一种配电网负荷分类模型的建立方法与流程
本发明属于配电网分类技术领域,具体涉及一种基于深度学习网络算法的配电网负荷分类模型的建立方法。
背景技术:
随着我国经济的快速发展与人民生活水平的日益提高,用户用电量表现出增长的态势,各行业的快速发展使得用户用电需求趋于多元化,对供电的要求也日益提高。负荷的合理分类对于负荷特性分析、电网负荷预测、用户行为分析、电网调度、电网规划和业扩报装等都有着重要作用。
近年来,深度学习网络快速发展,对学术领域产生了重大影响,在多个领域都得到了广泛应用。深度信念网络(deepbeliefnets,dbn)是由一系列受限波尔兹曼机(restrictedboltzmannmachine,rbm)组成的深度学习网络,其由geoffreyhinton在2006年提出。作为一种生成模型,dbn通过训练其神经元间的权重,从而让整个神经网络按照最大概率来生成训练数据。为避免对深度学习网络整体训练的难题,深度信念网络将整体训练拆分为自下向上的逐层对rbm进行无监督训练,再通过神经网络学习算法自上向下对网络进行有监督训练。这样能够解决深层次网络的训练时间问题,又可以避免陷入局部最优解的问题,最终能够获得效果更好的参数值。
技术实现要素:
基于以上背景,本发明提供了一种高效准确的基于深度学习网络算法的配电网负荷分类模型的建立方法。
为实现以上目的,本发明的技术方案如下:
一种配电网负荷分类模型的建立方法,依次包括以下步骤:
步骤a、基于深度学习网络算法建立负荷分类初始模型,其中,所述负荷分类初始模型为包含两个隐层的dbn模型,且其输出层采用softmax函数压缩输出;
步骤b、采用训练数据集训练步骤a得到的负荷分类初始模型,得到训练模型;
步骤c、采用测试数据集测试步骤b得到的训练模型,若测试结果满足要求,则以该训练模型作为配电网负荷分类模型,否则返回步骤a,调整参数后再次训练,直至测试结果满足要求。
所述步骤a依次包括以下步骤:
步骤a1、根据所需分类负荷的特性曲线属性确定负荷分类初始模型的输入层、隐层、输出层的节点数,其中,所述输入层的节点数为负荷特性曲线的数据个数,输出层的节点数为负荷分类的类别数;
步骤a2、设定负荷分类初始模型的训练参数,该训练参数包括每层rbm网络的自我检查频次、初始学习效率、训练数据集的迭代训练次数。
所述步骤b依次包括以下步骤:
步骤b1、根据营销系统数据,收集不同行业、不同季节、工作日与非工作日的日典型负荷特性曲线与年典型负荷特性曲线,并根据负荷特性曲线横坐标个数的不同对曲线进行初步分类,确定负荷分类的类别数,其中,横坐标个数为dbn模型的输入层节点数,负荷分类的类别数为dbn模型的输出层节点数;
步骤b2、根据步骤b1得到的数据建立训练数据集,其中,所述训练数据集包括输入数据集x与输出数据集y;
步骤b3、采用z-score标准化法对输入数据集x进行归一化处理;
步骤b4、根据步骤a2设定的参数对每层rbm网络单独采用自下向上的非监督学习法进行预训练;
步骤b5、先将预训练后的每层rbm网络组合成新的dbn模型,然后利用步骤b2得到的训练数据集、根据步骤a2设定的训练参数、采用自上向下的有监督学习法对该dbn模型进行训练,得到训练模型;
所述步骤c依次包括以下步骤:
步骤c1、依次按照步骤b1、b2所述方法建立测试数据集,其中,所述测试数据集包括输入数据集xt与输出数据集yt;
步骤c2、按照步骤b3所述方法对输入数据集xt进行归一化处理;
步骤c3、先将输入数据集xt输入步骤b得到的训练模型中,然后将训练模型的输出结果与输出数据集y、输出数据集yt对应进行比较,统计训练数据集与测试数据集的分类正确率,若测试数据的正确率满足要求,则配电网负荷分类模型建立完毕,否则返回步骤a,调整参数后再次训练,直至测试数据的正确率满足要求。
