一种城市管理信息舆情分析系统及方法与流程
本发明涉及舆情分析系统,更具体说,它涉及一种城市管理信息舆情分析系统及方法。
背景技术:
近年来,随着互联网的快速发展,我国的网络舆论信息流量一直呈加速上升的态势,并且信息获取和交流平台也在不断增多。互联网在促进信息交流和社会进步的同时,也给城市管理带来许多问题和挑战,主要表现为社会言论的不可控性,爆发式舆论带来的负面社会影响等等。每当有负面舆论爆发时,会带来不可估量的负面社会效应。
我国关于舆情思想和制度的建设有着悠久的历史,但是理论上真正对舆情的研究始于2003年,对网络舆情的研究始于2005年。因为舆情研究是一个新的社会科学与自然科学交叉的研究领域,在国内对此进行研究的人员和机构相对较少,研究深度也尚待加强。但近年来出现的一些有价值的研究成果,对理解和研究网络舆情很有启发意义。舆论无法完全避免,人为的舆论监控因其巨大的人力成本与反应时间慢等诸多限制,并不能在负面舆论爆发的第一时间进行舆论管控,采取有效的舆论信息分析及识别其情感特征,并对全网信息进行实时汇总和热度分析是城管舆情分析的重点研究内容。城管信息舆情的分析系统就是一种有效的非工程措施。
专利201610047697.7“一种互联网舆情分析方法”提出了一种互联网舆情分析方法,所述互联网舆情分析方法包括:首先针对选定获取事件,微博源文本进行划分,去除与情绪无关的划分项;然后采用统计分析工具进行统计,得到情绪分类模型的一个输入;最后针对输入用分类算法对微博内容中能表达情绪的相关词语、表情、符号进行建模,给出综合情感指数评价,得到情绪分类,并进行舆情监控及情绪走势分析。该发明对微博中词语、表情和符号等进行情绪建模,通过情绪指数计算,可对微博中热点事件的反应情势进行自动分类和有效监控。专利201410073473.4“舆情分析方法及系统”提出一种舆情分析方法,包括以下步骤:根据搜索请求搜索并读取网页文件;从网页文件中提取舆情信息;对舆情信息进行分类;对每个分类结果中的舆情信息进行进一步分析以得到每个分类结果中的舆情信息对应的起源、舆论情感色彩、网络扩散状态、发展趋势、地域信息和年龄段信息;根据对舆情信息的进一步分类结果以及预设的证据保全规则判断是否对舆情信息进行证据保全。这些方法和系统只实现了对特定网页或文本进行舆情分析和定性,不能实现对城市管理信息的智能化舆情分析。
技术实现要素:
本发明的目的是克服现有技术中对城市管理信息、情感分析和热词统计等功能的不足,提供一种城市管理信息舆情分析系统。
这种城市管理信息舆情分析系统,包括如下步骤:
步骤一、构建分词数据库:采用基于oracle的数据库对已有自然语言分词进行存储并为算法计算提供数据库支持;
步骤二、实现文本数据的采集:采用基于maven的项目管理系统,在前台进行文本数据的录入,用ajax将数据存储与json中的url进行与后台的交互,从而使服务器能获取需要分析的文本信息;
步骤三、中文分词及分词后感情预处理:通过庖丁解牛算法对已有文本信息进行基本分词处理,将分词存入分词数据库标上索引并且在分词过程中同时进行情感值的计算,依据既定的若干特征向量,这些特征向量主要分为正面情感修饰词和负面情感修饰词,再根据分词的情感分析来进行索引评论或帖子的感情值计算与分析;
步骤四、分词后过滤:一个帖子中会有许多无用的词汇,也称之为噪声词汇,过滤工作主要是通过特定的算法,通过既定的基词特征向量或基词库将其过滤,然后将过滤后的结果插入到热点词库;
步骤五、热点和情感分析:根据步骤四计算得出的热点词库及每个分词对应的情感向量对所有分析数据进行情感值计算和热度统计,得出每个句子对应的情感值以及分词的热度排序,并将分析结果进行可视化处理;
