一种基于词向量与词性的情感分析方法与流程
本发明涉及自然语言处理、数据挖掘、文本分析、计算语言学和机器学习领域,涉及文本预处理技术、特征提取技术、情感分析技术和机器学习分类技术,尤其是一种基于词向量与词性的情感分析方法。
背景技术
目前,中文微博情感分析方法可以分为两大类:基于情感词典的微博情感分析方法和基于机器学习的微博情感分析方法。基于情感词典的微博情感分析方法主要根据情感词典,将一条微博语句的情感极性值之和作为该条语句的情感极性,可分为词语特征级、句子级情感判别,该方法主要的优点是粒度细、分析准确。
但受到自然语言处理技术及相关抽取技术的限制,对语句中各语义成分及其对应关系的不能很好的识别。在中文有着丰富的语义表达,很多情感都是隐含的,比如:“我昨天吃了这道菜,今天就拉肚子了”。这句话没有一个情感词,但表达的是消极的情绪。所以基于情感词典的分析方法忽视了非情感词语对情感分析结果的影响,因而无法进行准确的分类。
基于机器学习的微博情感分类方法多使用分类模型如:支持向量机(supportvectormachine,svm)、朴素贝叶斯、最大熵模型等,选取文本中有利于情感极性分类的词或短语等作为特征,训练集语料的大小和质量、特征提取的好坏将直接决定分类器的好坏。特征工程是此类方法的核心,情感分类任务中常用到的特征有n-gram(大词汇连续语音识别中常用的一种语言模型)特征、句法特征、tf-idf(一种用于信息检索与数据挖掘的常用加权技术)特征等。
其中,tf-idf特征提取方法是通过tf-idf模型就能将一个文本进行向量化。优点是简单快速,结果比较符合实际情况。但这个模型存在一定的缺点,tf-idf是忽略了词之间相关性,该方法无法考虑词语的语义信息,因而提取到的特征会对最终的情感分析结果产生影响。
技术实现要素:
本发明提供了一种基于词向量与词性的情感分析方法,本发明能有效克服传统情感分析方法中不能充分考虑词语词性及语义信息对情感分析结果的影响的问题,将词性与语义进行结合,详见下文描述:
一种基于词向量与词性的情感分析方法,所述方法包括以下步骤:
获取原始微博语料库,并将原始微博语料库中的中文语料信息与语料标签信息进行匹配,每条语料信息对应一个标签信息;去除微博文本对情感分析没有积极作用或造成干扰的特殊符号。
将预处理后的文本根据词语的词性进行处理,筛选出需要的形容词、动词和否定词,构成原始特征集合;
计算词频,然后计算逆向文件频率,最后计算微博数据中词语的tf-idf值,再根据tf-idf提取特征词;
计算词语的tf-idf值,将词典中每条数据都由一个词语及其对应的词向量组成;将特征词与词向量字典结合,组成特征词与词向量字典;
将每条文本微博数据的文本的所有特征词组合,生成每一条文本微博数据的向量,最后得到所有微博数据的向量;
根据训练数据建立各自的微博数据情感分类模型,分别使用朴素贝叶斯分类器、最近邻分类器、随机森林分类器和支持向量机分类器进行情感分析。
所述每条语料信息对应一个标签信息具体为:
如果语料信息的情感积极,则标记为1;否则,标记为0。
本发明提供的技术方案的有益效果是:
1、在实验预处理阶段,针对使用情感词典无法准确分类的问题,通过词性过滤方法处理实验数据集,并明显地提高了情感分析的实验效果。
2、在特征提取阶段,针对传统语言模型无法存储词语语义信息的问题,利用word2vec将词语映射到向量空间,转换成词向量。将tf-idf特征提取方法与词向量相结合,既充分地考虑了词语的语义信息,又可以控制词向量的维度,该方法可以显著的提高自然语言处理任务的时间性能。
3、本发明可以更好的结合微博数据深层次的挖掘用户的需求,了解用户的情感倾向,为用户提供个性化服务。
附图说明
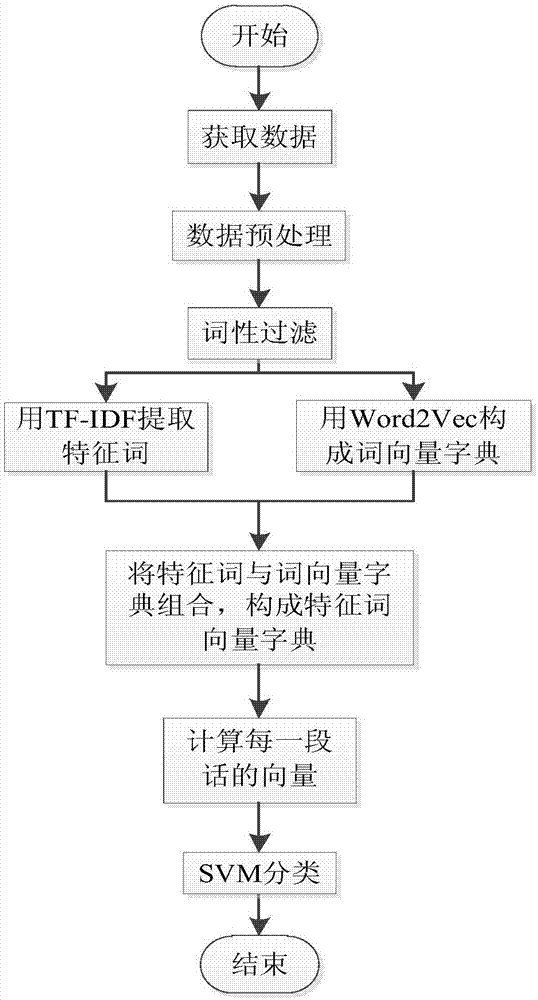
