一种基于人工智能的在线教育人机交互方法与系统与流程
本发明涉及电子信息领域的一种数字化视听技术,包括一种能够识别受众情绪的子系统和智能会话子系统,尤其是将其二者与在线教育系统相结合,可以更好向受众呈现个性化的教学内容。
背景技术:
在线教育(也称为e-learning)是通过应用信息科技和互联网技术进行课程内容传播分享和快速学习的方法。在线教育的教学方式以网络为介质,用户与教师通过网络即使相隔万里也可以开展教学活动;此外,借助网络课件,用户还可以随时随地进行学习,真正打破了时间和空间的限制,网络远程教育是最方便不过的学习方式。
现有的在线教育系统,包括教师终端、网关服务器、用户终端等设备、教师终端提供课程的视频信息,然后宽带网关设备通过网关服务器将课程视频信息发送到用户终端,受众通过用户终端即可观看老师的授课内容。然而,在发展的过程中也出现了一些问题:由于虚拟世界的限制,受众与老师交互性不好;每个用户的学习进度不一致,对知识点的掌握程度不一样,而采用统一的课表难以满足受众个性化的需求。
为了解决上述技术问题,专利cn201320133075.8公开了包括教师终端、服务器和至少一个用户终端的解决方案,所述教师终端和所述至少一个用户终端都借助于无线通信网络连接到所述服务器。专利cn201410132195.5公开了一种在线教育互动的方法及系统,包括由第一客户端获取用户手动书写的信息,响应用户的发送请求,将手动书写的信息发送至目标客户端;目标客户端接收后,将所述信息呈现给目标用户,同时获取目标用户手动书写的反馈信息的方式来实现。专利cn201310567606.9公开发了一种在线教育提问方法及系统,包括服务器,以及与该服务器连接的讲师端和若干用户端,该系统包括:提交模块,设置于讲师端和若干用户端;用于用户端提交问题或者答案至服务器的转发模块;转发模块,设置于服务器中,用于服务器将问题发送至其他用户端和讲师端进行显示,以及所述答案发送至用户端和讲师端。专利cn201610813907.9提供了一种移动互联网的在线教育系统,包括:云存储端、客户端、资料结构化单元、个性化推荐单元、学习评估单元等模块。云存储端用于提供海量数据的云存储,实现数据保存、备份;客户端,该客户端用于上传或下载相应的数据;资料结构化单元用于将数据中的学习资料进行分类并转换成细粒度可考核,形成可评估数据;个性化推荐单元根据学习资料官方定制或用户个性化定制若干课程模板,该模块根据课程模板定制课程顺序实现在线教育;学习评估单元根据练习评测、测验评测、学习过程收集的数据,评估学员学习情况。
总体来看,虽然现有的在线教育系统已经能够在某些方面初步提供个性化的服务,但在交互在线教育方法与系统方面还未见专利报道。本发明以现有流行在线教育平台为基础框架,以情绪识别模块的输出为依据,通过智能会话模块围绕课程内容进行个性化的人机交互。
技术实现要素:
目前的在线教育,向用户直接提供视频,无法根据用户的学习状态适时调整课堂内容,因此,效果并不理想。它对用户的认知水平要求较高;缺乏有效管理;对于系统性和操作性较强的知识的学习缺乏优势,缺乏人机互动交流。本发明公开一种基于人工智能的在线教育人机交互方法与系统,包括在线教育人机交互方法、情绪识别子系统和智能会话子系统。本系统从增强在线学习的人机交互生动性角度出发,情绪识别子系统通过用户观看视频时的表情来判断用户的学习状态。而智能会话子系统会根据不同的情绪来调节相应的课程内容并进行机器问答式的交互,从而起到将传统课堂上的师生交互与反馈搬到线上,赋予在线课堂以更加逼真的拟人互动性。(如图1)