步骤六、将结果进行可视化处理并以excel格式保存并输出。
所述步骤一具体包含:基于oracle的数据库的表设计,主要包括舆情表、分词表、基词表、过滤后分词表,所述的舆情表包含的字段有对应信息的编号、内容、时间、来源、情感分析值、来源地址,所述的分词表包含的字段有分词编号、分词内容、分词对应的信息来源编号、词性、情感数据、来源信息内容,所述的基词表包含的字段有基词编号和基词内容,所述的过滤后分词表包含的字段有过滤后分词编号、过滤后分词内容、分词对应的信息来源编号、分词频数。
所述的步骤二具体包括:通过maven系统在前台输入帖子内容及编号,并通过json数据交换格式和url与服务器端进行交互,将文本内容传递给服务器并按照舆情表的数据格式进行保存。
所述的步骤三具体包含:
使用庖丁解牛算法进行分词:
将字符串传入庖丁解牛算法进行分词,分词后以引号括出分词,以空格隔开分词,将分词格式重写,然后去掉分词标记,只留下分词和空格,将此结果传递给主函数,主函数计算分词后的空格数来确定分词数量,去掉空格,将分词后的字符串正式转为以分词为单位的数组。
情感统计:
读取已建立的基词表和分词表,导入正面情感向量数组、负面情感向量数组、情感程度向量数组和否定情感向量数组,用for循环在逐个判断分词向量,将情感向量用boolean变量输出,正面情感为true,负面情感为false。
感情修饰统计:
感情程度的统计分析要根据感情程度向量而定,不同的感情程度相对于不同的数据,若中心词为负面词语,将二元情感置为-1.弱第一元为否定,则置为-1,与第二元相乘否定负面为正面,若中心词前有修饰词,则乘以相应权值以表示感情程度,先计算末二元的正面程度,再与否定向量相加,得出情感值结果。
通过三元组法进行情感统计分析,设置三元各部分和总数值起始值为0,记三元组分别为整形变量res1、res2、res3,记总数值为整形变量res,若中心词为负面词,则设置第二元变量res2为-1,若第一元为否定分为如下三种情况:
1)若第一元为否定,则设置res1为-1,令总数值等于res2乘以res1,否定的负面即为肯定;
2)若负面词前有修饰词,则res1赋值为相应权值,令res等于res1乘以res2,以说明负面程度,返回总数值res;
3)若只有第二元中心词,则总数值res等于中心词res2的数值,返回总数值res;
当中心词res2为正面情感时,统计方法与上述负面统计分析类似。
当中心词为否定词时,分为如下情况:
1)当只有中心词res2时,令总数值res等于res2,返回总数值res0;
2)当存在修饰词res3时,令总数值res等于res2乘以res3,返回总数值res0;
3)当存在修饰词时,令res1等于对应权值,令res等于res2乘以res3加res1,返回总数值res0;
当中心词为保守否定时,先计算末二元的正面程度,再与否定向量相加,得出最终结果。若修饰词为极端否定向量,则将否定向量与负面向量相乘,得出其否定程度。
所述的步骤四具体包含:
通过步骤三得出的分词表中提取出感情值为0的词语,然后根据基词库中的基本信息对比过滤掉一些噪声词语,即没有意义的词汇,剩下的词多为名次,主要包括地名、日期和人名等等,这些词才可以成为热点词汇,将过滤后的结果放入热点词库中。,统计的最小单位是舆情元,所谓舆情元就是将词汇、来源绑定在一起形成的一个单元插入热点过滤词库中,在统计时,如果词汇来源和词汇均与数据库中已有词汇相同的情况,则不计入统计,只在已有词汇的词频上将数值累加。
所述的步骤五具体包含:
舆情情感分析结果图表:
情感综合统计模块中设置了多角度的情感分析统计、柱状图的生成和表格的数据对比输出功能,根据前台选择将对应的赋值变量传入proxy,获取后台json并在前台显示,若选择按趋向向量分析则在下拉框上会显示出正负面感情向量,若选择按照来源分析,则会显示各种来源的站点信息。
舆情热点统计:
舆情热点统计和分析在步骤三和步骤四的基础上进行的,对过滤分词表中的词汇进行提取,与舆情表中的信息进行比对再进行进一步统计分析。
热点统计是基于词频,以舆情来源为统计分析元的单位,将中心词汇交给后台,提出中心词汇以外的热点词汇,形成一个不重复的存储数组,然后对提取的信息进行来源比对,来自同一条舆情信息源的中心词汇热点系数设置为1,热点系数乘以对应中心词的词频即该中心词的热点度;如果待分析词汇与中心词并不是来自同一舆情源,则将待分析词的站点信息与舆情信息库进行比对,如果不一致则被视为是站外信息与中心词的相关度为零,如果一致则视为是站内信息,使用url临近算法来进行其与中心词的相关系数的计算,最后将相关系数乘以其词频就是其热点度,并以词为单位输出分析结果。
所述的步骤六具体包含:
通过控制层excelbuild类与后台的excelutil类实现将数据以excel格式导出。
本发明的有益效果是:本发明提出了一种城市管理信息舆情分析系统,该系统利用分词算法和情感向量算法对舆情进行分析,挖掘出城市管理信息舆情的热点和情感方向,通过舆情对于城市管理建设的反作用力来进一步加强工作的针对性,从而提高城管工作的效率、获益率,加强城市管理建设。本发明提出了一种基于情感向量的舆情情感分析算法,能对舆情进行有效准确的情感预测,从而为舆情热点统计及舆情方向把控提供支持。系统采用orace数据库,能有效存储大量分词数据及基词数据并应对数据的快速增长,应用数据可视化技术发掘历史数据的内在价值,为舆情分析及管控工作提供信息指导。
附图说明
图1是本发明提出的城市管理信息舆情分析系统功能框架图;
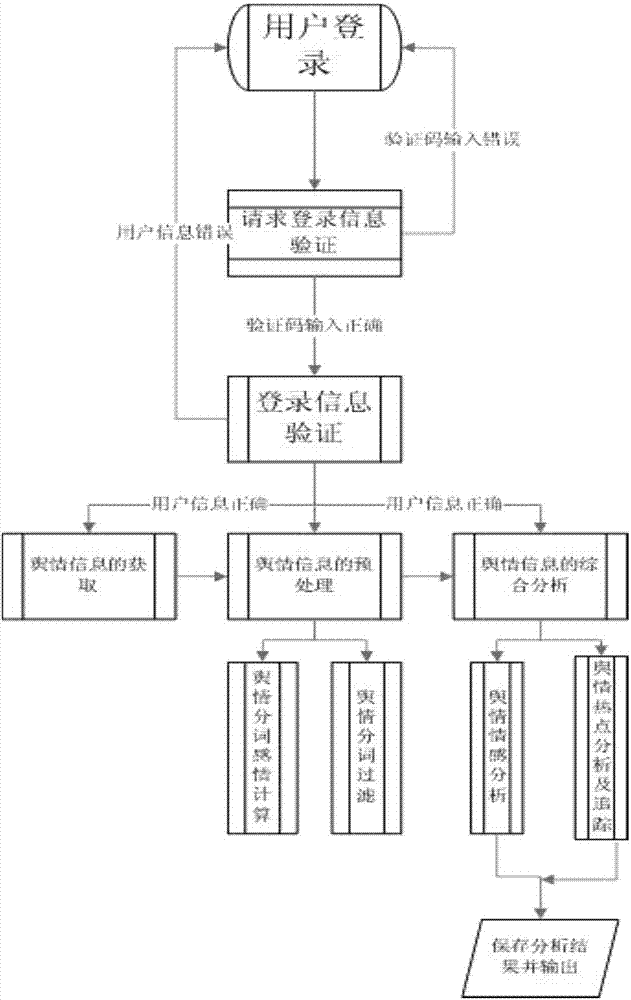
图2是本发明提出的城市管理信息舆情分析系统业务流程图;
图3是本发明描述的舆情表结构图;
图4是本发明描述的分词表结构图;
图5是本发明描述的基词表结构图;
图6是本发明描述的过滤后词汇表结构图;
图7是本发明实现的添加操作界面图;
图8是本发明实现的舆情情感统计分析结果图;
图9是本发明实现的词汇过滤和热点词频统计结果图;
图10是本发明实现的舆情情感分析结果柱状图;
图11是本发明实现的舆情情感分析结果表格图;
图12是本发明实现的舆情信息热点综合分析柱状图;
图13是本发明的舆情信息分析结果导出的excel数据图。
具体实施方式
下面结合实施例对本发明做进一步描述。下述实施例的说明只是用于帮助理解本发明。应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以对本发明进行若干改进和修饰,这些改进和修饰也落入本发明权利要求的保护范围内。
该系统的总体结构如图1所示,业务流程如图2所示,具体实现步骤如下:
步骤一、构建分词数据库
通过对文本信息分词数据的研究可以发现,文本信息的分词主要包括情感分词、信息分词和噪声分词,根据系统结构建立如图3所示结构的舆情信息表用以存储源文本信息,建立如图4所示结构的分词表用以存储分词信息,建立如图5所示结构的基词表,建立如图6所示结构的过滤后分词表。
步骤二、实现文本数据的采集
系统采用了基于maven的项目管理插件,在前台进行如图7所示的添加操作后,通过ajax将数据存储与json中已设置的url与后台进行交互,将添加数据按照舆情信息表的结构存入服务器,再通过后台的json数据格式抛给前台并显示最新结果。
