文件处理方法及装置与流程
本发明实施例涉及数据处理技术领域,并且更具体地,涉及一种文件处理方法及装置。
背景技术:
当前,非经数据大部分是以压缩文件的形式上报的,在对这些非经数据进行使用或测试时,需要解压缩文件,并人工从解压缩的文件中选取需要的文件,这种方式在需要从数量巨大的解压缩文件中选取文件的情况下,不仅需要消耗大量的人力,并且效率极低。
技术实现要素:
本发明实施例提供一种文件处理方法及装置,其能自动解压缩文件,并从解压缩得到的文件中自动筛选出需要的文件,不仅有效提高了文件处理的效率,并且大大节省了人力成本。
第一方面,提供了一种文件处理方法,所述方法包括如下步骤:
获取压缩文件路径以及解压缩文件路径;
根据所述压缩文件路径获取待处理文件,判断是否解压缩过所述待处理文件,若没有解压缩过所述待处理文件,则判断所述待处理文件是否为预定类型的压缩文件,若所述待处理文件是所述预定类型的压缩文件,则解压缩所述待处理文件,得到若干个解压缩文件,并将所述若干个解压缩文件根据所述解压缩文件路径进行存储;
根据解压缩文件路径获取所有的所述解压缩文件,并从所有的所述解压缩文件中,筛选满足预定条件的所述解压缩文件,得到若干个目标文件;
将所述的所述目标文件存储在一个文件夹内。
结合第一方面,在第一种可能的实现方式中,所述并从所有的所述解压缩文件中,筛选满足预定条件的所述解压缩文件,得到若干个目标文件,包括如下步骤:
从所有的所述解压缩文件中,筛选文件名中包括第一预定字段的所述解压缩文件,得到若干个所述目标文件。
结合第一方面,在第二种可能的实现方式中,所述并从所有的所述解压缩文件中,筛选满足预定条件的所述解压缩文件,得到若干个目标文件,包括如下步骤:
从所有的所述解压缩文件中,筛选文件中包括第二预定字段的所述解压缩文件,得到若干个备选目标文件;其中,所述第二预定字段的数量为1个或多个;
从所有的所述备选目标文件中,筛选所述第二预定字段的值为预定值的所述备选目标文件,得到若干个所述目标文件。
结合第一方面,在第三种可能的实现方式中,所述并从所有的所述解压缩文件中,筛选满足预定条件的所述解压缩文件,得到若干个目标文件,包括如下步骤:
将所有的所述解压缩文件按照对应的文件生成时间从小到大进行排序;
并根据预定时间段将所述若干个解压缩文件分割成若干个分组;
从每个所述分组的第一个所述解压缩文件开始,判断当前所述解压缩文件是否满足所述预定条件;
如果满足预定条件,则当前所述解压缩文件为目标文件;如果不满足所述预定条件,则判断N值是否大于预定数值,若大于所述预定数值,则当前分组处理完毕,对下一个分组进行所述目标文件的筛选,否则,N值加1,并判断当前分组的下一个所述解压缩文件是否满足所述预定条件,并重复当前步骤;其中,N是初始值为0的正整数。
结合第一方面,在第四种可能的实现方式中,所述方法还包括以下步骤:
设置所述压缩文件路径以及解压缩文件路径。
结合第一方面,在第五种可能的实现方式中,所述方法在得到所述若干个目标文件之后,还包括如下步骤:
根据解压缩文件路径,删除所有的所述解压缩文件。
第二方面,提供了一种文件处理装置,所述装置包括:
路径获取模块,用于获取压缩文件路径以及解压缩文件路径;
文件解压模块,用于根据所述压缩文件路径获取待处理文件,判断是否解压缩过所述待处理文件,若没有解压缩过所述待处理文件,则判断所述待处理文件是否为预定类型的压缩文件,若所述待处理文件是所述预定类型的压缩文件,则解压缩所述待处理文件,得到若干个解压缩文件,并将所述若干个解压缩文件根据所述解压缩文件路径进行存储;
文件筛选模块,用于根据解压缩文件路径获取所有的所述解压缩文件,并从所有的所述解压缩文件中,筛选满足预定条件的所述解压缩文件,得到若干个目标文件;
文件存储模块,用于将所述的所述目标文件存储在一个文件夹内。
结合第二方面,在第一种可能的实现方式中,所述文件筛选模块还用于从所有的所述解压缩文件中,筛选文件名中包括第一预定字段的所述解压缩文件,得到若干个所述目标文件。
结合第二方面,在第二种可能的实现方式中,所述述文件筛选模块包括:
