一种应用程序的排名欺诈检测方法与流程
本发明涉及排名欺诈检测技术领域,特别涉及一种应用程序的排名欺诈检测方法。
背景技术:
随着智能手机的普及,诸如苹果的appstore,谷歌的googleplay这类的移动应用市场通过为用户提供种类丰富的手机应用随之流行开来。在这些移动应用市场中,均提供了反映应用热门程度排行榜功能。应用排行榜不仅能够反映应用商店中各应用的受用户欢迎程度,同时还能够为排名较为靠前的应用带来更多的用户流量。因此,有许多别有用心的应用开发者还向排名欺诈服务提供机构购买排名欺诈服务,以此提高自家应用在应用商店排行榜中的排名。这些排名欺诈服务提供机构能够在段时间内调动大量的用户,通过为目标应用制造巨大下载量、大量好评等手段,来使目标应用的排名在段时间内得到明显提升,有的甚至能冲进榜首。
这些排名欺诈服务提供机构的大肆活跃,将会严重影响应用商店中正常应用间的公平竞争。因此,如何能够有效检测到应用商店中的排名欺诈行为,并及时采取有效措施,成了当前排名欺诈检测技术领域中的棘手问题。
技术实现要素:
本发明的目的在于针对现有的排名欺诈检测技术不足而提供的一种应用程序的排名欺诈检测方法,该方法首次将人工智能技术应用到排名欺诈检测技术领域中,可行性好,比起以往使用人工方法和启发式规则进行排名欺诈检测,在效率上有了极大的提升。能够为应用商店运营者提供有力工具,对维护应用商店正常秩序起到重要作用。
实现本发明目的的具体技术方案是:
一种应用程序的排名欺诈检测方法,该方法包括以下具体步骤:
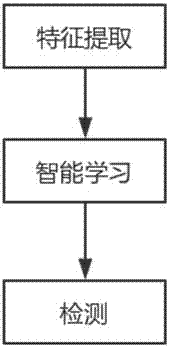
特征提取阶段:从应用程序元数据和生成数据中提取特征数据;
深度学习阶段:使用深度学习模型对由特征数据和监督值组成的样本集进行训练;
检测阶段:输入待测应用的特征数据,判别是否存在排名欺诈。
所述应用程序元数据为自应用程序发布便不再变更的数据,包括但不限于如下2个:应用所属分类、应用售价。
所述应用程序生成数据为,在应用商店中,与应用程序相关并有可能发生变更的数据,包括但不限于如下17个:每日总榜排名序列、每日分类榜排名序列、用户评分序列、每日下载量序列、是否入选精品推荐、评论熵、平均评分、各种数值的评分占比、总下载量、评论用户数、各种数值的删除评分占比、曾有历史评论被删除的用户占比、高分评论者、评论者平均评论数、下载量与评论者数的相关性系数、下载量与积极评论者数的相关性系数、下载量与消极评论者数的相关性系数。
所使用的深度学习模型具有如下特征:
(1)采用多层反馈神经网络和多层感知器模型相结合的方式构造整体模型;
(2)采用多层反馈神经网络处理长度不固定的数值序列,抽象出特征向量后再和其它数值类型的特征组成长度固定的总体特征向量;
(3)采用多层感知器模型进行处理分类。
所述多层感知器模型采用了快速终止的方法,即在每一个迭代结束时计算验证数据的准确度,当上述准确度不再提高时,就停止训练,避免过度拟合。
所述多层感知器模型采用了10折交叉验证作为命中率测试的方法,即每次将验证数据分为十份,轮流使用其中九份作为训练数据,剩下一份作为验证数据,十次验证数据结果的均值作为命中率测试的最终结果。
本发明能够得到在应用商店中的排名欺诈应用集合,为应用商店的管理提供可靠保障。在训练样本足够多的情况下,该方法能够以较高的准确度对应用商店中排名欺诈应用进行检测。随着应用排名欺诈手段的不断更新,排名欺诈服务提供机构往往会采取新的技术手段,在新的案例中,以新的训练样本作为输入,该方法能够适应新形式下的排名欺诈技术手段的挑战。
附图说明
图1为本发明流程图。
