集成电路制造方法与流程
本公开涉及一种集成电路制造方法,特别是经由机器学习演算法验证光学邻近校正后(postopc)转印的集成电路制造方法。
背景技术:
半导体装置被使用在各种电子应用(例如个人电脑、手机、数码相机以及其他电子设备)中。集成电路(ic)经由包括设计步骤以及后续制造步骤的一个流程来制造。在设计步骤中,集成电路的布局被生成为电子文件。此布局包括对应于将要在晶片上制造的结构的几何形状。在制造步骤中,此布局被形成在半导体工作部件上。举例来说,经由顺序地沉积绝缘或介电层、导电层以及半导体层的材料在半导体基板上,并且使用光刻工艺来图案化各种材料层以在半导体基板上形成电路部件以及元件。
随着半导体工业已进入纳米技术工艺节点(例如5纳米)以追求更高的装置密度、更高的效能以及更低的成本。不断缩小的几何尺寸给集成电路制造带来挑战。因此,需要对各种半导体工艺步骤改善效率及减少成本,例如用于光学邻近校正(opc)之后的转印验证(printingverification)。
技术实现要素:
本公开提供了一种集成电路制造方法。此方法包括接收一集成电路设计布局。此方法包括对集成电路设计布局执行一光学邻近校正(opc)程序,以产生一校正后的集成电路设计布局。此方法还包括使用一机器学习演算法验证校正后的集成电路设计布局。
本公开提供了一种集成电路制造系统。此系统包括一掩模制造模块,被配置以接收一集成电路设计布局。此掩模制造模块包括一数据准备模块,被配置以对集成电路设计布局执行一光学邻近校正(opc)程序以产生一校正后的集成电路设计布局,并且使用一机器学习演算法验证校正后的集成电路设计布局。此掩模制造模块包括一掩模加工(masktooling)模块,被配置以转印校正后的集成电路设计布局。此系统包括一集成电路制造模块,被配置以使用一掩模制造一集成电路。
本公开提供了一种储存有多个电脑可执行代码的一种电脑可读媒体。电脑可执行代码包括一第一代码,用于接收一集成电路设计布局。电脑可执行代码包括一第二代码,用于对上述集成电路设计布局执行一光学邻近校正(opc)程序,以产生一校正后的集成电路设计布局。电脑可执行代码包括一第三代码,用于使用一机器学习演算法验证校正后的集成电路设计布局。
附图说明
本公开的观点从后续实施例以及附图可以更佳地理解。应知道各示意图所示为范例,并且所示出的不同特征并不应限定本公开的范围。另外,所示出的不同特征的尺寸可能任意增加或减少以清楚论述。
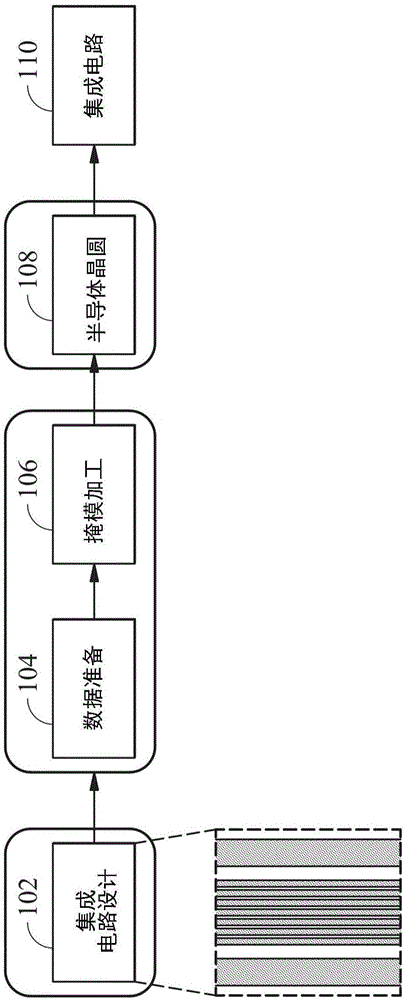
图1为根据本公开实施例的集成电路(ic)制造流程的示意图。
图2为根据本公开实施例的用于集成电路制造的集成电路设计以及掩模制造的示意图。
图3为根据本公开实施例的使用机器学习的光学邻近校正后验证的操作流程图。
图4为根据本公开实施例的用于集成电路制造的集成电路设计以及掩模制造(使用了机器学习的光学邻近校正后验证)的系统的示意图。
图4a为根据本公开实施例的用于机器学习模型训练及验证的数据源使用的是意图。
图5为根据本公开实施例的用于光学邻近校正后验证的数据训练、特征提取以及数据库产生机器学习技术的示意图。
附图标记说明:
100~集成电路制造流程
102~集成电路设计
104~数据准备
106~掩模加工
108~半导体晶圆
110~集成电路
202~光学邻近校正
204~光学邻近校正后验证
300~操作
301-312~步骤
400~系统
402~集成电路设计模块
404~掩模制造模块
406~数据准备模块
408~光学邻近校正模块
410~光学邻近校正后验证模块
412~特征识别模块
414~数据库比较模块
416~评估模块
418~存储器
420~数据库
422~数据训练模块
424~图案产生模块
426~训练模拟模块
428~掩模加工模块
430~集成电路制造模块
418a~数据源
430a~训练数据
432~目标数据
434~验证数据
436~目标数据
438~机器学习模型
440~测试预测
502~gds池
504~特征
具体实施方式
以下的公开内容提供许多不同的实施例或范例以实施本案的不同特征。以下的公开内容叙述各个构件及其排列方式的特定范例,以简化说明。当然,这些特定的范例并非用以限定。举例来说,若是本公开书叙述了一第一特征形成于一第二特征之上或上方,即表示其可能包含上述第一特征与上述第二特征是直接接触的实施例,亦可能包含了有附加特征形成于上述第一特征与上述第二特征之间,而使上述第一特征与第二特征可能未直接接触的实施例。另外,以下所公开的不同范例可能重复使用相同的参考符号及/或标记。这些重复为了简化与清晰的目的,并非用以限定所讨论的不同实施例及/或结构之间有特定的关系。
此外,其与空间相关用词。例如“在……下方”、“下方”、“较低的”、“上方”、“较高的”及类似的用词,为了便于描述图示中一个元件或特征与另一个(些)元件或特征之间的关系。除了在图中示出的方位外,这些空间相关用词意欲包含使用中或操作中的装置的不同方位。除此之外,设备可能被转向不同方位(旋转90度或其他方位),则在此使用的空间相关词也可依此相同解释。
