一种数据快速采集系统及方法与流程
本发明涉及大数据领域,具体地说是一种实用性强的数据快速采集系统及方法。
背景技术:
在大数据时代,面对海量数据的etl过程经常会选择kafka作为消息中间件应用在离线和实时的使用场景中,而kafka的数据上游和下游一直没有一个无缝衔接的pipeline来实现统一,通常会选择flume或者logstash采集数据到kafka,然后通过其他方式pull或者push数据到目标存储如笔者申请的专利cn201710391446中所示。
分布式模式的kafkaconnect的workers提供了可扩展性以及自动容错的功能,当connector第一次提交到集群、新增worker或者某个worker出现异常退出时,会触发task再平衡操作,避免将工作压力都集中在某个或某几个节点。而flume的自动容错需要相当复杂的配置,仅仅是在一个节点上实现了线程级别的工作压力分担。
如图1所示,kafkaconnect是一个分布式的数据采集程序,它主要包括以下几个子组件:
sourceconnector子组件:负责接收数据单元,并将数据单元批量的放置到kakfa集群指定topic的消息队列中。
sinkconnector子组件:负责消费指定topic的数据并将其传输到下一跳或最终的目标存储。
kafka集群:位于sourceconnector与sinkconnector子组件之间,用于缓存进来的消息数据。
在该申请案中,kafkaconnect旨在围绕kafka构建一个可扩展的,可靠的数据流通道,可以快速实现海量数据进出kafka,从而和其他数据源或者目标数据源进行交互,构造一个低延迟的数据pipeline。它提供了rest的api可动态添加、启动、停止connector,目前仅支持在系统中采集普通文件系统文件的数据,同时提供对数据进行简单处理,仅支持下沉到普通文件系统。
现有的sinkconnector组件仅有filestreamsinkconnector组件,并且数据都是下沉到基于hdd(harddiskdrive)硬盘驱动器的文件系统,因此kafkaconnect的sinkconnector组件的性能瓶颈就在hdd的i/o操作上。即使将数据下沉到基于ssd(solidstatedrive)固态硬盘的文件系统,不仅大大增加了硬件的投入成本,而且数据下沉组件的性能提升也有限。
因此,亟需一种提高数据下沉效率、不再像flume一样需要复杂配置的数据快速采集技术。
技术实现要素:
本发明的技术任务是针对以上不足之处,提供一种实用性强的数据快速采集系统及方法。
一种数据快速采集系统,包括,
kafkaconnect组件,用于进行数据采集;
数据下沉组件,在分布式内存文件系统alluxio中设计,用于连接上述kafkaconnect组件,并将kafkaconnect组件采集的数据存储到存储系统中;
存储系统,用于存储来自数据下沉组件的数据。
所述数据下沉组件在分布式内存文件系统alluxio启用分层存储后,提供分配、回收策略和预留空间的规则,其中,
分配规则采用轮询调度分配的方式,即分配数据块到有空间的最高存储层,存储目录通过轮询调度选出;
回收策略采用lrfu回收,即基于权重分配的最近最少使用和最不经常使用策略来移除数据块;
预留空间规则是指每层存储预留空间比例。
所述存储系统采用分布式存储系统hdfs,并配置在mem、ssd或hdd存储结构中,相对应的,数据下沉组件提供的预留空间规则为:mem预留0.4,ssd预留0.2,hdd不启用预留。
所述kafkaconnect组件中提供sourceconnector抽象类、sinkconnector抽象类、sinktask抽象类,相对应的,数据下沉组件中提供继承自kafkaconnect组件中抽象类的下述结构:
alluxiofilestreamsinkconnectork类,继承自抽象类sinkconnector,用于读取与alluxio相关的配置参数,这里的配置参数包括alluxio的uri地址、文件路径、文件类型、文件名称生成策略、以及文件滚动策略。
alluxiofilestreamsinktask类,继承自抽象类sinktask,通过循环处理接收到的数据,将它们按照hdfs中对应的文件格式写入alluxio分布式内存文件系统,所述hdfs中对应的文件格式包括文本、顺序文件、avro文件。
所述alluxiofilestreamsinktask类还用于刷写数据到alluxio文件系统以及提交已经当前消费的topic各个分区的偏移量信息。
一种数据快速采集方法,基于上述系统,其实现过程为:
一、首先启动alluxio集群,通过alluxio分布式内存文件系统设计数据下沉组件;
二、将设计的数据下沉组件的jar包分发到安装kafkaconnect组件的集群中每个节点机器的类加载路径;
三、通过kafkaconnect组件进行数据采集;
四、数据下沉组件将kafkaconnect组件采集的数据存储到分布式存储系统hdfs中。
所述步骤四中通过数据下沉组件实现数据下沉包括:
alluxiofilestreamsinkconnectork类通过以下命令:start(map<string,string>config),读取有关alluxio的相关配置参数,这里的配置参数包括alluxio的uri地址、文件路径、文件类型、文件名称生成策略、以及文件滚动策略;