图1为基于词向量与词性的情感分析方法的流程图;
图2为不同分类器对实验效果影响的示意图;
图3为不同情感分析方法对实验效果影响的示意图。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚,下面对本发明实施方式作进一步地详细描述。
实施例1
参见图1,本发明实施例提供了一种基于词向量与词性的情感分析方法,该方法包括以下步骤:
101:整理原始语料库;
该步骤101具体包括:取已有的原始微博语料库,并将微博语料库中的中文语料信息与语料标签信息进行匹配。
102:数据预处理;
去除微博文本对情感分析没有积极作用或造成干扰的特殊符号,如网址、@标记、转发标记“//”以及内容标记信息“#内容#”等。
103:将预处理后的文本进行根据词语的词性进行处理,筛选出需要的形容词、动词和否定词,构成原始特征集合。
104:计算词语的tf-idf值,并利用词语的tf-idf值提取特征词;
105:用word2vec处理语料库,获得词向量字典;
106:将特征词与词向量字典结合,组成特征词与词向量字典;
107:将每条文本微博数据的文本的所有特征词组合,生成每一条文本微博数据的向量,最后得到所有微博数据的向量;
108:利用分类器对微博数据生成的向量建立微博数据情感分类模型。
在一个实施例中,步骤101对整理原始微博语料库,具体步骤如下:
获取原始微博语料库,并将原始微博语料库中的语料信息data与语料标签信息senti_label进行匹配,每条语料信息对应一个标签信息。如果语料信息的情感积极,则标记为1;否则,标记为0。
在一个实施例中,步骤102进行数据预处理,具体步骤如下:
依次去除原始微博语料库中的重复微博、去除@、url和#等特殊符号、去除微博中的英文内容进行中文分词,去除停用词,并进行词性标注。
在一个实施例中,步骤103对预处理后微博文本进行词性过滤,具体步骤如下:
将预处理后的文本根据词语的词性,筛选出需要的形容词、动词、否定词等词语特征项,过滤掉对情感分析结果无意义的副词、量词、连词以及介词等词语。
在一个实施例中,步骤104提取微博词语的特征词,具体步骤如下:
首先计算词频,然后计算逆向文件频率,最后计算微博数据中词语的tf-idf值。再根据tf-idf提取特征词。
在一个实施例中,步骤105处理微博数据语料库,得到词向量字典,具体步骤如下:
利用word2vec工具,将该词典中每条数据都由一个词语及其对应的词向量组成。如词语“喜欢”对应的200维词向量。
在一个实施例中,步骤106生成的词向量字典组合,构成特征词向量字典。
在一个实施例中,步骤108对微博数据进行情感分类,具体步骤如下:
根据训练数据建立各自的微博数据情感分类模型,分别使用朴素贝叶斯分类器、最近邻分类器、随机森林分类器和支持向量机分类器进行情感分析。
综上所述,本发明实施例能有效克服传统情感分析方法中不能充分考虑词语词性及语义信息对情感分析结果的影响的问题,将词性与语义进行结合。
实施例2
下面结合具体的实例、数学公式对实施例1中的方案进行进一步地介绍,详见下文描述:
201:首先需要获取原始微博语料库,然后对原始微博语料库进行整理,将原始微博语料库中的语料信息data与语料标签信息senti_label进行匹配,每条语料信息对应一个标签信息。如果语料信息为积极,则标记为1;否则,标记为0。
202:进行原始微博语料库的数据预处理;
从原始微博语料库中依次去除重复微博、@、url和#等特殊符号、英文内容,接着使用bostonnlp对微博文本进行分词处理,并标记词语词性,去除无意义的停用词,最后将分词结果中的每个词语标注一个正确词性。
203:将预处理后的微博语料库进行词性过滤;
