一种基于高斯混合的大数据智能推荐方法与流程
本发明涉及一种基于高斯混合的智能推荐方法,属于大数据智能推荐领域,涉及大数据推荐模型与群智能优化算法的结合及使用。
背景技术:
随着电子商务的发展,商家提供的商品种类和数量急剧增长。具有明确需求的用户可直接通过搜索查找想购买的商品即可。然而,实际中用户需求通常具有不确定性和模糊性。据亚马逊统计,在其网站购物的客户中,有明确购买意向的仅占16%。如果商家能够从海量的商品中把满足用户模糊需求的商品主动推荐给用户,则有望将潜在需求转化为实际需求,不仅能提高电子商务网站的销售量,还有助于提高用户对网站的忠诚度。在此背景下,能够根据用户特征有针对性推荐商品的个性化推荐系统应运而生,并被广泛应用。包括amazon、ebay、youtube和google在内的诸多网站都部署了不同形式的推荐系统,并产生了巨大的商业利润。据统计,2006年推荐系统为amazon提高了30%的销售额。推荐系统具有重要的应用价值,不仅成为计算机领域具有挑战性的研究课题之一,还吸引了来自数学、物理、认知、人工智能、管理、市场营销等众多领域的研究者。
因此如何有效地利用数据挖掘和机器学习方法向用户推荐有价值的个性化信息成为有很强实际意义的问题。协同过滤是一种能够产生个性化推荐的有效技术,在各种推荐系统中都得到广泛应用,其基本任务是根据相似的偏好匹配用户,以推荐用户可能会喜欢的项目。协同过滤算法一般可以分为基于内存和基于模型。其中,基于内存的协同过滤又可分为基于用户和基于项目。前者是计算用户间相似度,得到与目标用户兴趣偏好相似的最近邻,以此为基础进行预测推荐。它没有对原有数据进行学习的能力,不具有很好的扩展性,且存在冷启动问题。而基于项目的推荐是从商品角度计算项目之间的相似度,通过项目的最近邻搜索来产生推荐。一般来讲,项目间相似度比用户偏好的相似度稳定,离线对前者进行计算,避免了线上大数量级用户的最近邻搜索,大大降低了在线计算量。与基于内存的算法不同,基于模型的算法不是直接通过用户-项目原始评分数据进行计算推荐,而是用机器学习的方法对数据进行学习建模,再通过模型预测用户对未评分项目的习惯偏好。常用的模型包括贝叶斯、奇异值分解(singularvaluedecomposition,svd)、潜在语义分析(latentsemanticanalysis,lsa)、概率潜在语义分析(probabilisticlatentsemanticanalysis,plsa)等。
然而,基于模型的算法有必要考虑如下问题:第一,用户对项目评分的高低受多种因素影响,包括用户对项目主题/内容的感兴趣程度,用户的评分习惯,项目本身的品质等。第二,单一的潜变量很难同时体现用户与用户,项目与项目,用户与项目之间的关系,需要将用户按照相似的兴趣和偏好聚类,将项目按照相似的主题和内容聚类。第三,通常的“硬”聚类方式,即每个用户或项目只属于单一的一个类,很难描述同一用户可能具有的多种兴趣以及同一项目的多种不同属性。比较合理的做法是“软”聚类,每个用户或项目依概率属于多个类,用户在某类上概率值的大小反映了用户对这一类的偏好程度,项目亦然。
