适用于证券交易系统的故障检测方法及装置与流程
本发明涉及故障检测技术领域,具体来说是一种适用于证券交易系统的故障检测方法及装置。
背景技术:
证券交易系统是一个对可用性要求很高的分布式系统,在设计高可用证券交易系统时通常会采用基于ip组播的组通信模式来构建多服务副本的方法,从而保证系统的高可用性。在组通信的服务发生故障的时候,对系统发现故障的及时性和正确性都有非常高的要求。发现故障的及时性直接影响着系统服务的恢复时间,故障识别错误后会直接导致业务处理错误,所以故障检测算法对于采用组通信分布式架构的证券交易系统来说是高可用性指标的关键因素。目前绝大多数分布式系统的故障检测都是基于超时判断的方法,比如采用ping方法、心跳方法、gossip方法等,基于不可靠的故障检测算法不适用于类似证券交易系统这样对可靠性和实时性都要求很高的分布式系统。
证券交易系统是一个通过网络连接的多台主机构成的高可用分布式系统。整个系统由一组有限的进程组成,进程之间只能通过发送和接收消息进行通信。进程一般会由于主机故障或者崩溃导致明确的故障,或者由于设备故障导致进程的消息丢失也是明确的故障,比较复杂的故障是由于网络分裂导致的系统分区故障,所以证券交易系统需要处理崩溃故障和丢失故障以及网络分区故障。在这里我们不讨论分布式系统中的消息篡改问题,因为在证券交易系统中内部节点都是可信任的。
适用于基于组通信的分布式架构证券交易系统的故障检测算法需要能够对上述3种故障的及时准确发现,传统的故障检测算法一般不考虑网络分区的故障,而且假设的故障场景也不是组通信场景而是点对点的故障检测。
技术实现要素:
本发明的目的在于解决现有技术的不足,提供一种适用于证券交易系统的故障检测方法及装置,能实现故障的及时检测,尤其适用于证券交易系统。
为了实现上述目的,设计一种适用于证券交易系统的故障检测方法,所述的方法如下:
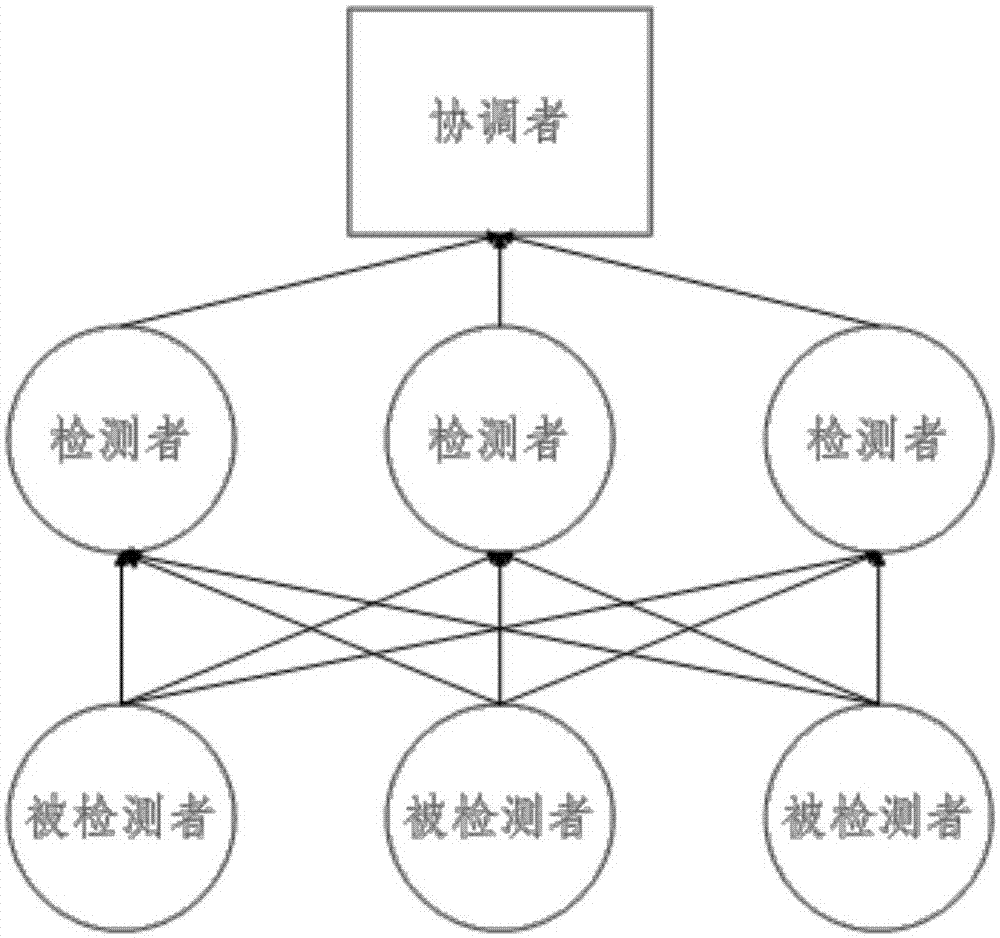
由若干被检测者模块定时向检测者模块发送包括进程组状态信息的心跳消息。
由至少一个检测者模块接收所有被检测者模块的心跳消息,并计算每一被检测者模块每次心跳消息的超时时限,若在任一次心跳消息的超时时限内检测者模块未接收到被检测者模块发出的心跳消息,则检测者模块向协调者模块汇报被检测者模块的状态视图。
由一个协调者模块接收所有检测者模块汇报的状态视图,并根据状态视图来判断被检测者模块的故障行为并作出裁决。
所述的每次心跳消息的超时时限通过如下公式获得:
tok+1=tek+1+tαk+1(a)
式中:tok+1是第k+1次心跳消息的超时时限,tαk+1是第k+1次心跳消息的自适应安全余量,tek+1是第k+1次预期的心跳消息到达时间;
所述的第k+1次预期的心跳消息到达时间的通过如下公式获得:
式中:ti是第i次心跳消息的接收时间,tsi是第i次心跳消息的发送时间,tsk+1是第k+1次心跳消息的发送时间,心跳消息的接收端在接收到最近的n个心跳消息后即可以根据公式2计算出下次心跳时限的期望值tek+1;
所述的第k+1次心跳消息的自适应安全余量通过如下公式获得:
式中:ti是第i次心跳消息的接收时间,toi是第i次心跳消息的超时时限。
若任一被检测者模块在任一次心跳消息的超时时限内未接收到被检测者模块发出的心跳消息,则检测者模块将该被检测者模块设置为怀疑故障状态,并向协调者模块汇报所有被检测者模块的状态视图。
当协调者模块接收到任一被检测者模块所发出的状态视图时,则对为怀疑故障状态的被检测者模块进行判断,若为怀疑故障状态的被检测者模块不含有关键进程,则对本地视图状态进行更新。
若为怀疑故障状态的被检测者模块含有关键进程,则等待一个收敛周期,并在收敛周期后向所有检测者模块发出状态收集的通知,并由所有检测者模块分别向协调者模块汇报所有被检测者模块的状态视图,并通过状态视图对关键进程的状态进行判断。
所述的通过状态视图对关键进程的状态进行判断的方法如下:若状态视图中多数被检测者模块的状态为活跃状态,则判定关键进程的状态为活跃,并更新本体视图状态为正常状态;反之,则判定关键进程的状态为故障,并通知所有组成员更新状态视图和编号,进入新的故障检测状态。
所述的收敛周期大于两倍的心跳间隔。
本发明还设计一种用于所述的适用于证券交易系统的故障检测方法的装置,所述的装置包括:
若干用于定时向检测者模块发送包括进程组状态信息的心跳消息的被检测者模块;
至少一个用于接收所有被检测者模块的心跳消息,并计算每一被检测者模块每次心跳消息的超时时限,若在任一次心跳消息的超时时限内未接收到被检测者模块发出的心跳消息,则向协调者模块汇报被检测者模块的状态视图的检测者模块;
及一个用于接收所有检测者模块汇报的状态视图,并根据状态视图来判断被检测者模块的故障行为并作出裁决的协调者模块。
本发明同现有技术相比,其优点在于:
1,故障检测的时效性更高;
2,故障检测的准确性更高;
3,能够解决在网络分区下故障检测问题,避免分布式证券交易系统在网络分区故障下多主节点的故障。
附图说明
图1是本发明方法的模块示意图。
具体实施方式
下面结合附图对本发明作进一步说明,这种装置及方法的结构和原理对本专业的人来说是非常清楚的。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
现有的故障检测算法采用了固定的超时时限,这导致了该算法在故障检测时存在故障不能及时检测出的情况,在网络带宽压力较大的时候会导致故障检测出错。应用在证券交易系统上时,在出现网络分区的情况下,会导致在一个分布式证券交易系统中存在两个主节点的情况,最终导致业务数据错乱,而采用本申请的方法,则不存在这些问题。
首先,针对进程崩溃和消息丢失类型的故障可以采用超时判断的原理方法。传统的超时判断的方法一般会设置一个固定的超时周期。在超时周期内没有收到心跳消息就认为对端进程失效了,这样的算法在逻辑上简单易懂也易于实现,但是对进程状态的检测却是非常武断的。因为在分布式系统内部消息在传输时要经过一段未知的延迟才能到达相应的节点,采用固定周期判断存在误判的可能。采用延迟上限来做为固定超时时间虽然可以避免超时误判的可能性,但一般来所延迟上线还是一个比较宽泛的值,这个宽泛的值会导致故障检测判断的不及时。