面向在线教育的情绪识别子系统是指,通过用户端摄像头采集的影像信息,利用计算机情绪识别技术分析用户的情绪,进而判断用户的学习状态和接受程度。在此基础上,适时调整在线课程的呈现内容与方式,解决传统在线教育学习效果不佳的问题。
面向在线教育的智能会话子系统是指,通过接收用户的语音输入并将其转换成文字形式,再利用自然语言理解模块对其进行处理。会话管理负责协调以上各部分的调用及维护当前会话状态,选择特定回复方式并交由自然语言生成部分进行处理。自然语言生成部分输出文字形式的回复,作为输入由语音合成部分将文字转换成语音输出给用户。
本发明解决其技术问题所采取的具体技术方案:情绪识别子系统可概括为5个部分:卷积神经网络提取图像特征,递归神经网络建模时序特征,音频模块处理音频信息,aggregatedcnn进行粗略分类,融合网络将不同类型特征融合。智能会话子系统可概括为5个部分:语音识别,自然语言理解,对话管理,自然语言生成,语音合成。
卷积神经网络作为特征提取器,提取图像特征。递归神经网络将图像特征在时间序列上进行建模。音频模块作为音频特征提取器,提取音频特征。聚集卷积神经网络接收来自卷积神经网络的特征向量,对特征进行粗略的分类。融合网络将不同类型的特征融合,对该小片段视频的情绪进行预测。情绪识别子系统最终将受众的情绪分为七类:生气、厌恶、害怕、伤心、惊讶、中立、开心。
语音识别模块负责接收用户的语音输入并将其转换成文字形式交由自然语言理解模块进行处理。自然语言理解模块是了一个基于本体和语义文法的上下文相关问答系统。会话管理模块负责协调各个模块的调用及维护当前会话状态,选择特定回复方式并交由自然语言生成模块进行处理。自然语言生成模块输出文字形式的回复,作为输入交由语音合成模块进行语音合成的处理。语音合成模块中使用统计参数语音合成方法将自然语言生成模块的输出转换成语音,然后输出给用户。
针对不同的情绪,智能会话子系统会通过人机问答的形式做出不同的交互,以调节课堂节奏和气氛,帮助用户轻松愉快地完成课程内容的学习。
以在线教育为背景,基于人工智能的在线教育人机交互方法将生气、厌恶、害怕、伤心、惊讶、中立、开心七种情绪对应地理解为:课堂节奏过慢或过快产生抵触情绪、不适应讲者的授课风格、课堂内容难度太大产生畏难情绪、跟不上课堂进度、不能理解讲者所授内容(生气、厌恶、害怕、伤心),意想不到的知识点(惊讶),正在认真听讲(中立),对知识点理解的很透彻(开心)。
例如,当用户流露出惊讶、中立、开心的表情时,系统会认为其对该部分知识掌握较好,将推送下一场景或给出适当的褒扬,并提升课堂节奏;当用户流露出生气、厌恶的表情时,系统会认为其对老师授课风格不适应,或感觉该部分内容较为枯燥,将播放舒缓音乐等调节课堂气氛,让用户尽快进入良好的学习状态;当用户流露出害怕、伤心的表情时,系统会认为其因为知识内容太过深入难以理解,或产生了畏难情绪,将给课堂管理者及时的反馈,并适当调整课程内容或者补充辅助的知识,帮助用户重新理解这部分内容。
智能会话子系统在用户学习的同时会自动管理一个重点内容提示窗口,该窗口是当前讲述内容的重点知识。依据所讲述的内容智能会话子系统在适当的场景下提出对应的问题。若用户回答正确且情绪识别子系统的反馈结果为惊讶、中立或开心的三者之一,则将推送下一教学场景。若用户回答正确且情绪识别子系统的反馈是厌恶,智能会话子系统则发出“这个内容或许有些单调,但这是基础,沉住气坚持下去”等类似的温馨提示。若在教学过程中用户出现生气或厌恶情绪,则由智能会话子系统播放舒缓的乐曲或者风趣的问答对话,待用户情绪恢复则继续进行教学。若在教学过程中用户出现害怕或伤心情绪,则智能会话子系统进行心理安抚,如发出:“这个内容确实很难,你已经很棒啦”、“加油哦,不要气馁呦”等鼓励性话语。然后在将上一教学场景的内容重新展示或跳到该教学场景内容的细化部分,之后再由智能会话子系统进行出题测试,测试通过后即可推送下一教学场景。若在教学过程中用户出现比较惊讶的情绪,根据教学内容弹出“这个方法是不是很高大上哦”、“加油,你马上就能理解和掌握这种方法”等鼓励性提示。
