应的职能部门;如果用户是通过向服务系统发送信息的方式报案,则可以以信息的方式向报案用户终端发送对应职能部门的电话。
本发明第三实施例还提供了一种计算机设备,包括存储器、处理器及存储在存储器上并可以在处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现第一实施例的一种匹配职能部门的方法。实现时,上述计算机程序可以存储在计算机存储介质中。
例如,处理器执行计算机程序时实现图3的如下过程:
s1,获取报案文本信息。该过程中,还可以根据报案文本信息确定问题类别或投诉内容等信息。
s2,对报案文本信息进行分词、词性标注、命名实体识别(ner,namedentityrecognition)、地名信息提取。
s3,判断地名数据库中是否存在与地名信息匹配度达到预设匹配度的地名。在存在的情况下,执行s4,否则执行s6。
s4,根据地名词和报案文本信息中的报案类别到预设映射数据库中搜索对应的职能部门。
s5,将搜索到的职能部门反馈至市民用户。
s6,按照顺序查找地名信息中的下一个地名词,返回s3。其中,该顺序可能是地名信息顺序方式或地名信息的倒序方式。
例如,当市民用户电话呼入报案“北京市海淀区中关村第三小学附近有交通事故”时,则地名信息为北京市海淀区中关村第三小学,则该地名信息对应的多个地名词依次为“北京市,海淀区,中关村第三小学”,对应的报案类别就是交通、突发事故类,则在查找智能部门时,可以匹配到交警部门,则可以为市民用户提供中关村第三小学附近交警部门的电话,以便及时处理问题。
本实施例人工本系统能够实现市政报案的自动流转,提高市政服务效率,降低人工成本。
可选地,在本实施例中,上述存储介质可以包括但不限于:u盘、只读存储器(rom,read-onlymemory)、随机存取存储器(ram,randomaccessmemory)、移动硬盘、磁碟或者光盘等各种可以存储程序代码的介质。可选地,在本实施例中,处理器根据存储介质中已存储的程序代码执行上述实施例记载的方法步骤。可选地,本实施例中的具体示例可以参考上述实施例及可选实施方式中所描述的示例,本实施例在此不再赘述。显然,本领域的技术人员应该明白,上述的本发明的各模块或各步骤可以用通用的计算装置来实现,它们可以集中在单个的计算装置上,或者分布在多个计算装置所组成的网络上,可选地,它们可以用计算装置可执行的程序代码来实现,从而,可以将它们存储在存储装置中由计算装置来执行,并且在某些情况下,可以以不同于此处的顺序执行所示出或描述的步骤,或者将它们分别制作成各个集成电路模块,或者将它们中的多个模块或步骤制作成单个集成电路模块来实现。这样,本发明不限制于任何特定的硬件和软件结合。
尽管为示例目的,已经公开了本发明的优选实施例,本领域的技术人员将意识到各种改进、增加和取代也是可能的,因此,本发明的范围应当不限于上述实施例。
- 还没有人留言评论。精彩留言会获得点赞!