在半导体工业中,集成电路(ic)设计使用多种工艺(例如蚀刻、沉积、注入、退火、研磨以及光刻)形成于晶圆上。光刻工艺将图案从掩模转移到晶圆,使得蚀刻、注入或其他步骤仅被施加在晶圆的预定区域。掩模包括集成电路图案并且被使用(有时重复使用)在晶圆工艺。掩模可以使用各种光刻写入(lithographywriting)技术被图案化。一个例子是电子束(e-beam)写入。
集成电路的制造使用光刻模拟以预测在晶圆上产生的掩模的图像。这样的预测可以用于诸如评估图像的品质、验证这些图像的可制造性、使用光学邻近校正执行掩模图案的校正以达到图像接近目标的图案、优化转印参数(例如照明源)或全局优化(globallyoptimize)此照明源与掩模以达到更好的转印能力。掩模设计的评估可以包括识别“热点(hotspot)”,其为在下线(tape-out)时具有缺陷的掩模区域。集成电路布局轮廓基于集成电路设计布局以及其他设计数据(例如栅极与主动区)所产生。集成电路布局轮廓的产生是模拟集成电路装置基于其设计布局以产生其物理尺寸及几何形状的程序。此模拟可以考虑与要制造集成电路装置的集成电路制造厂相关的制造数据,例如用于将定义在掩模的集成电路设计布局转移到晶圆上的集成电路特征的光刻工艺数据(例如:聚焦及/或能量(或曝光)剂量的统计数据)及/或蚀刻数据(例如:蚀刻剂特性)。此模拟将产生对应于集成电路设计布局的虚拟制造特征。在一实施例中,模拟可以经由合适的模拟工具被执行,例如以集成电路为重点的模拟程序(simulationprogramwithintegratedcircuitemphasis;spice)。spice是一种提供完整物理模拟的工具,包括输出信号变形、信号电平(signallevel)以及时间延迟。spice是ucberkeley开发的电路分析程序。模拟结果可以包括各种电性参数,例如饱和电流。在另一实施例中,模拟结果包括其他电性效能,例如短通道效应以及相关的效能偏差。各种验证以及检查可被执行以识别可能导致集成电路装置有品质问题及/或可靠度问题的热点。在一实施例中,各种准则可被定义以检查所模拟的电性参数,并且根据预定准则从模拟结果寻找是否有任何区域超出容许范围(例如:称为工艺窗口(processwindow))
形成用于具有较小特征尺寸的集成电路的掩模更有挑战性。邻近效应(proximityeffect)是与掩模图像相关的光学畸变的一种形式。对于给定的显影时间,在显影工艺后,光刻胶层的给定区域是否将残留或被移除取决于在暴露辐射期间沉积在该区域中的能量总量。图像特征的尺寸及/或分离逼近于所述辐射的解析度极限,此等图像特征将因此容易受到畸变,畸变取决于位于“锐利”边缘的两侧的绕射极大值及最小值如何相互作用。邻近效应可以至少部分地经由在与预期畸变相反的方向上修改任何给定特征以得到补偿。
光学邻近校正(opc)是用于调整(例如:校正或优化)掩模布局设计以改善成像效应的一种光刻技术。光学邻近校正程序的目的是尽可能地在硅晶圆上重现设计者所绘制的原始布局。举例来说,光学邻近校正可以用于补偿由绕射或工艺影响所导致的图像错误。光学邻近校正有助于在经过工艺后成为在晶圆上的蚀刻图像时,保持原始掩模布局设计的边缘布局的完整性。举例来说,在经过工艺处理后,在晶圆上被蚀刻的图像可能出现不规则性,例如比设计较窄或较宽的线宽。光学邻近校正可以经由改变(例如:校正)掩模布局设计的图案以补偿这种不规则性。对掩模布局设计的这些改变可以称为辅助特征(assistfeatures,afs)
其他畸变,例如圆角(roundedcorners),是经由光学成像机台所导致,并且难以补偿。如果不加以校正,这种畸变可能会显著改变正在制造的集成电路的电性特性。光学邻近校正可以经由移动边缘或加入额外多边形至掩模布局设计以校正这些错误。这可以经由基于特征之间的宽度与间隔所预先计算的查找表或者经由使用紧凑模型(compactmodel)以动态地模拟最终图案来驱动,并因此驱动边缘(通常会被分段)的移动以找到最佳解(例如:称为基于模型的光学邻近校正)。
在执行光学邻近校正以对掩模布局设计图案进行调整之后,修改后的图案可能更不规则。光学邻近校正后(postopc)验证可以被执行以识别校正后的掩模布局设计的突出区域(highlightareas)(突出区域可能无法正确地转印在晶圆上)。
本公开的实施例提供了使用机器学习方法进行光学邻近校正后验证(postopcverification)的技术。本文提供的光学邻近校正验证可以用于验证(例如:评估或预测)可以转印的掩模布局设计(包括在光学邻近校正程序中加入的辅助特征)。光学邻近校正验证以及光学邻近校正后验证可用于掩模的加工,其中此掩模将用于半导体装置的集成电路制造。
根据后续更详细描述的本公开实施例,机器学习技术(例如:基于图像的机器学习)可用于数据训练以及掩模布局设计的数据库产生,其具有各种加入的辅助特征、相关的转印输出(print-out)风险以及突出点(highlightpoints)。机器学习技术可以使用在光学邻近校正后验证中以识别在光学邻近校正后的掩模布局设计中的特征,使这些特征与在数据库中的掩模布局设计匹配,并且基于在数据库中相关的转印输出风险与突出点来验证光学邻近校正后的掩模布局设计。