为了便于系统管理不同深度的教学内容,课程采取三层模板的方式进行组织。第一层为全部课程的知识概况,该层展示了课程的知识大类,起到类似一级目录的作用;第二层为给定知识的正式教学内容,该层为用户提供了具体课程内容,是教学组织的核心层,起到类似二级目录的作用;第三层为正式教学内容的补充和拓展知识,是对教学内容的辅助说明,以便加深用户的理解,起到类似三级目录的作用。
附图说明:
图1在线教育平台总流程图
图2情绪特征提取卷积神经网络框架示意图
图3递归神经网络单个神经元在时间序列上的模型示意图
图4聚集卷积神经网络框架示意图
图5语音识别模块框架示意图
图6声学模型的建立流程
图7tri-gram语言模型建模过程
图8自然语言理解模块框架示意图
图9会话管理总控模块框架示意图
图10自然语言生成模块框架示意图
图11语音合成模块框架示意图
具体实施方式
从实时采集的视频图像中定位用户的人脸位置,进行图像预处理。首先,对实时视频进行逐帧处理,对于每一帧调用人脸定位算法,确定人脸的位置,然后进行调整人脸图像大小,深度等预处理工作,以适应于情绪识别的输入端要求。
情绪识别子系统(如图1中情绪识别子系统部分所示)可概括的分为5个部分:卷积神经网络提取图像特征,递归神经网络建模时序特征,音频模块处理音频信息,aggregatedcnn进行粗略分类,融合网络将不同类型特征融合。该情绪识别子系统将情绪分为7类,分别是:生气、厌恶、害怕、开心、伤心、惊讶和中立。
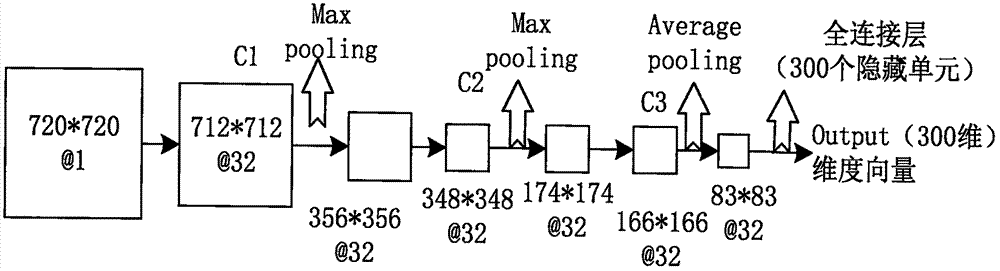
接下来,分别介绍情绪识别子系统的几个部分。所述的卷积神经网络(如图2所示)包含3个卷积层,每个卷积层后带一个池化层。第一个卷积层有32个9×9大小的卷积核,其后跟着一个最大池化层。第二个卷积层也有32个9×9大小的卷积核,其后跟着一个平均池化层。接着是第三个卷积层有64个9×9大小的卷积核,其后跟着一个平均池化层。接着是有300个隐藏单元的全连接层。cnn所用激活函数为relu,其函数形式为:
relu(x)=log(1+exp(x))
全连接层之后用一个递归神经网络(如图3所示)将视频中用户所表达的情绪在时间序列上进行建模。聚集cnn网络(如图4所示)在前述卷积神经网络基础上添加了k-mean层以及softmax输出,softmax层神经元个数为7个。融合网络将音频中提取的前十个主成分特征、聚集cnn的输出以及rnn的输出作为输入,然后将这些输入进行正则化。最后,再输入给一个softmax层(含有7个神经元),即可将受众情绪分为7类。
智能会话子系统(如图1中智能会话子系统部分所示)可概括地分为5个部分:(1)语音识别,(2)自然语言理解,(3)会话管理,(4)自然语言生成,(5)语音合成。语音识别模块负责接收用户的语音输入并将其转换成文字形式交由自然语言理解模块进行处理。会话管理模块负责协调各个模块的调用及维护当前会话状态,选择特定回复方式并交由自然语言生成模块进行处理。自然语言生成模块输出文字形式的回复,作为输入交由语音合成模块转换成语音输出给用户。
智能会话子系统的各个部分的结构为:
(1)语音识别模块(如图5所示)包括信号处理,解码器以及声学模型和语言模型。信号处理模块将根据人耳的听觉感知特点,抽取语音中最重要的特征,主要包括线性预测编码与梅尔频率倒谱系数,将语音信号转换为特征矢量序列。解码器根据声学模型和语言模型,将输入的语音特征矢量序列转化为字符序列。声学模型是对声学、语音学、环境的变量,以及说话人性别、口音的差异等的知识表示。语言模型则是对一组字序列构成的知识表示。
(2)自然语言理解模块(如图8所示)构建了一个基于文法和分类的问答系统。该模块是一个集问题分析处理,文本检索处理和答案抽取处理的管道模型。前一处理的输出是后一处理的输入,前一步的处理结果是后一步的处理对象。问题分析处理对问句进行句法和语义分析,以明确问题预期的答案类型以及抽取出查询关键词以用于相关文本的检索;文本检索处理利用第一个模块返回的查询关键词,从海量文档集中检索到包含答案的相关文档。从相关文档中,提取出包含答案的文档片段,以进一步减少答案抽取空间;答案抽取处理根据问题分析模块产生的各种约束条件,如问题的语义类别,命名实体类型,从文档片段中提取出答案,对答案进行处理后作为问答系统最后的输出结果。
(3)会话管理总控模块(如图9所示)负责协调和调度课程表示,学习记录管理,会话上下文管理和会话生成这四个模块。其中,课程表示模块,学习记录管理模块和会话上下文管理模块之间没有关联,都为会话生成模块服务,提供辅助的信息。课程表示模块(此模块还没有体现在架构图中)将设计通用的课程表示模板。针对在线教育系统,以课程为单位,研究课程知识的表示方法,设计课程形式表示模板,使得以该模板表示的课程内容能够方便地被会话机器人所使用乃至理解,从而达到自由运用到会话情景当中的目的。学习记录模块的记录包括学习活动的时间与内容,还包括各阶段的测试成绩,也包括用户在教育平台中各课程之间的横向活动记录。该模块的目的是让会话机器人掌握用户的学习情况,并重点评估用户对各知识点的理解和记忆程度,以便抽取需要强化的知识点,进行新会话的设计。会话上下文管理模块(此模块还没有体现在架构图中)管理和分析用户与机器人的对话,重点掌握用户当前的专注程度和情绪,从而为会话的生成提供辅助的信息。该部分采用前馈人工神经网络分析会话的语气语调等信息。会话生成模块(此模块还没有体现在架构图中)的功能是通过自然语言生成模块形成文字会话形式,后续经过语音合成模块处理可以转换成语音形式从而输出。
(4)自然语言生成模块(如图10所示)采用encoder-decoder框架。如图5所示,encoder部分采用多层向前神经网络,decoder部分采用rnn神经网络。将context和message拼接起来形成一个长的输入提供给encoder,把上下文信息融入模型之中。用框架来解决自然语言生成问题时,其含义是当用户输入message后,经过encoder-decoder框架计算,首先encoder对输入进行语义编码,形成中间语义表示c,decoder根据c生成了会话子系统的应答response。这样,用户反复输入不同的message,聊天机器人每次都形成新的response。
(5)语音合成模块(如图11所示)中使用统计参数语音合成方法。首先对输入文木进行分析,得到所需要的标注数据,即上下文属性;然后报据这些属性分别对时长、基频和谱参数的聚类决策树进行决策,并得到相应的模型序列;接着根据时长模型序列得到对应的状态序列,也就是预测出每个状态对应的顿数;最后结合预测出的状态时长,由基频模型和频谱模型基于参数生成算法来预测基频特征和频谱特征,该算法能保证生成平滑连续的特征轨迹。预测出基频特征和频谱特征被送入高质量合成器,合成出最终的语音。其中采用线谱对特征作为频谱特征。预测出的线谱对特征首先被转换成对应的系数,然后由系数恢复成频谱包络。恢复出的频谱包络和预测的基频特征被统一送入来重建语音。
- 还没有人留言评论。精彩留言会获得点赞!