将步骤202中的文本预处理结果根据词语的词性进行处理,筛选出需要的形容词、动词、否定词等词语特征项,将剩余词语构成原始特征集合。经过词性过滤的原始微博语料库只保留了形容词、动词和否定词。
204:计算词语的tf-idf值;
首先计算词频,然后计算逆向文件频率,,最后计算微博数据中词语的tf-idf值。
205:利用词语的tf-idf值大小提取特征词;
206:用word2vec处理语料库,获得词向量字典,该词向量字典中每条数据都由一个词语及其对应的词向量组成。
207:将得到的特征词与词语向量字典组合,构成特征词语向量字典;
208:计算每一条文本微博数据的向量,如公式(1)至(2)所示。
一条微博数据的第i个特征词的特征向量为vec(wordi),如公式(1)所示。
vec(wordi)=[v1,v2,......,v200](1)
其中,vi表示向量vec(wordi)第i维的数据值,vec(wordi)的维度为200;该条微博数据所对应的向量vector(graph)如公式(2)所示。
其中,n为该条微博数据中特征词的数目。
209:使用svm进行情感分析,核函数采用径向基核函数,调节支持svm中的参数c和gamma,可以使微博数据的情感分析实验得到最佳效果。
综上所述,本发明实施例可以更好的结合微博数据深层次的挖掘用户的需求,了解用户的情感倾向,为用户提供个性化服务。
实施例3
下面结合具体的实验数据、图2和图3对实施例1和2中的方案进行可行性验证,详见下文描述:
首先通过实验分别验证了朴素贝叶斯分类器、最近邻分类器、支持向量机分类器和随机森林分类器对实验效果的影响,并通过使用准确率(accuracy)、召回率(recallrate)、f值(f-measure)、精确率(precision)作为评价准则对实验结果进行评价,如图2所示,实验结果证明支持向量机分类器在该微博数据集上的情感分类具有较好的结果。
在图2中,可以看出,使用svm的accuracy、recal、f值、precision比贝叶斯分类器、最近邻分类器和随机森林分类器的高。
接着,在使用支持向量机进行情感分析的前提下分析了不同特征提取方法对情感分析实验效果的影响,tf-idf+word2vec特征提取模型与tf-idf特征提取模型相比,如表1所示,accuracy高了0.3086%,f值高了0.1251%,precision高了0.3366%。tf-idf+word2vec特征提取模型与word2vec模型相比,accuracy高了0.6173%,recall高了1655%,f值高了0.3379%,precision高了0.4608%。基于tf-idf与词向量的特征提取方法(tf-idf+word2vec)能够取得较好的情感分类效果。
表1不同特征提取方法的实验效果对比
最后,对比不同情感分析方法对实验效果的影响,如图3所示,基于词向量与词性的情感分析方法(sentimentanalysisalgorithmbasedonwordvectorandpos,sa2-wv&pos)与ilar-tc方法相比,在准确率、召回率、f值以及精确率方面的效果更好,证明了词性过滤对情感分析实验结果能够产生积极作用。
在图3中,sa2-wv&pos比ilar-tc方法在实验准确率、召回率、f值及精确率方面有显著的提高,对微博数据的情感分析具有积极意义。
本发明实施例对各器件的型号除做特殊说明的以外,其他器件的型号不做限制,只要能完成上述功能的器件均可。
本领域技术人员可以理解附图只是一个优选实施例的示意图,上述本发明实施例序号仅仅为了描述,不代表实施例的优劣。
以上所述仅为本发明的较佳实施例,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!