图1是根据本公开一些实施例的集成电路(ic)制造流程的示意图。集成电路制造流程100是一个使用光学邻近校正后验证的集成电路制造流程的示例,其中使用光学邻近校正后验证使用机器学习方法(例如:基于图像的机器学习)。
集成电路制造流程100的电路制造可以从集成电路设计102开始以创建掩模布局设计。根据一个实施例,集成电路设计102可以由集成电路设计厂执行。在另一实施例中,根据集成电路设计102,设计者是与被指定制造集成电路产品的集成电路制造厂分离的设计团队。在多个实施例中,集成电路制造厂能够制造掩模、半导体晶圆或两者。集成电路设计102包括为集成电路产品所设计并且基于集成电路产品规范的各种几何图案。集成电路设计102可以基于设计规范并且可以包括逻辑设计、图表设计(schematicdesign)以及物理设计。举例而言,集成电路设计布局的一部份包括各种集成电路特征(亦称为主要特征),例如主动区、栅极、源极与漏极、内部层间的相互连线的金属线或介层窗(via)以及用于作焊盘(bondingpad)的开孔,这些特征将被形成在半导体基板(例如硅晶圆)以及设置在半导体基板上的多个材料层中。集成电路设计布局可包括某些辅助特征(af),例如那些用于成像效应、处理提升及/或掩模识别信息的特征。在图1中显示的集成电路设计102仅是具有几何图案的掩模布局设计的一个说明范例。
集成电路设计102对集成电路产生掩模布局设计,掩模布局设计被提供至掩模制造实体(entity),例如掩模厂。集成电路设计布局可以呈现在具有几何图案信息的一或多个数据文件中。在一实施例中,集成电路设计布局以图形设计系统“gds”(graphicsdesignsystemdata)的格式表示。掩模制造实体可以根据来自集成电路设计厂所接收到的掩模布局设计执行数据准备104以及掩模加工(masktooling)106。掩模加工106基于来自数据准备104的调整后的掩模布局设计结果来制造掩模(有时称为倍缩掩模)或一组掩模。数据准备104准备调整后的掩模布局设计,并且提供该图案到掩模加工106。如图2所示,数据准备104包括执行光学邻近校正202以及光学邻近校正后验证204。根据本公开的实施例,光学邻近校正后验证使用机器学习(例如:基于图像的机器学习)方法以在掩模加工106之前验证校正后的掩模布局设计。
掩模加工106使用光刻技术来制造掩模,例如电子束光刻。掩模加工106可以根据各种技术形成掩模。在另一实施例中,掩模使用二元技术(binarytechnology)来形成。在此情况下,掩模图案包括不透明区及透明区。在一实施例中,二元掩模包括一透明基板(例如:熔融石英)以及涂布在掩模的不透明区域的不透明材料(例如:铬)。在另一实施例中,掩模使用相位移技术形成。在相位移掩模(psm)中,在掩模上所形成的图案的多个特征被配置以具有合适的相位差以提升解析度及成像品质。在多个实施例中,相位移掩模在公知常识中可以是衰减相位移掩模(attenuatedpsm)、交替相位移掩模(alternatingpsm)或无铬(chrome-less)相位移掩模,或者是将来所发展的其他相位移掩模。
掩模(或一组掩模)可以用于集成电路制造实体(例如:有时称为“fab”的集成电路制造厂)以制造半导体晶圆108。半导体晶圆108可包括硅基板或其他合适基板,基板可以是半导体(例如:锗)、复合半导体(例如:碳化硅、砷化铟或磷化铟)或合金半导体(例如:硅锗碳、磷砷化镓或磷化铟镓)。半导体晶圆108可进一步包括多个掺杂区、介电特征及多层内部连线。
集成电路制造实体包括多个工艺机台以对半导体晶圆108应用各种工艺来制造集成电路110。这些工艺可包括在半导体晶圆108上执行沉积、蚀刻、研磨、清洗、退火以及光刻。集成电路制造实体使用光刻以在用来制造集成电路110的半导体晶圆108上形成集成电路图案,其中光刻使用了根据本文所述的使用机器学习技术来验证校正后的掩模布局设计所创建的掩模。此集成电路图案从掩模被转移到感光材料层(例如光刻胶)。
示例的光刻工艺可包括光刻胶旋转涂布、软烘烤、掩模对准、曝光、曝光后烘烤、显影光刻胶以及硬烘烤的工艺步骤。光刻设备通常包括提供辐射能的辐射源、投影用于光刻图案化的辐射能的透镜系统以及具有扫描功能的掩模基座(maskstage)。辐射能可以是适合光源,例如紫外光(uv)、深紫外光(duv)或极紫外光(euv)源。举例来说,辐射源可包括氟化氪(krf)准分子激光、氟化氩(arf)准分子激光、氟(f2)准分子激光、汞灯或其他光源,但不限于此。透镜系统可包括一或多个照明模块,照明模块被设计以将来自辐射源的辐射束引导到掩模上。掩模基座可以操作以固定掩模并且在平移及/或旋转模式中操作掩模。光刻设备可包括基板基座,基板基座用于第一光刻工艺期间在平移及/或旋转模式中保持及操作欲图案化的基板。对准装置可以被使用以对准掩模与基板。
在另一实施例中,掩模被用以在离子注入工艺之前在半导体晶圆108上形成图案,以在半导体晶圆108中形成多个掺杂区域。在另一实施例中,掩模被用以在蚀刻工艺之前在半导体晶圆108上形成图案,以在半导体晶圆108中形成多个蚀刻区域。在另一实施例中,掩模被用以在沉积工艺(例如化学气相沉积(cvd)或物理气相沉积(pvd))之前在半导体晶圆108上形成图案,以在半导体晶圆108上的多个区域中形成薄膜。