步骤三、中文分词及感情预处理
数据导入完成后,将文本信息传入庖丁解牛算法进行分词,分词后以引号括出分词,以空格隔开分词,将分词格式重写,然后去掉分词标记,只留下分词和空格,将此结果传递给主函数,主函数计算分词后的空格数来确定分词数量,去掉空格,将分词后的字符串正式转为以分词为单位的数组并按照分词表结构在服务器中进行存储。
读取已建立的基词表和分词表,导入正面情感向量数组、负面情感向量数组、情感程度向量数组和否定情感向量数组,用for循环在逐个判断分词表所述的情感向量数组,将情感向量用boolean变量输出,正面情感为true,负面情感为false。
感情程度的统计分析根据感情程度向量而定,不同的感情程度相对于不同的数据,若中心词为负面词语,将二元情感置为-1.弱第一元为否定,则置为-1,与第二元相乘否定负面为正面,若中心词前有修饰词,则乘以相应权值以表示感情程度,计算末二元的正面程度,再与否定向量相加,得出情感值结果。
进行分词和情感预处理的分词信息如图8所示。
步骤四、分词后过滤
依据步骤三得出的分词表中提取出感情值为0的词语,然后根据基词库中的基本信息对比过滤掉噪声词语,剩下的词主要包括地名、日期和人名等,将过滤后的结果放入热点词库中。在统计词频时,如果待统计词汇的来源和词汇均与数据库中已有词汇相同,则不计入统计,只在已有词汇的词频上将数值累加,然后将过滤后的结果插入到热点词库。
分词后过滤结果如图9所示。
步骤五、热点和情感分析
(一)舆情热点统计
舆情热点统计和分析在步骤三和步骤四的基础上进行的,对过滤分词表中的词汇进行提取,与舆情表中的信息进行比对再进行进一步统计分析。
将中心词汇交给后台,提出中心词汇以外的热点词汇,形成一个不重复的存储数组,然后对提取的信息进行来源比对,来自同一条舆情信息源的中心词汇热点系数设置为1,热点系数乘以对应中心词的词频即该中心词的热点度;如果待分析词汇与中心词并不是来自同一舆情源,则将待分析词的站点信息与舆情信息库进行比对,如果不一致则视为是站外信息,与中心词的相关度为零,如果一致则视为是站内信息,使用url临近算法来进行其与中心词的相关系数的计算,最后将相关系数乘以其词频就是其热点度,并以词为单位输出分析结果。
(二)舆情情感分析结果图表
根据步骤四计算得出的热点词库及每个分词对应的情感向量对所有分析数据进行情感值计算和热度统计,得出每个句子对应的情感值以及分词的热度排序,并将分析结果进行可视化处理。
情感综合统计模块中设置了多角度的情感分析统计、柱状图的生成和表格的数据对比输出功能,根据前台选择将对应的赋值变量传入proxy,获取后台json并在前台显示,若选择按趋向向量分析则在下拉框上会显示出正负面感情向量,若选择按照来源分析,则会显示各种来源的站点信息。
舆情情感分析柱状图如图10所示。
舆情情感分析表格如图11所示。
舆情热点分析柱状图如图12所示。
步骤六、将结果进行可视化处理并以excel格式保存并输出
通过控制层excelbuild类与后台的excelutil类实现将数据以excel格式导出。
定义存储路径,通过输出字符流取出文件内容,调用底层util的写入方法,将封装好的外部信息、数据信息、表头信息作为三大参数传入util类中,接build类文件传入的关于表头三个参数:文件外部信息、所在行、表头信息,在输出函数中逐行写入数据,最终以excel格式导出所写数据。
导出后的excel内容如图13所示。
- 还没有人留言评论。精彩留言会获得点赞!