所述步骤b3采用以下公式进行归一化处理:
式中,xi为输入数据集中的某一样本,μi为xi中样本数据的均值,σi为xi中样本数据的标准差,i=1,2,…,n,n为样本容量。
与现有技术相比,本发明的有益效果为:
1、本发明一种配电网负荷分类模型的建立方法先基于深度学习网络算法建立负荷分类初始模型,再采用训练数据集训练该初始模型得到训练模型,然后采用测试数据集测试训练模型,该设计充分发挥深度学习算法的优势,将其应用于配电网负荷分类上能够充分利用电网运行过程中海量的负荷数据对模型进行训练,从而保证了配电网负荷分类的准确、高效性,便于实际应用。因此,本发明保证了配电网负荷分类的准确、高效性。
2、本发明一种配电网负荷分类模型的建立方法采用z-score标准化法对输入数据集进行归一化处理,不仅有助于提高训练效率,而且能够提高训练精度。因此,本发明具有较高的训练效率和精度。
附图说明
图1为本发明的流程图。
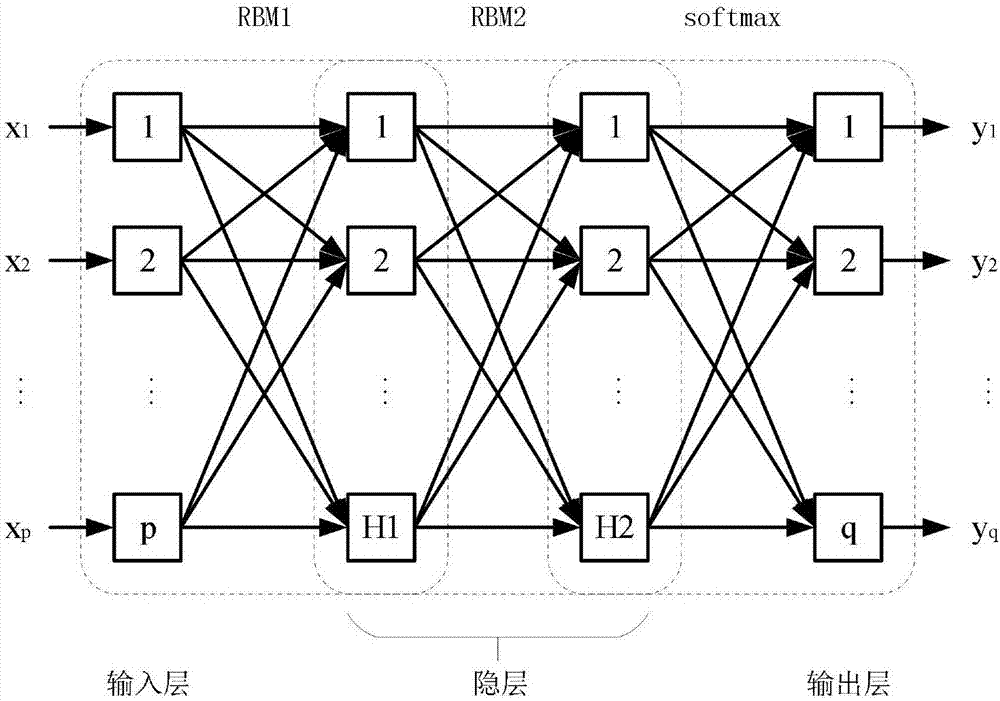
图2为本发明实施例1的dbn模型结构图。
具体实施方式
下面结合具体实施方式对本发明作进一步详细的说明。
参见图1,一种配电网负荷分类模型的建立方法,依次包括以下步骤:
步骤a、基于深度学习网络算法建立负荷分类初始模型,其中,所述负荷分类初始模型为包含两个隐层的dbn模型,且其输出层采用softmax函数压缩输出;
步骤b、采用训练数据集训练步骤a得到的负荷分类初始模型,得到训练模型;
步骤c、采用测试数据集测试步骤b得到的训练模型,若测试结果满足要求,则以该训练模型作为配电网负荷分类模型,否则返回步骤a,调整参数后再次训练,直至测试结果满足要求。
所述步骤a依次包括以下步骤:
步骤a1、根据所需分类负荷的特性曲线属性确定负荷分类初始模型的输入层、隐层、输出层的节点数,其中,所述输入层的节点数为负荷特性曲线的数据个数,隐输出层的节点数为负荷分类的类别数;
步骤a2、设定负荷分类初始模型的训练参数,该训练参数包括每层rbm网络的自我检查频次、初始学习效率、训练数据集的迭代训练次数。
所述步骤b依次包括以下步骤:
步骤b1、根据营销系统数据,收集不同行业、不同季节、工作日与非工作日的日典型负荷特性曲线与年典型负荷特性曲线,并根据负荷特性曲线横坐标个数的不同对曲线进行初步分类,确定负荷分类的类别数,其中,横坐标个数为dbn模型的输入层节点数,负荷分类的类别数为dbn模型的输出层节点数;
步骤b2、根据步骤b1得到的数据建立训练数据集,其中,所述训练数据集包括输入数据集x与输出数据集y;
步骤b3、采用z-score标准化法对输入数据集x进行归一化处理;
步骤b4、根据步骤a2设定的参数对每层rbm网络单独采用自下向上的非监督学习法进行预训练;
步骤b5、先将预训练后的每层rbm网络组合成新的dbn模型,然后利用步骤b2得到的训练数据集、根据步骤a2设定的训练参数、采用自上向下的有监督学习法对该dbn模型进行训练,得到训练模型;
所述步骤c依次包括以下步骤:
步骤c1、依次按照步骤b1、b2所述方法建立测试数据集,其中,所述测试数据集包括输入数据集xt与输出数据集yt;
步骤c2、按照步骤b3所述方法对输入数据集xt进行归一化处理;
步骤c3、先将输入数据集xt输入步骤b得到的训练模型中,然后将训练模型的输出结果与输出数据集y、输出数据集yt对应进行比较,统计训练数据集与测试数据集的分类正确率,若测试数据的正确率满足要求,则配电网负荷分类模型建立完毕,否则返回步骤a,调整参数后再次训练,直至测试数据的正确率满足要求。
所述步骤b3采用以下公式进行归一化处理:
式中,xi为输入数据集中的某一样本,μi为xi中样本数据的均值,σi为xi中样本数据的标准差,i=1,2,…,n,n为样本容量。