第一筛选子模块,用于从所有的所述解压缩文件中,筛选文件中包括第二预定字段的所述解压缩文件,得到若干个备选目标文件;其中,所述第二预定字段的数量为1个或多个;
第二筛选子模块,用于从所有的所述备选目标文件中,筛选所述第二预定字段的值为预定值的所述备选目标文件,得到若干个所述目标文件。
结合第二方面,在第三种可能的实现方式中,所述述文件筛选模块包括:
排序子模块,用于将所有的所述解压缩文件按照对应的文件生成时间从小到大进行排序;
分组子模块,用于并根据预定时间段将所述若干个解压缩文件分割成若干个分组;
第三筛选子模块,用于从每个所述分组的第一个所述解压缩文件开始,判断当前所述解压缩文件是否满足所述预定条件;如果满足预定条件,则当前所述解压缩文件为目标文件;如果不满足所述预定条件,则判断N值是否大于预定数值,若大于所述预定数值,则当前分组处理完毕,对下一个分组进行所述目标文件的筛选,否则,N值加1,并判断当前分组的下一个所述解压缩文件是否满足所述预定条件;其中,N是初始值为0的正整数。
在本发明实施例的上述技术方案中,首先根据压缩文件路径获取待处理文件,判断是否解压缩过待处理文件,若没有解压缩过待处理文件,则判断待处理文件是否为预定类型的压缩文件,若待处理文件是预定类型的压缩文件,则解压缩待处理文件,得到若干个解压缩文件;之后从所有的解压缩文件中,筛选满足预定条件的解压缩文件,得到若干个目标文件,并将所有目标文件存储在一个文件夹内,上述技术方案实现了自动解压缩文件,并从解压缩得到的文件中自动筛选出需要的文件,不仅有效提高了文件处理的效率,并且大大节省了人力成本。
附图说明
为了更清楚的说明本发明实施例的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单的介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1示意性的示出了根据本发明一实施例的文件处理方法的流程图。
图2示意性的示出了根据本发明再一实施例的文件处理方法的流程图。
图3示意性的示出了根据本发明又一实施例的文件处理方法的流程图。
图4示意性的示出了根据本发明又一实施例的文件处理方法的流程图。
图5示意性的示出了根据本发明一实施例的文件处理装置的框图。
图6示意性的示出了根据本发明再一实施例的文件处理装置的框图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明的一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
本实施例提供了一种文件处理方法,如图1所示,该方法包括如下步骤:
110、获取压缩文件路径以及解压缩文件路径;
此步骤中,压缩文件路径指的是压缩文件的存放地址,解压缩文件路径指的是解压后生成的文件的存放地址;
在此步骤执行之前,还可以包括设置压缩文件路径以及解压缩文件路径的步骤,具体地可以利用如下代码段设置压缩文件路径以及解压缩文件路径:
gfile='D:\\ftp\\yc\\'#指定压缩文件路径
sfile='D:\\ftp\\yc\\ycuzip\\'指定解压文件路径
120、根据压缩文件路径获取待处理文件,判断是否解压缩过待处理文件,若没有解压缩过待处理文件,则判断待处理文件是否为预定类型的压缩文件,若待处理文件是预定类型的压缩文件,则解压缩待处理文件,得到若干个解压缩文件,并将若干个解压缩文件根据解压缩文件路径进行存储;
此步骤中,#判断之前是否解压过此待处理文件,如果解压过则将原有文件删除,具体的利用如下代码段实现:
if os.path.isfile('D:\\ftp\\yc\\sbzl1.txt'):
os.remove('D:\\ftp\\yc\\sbzl1.txt')
此步骤中,预定类型可以根据实际应用场景的需求灵活设定,例如将预定类型设置为.Zip类型的文件,那么判断待处理文件是否为预定类型的压缩文件,若待处理文件是预定类型的压缩文件,则解压缩待处理文件,得到若干个解压缩文件,可以利用如下代码段实现:
130、根据解压缩文件路径获取所有的解压缩文件,并从所有的解压缩文件中,筛选满足预定条件的解压缩文件,得到若干个目标文件;
此步骤中,预定条件具体根据实际的应用场景需要灵活设定,例如可以选取包含特定字段的文件或选取特定时间段生成的文件;
140、将所有的目标文件存储在一个文件夹内。
本实施例的方法可以实现将文件批量进行解压缩,并将解压完的文件提取需要的同类型的文件数据放到一个文件中,通过此方法不仅能提高工作效率,而且能减轻相关工作人员的工作量。
在一个实施例中,步骤130中,从所有的解压缩文件中,筛选满足预定条件的解压缩文件,得到若干个目标文件,包括如下步骤:
从所有的解压缩文件中,筛选文件名中包括第一预定字段的解压缩文件,得到若干个目标文件;
此步骤中,第一预定字段根据实际应用场景的需要灵活设定,筛选文件名中包含第一预定字段的文件,表示需要的目标文件是内容或领域相关的文件。
具体地可以利用如下程序段实现本实施例的步骤:
应当说明的是,第一预定字段可以只包括一个字段,也可以包括多个不同的字段,本实施例对此不进行限定。这里的字段可以理解为关键字。
本实施例实现了利用关键字进行文件提取。
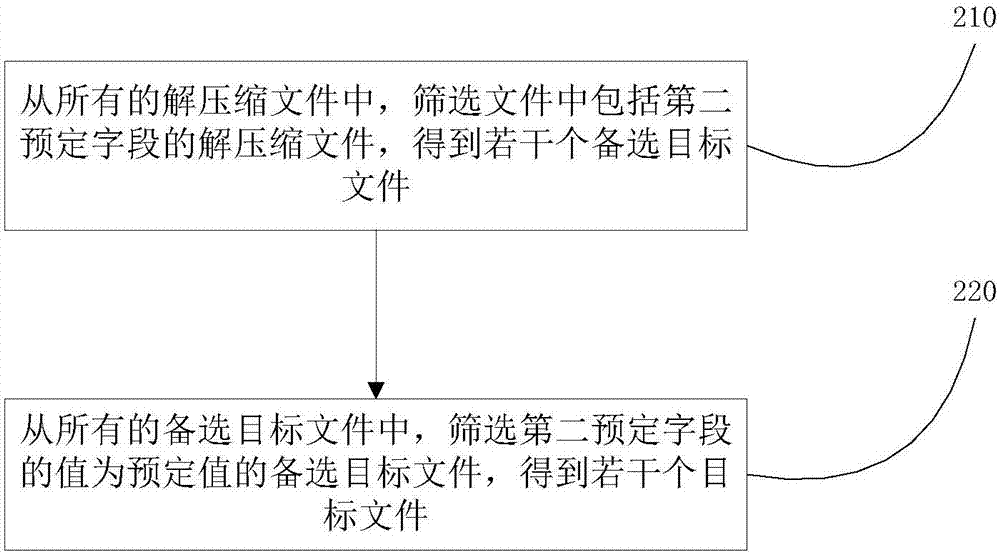
在一个实施例中,如图2所示,步骤130中,从所有的解压缩文件中,筛选满足预定条件的解压缩文件,得到若干个目标文件,包括如下步骤:
210、从所有的解压缩文件中,筛选文件中包括第二预定字段的解压缩文件,得到若干个备选目标文件;其中,第二预定字段的数量为1个或多个;
此步骤中,第二预定字段根据实际应用场景的需要灵活设定,筛选文件中包含第二预定字段的文件,表示需要的目标文件是内容或领域相关的文件。
应当说明的是,第二预定字段可以只包括一个字段,也可以包括多个不同的字段,本实施例对此不进行限定。
220、从所有的备选目标文件中,筛选第二预定字段的值为预定值的备选目标文件,得到若干个目标文件;
此步骤中,预定值根据实际应用场景的需要灵活设定。
本实施例实现了对包括特定内容的文件的提取。
当文件名中无法找到规律提取文件时,可以通过文件中的某个字段的唯一值(即上述预定值)进行数据提取写入到一个指定文件中:首先找到文件中唯一字段作为提取文件的关键字,其次将找到关键字的文件写入到一个指定文件中去,详细可以具体利用如下代码段实现:
在一个实施例中,步骤130中,从所有的解压缩文件中,筛选满足预定条件的解压缩文件,得到若干个目标文件,包括如下步骤:
310、将所有的解压缩文件按照对应的文件生成时间从小到大进行排序;
此步骤中,文件生成时间并非通过文件解压缩,得到解压缩文件的时间,而是文件本身的具体形成时间或租后修改时间;
320、并根据预定时间段将若干个解压缩文件分割成若干个分组;
此步骤中,预定时间段根据实际应用场景的需要灵活设定,本实施例对此并不进行限定;
330、从每个分组的第一个解压缩文件开始,判断当前解压缩文件是否满足预定条件;
此步骤中的预定条件与上述三个实施例的预定条件相同,对此并不再进行赘述;
340、如果满足预定条件,则当前解压缩文件为目标文件;如果不满足预定条件,则判断N值是否大于预定数值,若大于预定数值,则当前分组处理完毕,对下一个分组进行目标文件的筛选,否则,N值加1,并判断当前分组的下一个解压缩文件是否满足预定条件,并重复当前步骤;其中,N是初始值为0的正整数。
本实施例对每个预定时间段内的解压缩文件进行判断和筛选,如果前预定数值个解压缩文件不满足预定条件,则表明当前分组的解压缩文件的占比较小,不再对当前分组进行筛选。
在一个实施例中,文件处理方法在得到若干个目标文件之后,还包括如下步骤:
根据解压缩文件路径,删除所有的解压缩文件。
本实施例具体地可以利用如下代码段实现杉树步骤:
for a in afile:
os.remove(sfile+a)#数据提取完之后,把解压的所有文件删除
本实施例的上述方法可以自动解压文件,自动提取解压文件中同类型的指定数据写到一个文件中,并能将解压后处理完的数据进行删除。使用上述方法可以有效的减少操作人员的操作时间和花费的精力,并且完成一些人为无法完成的测试项,提高测试效率和完善测试功能。