具体实施方式
下面结合附图及具体实施例对本发明做进一步说明,但本发明的实施方式不限于此。
本发明包括以下具体步骤:
实施例1
首先,进入特征提取阶段,需要从应用程序元数据和生成数据中提取特征数据。
元数据为自应用程序发布便不再变更的数据,包括不限于如下2个:应用所属分类、应用售价。应用所述分类使用one-hot编码。应用售价为具体数字价格,若应用免费则价格为零。
应用程序生成数据为,在应用商店中,与应用程序相关并有可能发生变更的数据,包括但不限于如下17个:每日总榜排名序列、每日分类榜排名序列、用户评分序列、每日下载量序列、是否入选精品推荐、评论熵、平均评分、各种数值的评分占比、总下载量、评论用户数、各种数值的删除评分占比、曾有历史评论被删除的用户占比、高分评论者、评论者平均评论数、下载量与评论者数的相关性系数、下载量与积极评论者数的相关性系数、下载量与消极评论者数的相关性系数。
每日总榜排名序列以及每日分类榜排名序列为待检测时间周期内应用每天的排名数值。用户评分序列为待检测时间周期内应用所收到的所有用户评分按照时间先后顺序排成的序列。每日下载量序列为待检测时间周期内应用的每日下载量构成的序列。
是否入选精品推荐的值取0或1。
评论熵如下计算:
e=∑plogp
其中,p为待检测应用某日收到的评论数占总评论数的比重。
各种数值的删除评分占比为:被删除的1星评论数、被删除的2星评论数、被删除的3星评论数、被删除的4星评论数、被删除的5星评论数。
高分评论者为:历史评论大于等于4星的用户。
评论者平均评论数为:每个评论者历史平均评论次数的平均数。
下载量与评论者数的相关性系数、下载量与积极评论者数的相关性系数、下载量与消极评论者数的相关性系数均使用pearson相关性系数计算方法。
其次,深度学习阶段将使用深度学习模型对由特征数据和监督值组成的样本集进行训练。
训练时采用多层反馈神经网络和多层感知器模型相结合的方式构造整体模型;训练时采用多层反馈神经网络处理长度不固定的数值序列,抽象出特征向量后再和其它数值类型的特征组成长度固定的总体特征向量;训练时采用多层感知器模型进行处理分类。
在每一个迭代结束时计算验证数据的准确度,当模型在训练集上的述准确度不再提高时,就停止训练,避免过度拟合。
采用了10折交叉验证作为命中率测试的方法,每次将验证数据分为十份,轮流使用其中九份作为训练数据,剩下一份作为验证数据,十次验证数据结果的均值作为命中率测试的最终结果。
最后,进行检测,即输入待测应用的特征数据到前一阶段训练完成的模型中,判别是否存在排名欺诈。
尽管上面对本发明说明性的具体实施方式进行了描述,以便于本技术领域的技术人员理解本发明,但应该清楚,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所有获得的所有其他实施例,都属于本发明的保护范畴。
技术特征:
技术总结
本发明公开了一种应用程序的排名欺诈检测方法,该方法包括:特征提取阶段,深度学习阶段与检测阶段。特征提取阶段以应用程序元数据和生成数据作为输入,输出特征数据。深度学习阶段使用人工神经网络作为学习模型,对特征数据和监督值组成的样本集进行训练,得到已训练的学习模型。检测阶段以特征数据作为输入,通过已训练的学习模型,输出应用程序的检测结果。本发明能够得到在应用商店中的排名欺诈应用集合,为应用商店的管理提供可靠保障。
技术研发人员:何道敬;洪凯;唐宗力
受保护的技术使用者:华东师范大学
技术研发日:2018.04.19
技术公布日:2018.11.06
- 还没有人留言评论。精彩留言会获得点赞!