图2是根据一些实施例的用于集成电路制造的集成电路设计方法以及掩模制造方法的示意图。如图2所示,数据准备104包括光学邻近校正202以及光学邻近校正后验证204。如图2所示,数据准备104接收掩模布局(例如:从集成电路设计厂),掩模布局可以是用于集成电路或半导体装置的设计图案。
虽然在图2中没有显示,数据准备104可包括对集成电路设计布局执行逻辑操作(或lop)。举例来说,逻辑操作可以根据制造规则修改集成电路设计布局。
虽然在图2中没有显示,数据准备104可包括对集成电路设计布局执行重新定向处理(retargetingprocess)。在此步骤中,可以修改集成电路设计布局以在基于规则的方法中改善成像效应,使得修改后的集成电路设计布局在晶圆上具有改善的图像。在此步骤中对集成电路设计布局的修改可包括重新调整主要特征的尺寸、重新定位主要特征的边缘、对主要特征重新塑形、对主要特征加入辅助特征、对主要特征加入散射条(scatteringbar)或前述的组合。在一实施例中,各种辅助特征包括衬线(serif)特征或冗余插入(dummyinsertion)特征。如上面所述,在集成电路中的功能元件被称为主要特征。在另一实施例中,散射条与主要特征间是间隔开的。在某一个实施例中,散射条是次解析度特征,其尺寸低于光刻工艺的解析度。因此,这些次解析度特征无法在半导体基板上成像。然而,冗余插入特征的尺寸被设定可成像到半导体基板上。举例来说,冗余插入特征包括远离主要特征设置的冗余隔离(dummyisolation)特征及/或导电特征,以在热工艺期间提供均匀的热效应。在另一实施例中,冗余插入特征可被加入到集成电路设计布局以提升化学机械研磨(cmp)或其他工艺优点。这些特征被称为解析度特征。此外,重新定向处理后的集成电路布局的光刻成像得到改善,解析度及准确度有所提升。重新定向处理不只用于结合各种特征,而且还修改在光刻工艺期间主要特征的光学效能。另外,其他特征可被加入或其他动作可被应用以调整集成电路设计布局。
数据准备104进行到光学邻近校正202的程序。光学邻近校正202以接收集成电路设计布局(例如:如图2所示的掩模布局(gds.in))为输入并且以提供经由光学邻近校正的程序调整后的另一个集成电路设计布局(例如:如图2所示的校正后的掩模布局(gds.out))为输出。光学邻近校正202可以使用基于模型的方法被执行。在进行光学邻近校正202期间,集成电路布局被修改,使得修改后的集成电路设计布局在晶圆上具有改善的图像。在此步骤中对集成电路设计布局的修改包括重新调整主要特征的尺寸、重新定位主要特征的边缘、对主要特征重新塑形、对主要特征加入辅助特征、对主要特征加入散射条或前述的组合。光学邻近校正202包括模拟集成电路设计布局以产生集成电路设计布局的轮廓。集成电路设计布局的轮廓是集成电路设计布局从对应的掩模转移到集成电路基板(例如半导体晶圆)时的图像。基于轮廓与所预期的集成电路设计布局的差异,此过程可以重复许多次,直到差异在可接受范围内。此模拟是基于制造数据来进行。此模拟包括根据制造数据模拟光刻工艺以从掩模转移集成电路设计布局到集成电路基板,制造数据包括光刻光学成像数据,并且可进一步包括光刻胶反应数据。在另一实施例中,制造数据可还包括蚀刻数据,例如蚀刻偏差(etchingbias)。
光学邻近校正后验证204可以根据输入所设计的布局图案来检查光刻胶转印输出(resistprint-out)。光学邻近校正后验证204可包括执行评估程序以确定轮廓是否可接受。一组电子束数据被产生,以电子束写入机可使用的格式显示集成电路设计布局。这组电子束数据可被称为用于掩模制造的下线(tape-out)。下线系统可以执行数据准备104。下线系统可以是分离的实体或可以分布在现有实体中,例如设计/实验室设施或在线系统。下线系统可以连接到网络,例如网际网络或内部网络。如下所述,本公开对光学邻近校正后验证204提供机器学习方法。
在公知的光学邻近校正后验证(例如:称为转印检查)中,可以经由调整模拟的曝光能量剂量来执行转印检查。举例来说,剂量可以在标称条件(nominalconditions)附近的范围内增加或减少。接着,使用所得模型(resultantmodule)执行全晶片检查以评估转印输出或缺陷的可能性。然而,在一些情况下,剂量变化窗口(dosevariationwindow)取决于层的类型(layertypes)。因此,剂量范围的偏差可能不够准确以检查转印输出的确切区域,这会导致在检查期间低估热点区域或高估热点区域(例如:在转印中有缺陷机率的区域),进而降低产能。因此,需要更准确的光学邻近校正后验证。
使用机器学习的光学邻近校正后验证的示例
如上所述,当集成电路设计布局从对应的掩模转移到集成电路基板(例如半导体晶圆)时,光学邻近校正程序提供集成电路设计布局的图像。机器学习是一种图案辨识的强力(powerful)方法。根据某些实施例,机器学习可用于在使用图案辨识的训练模型的光学邻近校正后验证中检查光刻胶转印输出,以建立在光学邻近校正后的集成电路设计布局(例如:主要特征以及邻近辅助特征)与是否晶圆将转印输出该图案的相关评估之间的关系。机器学习演算法的范例包括卷积神经网络(convolutionalneuralnetwork;cnn)演算法、递归神经网络(recursiveneuralnetwork)演算法、支援向量机(supportvectormachine)演算法以及深度学习人工智慧演算法。
