基于光照生成对抗网络的课堂听课异常检测方法与流程
本发明属于异常检测技术领域,更为具体地讲,涉及一种基于光照生成对抗网络的课堂听课异常检测方法。
背景技术:
计算机异常检测是在不需要人为干预情况下,利用计算机视觉理论和视频分析的方法对摄像头等监控设备记录的视频序列进行分析,实现对结构化场景中目标的定位、识别和跟踪,并在此基础上分析和判断目标的行为,得出对图像内容含义的理解以及对客观场景的解释,并从而指导和规划行动。
现有的异常检测方法常采用特定的统计分析方法、以及深度学习方法。申请号为201510141935.6的中国专利《一种用于复杂结构化场景的人群运动轨迹异常检测方法》通过提取监控视频历史数据中复杂结构化场景内的人群运动轨迹并对人群运动轨迹进行分段,进行基于最大最小距离的多中心聚类算法的学习,使用基于lof算法的异常检测,高效、实用地解决了人群运动轨迹检测问题。申请号为201410795393.x的中国专利《基于时间递归神经网络的人群异常检测和定位系统及方法》使用时间递归神经网络对采集的样本数据进行分析训练以完成异常检测。申请号为201710305833.2的中国专利《一种视频异常检测方法》利用灰度投影算法完成全局运动估计,有效地实现图像抖动检测及抖动程度估计。该方法常常容易陷入局部最优解,当训练数据集大、训练网络复杂时,训练时间往往很高,代价过大,效率过低。
目前异常检测的主要应用领域包括智能交通、智能监控等。申请号为201410799626.3的中国专利《一种交通异常检测方法及系统》将正常交通视频图像序列分为视频块序列,检测视频块序列中的镜头数量,建立视频块序列中的镜头数量的高斯模型,利用高斯模型对测试交通视频图像进行异常检测。申请号为201510670786.2的中国专利《基于运动重构技术的交通场景异常检测方法》利用运动模式的空间位置信息,探索了不同运动模式间的空间结构信息,解决了现有的异常检测方法对该特定场景的不适用性。申请号为201710131835.4的中国专利《基于isolationforest的城市道路交通异常检测方法》以道路为检测对象,根据道路在不同时段的平均运行速度划分不同类别数据集,基于每个数据集训练一个isolationforest,通过检测道路速度在isolationforest中到根节点的距离来判断道路是否异常。申请号为201510046984.1的中国专利《一种基于车辆轨迹相似性的异常检测方法》再计算典型轨迹与该类车辆轨迹的相似性度量建立偏差统计模型,得到相似性度量的置信区间,最后计算待测轨迹与典型轨迹的相似性度量,根据置信区间判断是否异常。但该方法复杂,场景适应度低,需要大量的真实数据集,数据成本大。
现有的异常检测方法还未涉及课堂教学监考过程中的听课状态分析,本发明的任务与现有的课堂视频、头部姿态数据与现有异常检测方法不同。本发明在方法实现上与现有的异常检测方法区别在于,在深度学习方法的基础上,不仅使用3d模型和光照渲染生成样本,而且使用基于生成对抗网络,生成光照优化后的头部姿态数据,解决光照渲染头部位置图像与真实头部位置图像数据特征的不一致性。使用生成对抗样本能够有效的提高头部姿态检测的准确性,并通过对头部姿态检测的统计分析,实现课堂听课异常状态判断。
技术实现要素:
为了弥补已有技术的不足,本发明提出一种基于光照生成对抗网络的课堂听课异常检测方法。
本发明采用的技术方案是:
