数据推送方法、装置以及计算机可读存储介质与流程
本发明涉及移动互联网技术领域,特别涉及一种数据推送方法、装置以及计算机可读存储介质。
背景技术:
随着移动互联网电商的发展,越来越多的用户在移动端进行购物,当用户下单购物后,可以向用户推荐很多商品,例如用户购买过手机,可以推荐手机壳,手机膜,移动电源等等。
然而,移动客户端根据用户购买过的商品进行商品的推荐时,有些推荐商品与用户购买过的商品是相关联的,有些推荐商品与用户购买过的商品是不相关联的,这些不相关联的推荐商品会降低用户体验。
技术实现要素:
本发明解决的一个技术问题是,如何智能的向用户推送相关联的数据。
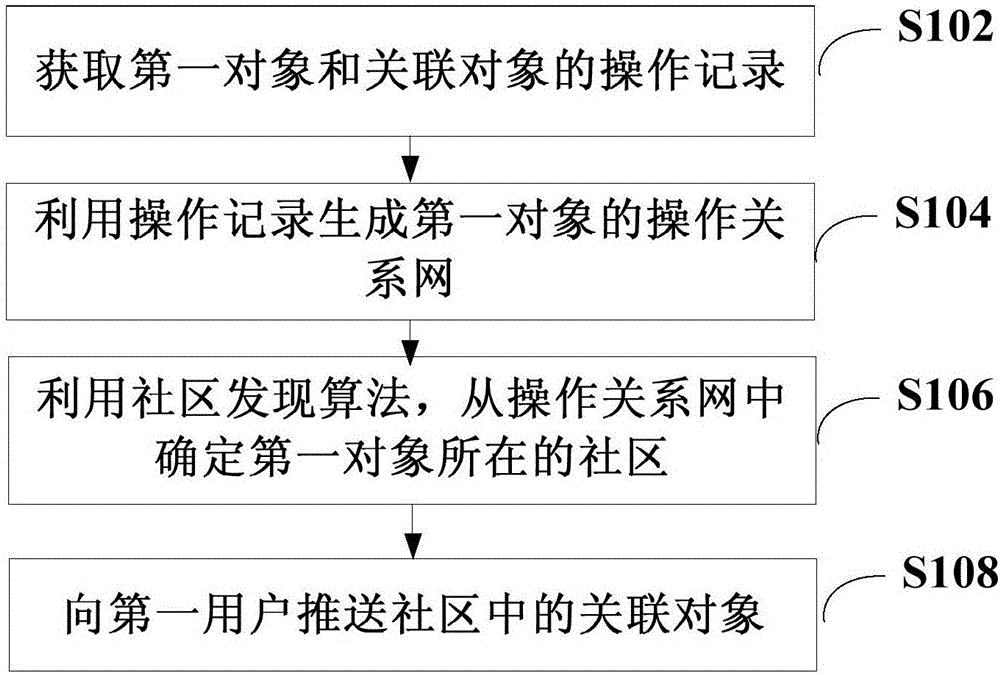
根据本发明实施例的一个方面,提供了一种数据推送方法,包括:获取第一对象和关联对象的操作记录,第一对象为第一用户操作的对象之一,关联对象为也操作第一对象的第二用户操作的对象,关联对象与第一对象不同;利用操作记录生成第一对象的操作关系网,操作关系网的节点表示第一对象和关联对象,操作关系网的边表示对象之间存在操作关联关系;利用社区发现算法,从操作关系网中确定第一对象所在的社区;向第一用户推送社区中的关联对象。
在一个实施例中,数据推送方法还包括:在获取第一对象以及关联对象的操作记录之前,根据操作第一对象的所有用户数n,以及操作第一对象的所有用户中还操作第二对象的用户数m,确定第二对象与第一对象的关联度,第二对象为关联对象中的各个对象;将与第一对象的关联度高于阈值的第二对象确定为关联对象。
在一个实施例中,确定第二对象与第一对象的关联度包括:将m与n的比值确定为第二对象与第一对象的关联度。
在一个实施例中,数据推送方法还包括:在利用操作记录生成第一对象的操作关系网之前,提取关联对象的商品描述;利用文本分词算法,对关联对象的商品描述进行文本分词;将所得文本分词满足预设条件的关联对象确定为相同的关联对象;将相同的关联对象的操作记录进行合并。
在一个实施例中,利用结巴分词算法,对关联对象进行文本分词。
在一个实施例中,向第一用户推送社区中的关联对象包括:按照与第一操作对象的关联度从高到低的顺序,向第一用户推送社区中的关联对象。
根据本发明实施例的另一个方面,提供了一种数据推送装置,包括:操作记录获取模块,用于获取第一对象和关联对象的操作记录,第一对象为第一用户操作的对象之一,关联对象为也操作第一对象的第二用户操作的对象,关联对象与第一对象不同;操作关系网生成模块,用于利用操作记录生成第一对象的操作关系网,操作关系网的节点表示第一对象和关联对象,操作关系网的边表示对象之间存在操作关联关系;社区发现模块,用于利用社区发现算法,从操作关系网中确定第一对象所在的社区;数据推送模块,用于向第一用户推送社区中的关联对象。
在一个实施例中,数据推送装置还包括:关联度确定模块,用于在获取第一对象以及关联对象的操作记录之前,根据操作第一对象的所有用户数n,以及操作第一对象的所有用户中还操作第二对象的用户数m,确定第二对象与第一对象的关联度,第二对象为关联对象中的各个对象;关联对象确定模块,用于将与第一对象的关联度高于阈值的第二对象确定为关联对象。
在一个实施例中,关联度确定模块用于:将m与n的比值确定为第二对象与第一对象的关联度。
在一个实施例中,数据推送装置还包括:商品描述提取模块,用于在利用操作记录生成第一对象的操作关系网之前,提取关联对象的商品描述;文本分词模块,用于利用文本分词算法,对关联对象的商品描述进行文本分词;相同关联对象确定模块,用于将所得文本分词满足预设条件的关联对象确定为相同的关联对象;操作记录合并模块,用于将相同的关联对象的操作记录进行合并。
在一个实施例中,文本分词模块用于:利用结巴分词算法,对关联对象进行文本分词。
在一个实施例中,数据推送模块用于:按照与第一操作对象的关联度从高到低的顺序,向第一用户推送社区中的关联对象。
根据本发明实施例的另一个方面,提供了一种数据推送装置,包括:存储器;以及耦接至存储器的处理器,处理器被配置为基于存储在存储器中的指令,执行前述的数据推送方法。
根据本发明实施例的又一个方面,提供了一种计算机可读存储介质,计算机可读存储介质存储有计算机指令,指令被处理器执行时实现前述的数据推送方法。