在机器学习中,卷积神经网络(cnn或convnet)是已经成功地应用于分析视觉图像的一种深度类别的前馈人工神经网络。卷积神经网络使用多层感知器的变体,其被设计为需要最少的预处理。它们亦被知晓为位移不变(shiftinvariant)或空间不变(spaceinvariant)的人工神经网络(siann),这是基于它们的共享权重结构以及转移不变特性。与其他图像分类演算法相比,卷积神经网络使用相对较少的预处理。这意味着网络在学习传统演算法中为手动工程(hand-engineered)的过滤器(filter)。这种在特征设计中独立于(不依靠)先前知识以及人力为其一主要优点。
递归(recursive)神经网络(rnn)是经由在结构上递归地应用相同的一组权重所创建的一种深度神经网络,通过在拓朴排序(topologicalorder)中给定的结构以产生在可变尺寸输入结构(variable-sizestructures)上的结构预测或纯量预测。举例来说,递归神经网络已经成功地在自然语言处理中学习序列以及树形结构,主要是基于词嵌入(wordembedding)的词组与句子连续表示。递归神经网络首先被引入以学习分布的结构表示,例如逻辑术语。
在机器学习中,支援向量机(svms,亦支援向量网络)是具有关联于学习演算法的监督学习模型,其分析数据用于分类分析及回归分析。给定一组训练范例,每个训练范例被标记属于两个类别中的一个或另一个,支援向量机训练演算法建立一个模型,用以分配新的训练范例至一个类别或另一个类别,使其成为非机率二元线性分类器(虽然多种方法(例如普拉特缩放(plattscaling))存在以在机率分类设置中使用支援向量机)。支援向量机模型是将训练范例在空间中表示为点的映射,使得各个类别由尽可能宽的明确差距(gap)被划分。新的训练范例接着被映射至同一空间中,并且基于它们会落在差距(gap)的哪一侧预测属于其类别。除了执行线性分类外,支援向量机可以使用所谓的核心技巧(kerneltrick)高效地执行非线性分类,隐密地映射它们的输入到高维度特征空间。当数据未被标签时,监督学习是不可能的,并且需要一种无监督学习方法,该方法会试图找到数据的自然聚类(naturalclustering)到多个分组,并且接着映射新数据到这些形成的多个分组。对支援向量机提供改善的聚类(clustering)演算法被称为支援向量聚类(supportvectorclustering),并且在当数据未被施加标签时或当只有一些数据被施加标签为用于分类过程(classificationpass)的预处理时被使用。
深度学习(亦被知为深度结构学习或分层(hierarchical)学习)是人工神经网络的应用,应用于包含多于一个隐藏层的学习任务。深度学习是基于学习数据表示法的机器学习方法的更广泛家族的一部份,不同于任务特定的演算法。学习可以受到监督、部份地受到监督或无监督。某些表示法(representations)在基于在生物神经系统中的信息处理和通信图案的解释下是松散的,例如试图定义在大脑中的各种刺激以及相关神经元反应之间的关系的神经编码。
图3是根据一些实施例的使用机器学习(例如:基于图像的机器学习)的光学邻近校正后验证的操作300流程图。根据某些实施例,光学邻近校正后验证的操作300可经由如上述的掩模制造实体(例如:经由数据准备模块)来执行。在实施例中,操作300可经由处理器或处理系统来执行。为了明确表示,将结合图4中的系统400来说明操作300,系统400被配置以执行操作300。
操作300在步骤302经由接收集成电路设计布局(例如:gds.in数据剪辑(dataclip)或电脑辅助设计(cad)数据文件)作为开始。集成电路设计布局可以由掩模制造模块404接收。集成电路设计布局可以从集成电路设计模块402(例如:集成电路设计厂)输出。举例来说,集成电路设计布局可以自动化地产生或经由使用者使用电脑辅助设计软件输入。
操作300包括在步骤304中对集成电路设计布局执行光学邻近校正程序,以产生校正后的集成电路设计布局,并且在步骤306中使用机器学习演算法验证校正后的集成电路设计布局。掩模制造模块404可包括执行光学邻近校正和光学邻近校正后验证的数据准备模块406。举例来说,数据准备模块406包括光学邻近校正模块408,光学邻近校正模块408执行光学邻近校正程序以输出校正后的掩模布局设计(例如:gds.out数据剪辑)到光学邻近校正后验证模块410。
根据某些实施例,在步骤306中验证校正后的集成电路设计布局包括在步骤308中使用机器学习演算法识别校正后的集成电路设计布局的一或多个特征(例如:主要特征及/或辅助特征)、在步骤310中将一或多个识别后的特征与包括多个特征的数据库作比较以及在步骤312中基于与该多个特征关联的数据库中的多个标签(例如:指示是否集成电路设计布局将成功地转印输出在晶圆上或具有缺陷的转印输出在晶圆上(或其机率))来验证校正后的集成电路设计布局。举例来说,光学邻近校正后验证模块410包括特征识别模块412,特征识别模块412被配置以识别在校正后的集成电路设计布局中的特征。