为此我们需要设计一个兼顾准确性和及时性的超时判断算法,超时判断算法的核心就是超时时限的计算。采用动态自适应的超时时限可以避免固定时限带来的问题,能够在相对判断准确的情况下及时发现故障。适用于大规模分布式系统的基于统计模型的动态自适应的超时判断算法存在一定的概率性,对于高可靠的证券交易系统不是合适。因此我们提出了一个不需要依赖统计模型的动态自适应超时时限计算方法。该方法使用了适应性安全时间余量和心跳消息的发送周期,具体超时时限的公式描述如公式a:
tok+1=tek+1+tαk+1(a)
公式中tok+1是第k+1次心跳消息的超时时限,tαk+1是第k+1次心跳消息的自适应安全余量,为了更准确地判断超时,对于tek+1和tαk+1进行了动态自适应调整。tek+1心跳到达时间由心跳发送时间和心跳消息传输延迟时间组成,对于心跳发送时间由心跳发送方确定,所以只有不确定的心跳消息传输延迟可以动态判断调整。对于基于组通信的分布式交易系统来说心跳消息传输延迟在一般情况下抖动还是比较小的,所有我们可以采用最近n次心跳消息传输延迟的算术平均值当作下次传输延迟的预计期望值,如公式b所示。
公式b中ti是第i次收到心跳消息的时间,tsi是第i次心跳消息发送的时间,tsk+1是第k+1次心跳消息发送的时间。心跳消息的接收端在接收到最近的n个心跳消息后即可以根据公式b计算出下次心跳时限的期望值tek+1,在没有接受到n个心跳消息之前可以用固定心跳间隔来计算期望值tek+1。
适应性安全余量主要是受网络传输的延迟影响,当网络比较拥塞的时候,传输的延迟变大,这是安全余量要随之增大;当网络流量比较小的时候,传输速度比较快,安全余量可以随之适当减小。对于分布式证券交易系统这样的网络结构相对简单,可靠性高,无复杂的通信协议,并且计算节点规模不是很大,网络带宽比较大,传输延迟比较小且传输稳定。所以自适应安全余量可以根据前n次估算误差的算术平均值和固定常量ξ来计算,如公式c所示。
在公式c中,ti是第i次实际心跳时限,toi是第i次估计期望心跳时限。通过n次心跳消息的接收就能计算出第n+1次的自适应安全余量。
再者,在传统的故障检测算法中,一般都假设一个故障检测者模块和一个故障被检测者模块,但是在证券交易系统中为了保证系统的高可用,一般对于同一个服务都会有多个服务进程副本,因此也存在着多个故障检测者模块和多个故障被检测者模块。这样在每一个故障检测者模块中都有一个同一组服务进程的状态视图。故障被检测者模块在心跳消息中加入进程组状态信息,如此故障检测者模块就可以通过每一个心跳消息。
在分布式证券交易系统的自适应故障检测算法包含3个类型的模块:被检测者模块、检测者模块和协调者模块,如图1所示。每个检测者模块负责组内所有被检测者模块的状态检测,一个组内只有一个协调者模块,其在被检测者模块故障发生时做出最终的裁决。检测者模块在启动的n个心跳消息周期内,其检测行为会依赖初始设置的值,但随着运行时间不断变长,初始设置对超时时限期望值的影响将渐渐消失,检测行为和检测质量将趋于稳定,故障检测者模块将运行在一个自适应的阶段。