本发明的原理说明如下:
本发明将深度学习理论应用于配电网负荷分类有助于将电网运行过程中海量的负荷数据利用起来,根据具体需求制定合理的分类方法,使负荷分类过程准确、高效。
本发明所述负荷分类模型为使用两个rbm堆叠而成的dbn模型,该dbn模型中共包含两个隐层,最后一层采用softmax函数压缩输出使之具有概率意义以便实现分类功能。
本发明对负荷分类初始模型的训练分为两步实施:第一步采用非监督学习方法自下向上对每个rbm进行充分的预训练,获取rbm的初始权值;第二步将两层rbm堆叠成dbn模型,该部采用自上向下的有监督学习方法对该网络进行训练,对网络权重初值进行微调,可确保整个网络权重达到最优分布。另外,在第一步中需要确定每层rbm网络自我检查的频次t与初始学习效率k;在第二步中需要确定dbn模型采用训练数据迭代训练的次数m。
本发明所述输出层的节点数是根据具体需求制定合理的分类方法后人为设定的个数。
实施例1:
参见图1,一种配电网负荷分类模型的建立方法,依次按照以下步骤进行:
步骤1、基于深度学习网络算法建立负荷分类初始模型,其中,所述负荷分类初始模型为包含两个隐层的dbn模型(参见图2),且其输出层采用softmax函数压缩输出,本实施例采用每隔1h记录一次的日负荷特性曲线作为网络的输入,因此输入层节点数为p=24,设定输出层节点数选取为q=5,隐层的节点数选取为h1=50、h2=50;
步骤2、设定下层rbm网络的自我检查频次t1=10、初始学习效率k1=0.005,上层rbm网络的自我检查频次t2=100、初始学习效率k2=0.005,训练数据集的迭代训练次数m=50000;
步骤3、根据营销系统数据,收集不同行业、不同季节、工作日与非工作日的日典型负荷特性曲线与年典型负荷特性曲线,并根据负荷特性曲线横坐标个数的不同对曲线进行初步分类,确定负荷分类的类别数,其中,横坐标个数为dbn模型的输入层节点数,负荷分类的类别数为dbn模型的输出层节点数;
步骤4、根据步骤3得到的数据建立训练数据集,其中,所述训练数据集包括输入数据集x与输出数据集y,有5类曲线,每类1000条,样本容量n=5000
xi=(x1x2…xp);
yi=(y1y2…yq);
式中,xi(i=1,2,…,n)为输入数据集x中的一个样本,是由负荷特性曲线中纵坐标数值组成的一维行向量,yi(i=1,2,…,n)为输出数据集y中对应xi的一个样本,表示对应负荷特性曲线的分类结果;
步骤5、采用z-score标准化法对输入数据集x进行归一化处理:
式中,μi为xi中样本数据的均值,σi为xi中样本数据的标准差;
步骤6、根据步骤2设定的训练参数对每层rbm网络单独采用自下向上的非监督学习法进行预训练;
步骤7、先将预训练后的每层rbm网络组合成dbn模型,然后利用步骤4得到的训练数据集、根据步骤2设定的训练参数、采用自上向下的有监督学习法对该dbn模型进行训练,得到训练模型;
步骤8、依次按照步骤3、4所述方法建立多组测试数据集,其中,所述测试数据集包括输入数据集xt与输出数据集yt,每组测试数据集有5类曲线,每类100条,样本容量s=500;
步骤9、按照步骤5所述方法对输入数据集xt进行归一化处理;
步骤10、先将输入数据集xt输入步骤7得到的训练模型中,然后将训练模型的输出结果与输出数据集y、输出数据集yt对应进行比较,统计训练数据集与测试数据集的分类正确率,若测试数据的正确率满足要求,则配电网负荷分类模型建立完毕,否则返回步骤1,调整参数后再次训练,直至测试数据的正确率满足要求。
实验结果表明,采用本实施例步骤1与步骤2设定的参数得到的训练模型,测试数据平均的正确率在98%以上。
- 还没有人留言评论。精彩留言会获得点赞!