根据某些实施例,特征识别模块412使用机器学习演算法以识别该多个特征。机器学习转印输出模型使用各种输入图案布局的模拟/晶圆结果进行训练。透过机器学习方法(例如卷积神经网络、支援向量机、深度学习方法),来自输入的gds布局可以被提取并且嵌入到训练模型中。接着,训练模型建立晶圆上可能的转印输出结果与具有辅助特征布置的输入设计图案之间的关联性。举例来说,光学邻近校正后验证模块410还包括数据库比较模块414。系统400可包括存储器418(或多个存储器),存储器418可以位于系统400内的各个位置。存储器418储存数据库420。数据库420可包括许多不同的集成电路设计布局、特征及/或辅助特征。另外,数据库420储存与在数据库中每一个不同的集成电路设计布局、特征及/或辅助特征相关的标签。标签对应于(例如:使用掩模进行光刻工艺以制造集成电路的期间)图案是否将成功地转印输出在晶圆上的预测,或是对应于转印输出在晶圆上的图案是否具有缺陷的预测(例如:模拟的结果)。数据库比较模块414可以将在校正后的集成电路设计布局中所识别出的特征与在数据库420中的特征进行比较。基于该比较,数据库比较模块414可以将校正后的集成电路设计布局与在数据库420中的图案作匹配。评估模块416可以检查在数据库420中与匹配图案相关的标签。基于该标签,评估模块416可以确定(例如:预测)校正后的集成电路设计布局是否将转印输出。
因此,机器学习训练模型可以突出显示(highlight)可能的图案区域,并且可以应用更详细的工艺窗口(例如:公差阈值(tolerancethreshold))模型以检查真实的工艺窗口。工艺窗口可以立即在光学邻近校正流程之后进行预先检查以及通选(gate),并且可以减少半导体开发的整体运行时间。
透过机器学习,系统400可以从许多严谨的模拟结果中训练出精确的转印模型。此外,从机器学习中(例如:神经网络),此模型接着可以基于在某个范围内图案布局在掩模设计(design-on-mask;dom)与晶圆设计(design-on-wafer;dow)之间建立连接。接着,所得的模型可以应用在光学邻近校正后验证,以有效检查转印输出机率,因为所提出的方法是基于图像而不是实时模拟。
如图3所述,在步骤301中,可以执行数据训练以产生数据库420(例如经由数据训练模块422)。举例来说,数据训练模块422可以包括图形产生模块424以产生许多不同图案(例如:集成电路设计布局、特征、辅助特征、辅助特征布置、布局类型、环境等等)。训练模拟模块426可以对由图案产生模块424所产生的图案执行转印模拟,以确定图案是否将成功地转印输出在晶圆上的机率,或是图案是否具有缺陷的转印输出在晶圆上的机率。基于模拟结果,训练模拟模块426可以创建与将被储存在数据库420中的图形相关的标签。这些储存的图案以及标签可用于后期的光学邻近校正后验证程序。
在一些情况下,该模拟执行光学邻近校正紧凑模型以确定转印输出风险。在此模型中,曝光能量变化以在各种环境下测试此图案以确定图案是否将成功地转印输出(例如:具有缺陷)。举例来说,光学邻近校正紧凑模型可具有以下形式:
根据某些实施例,除了其他光学邻近校正验证技术(例如:紧凑光学邻近校正模型),可以使用本文所述的用于光学邻近校正后验证的机器学习方法。举例来说,经由在不同曝光剂量下执行模拟来验证校正后的集成电路设计布局,以基于轮廓和强度确定转印输出机率。因此,多个标准可被应用来检查使用不同方法的转印输出风险。根据某些实施例,大约百分之八十(80%)的可用数据可以用于数据训练以产生数据库420,并且大约百分之二十(20%)的数据可以用于图4a所示的转印验证。如图4a所示,数据源418a(例如:在存储器418)可以分成用于数据训练的子集和用于验证(测试)的子集,这些子集可以包括特征以及目标图案。数据源418a可以随机地被选择。如图4a所示,大约80%的数据源418a被选择为训练数据430a和目标数据432,并且大约20%的数据源418a被选择为验证数据434和目标数据436。这可以避免在模型训练期间过度拟合(over-fitting)。可以使用不同数据组执行多次数据训练及验证,以训练及验证机器学习(ml)模型438。验证数据434包括基于机器学习模型438而用于在训练数据430a中的特征的测试预测440。测试预测440可以与目标数据436进行比较以评估机器学习模型438的精确性。
一旦集成电路设计布局被验证,可以接着转印(例如:下线)掩模。如图4所示,掩模制造模块404包括掩模加工模块428。掩模加工模块428使用经由数据准备模块406验证的集成电路掩模布局设计,并且转印掩模(例如:使用电子束光刻或其他工艺技术)。此掩模可以接着用于制造半导体装置的集成电路制造。如图4所示,系统400包括集成电路制造模块430。集成电路制造模块430可以由集成电路制造实体(例如:fab(集成电路制造厂))来执行。集成电路制造模块430可以应用各种光刻技术使用掩模来制造集成电路。