本发明提供了更加优化的数据推送方法,能够智能的向用户推送相关联的数据。
通过以下参照附图对本发明的示例性实施例的详细描述,本发明的其它特征及其优点将会变得清楚。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
图1示出了本发明一个实施例的数据推送方法的流程示意图。
图2示出商品a的操作关系网。所谓操作关系网,在本示例中可
图3示出了本发明另一个实施例的数据推送方法的流程示意图。
图4示出了本发明又一个实施例的数据推送方法的流程示意图。
图5示出了本发明一个实施例的数据推送装置的结构示意图。
图6示出了本发明数据推送装置的另一个实施例的结构示意图。
图7示出了本发明数据推送装置的又一个实施例的结构示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。以下对至少一个示例性实施例的描述实际上仅仅是说明性的,决不作为对本发明及其应用或使用的任何限制。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其它实施例,都属于本发明保护的范围。
首先结合图1介绍本发明一个实施例的数据推送方法。
图1示出了本发明一个实施例的数据推送方法的流程示意图。如图1所示,该实施例中数据推送方法包括步骤s102~步骤s108。
步骤s102,获取第一对象和关联对象的操作记录,第一对象为第一用户操作的对象之一,关联对象为也操作第一对象的第二用户操作的对象,关联对象与第一对象不同。
例如,用户a购买了商品a,用户b也购买了商品a,同时用户b还购买了商品b。那么商品b即为商品a的关联对象,可以提取商品a以及商品b的购买记录。
步骤s104,利用操作记录生成第一对象的操作关系网,操作关系网的节点表示第一对象和关联对象,操作关系网的边表示对象之间存在操作关联关系。
图2示出商品a的操作关系网。所谓操作关系网,在本示例中可以理解为商品a的购买关系网。操作关系网的节点表示商品a以及包括商品b的关联商品,操作关系网的边表示商品之间存在购买关联关系。
步骤s106,利用社区发现算法,从操作关系网中确定第一对象所在的社区。
例如,可以通过gn算法从操作关系网中确定第一对象所在的社区。gn算法是一种分裂型的社区结构发现算法。该算法根据网络中社区内部高内聚、社区之间低内聚的特点,逐步去除社区之间的边,取得相对内聚的社区结构。算法用边介数的概念来探测边的位置,某边的边介数定义为网络上所有顶点之间的最短路径通过该边的次数。由定义可知,如果一条边连接两个社区,那么这两个社团节点之间的最短路径通过该边的次数就会最多,相应的边介数最大。如果删除该边,那么两个社团就会分割开。gn算就就是基于此思想反复计算当前网络的最短路径,计算每条边的边介数,删除边介数最大的边。最后在预设条件下算法停止,即可得到网络的社区结构,该预设条件可以为商品a所在社区中的节点数小于预设值。图2中的虚线圆圈示出了利用社区发现算法得出的商品a的操作关系网中的社区,其中包括商品a所在的社区。
步骤s108,向第一用户推送社区中的关联对象。
例如,可以向用户a推送商品a所在社区中的关联商品,购买商品a的用户还会有很大可能性购买商品a所在社区中的关联商品。即用户购买商品a之后,可以通过分析商品a的商品购买关系网发现用户购买商品a后的购买其它的商品,可以在猜你喜欢或者用户的商品a的订单详情页推荐这些商品。
上述实施例中,通过寻找其它也购买商品a的用户,提取购买过商品a的所有用户的所有的购买过的商品列表生成商品a的操作关系网,并通过社区发现算法从商品a的操作关系网中找出商品a所在的社区。本发明实现了更加优化的数据推送方法,由于商品a所在的社区中的商品与商品a紧密关联,本发明实现了更加智能的向用户a推送与商品a相紧密关联的商品,提升了用户体验。
下面结合图3介绍本发明另一个实施例的数据推送方法。
图3示出了本发明另一个实施例的数据推送方法的流程示意图。如图3所示,在图1所示实施例的基础上,本实施例中的数据推送方法包括步骤s300~步骤s308。
步骤s300,在获取第一对象以及关联对象的操作记录之前,根据操作第一对象的所有用户数,以及操作第一对象的所有用户中还操作第二对象的用户数,确定第二对象与第一对象的关联度,第二对象为关联对象中的各个对象。