alluxiofilestreamsinktask类通过以下命令:put(collection<sinkrecord>records),循环处理接收到的数据,将它们按照hdfs中对应的文件格式写入alluxio分布式内存文件系统,然后再将处理后的数据存储到hdfs中。
所述hdfs中对应的文件格式包括文本、顺序文件、行式存储文件、列式存储文件。
所述alluxiofilestreamsinktask类还通过以下命令:flush(map<topicpartition,offsetandmetadata>offsets),刷写数据到alluxio文件系统以及提交已经当前消费的topic各个分区的偏移量信息。
本发明的一种数据快速采集系统及方法和现有技术相比,具有以下有益效果:
本发明的一种数据快速采集系统及方法,数据下沉组件通过利用alluxio的异步写入和层次存储特性降低了硬件的投入成本,并且提高了数据下沉的效率,提升了kafkaconnect数据采集的性能;利用kafkaconnect的任务再平衡操作,实现了数据采集集群高可用的自动容错以及负载均衡;通过配置的分配策略将数据尽量平均地分配到集群中的每个节点上,避免了一定程度的数据倾斜问题,实用性强,适用范围广泛,易于推广。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据提供的附图获得其他的附图。
附图1为现有技术的kafka数据采集示意图。
附图2为本发明中的kafka数据采集示意图。
附图3为本发明方法实现流程图。
具体实施方式
为了使本技术领域的人员更好地理解本发明的方案,下面结合具体实施方式对本发明作进一步的详细说明。显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
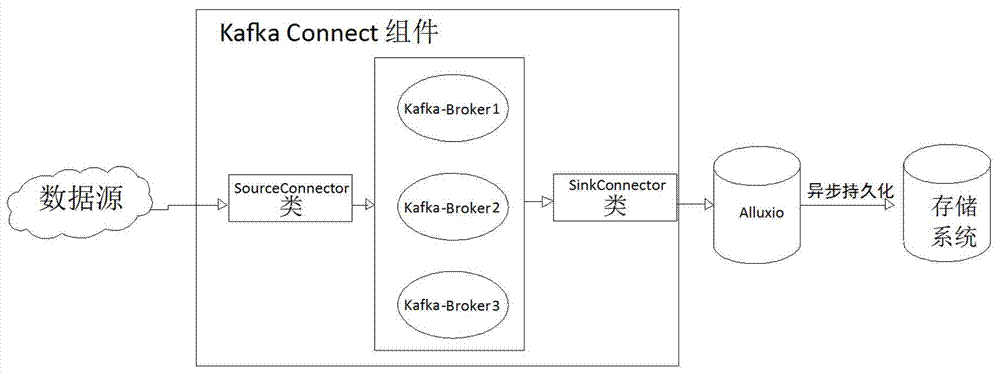
如附图2所示,一种数据快速采集系统,采用alluxio分布式内存文件系统作为kafkaconnect组件的目标存储,设计了alluxiosinkconnector数据下沉组件。通过利用alluxio系统的异步持久化特性提高了数据下沉的效率;当connector第一次提交到集群、新增worker或者某个worker出现异常退出时,分布式kafkaconnect会触发task再平衡操作,避免将工作压力都集中在某个或某些节点,实现了kafkaconnect高可用的自动容错以及负载均衡。
其结构包括,
kafkaconnect组件,用于进行数据采集;
数据下沉组件,在分布式内存文件系统alluxio中设计,用于连接上述kafkaconnect组件,并将kafkaconnect组件采集的数据存储到式存储系统中;
存储系统,用于存储来自数据下沉组件的数据。
所述数据下沉组件在分布式内存文件系统alluxio启用分层存储后,提供分配、回收策略和预留空间的规则,其中,
分配规则采用轮询调度分配的方式,即分配数据块到有空间的最高存储层,存储目录通过轮询调度选出;
回收策略采用lrfu回收,即基于权重分配的最近最少使用和最不经常使用策略来移除数据块;
预留空间规则是指每层存储预留空间比例。
所述存储系统采用分布式存储系统hdfs,并配置在mem、ssd或hdd存储结构中,相对应的,数据下沉组件提供的预留空间规则为:mem预留0.4,ssd预留0.2,hdd不启用预留。
所述kafkaconnect组件中提供sourceconnector抽象类、sinkconnector抽象类、sinktask抽象类,相对应的,数据下沉组件中提供继承自kafkaconnect组件中抽象类的下述结构:
alluxiofilestreamsinkconnectork类,继承自抽象类sinkconnector,用于读取与alluxio相关的配置参数,这里的配置参数包括alluxio的uri地址、文件路径、文件类型、文件名称生成策略、以及文件滚动策略。
在上述结构中,kafka和其他系统之间复制数据时,需要创建自定义的从系统中pull数据或push数据到系统的connector(连接器)。connector有两种形式:sourceconnector,从其他系统导入数据(如:jdbcsourceconnector将导入一个关系型数据库到kafka);sinkconnector,导出数据(如:hdfssinkconnector将kafka主题的内容导出到hdfs文件)。connector不会执行任何复制自己的数据:它们的配置展示了要复制的数据,而connector是负责打破这一工作变成一组可以分配worker的任务。这些任务也有两种相对应的形式:sourcetask和sinktask。在手里的任务,每个任务必须复制其子集的数据或kafka的。在kafka系统中,这些任务作为一组具有一致性模式的记录(消息)组成的输出和输入流。有时,这种映射是明显的:在一组日志文件,每个文件可以被视为一个流,每个分析的行形成一个记录,使用相同的模式和offset存储在文件中的字节偏移。