基于上述思路,本发明提出了一种新的基于高斯混合模型的协同过滤算法gmm-tcf(gaussianmixturemodel-timecollaborativefiltering)进行推荐,它结合了基于高斯模型和改进的基于项目的协同过滤算法。前者通过潜在变量引出多兴趣群体的概念,对用户模型进行学习得到用户属于每个兴趣群体的概率,以及群体对项目的兴趣偏好。另一方面,在对基于项目的推荐值计算上,考虑到两个项目出现时间越相近,则物品之间的相似度会越高,因此对相似度的计算引入一个项目相似度时间因子。同时,算法运用cfpso(compressionfactorparticleswarmoptimization)算法对高斯混合模型中的参数进行优化,并通过线性加权的方式将基于用户兴趣和基于项目的推荐值进行有效结合,从而弥补了基于用户兴趣度模型推荐所带来的兴趣群体局限性,解决了推荐系统的冷启动问题和单一兴趣推荐的局限性,有效地提高了推荐的准确性。此外,算法采用用户兴趣和项目的联合概率进行模型构建。同时,针对高斯混合模型中的参数如何进行初始化进行合理选择,以及在高斯混合模型中运用em(expectationmaximization)算法求解其参数时,如何采用合适的似然函数。
上述这种高斯混合模型协同过滤推荐算法gmm-tcf的主要推荐机制在于:在推荐算法的选择上,不仅仅选择通过用户间相似度为用户进行推荐,同时结合项目之间的相似度对用户进行推荐。这种推荐方式不仅弥补了用户所属单一聚类的局限性,同时利用项目之间的时间因子改进相似度计算公式,从而有效地提高了算法的推荐精度。
技术实现要素:
本发明的主要内容是基于高斯混合模型的协同过滤推荐算法gmm-tcf的研究及应用,主要包括用户和项目联合概率的生成、如何定义大数据推荐模型中的最大似然函数、如何对大数据推荐模型中的高斯混合参数进行初始化和优化、以及怎么样将基于高斯混合的用户兴趣度模型与基于项目的推荐模型进行线性结合。其采用的技术方案为:1)通过运用高斯混合模型将用户进行软聚类,从而提出基于用户兴趣的相似度预测模型,计算该模型的预测评分;2)通过引入项目时间因子,从而改进相似度计算公式,计算基于项目模型的预测评分;3)将上述两模型的预测评分进行线性结合,作为最终的项目预测评分,从而推荐给目标用户。
本发明采用的技术方案为一种基于高斯混合的大数据智能推荐方法,该方法的实现步骤如下:
(1)基于用户兴趣的相似度预测模型。首先,通过plsa模型构建用户和项目的联合概率,基于此概率形式,构建合适的似然函数即大数据智能推荐模型。然后,通过cfpso算法优化em算法从而求解大数据智能推荐模型中的参数。最后,运用大数据智能推荐模型求解目标用户对项目的预测评分。
a.构建用户和项目的联合概率。对于每一个三维向量<u,i,v>,其中u,i,v分别为用户u、项目i、及用户u对项目i的评分。引入潜在变量z={z1,z2,…,zk},其中zi(1≤i≤k)为不同的聚类群体,用p(zk|u)表示用户u属于zk群体的概率且