例如,可以通过以下等式确定第二对象b与第一对象a的关联度spra,b。
其中spca,b表示购买商品a的所有用户中也购买商品b的用户数量,apc表示购买商品a的用户数量总和。
步骤s301,将与第一对象的关联度高于阈值的第二对象确定为关联对象。
步骤s302,参照图1所示实施例中的步骤s102。
步骤s304,参照图1所示实施例中的步骤s104。
步骤s306,参照图1所示实施例中的步骤s106。
步骤s308,按照与第一操作对象的关联度从高到低的顺序,向第一用户推送社区中的关联对象。
例如,可以在商品a所在社区中按照与商品a的关联度从高到低的顺序,向用户a推送商品a所在社区中的关联对象。
上述实施例中,通过计算其它商品与商品a之间的关联度筛选商品a的关联对象,可以进一步确定与商品a更加紧密关联的商品,并减少为生成商品a的购买关系网的运算量。同时,按照与第一操作对象的关联度从高到低的顺序,向用户a推送社区中的关联对象,能够使用户优先收到关联更紧密的推送数据,进一步提升用户体验。
下面结合图4介绍本发明又一个实施例的数据推送方法。
图4示出了本发明又一个实施例的数据推送方法的流程示意图。如图4所示,在图1所示实施例的基础上,在步骤s102以及步骤s104之间,本实施例中的数据推送方法还包括步骤s4032~步骤s4038。
步骤s4032,在利用操作记录生成第一对象的操作关系网之前,提取关联对象的商品描述。
例如,从用户购买记录表中提取所有用户购买的所有商品列表和所有商品的商品描述。
步骤s4034,利用文本分词算法,对关联对象进行文本分词。
例如,可以利用jieba结巴分词算法,对关联对象进行文本分词。开源的jieba分词支持三种分词模式:(1)精确模式,试图将句子最精确地切开,适合文本分析;(2)全模式,把句子中所有的可以成词的词语都扫描出来,速度非常快,但是不能解决歧义;(3)搜索引擎模式,在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词。
步骤s4036,将所得文本分词满足预设条件的关联对象确定为相同的关联对象。
通过jieba分词可以获取商品a相关的购买商品的关键词。例如,对“蒙牛纯牛奶puremilk250ml16盒”分词后得到如下关键词:
蒙牛/n
纯/n
牛奶/n
pure/n
milk/n
250ml16/n
盒/n
然后,可以将所得文本分词相同的个数大于预设值的关联对象确定为相同的关联对象,或者将所得文本分词相同的比例大于预设值的关联对象确定为相同的关联对象。例如,相同文本分词的个数大于5个,或者相同文本分词的占比大于80%,可以确定为相同的关联对象。
步骤s4038,将相同的关联对象的操作记录进行合并。
上述实施例中,通过文本分词算法,可以将具有不同描述的同一个商品归纳为同一个商品,从而更加准确的确定商品的操作关系网。特别的,利用jieba分词,可以在算法的时间与空间性能中寻找一定的平衡或者偏向。上述实施例中的文本分词算法复用性强,提高了自动化程度。
下面结合图5介绍本发明一个实施例的数据推送装置。
图5示出了本发明一个实施例的数据推送装置的结构示意图。如图5所示,本实施例的数据推送装置50包括模块502~508。
操作记录获取模块502,用于获取第一对象和关联对象的操作记录,第一对象为第一用户操作的对象之一,关联对象为也操作第一对象的第二用户操作的对象,关联对象与第一对象不同;
操作关系网生成模块504,用于利用操作记录生成第一对象的操作关系网,操作关系网的节点表示第一对象和关联对象,操作关系网的边表示对象之间存在操作关联关系;
社区发现模块506,用于利用社区发现算法,从操作关系网中确定第一对象所在的社区;
数据推送模块508,用于向第一用户推送社区中的关联对象。
上述实施例中,通过寻找其它也购买商品a的用户,提取购买过商品a的所有用户的所有的购买过的商品列表生成商品a的操作关系网,并通过社区发现算法从商品a的操作关系网中找出商品a所在的社区。本发明实现了更加优化的数据推送方法,由于商品a所在的社区中的商品与商品a紧密关联,本发明实现了更加智能的向用户a推送与商品a相紧密关联的商品,提升了用户体验。