一种基于光照生成对抗网络的课堂听课异常检测方法,其特征在于:包括有以下步骤:
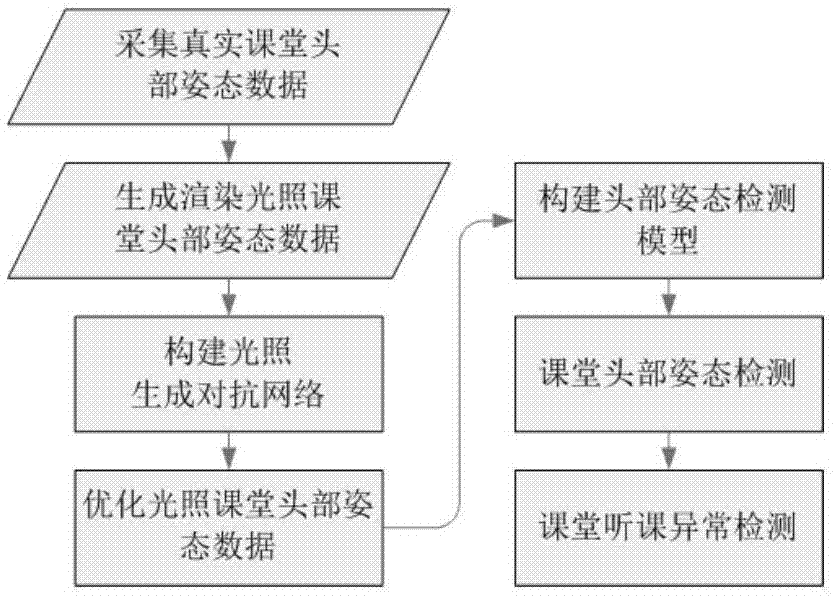
步骤s1:采集真实课堂头部姿态数据:
采集并获取真实课堂中的视频帧,构建头部位置检测模型,标记候选头部位置图像,获取训练集和训练参数;
步骤s2:渲染光照课堂头部姿态数据:
根据设计的课堂学生3d模型,设置模型中头部姿态、光照条件、摄像机拍摄角度参数,多次渲染,获取渲染光照下的课堂图像集合;
步骤s3:构建光照生成对抗网络:
根据11层光照生成对抗网络,求解光照生成对抗网络的目标损失,训练光照生成对抗网络;
步骤s4:产生生成对抗样本:
使用真实课堂头部姿态数据,获取不同光照条件、拍摄角度、不同人物的光照渲染头部位置图像,使用训练后的光照生成对抗网络模型参数,生成优化后的的渲染光照头部位置图像,计算光照优化头部位置图像的判决得分,设置逼真图像阈值,选取大于阈值的作为逼真的渲染光照头部位置图像;
步骤s5:构建头部姿态检测模型:
将逼真的渲染光照头部位置图像作为头部姿态检测的训练数据,类别标记头部姿态检测的训练数据,设置头部姿态检测模型,通过训练获得头部姿态检测模型的参数;
步骤s6:课堂头部姿态检测:
使用生成对抗头部姿态检测模型,实现课堂头部姿态检测;
步骤s7:课堂听课异常检测:
输入课堂实时采集视频,提取视频帧,使用构建的模型和训练参数,设置听课异常检测机制,获得不同状态学生的比例。
下面详细描述基于光照生成对抗网络的课堂听课异常检测方法的各个步骤。
所述的采集真实课堂头部姿态数据,包括以下步骤:
步骤s1-1:采集真实课堂视频;
步骤s1-2:获取课堂视频中的视频帧,并进行滑动窗口采样,获得候选头部位置图像,每个头部位置图像包含rgb三层颜色通道;
步骤s1-3:构建头部位置检测模型,共8层的神经网络模型,其中前6层为卷积神经网络,第7层和第8层为全连接网络;
步骤s1-3-1:前6层卷积神经网络使用相同的参数,每层的滤波器尺寸为3*3,滤波器数量为256,池化方法为求和池化,即256通道中响应值求和结果,保留为最后的输出响应,激励函数形式为relu函数;
步骤s1-3-2:第7层的全连接层,将256特征神经元映射为4096特征神经元,全连接映射参数矩阵为256*4096;
步骤s1-3-3:第8层的全连接层,将4096特征神经元映射为单个神经元,全连接映射参数矩阵为4096*2,其中,最后输出层神经元的类别为1表示是头部位置图像,0表示不是头部位置图像;
步骤s1-4:对步骤s1-2获取的候选头部位置图像进行标记,获得头部训练数据,和非头部训练数据,构建头部位置检测训练集;
步骤s1-5:使用步骤s1-4获取的头部位置检测训练集,对步骤s1-3构建的头部位置检测模型进行训练,获得训练后的头部位置检测模型参数wheadpos;
步骤s1-6:对步骤s1-2获取的候选头部位置图像,使用训练后的头部位置检测模型参数wheadpos,进行人脸判断,可以辨别出头部和非头部,从而可以提取测试视频的真实头部位置图像realheadpos。
所述的渲染光照课堂头部姿态数据,包括以下步骤:
步骤s2-1:设计课堂学生3d模型;
步骤s2-2:在课堂学生3d模型中设置学生听课的头部姿态;
步骤s2-3:在课堂学生3d模型中设置光照条件;
步骤s2-4:在课堂学生3d模型中设置摄像机拍摄角度;