b.构建似然函数即大数据智能推荐模型。假定群体z对项目i评分v的条件概率p(v|i,z)符合高斯分布,有p(v|i,z)=n(μi,z,σi,z)=p(v;μi,z,σi,z),其中μi,z,σi,z分别为群体z对项目i评分的均值和方差,则用户和项目的联合概率是一个满足高斯混合的概率模型:
c.参数初始化选择。针对参数p(z|u),μi,z,
第一步:初始化粒子种群。给定粒子群的数目同时对粒子群中每个粒子的初始位置和速度进行初始化,位置和速度公式如下:
其中,
第二步:计算粒子群中各个粒子的适应度值,并更新粒子的当前个体最优位置pbest和粒子群的群体最优位置gbest。
第三步:对粒子群的gbest根据em算法对其进行更新。比较更新前后的适应度值,如果更新后的gbest值使得适应度函数值变大,则更新种群最优位置gbest信息,否则不予更新。
第四步:对更新后的种群最优值gbest进行校验,如果其满足要求,则结束cfpso算法,并取得gbest值的属性信息作为em算法的初始参数;否则转至第五步。
第五步:根据公式(2)和(3)更新粒子群中粒子个体的速度和位置参数并转至第二步继续执行。其中,em算法的执行步骤如下:
e步:根据每一个评分向量<u,i,v>,计算得到每个潜在的变量z∈z的后验概率p(z|u,v,i),如下:
m步:根据e步计算得到的后验概率,并结合拉格朗日最优化极值对似然函数求偏导可得到p(z|u),μi,z,
根据cfpso优化em算法的初始化参数,交替执行e步和m步,直到收敛,求得参数p(z|u),μi,z,
d.用户兴趣相似度模型预测评分。通过m步中的参数集,构造基于高斯混合的用户兴趣相似度模型,从而计算用户u对项目i的预测评分,具体公式如下:
(2)基于项目的预测模型。根据对项目打分的用户越多,则项目之间的相似度越高。同时,由于同类物品出现的时间越相近,则各物品之间的相似度越高,因此引入项目时间因子,定义如下:
其中,ti和tj为项目i和项目j出现的时间。定义项目i和j的相似度为sim(i,j):
其中,u(i)和u(j)分别是对项目i和j评分的用户集合,ru,i和ru,j表示用户u对项目i和项目j的评分,
其中,s(i)为项目i的领域集合,这里选择项目是否加入邻域的方式为判断两项目的相似度是否大于一定的阈值,这样的计算的方式减少项目之间的比较排序,节约运算时间。
(3)线性加权预测。将用户兴趣相似预测模型与基于项目的预测模型运用线性加权的方式将二者的预测评分进行结合,从而计算出用户对项目的最终预测评分,其公式计算如下:
rateu,i=α×rate_uhmmu,i+β×rate_itemu,i,0<α<1,α+β=1(12)
综上,对协同过滤算法中用户对项目的预测评分进行改进,分别通过高斯混合、cfpso、em算法建立基于用户兴趣相似度预测模型,通过添加时间因子建立基于项目预测模型,从而将二者的预测评分进行线性结合,作为用户对项目的最终预测评分。
通过这种方式,一方面从最初用户属于某一个聚类到多个聚类的转变,这使得用户的兴趣得到了极大的体现;另一方面,通过添加项目时间因子,提高了项目之间的相似度,从而建立基于项目的预测模型,使得算法的推荐效果更好,推荐精度更高。
附图说明
图1:基于高斯混合模型的协同过滤算法的整体框架图