图5是根据一些实施例的用于光学邻近校正后验证的数据训练、特征提取以及数据库产生机器学习技术的示意图。图5更详细地显示可以由数据训练模块422执行的数据训练以及数据库产生技术。
如图5所示,数据训练可包括形成gds池(pool)502。举例来说,gds池502可包括由图案产生模块424产生并且储存在数据库420的集成电路设计布局(例如,gds数据剪辑)。如图所示,可以从集成电路设计布局提取特征(例如:主要特征、辅助特征等等),例如特征504。如上面所述,机器学习技术可以用于特征提取。训练模拟模块426可以预测特征是否将“转印”或“不转印”。训练的输出是与可储存在数据库420中的特征/图案相关的标签,以指示相关的特征/图案是否将转印。如上面所述,储存在数据库420中的图案及标签可以用于光学邻近校正后验证。
可以使用通用处理器、特殊应用集成电路(asic)、现场可程序逻辑门阵列(fpga),或者其他可程序逻辑装置(pld)、离散栅极或电晶体逻辑(discretegateortransistorlogic)、离散硬件部件,或者设计以执行本文所述功能的任何组合,来实现或执行结合本公开所述的各种逻辑块、模块以及电路。如果以软件实现,可以将这些功能作为一或多个指令或代码储存或传输到电脑可读媒体上。无论软件、固件、中介软件(middleware)、微代码、硬件描述语言或其他,软件都应被广义地解释为指令、数据或任何组合。电脑可读媒体包括电脑储存媒体以及通信媒体两者,通信媒体包括任何便于将电脑程序从一个地方传输到另一个地方的任何媒体。处理器可以负责执行储存在机器可读储存媒体上的软件模块。电脑可读媒体可以耦接到处理器,使得处理器可以从储存媒体读取信息(并写入信息到储存媒体)。或者,储存媒体可以整合到处理器中。机器可读媒体可包括具有指令存在其上的电脑可读储存媒体。机器可读媒体或其任何部份可以整合到处理器中,例如缓存(cache)及/或通用寄存器文件(generalregisterdiles)。机器可读媒体可以体现(embodied)在电脑程序产品中。
电脑可读媒体可包括多个软件模块。软件模块可包括单一指令或许多指令,并且可以分布在几个不同的代码区段(codesegment)上、不同程序的间以及跨越多个储存媒体。软件模块包括经由设备(例如处理器)执行时,使处理系统执行各种功能的指令。因此,某些实施例可包括具有指令储存(及/或编码)在其上的电脑可读媒体,指令可由一或多个处理器执行以执行本文所述的操作(例如用于执行本文所述且显示在图3中的操作的指令)。
本文所述的使用机器学习于集成电路设计布局的光学邻近后验证的技术可以帮助改善验证集成电路设计布局的效率及精确度。改善效率可以加速掩模的制造流程,进而降低相关成本。改善精确度可以减少转印掩模的缺陷,进而减少校正或重新转印所涉及的时间及成本。
在一实施例中,提供了一种集成电路制造方法。此方法包括接收一集成电路设计布局。此方法包括对集成电路设计布局执行一光学邻近校正(opc)程序,以产生一校正后的集成电路设计布局。此方法还包括使用一机器学习演算法验证校正后的集成电路设计布局。
在一实施例中,在集成电路制造方法中,其中验证上述校正后的集成电路设计布局的步骤包括使用上述机器学习演算法以识别上述校正后的集成电路设计布局的一或多个第一特征;将识别后的上述一或多个第一特征与一数据库进行比较,其中上述数据库包括多个第二特征;以及基于与上述第二特征关联的上述数据库中的多个标签来验证上述校正后的集成电路设计布局。
在一实施例中,在集成电路制造方法中,其中上述多个标签对应于一机率,其中上述机率为上述校正后的集成电路设计布局是否将成功地转印在一晶圆上,或者上述校正后的集成电路设计布局是否具有缺陷地转印在上述晶圆上。
在一实施例中,在集成电路制造方法中,其中接收上述集成电路设计布局的步骤包括接收一图形设计系统(gds)文件,并且上述校正后的集成电路设计布局包括一调整后的图形设计系统文件。
在一实施例中,在集成电路制造方法中还包括产生上述数据库,其中产生上述数据库的步骤包括产生多个集成电路设计布局;对每一个集成电路设计布局执行一转印模拟以确定一机率,上述机率为上述校正后的集成电路设计布局是否将成功地转印在一晶圆上,或者上述校正后的集成电路设计布局是否具有缺陷地转印在上述晶圆上;以及在上述数据库中储存与每一个集成电路设计布局关联的一标签,其中上述标签指示上述机率。
在一实施例中,在集成电路制造方法中,其中上述机器学习演算法包括以下至少一者:一卷积神经网络(convolutionalneuralnetwork)演算法、一递归神经网络(recursiveneuralnetwork)演算法、一支援向量机(supportvectormachine)演算法或一深度学习人工智慧演算法。
在一实施例中,在集成电路制造方法中还包括经由在多个曝光剂量中对每一个集成电路执行多个转印模拟以使用一紧凑光学邻近校正模型(compactopcmodel)验证上述校正后的集成电路设计布局以确定上述机率。