下面通过一个实施例对本发明的文件处理方法进行详细说明。
如图3所示,本实施例的文件处理方法包括如下步骤:
步骤一、指定压缩文件路径;
步骤二、根据压缩文件路径上的压缩文件中,是否存在以.zip为后缀的文件,如果不存在,则本实施例的文件处理方法结束,如果存在,则执行步骤三;
步骤三、将压缩文件解压缩到指定文件夹下;
步骤四、在得到的解压缩文件中,查找是否存在指定的文件(即解压缩文件的文件名中是否存在第一预定字段);
步骤五、如果存在第一指定字段,则将对应的解压缩文件写到指定的文件中(即将对应的文件放入指定的文件夹中);
步骤六、删除所有的加压缩文件。
下面通过一个实施例对本发明的文件处理方法进行详细说明。
如图4所示,本实施例的文件处理方法包括如下步骤:
步骤一、指定压缩文件路径;
步骤二、根据压缩文件路径上的压缩文件中,是否存在以.zip为后缀的文件,如果不存在,则本实施例的文件处理方法结束,如果存在,则执行步骤三;
步骤三、将压缩文件解压缩到指定文件夹下;
步骤四、在得到的解压缩文件中,查找是否存在指定字段(即解压缩文件中是否存在第二指定字段,并且第二指定字段的取值是否为预定值);
步骤五、如果存在指定字段,则将对应的解压缩文件写到指定的文件中(即将对应的文件放入指定的文件夹中);
步骤六、删除所有的加压缩文件。
对应于上述文件处理方法,本发明还公开了一种文件处理装置,如图5所示,该装置包括:
路径获取模块,用于获取压缩文件路径以及解压缩文件路径;
文件解压模块,用于根据压缩文件路径获取待处理文件,判断是否解压缩过待处理文件,若没有解压缩过待处理文件,则判断待处理文件是否为预定类型的压缩文件,若待处理文件是预定类型的压缩文件,则解压缩待处理文件,得到若干个解压缩文件,并将若干个解压缩文件根据解压缩文件路径进行存储;
文件筛选模块,用于根据解压缩文件路径获取所有的解压缩文件,并从所有的解压缩文件中,筛选满足预定条件的解压缩文件,得到若干个目标文件;
文件存储模块,用于将所有的目标文件存储在一个文件夹内。
在一个实施例中,文件筛选模块还用于从所有的解压缩文件中,筛选文件名中包括第一预定字段的解压缩文件,得到若干个目标文件。
在一个实施例中,如图6所示,文件筛选模块包括:
第一筛选子模块,用于从所有的解压缩文件中,筛选文件中包括第二预定字段的解压缩文件,得到若干个备选目标文件;其中,第二预定字段的数量为1个或多个;
第二筛选子模块,用于从所有的备选目标文件中,筛选第二预定字段的值为预定值的备选目标文件,得到若干个目标文件。
在一个实施例中,文件筛选模块包括:
排序子模块,用于将所有的解压缩文件按照对应的文件生成时间从小到大进行排序;
分组子模块,用于并根据预定时间段将若干个解压缩文件分割成若干个分组;
第三筛选子模块,用于从每个分组的第一个解压缩文件开始,判断当前解压缩文件是否满足预定条件;如果满足预定条件,则当前解压缩文件为目标文件;如果不满足预定条件,则判断N值是否大于预定数值,若大于预定数值,则当前分组处理完毕,对下一个分组进行目标文件的筛选,否则,N值加1,并判断当前分组的下一个解压缩文件是否满足预定条件;其中,N是初始值为0的正整数。
应当说明的是,本发明实施例的方法的每个步骤与本发明实施例的对应装置的执行步骤是一一对应的,因此对于其中重复的部分,不再进行赘述。
综上,本发明实施例的文件处理方法以及装置可以实现自动解压文件并自动提取有效文件数据写到一个单独的文件中,并且可以将获取完文件数据后自动删除解压后的无效文件;因此能够在高效完成获取数据的时间,同时也能减轻工作量。
以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本领域的技术人员在本发明揭露的技术范围内,可轻易想到变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应所述以权利要求的保护范围为准。
- 还没有人留言评论。精彩留言会获得点赞!