自适应故障检测算法根据3个不同的模块分为3个部分:第1部分被检测者模块m,实现心跳消息的定时发送;第2部分检测者模块s,来计算和优化每一个被检测者模块m预期的心跳消息到达时间te和心跳消息超时时限to以及自适应安全余量t,并接收m的心跳消息维护m的状态,向协调者汇报检测者模块和被检测者模块的状态视图;第3部分协调者模块a,主要是接收m汇报的状态视图,根据状态视图来判断确认m的故障行为并为组成员的状态切换做出最终决定。
实施例
参见图1,所述的装置包括:若干用于定时向检测者模块发送包括进程组状态信息的心跳消息的被检测者模块,若干用于接收所有被检测者模块的心跳消息,并计算每一被检测者模块每次心跳消息的超时时限,若在任一次心跳消息的超时时限内未接收到被检测者模块发出的心跳消息,则向协调者模块汇报被检测者模块的状态视图的检测者模块,及一个用于接收所有检测者模块汇报的状态视图,并根据状态视图来判断被检测者模块的故障行为并作出裁决的协调者模块。所有被检测者模块均按顺序进行编号,并且所有组成员,即所有被检测者模块、检测者模块及协调者模块,按照编号在状态视图中为各被检测者模块记录有状态情况,通信组的状态视图的编号表示了通信组成员范围。
任一被检测者模块m的工作流程:
1)初始化参数心跳间隔δ。
2)当前时间为ti+δ时,发送心跳消息mi,ti=ti+δ,δ为心跳间隔。
任一检测者模块的工作流程:
1)初始化参数n,心跳间隔δ,安全余量的常量ξ,其中n为心跳消息的序号,如第一次接收到的心跳消息的序号n=1。
2)接收到来自被检测者模块m的心跳消息mi,并记录接收时间ti。
3)如果i≥km,其中i为预期接收的心跳消息序号,km为接受到的心跳消息的序号,那么km=i。
4)根据公式b,计算出tek+1,根据公式c,计算出tαk+1。
5)根据公式a,计算出tok+1。
6)将被检测者模块m的状态修改为活跃。
7)如果在tok+1的时限内没有收到被检测者模块m的心跳消息,则将被检测者模块m的状态修改为怀疑故障,并向协调者发送当前所有被检测者的状态视图。
8)在收到协调者模块a的状态收集通知后,发送当前所有被检测者的状态视图。
协调者模块a的工作流程:
1)初始化视图收敛周期ψ,ψ要大于2δ。
2)接收到检测者s发送的状态视图后,协调者模块a判断被检测者模块m是否包含关键进程,协调者模块a记录有每个被检测者模块的状态,并预先对包含有关键进程的被检测者模块作有状态记录。
3)协调者模块a的本地视图包含了所有被检测者模块的状态信息。如果怀疑故障的被检测者模块m包含有关键进程,则更新本地视图中的该被检测者模块m至故障状态,并转步骤5。
4)如果否,则更新本地视图状态为正常。
5)等待收敛周期ψ后,向检测者发送状态收集通知。
6)收集所有检测者模块的状态视图,判断关键进程的状态。其中每个检测者模块的状态视图中均包含了所有被检测者模块的状态。
7)如果多数状态为活跃,则判定关键进程的状态为活跃,更新本地视图为正常状态。
8)如果多数状态为故障,则判定关键进程的状态为故障,并通知所有组成员更新视图状态和编号,进入新的故障检测状态。
- 还没有人留言评论。精彩留言会获得点赞!