alluxiofilestreamsinktask类,继承自抽象类sinktask,通过循环处理接收到的数据,将它们按照hdfs中对应的文件格式写入alluxio分布式内存文件系统。
所述alluxiofilestreamsinktask类还用于刷写数据到alluxio文件系统以及提交已经当前消费的topic各个分区的偏移量信息。
如附图3所示,一种数据快速采集方法,基于上述系统,其实现过程为:
一、首先启动alluxio集群,通过alluxio分布式内存文件系统设计数据下沉组件;
二、将设计的数据下沉组件的jar包分发到安装kafkaconnect组件的集群中每个节点机器的类加载路径;
三、通过kafkaconnect组件进行数据采集;
四、数据下沉组件将kafkaconnect组件采集的数据存储到分布式存储系统hdfs中。
在步骤二中进行数据下沉组件的分发时,还需要配置数据采集的connector.class为alluxiofilestreamsink,然后启动数据下沉组件进行数据采集。
所述步骤四中通过数据下沉组件实现数据下沉包括:
alluxiofilestreamsinkconnectork类通过以下命令:start(map<string,string>config),读取有关alluxio的相关配置参数,这里的配置参数包括alluxio的uri地址、文件路径、文件类型、文件名称生成策略、以及文件滚动策略;
alluxiofilestreamsinktask类通过以下命令:put(collection<sinkrecord>records),循环处理接收到的数据,将它们按照hdfs中对应的文件格式写入alluxio分布式内存文件系统,然后再将处理后的数据存储到hdfs中。
所述hdfs中对应的文件格式包括文本、顺序文件、行式存储文件、列式存储文件。
所述alluxiofilestreamsinktask类还通过以下命令:flush(map<topicpartition,offsetandmetadata>offsets),刷写数据到alluxio文件系统以及提交已经当前消费的topic各个分区的偏移量信息。
通过自定义kafkaconnect中converter,针对hdfs中的不同文件类型,设计研发了hdfs中text、sequence、parquet等格式数据与kafkaconnect内部格式数据的转换类。
本发明通过利用alluxio的异步写入和层次存储特性降低了硬件的投入成本,并且提高了数据下沉的效率,提升了kafkaconnect数据采集的性能。利用kafkaconnect的任务再平衡操作,实现了数据采集集群高可用的自动容错以及负载均衡。通过配置的分配策略将数据尽量平均地分配到集群中的每个节点上,避免了一定程度的数据倾斜问题。
kafkaconnect是一种用于在kafka和其他系统之间可扩展的、可靠的流式传输数据的工具。它使得能够快速定义将大量数据集合移入和移出kafka的连接器变得简单。
分布式模式的kafkaconnect的workers提供了可扩展性以及自动容错的功能,当connector第一次提交到集群、新增worker或者某个worker出现异常退出时,会触发task再平衡操作,避免将工作压力都集中在某个或某几个节点。而flume的自动容错需要相当复杂的配置,而且仅仅是在一个节点上实现了线程级的工作压力分担。
在上述描述中,涉及的部分描述定义如下:
connectors:定义了数据源和数据下沉的目标系统,connector实例是一个需要负责在kafka和其他系统之间复制数据的逻辑作业。
tasks:每个connector会协调一系列的task去执行任务,connector可以把作业分成许多task,在分布式模式下,然后再把task分发到各个woker中执行,task将状态信息保存在kafka集群的指定topic下,当connector第一次提交到集群、新增worker或者某个worker出现异常退出时,会触发task再平衡操作,避免将工作压力都集中在某个或某些节点。
workers:connectors和tasks都是逻辑工作单位,必须在进程中执行,worker就是进程。分布式模式下,worker提供了可扩展性以及自动容错功能。
converters:converter会把bytes数据转换成kafkaconnect内部的格式(avro),也可以把内部存储格式的数据转变成bytes,converter对connector来说是解耦的。
以上所述仅为本发明的较佳实施例,本发明的专利保护范围包括但不限于上述具体实施方式,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明的专利保护范围之内。
通过上面具体实施方式,所述技术领域的技术人员可容易的实现本发明。本文中应用了具体个例对本发明的原理及实施方式进行了阐述,以上实施例的说明只是用于帮助理解本发明的方法及其核心思想。应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以对本发明进行若干改进和修饰,这些改进和修饰也落入本发明权利要求的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!