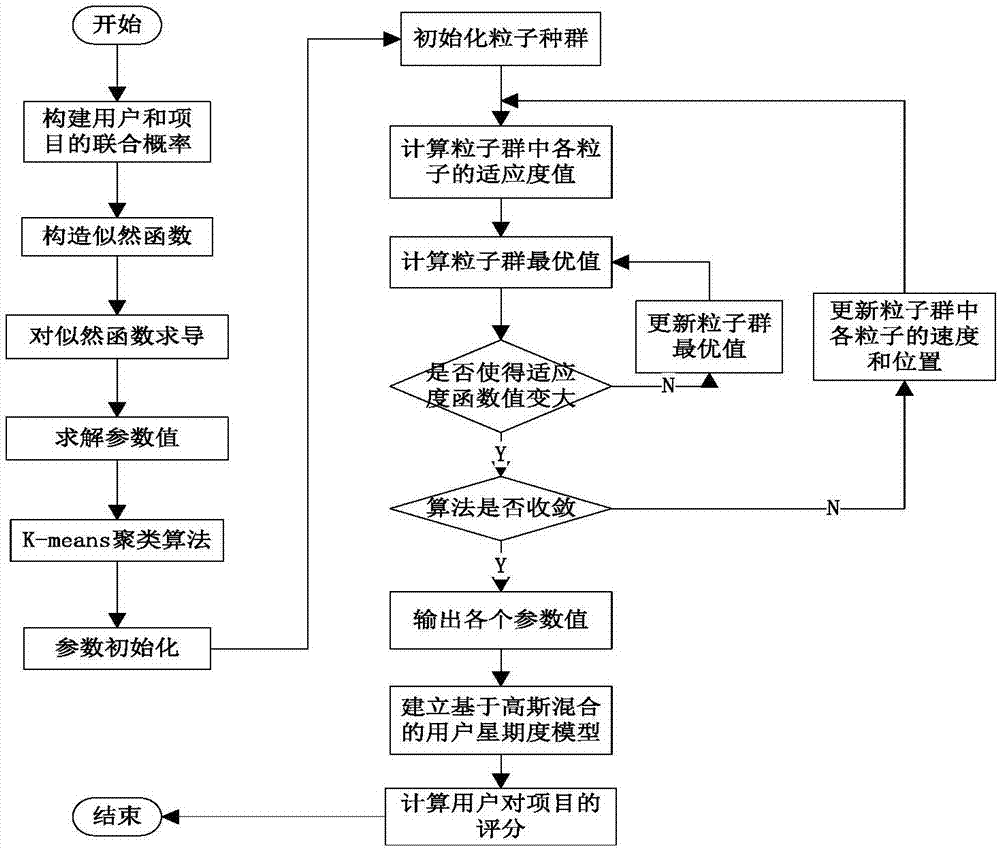
图2:基于高斯混合模型的用户兴趣度预测模型流程图
图3:基于项目的预测推荐模型流程图
图4:不同item-cf邻域下的mae图
具体实施方式
下面结合相关附图对本发明进行解释和阐述:
为使本发明的目的、技术方案和特点更加清楚明白,以下结合具体实施例子,并参照附图,对本发明进行进一步的细化说明。基于高斯混合模型的协同过滤算法的整体框架图如图1所示。
各个步骤说明如下:
(1)提出一种基于高斯混合模型的用户兴趣度预测模型,使得用户的兴趣得到极大体现而不局限于某一聚类之中。
(2)提出一种基于项目的预测模型,研究了项目出现先后的时间因子对推荐评分的影响。
(3)提出一种基于高斯混合协同过滤推荐算法模型,相较于上述提出的模型,该模型推荐精度更高。
实验环境如下:
本发明通过实验验证本文提出的基于高斯混合模型协同过滤算法的实际效果,实验环境为win7(64位)主机,8g内存,1t硬盘,采用netflix数据集,并通过交叉验证的方式来验证推荐的mae值。
首先,算法建立基于高斯混合模型的用户兴趣度预测模型。通过采用plsa概率潜在语义分析用户的兴趣,同时引入潜在变量z引出用户的多兴趣,从而计算用户和项目的联合概率。在此基础上,假定用户群体z对项目的评分服从高斯分布,从而构造最大似然函数,并对其求对数,进而求解出参数的一般解。针对参数的初始化,该模型采用k-mean聚类算法对其进行初始值进行设定,并通过cfpso算法对初始值参数不断进行优化,直到cfpso算法适应度函数收敛或者算法达到指定的迭代次数,结束优化过程,输出em算法参数的最终值,从而构造该用户兴趣度模型,预测用户对项目的评分rate_uhmmu,i,该模型构建流程图如2所示。
然后,算法建立基于项目的预测推荐模型。通过引入项目时间因子,构造项目时间因子函数,从而改进基于项目协同过滤推荐的相似度计算方式,提高项目之间的相似性。通过构造基于项目的预测推荐模型,进而通过预测评分公式计算用户对项目的预测评分rate_itemu,i,该预测推荐模型构建的流程图如图3所示。
最后,算法依托基于高斯混合模型的用户兴趣度模型和基于项目的预测推荐模型,构造基于高斯混合的协同过滤推荐模型,即算法针对两个模型取得的用户对项目的预测评分,通过线性函数将其联系起来,改进预测评分公式,进而计算用户对项目的最终预测评分rateu,i。
从图4中本发明提出的算法模型与其他算法进行对比,可以明确看到本文提出的算法gmm-tcf的mae值明显小于其他算法,且随着项目邻域中item个数的增加,mae值呈现下降趋势。
综合上述实验,利用基于高斯混合的协同过滤推荐模型对用户进行推荐,一方面可以有效利用用户多兴趣,同时在高斯混合参数值的选取上进行优化。另一方面,引入项目时间因子不仅可以提高项目之间的相似性,而且通过阈值计算邻域的方式可以有效降低算法的运行时间,通过将预测评分线性组合的方式进行调整,使得用户对项目的评分更加准确,从而提高了算法的推荐精度和推荐效率。
- 还没有人留言评论。精彩留言会获得点赞!