在一个实施例中,数据推送装置50还包括关联度确定模块500以及关联对象确定模块501。
关联度确定模块500用于在获取第一对象以及关联对象的操作记录之前,根据操作第一对象的所有用户数n,以及操作第一对象的所有用户中还操作第二对象的用户数m,确定第二对象与第一对象的关联度,第二对象为关联对象中的各个对象;
关联对象确定模块501用于将与第一对象的关联度高于阈值的第二对象确定为关联对象。
在一个实施例中,关联度确定模块用于:将m与n的比值确定为第二对象与第一对象的关联度。
上述实施例中,通过计算其它商品与商品a之间的关联度筛选商品a的关联对象,可以进一步确定与商品a更加紧密关联的商品,并减少为生成商品a的购买关系网的运算量。同时,按照与第一操作对象的关联度从高到低的顺序,向用户a推送社区中的关联对象,能够使用户优先收到关联更紧密的推送数据,进一步提升用户体验。
在一个实施例中,数据推送装置50还包括商品描述提取模块5032、文本分词模块5034、相同关联对象确定模块5036以及操作记录合并模块5038。
商品描述提取模块5032用于在利用操作记录生成第一对象的操作关系网之前,提取关联对象的商品描述;
文本分词模块5034用于利用文本分词算法,对关联对象的商品描述进行文本分词;
相同关联对象确定模块5036用于将所得文本分词满足预设条件的关联对象确定为相同的关联对象;
操作记录合并模块5038用于将相同的关联对象的操作记录进行合并。
在一个实施例中,文本分词模块5034用于:利用结巴分词算法,对关联对象进行文本分词。
上述实施例中,通过文本分词算法,可以将具有不同描述的同一个商品归纳为同一个商品,从而更加准确的确定商品的操作关系网。特别的,利用jieba分词,可以在算法的时间与空间性能中寻找一定的平衡或者偏向。上述实施例中的文本分词算法复用性强,提高了自动化程度。
在一个实施例中,数据推送模块数据推送模块508用于:
按照与第一操作对象的关联度从高到低的顺序,向第一用户推送社区中的关联对象。
图6示出了本发明数据推送装置的另一个实施例的结构示意图。如图6所示,该实施例的数据推送装置60包括:存储器610以及耦接至该存储器610的处理器620,处理器620被配置为基于存储在存储器610中的指令,执行前述任意一个实施例中的数据推送方法。
其中,存储器610例如可以包括系统存储器、固定非易失性存储介质等。系统存储器例如存储有操作系统、应用程序、引导装载程序(bootloader)以及其他程序等。
图7示出了本发明数据推送装置的又一个实施例的结构示意图。如图7所示,该实施例的数据推送装置70包括:存储器810以及处理器820,还可以包括输入输出接口730、网络接口740、存储接口750等。这些接口730,740,750以及存储器810和处理器820之间例如可以通过总线750连接。其中,输入输出接口730为显示器、鼠标、键盘、触摸屏等输入输出设备提供连接接口。网络接口740为各种联网设备提供连接接口。存储接口750为sd卡、u盘等外置存储设备提供连接接口。
本发明还包括一种计算机可读存储介质,其上存储有计算机指令,该指令被处理器执行时实现前述任意一个实施例中的数据推送方法。
本领域内的技术人员应明白,本发明的实施例可提供为方法、系统、或计算机程序产品。因此,本发明可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。而且,本发明可采用在一个或多个其中包含有计算机可用程序代码的计算机可用非瞬时性存储介质(包括但不限于磁盘存储器、cd-rom、光学存储器等)上实施的计算机程序产品的形式。
本发明是参照根据本发明实施例的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。
这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。
这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。
以上所述仅为本发明的较佳实施例,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!