在另一实施例中,提供了一种集成电路制造系统。此系统包括一掩模制造模块,被配置以接收一集成电路设计布局。此掩模制造模块包括一数据准备模块,被配置以对集成电路设计布局执行一光学邻近校正(opc)程序以产生一校正后的集成电路设计布局,并且使用一机器学习演算法验证校正后的集成电路设计布局。此掩模制造模块包括一掩模加工(masktooling)模块,被配置以转印校正后的集成电路设计布局。此系统包括一集成电路制造模块,被配置以使用一掩模制造一集成电路。
在一实施例中,在集成电路制造系统中,其中上述集成电路制造系统还包括至少一存储器以储存一数据库:以及上述数据准备模块被配置以经由以下方式验证上述校正后的集成电路设计布局:使用上述机器学习演算法以识别上述校正后的集成电路设计布局的一或多个第一特征;将识别后的上述一或多个第一特征与一数据库进行比较,其中上述数据库包括多个第二特征;以及基于与上述第二特征关联的上述数据库中的多个标签来验证上述校正后的集成电路设计布局。
在一实施例中,在集成电路制造系统中,其中上述多个标签对应于一机率,其中上述机率为上述校正后的集成电路设计布局是否将成功地转印在一晶圆上,或者上述校正后的集成电路设计布局是否具有缺陷地转印在上述晶圆上。
在一实施例中,在集成电路制造系统中,其中接收上述集成电路设计布局的步骤包括接收一图形设计系统(gds)文件,并且其中上述校正后的集成电路设计布局包括一调整后的图形设计系统文件。
在一实施例中,在集成电路制造系统中还包括一数据训练(datatraining)模块,被配置以经由以下方式产生上述数据库:产生多个集成电路设计布局;对每一个集成电路设计布局执行一转印模拟以确定一机率,上述机率为上述校正后的集成电路设计布局是否将成功地转印在一晶圆上,或者上述校正后的集成电路设计布局是否具有缺陷地转印在上述晶圆上;以及在上述数据库中储存与每一个集成电路设计布局关联的一标签,其中上述标签指示上述机率。
在一实施例中,在集成电路制造系统中,其中上述机器学习演算法包括以下至少一者:一卷积神经网络(convolutionalneuralnetwork)演算法、一递归神经网络(recursiveneuralnetwork)演算法、一支援向量机(supportvectormachine)演算法或一深度学习人工智慧演算法。
在一实施例中,在集成电路制造系统中,其中上述数据准备模块更被配置以经由在多个曝光剂量中对每一个集成电路执行多个转印模拟以使用一紧凑光学邻近校正模型(compactopcmodel)验证上述校正后的集成电路设计布局以确定上述机率。
在另一实施例中,提供了一种储存有多个电脑可执行代码的一种电脑可读媒体。电脑可执行代码包括一第一代码,用于接收一集成电路设计布局。电脑可执行代码包括一第二代码,用于对上述集成电路设计布局执行一光学邻近校正(opc)程序,以产生一校正后的集成电路设计布局。电脑可执行代码包括一第三代码,用于使用一机器学习演算法验证上述校正后的集成电路设计布局。
在一实施例中,在电脑可读媒体中,其中用于验证上述校正后的集成电路设计布局的上述第三代码包括:一第四代码,用于使用上述机器学习演算法以识别上述校正后的集成电路设计布局的一或多个第一特征;一第五代码,用于将识别后的上述一或多个第一特征与一数据库进行比较,其中上述数据库包括多个第二特征;以及一第六代码,用于基于与上述第二特征关联的上述数据库中的多个标签来验证上述校正后的集成电路设计布局。
在一实施例中,在电脑可读媒体中,其中多个标签对应于一机率,其中上述机率为上述校正后的集成电路设计布局是否将成功地转印在一晶圆上,或者上述校正后的集成电路设计布局是否具有缺陷的转印在上述晶圆上。
在一实施例中,在电脑可读媒体中,其中用于接收上述集成电路设计布局的第一代码包括用于接收一图形设计系统(gds)文件的一第七代码,并且其中上述校正后的集成电路设计布局包括一调整后的图形设计系统文件。
在一实施例中,在电脑可读媒体还包括用于产生上述数据库的一第八代码,上述第八代码包括:一第九代码,用于产生多个集成电路设计布局;一第十代码,用于对每一个集成电路设计布局执行一转印模拟以确定一机率,上述机率为上述校正后的集成电路设计布局是否将成功地转印在一晶圆上,或者上述校正后的集成电路设计布局是否具有缺陷的转印在上述晶圆上;以及一第十一代码,用于在上述数据库中储存与每一个集成电路设计布局关联的一标签,其中上述标签指示上述机率。
在一实施例中,在电脑可读媒体中,其中上述机器学习演算法包括以下至少一者:一卷积神经网络(convolutionalneuralnetwork)演算法、一递归神经网络(recursiveneuralnetwork)演算法、一支援向量机(supportvectormachine)演算法或一深度学习人工智慧演算法。
前述内文概述了许多实施例的特征,使本技术领域中普通技术人员可以从各个方面更佳地了解本公开。本技术领域中普通技术人员应可理解,且可轻易地以本公开为基础来设计或修改其他工艺及结构,并以此达到相同的目的及/或达到与在此介绍的实施例等相同的优点。本技术领域中普通技术人员也应了解这些相等的结构并未背离本公开的发明精神与范围。在不背离本公开的发明精神与范围的前提下,可对本公开进行各种改变、置换或修改。
- 还没有人留言评论。精彩留言会获得点赞!