步骤s2-5:根据步骤s2-1,步骤s2-2,步骤s2-3,步骤s2-4设置的条件,进行多次拍摄,获取渲染光照下的课堂图像集合;
步骤s2-6:对渲染光照下的课堂图像集合,使用步骤s1-5训练后的头部位置检测模型参数wheadpos,获得光照渲染头部位置图像renderheadpos。
所述的构建光照生成对抗网络,包括以下步骤:
步骤s3-1:设置光照生成对抗网络,其中前4层为光照生成优化网络,第5层到第11层为光照生成判决网络;
步骤s3-1-1:设置光照生成优化网络,使用4层的卷积神经网络;
步骤s3-1-1-1:在优化网络中,每层的卷积神经网络使用相同的参数,每层的滤波器尺寸为3*3,滤波器数量为256,池化方法为最大池化,即256通道中最大的响应值保留为最后的输出响应,激励函数形式为relu函数;
步骤s3-1-1-2:将光照生成优化网络中的所有参数,记做wref;
步骤s3-1-1-3:输入图像经过光照生成优化网络,会得到优化后的图像,优化后的图像和原始图像分辨率相同;
步骤s3-1-2:设置光照生成判决网络,使用7层的神经网络,其中前5层为卷积神经网络,第6层、第7层为全连接神经网络;
步骤s3-1-2-1:在判决网络中,前5层使用相同的参数,每层的滤波器尺寸为3*3,滤波器数量为64,池化方法为求和池化,即64通道中响应值求和结果,保留为最后的输出响应,激励函数形式为relu函数;
步骤s3-1-2-2:第6层的全连接层,将256特征神经元映射为4096特征神经元,全连接映射参数矩阵为256*4096;
步骤s3-1-2-3:第7层的全连接层,将4096特征神经元映射为单个神经元,全连接映射参数矩阵为4096*2,其中,最后输出层神经元的类别yreal,yreal为1表示是真实头部位置图像,0表示光照优化头部位置图像;
步骤s3-1-2-4:将光照生成判决网络中的所有参数,记做wjudge;
步骤s3-1-2-5:将一张光照渲染图像,输入光照生成判决网络,可以判决出其得分较接近于0;将一张真实头部位置图像,输入光照生成判决网络,可以判决出其得分较接近于1;
步骤s3-2:求解光照生成对抗网络的目标损失;
步骤s3-2-1:计算光照渲染图像的优化损失;
步骤s3-2-1-1:将光照渲染头部位置图像renderheadpos,输入步骤s3-1-1光照生成优化网络,获得光照优化头部位置图像refineheadpos;
步骤s3-2-1-2:求解光照渲染头部位置图像的优化损失,即光照优化头部位置图像refineheadpos和光照渲染头部位置图像renderheadpos的距离,使用1范数来计算2张图像之间的距离,即
dref=||renderheadpos-refineheadpos||1
步骤s3-2-2:计算图像的判决损失;
步骤s3-2-2-1:构建头部位置图像集合imgheadpos,其中包含真实头部位置图像realheadpos和光照优化头部位置图像refineheadpos;
步骤s3-2-2-2:根据图像类型,对头部位置图像集合imgheadpos设置图像标记yreal,yreal为1表示是真实头部位置图像,0表示光照优化头部位置图像;
步骤s3-2-2-3:将头部位置图像imgheadpos,输入步骤s3-1-2光照生成判决网络,获得判决得分sjudge;
步骤s3-2-2-4:根据判决得分和图像标记,并求解一张图像的判决损失
步骤s3-2-3:求解光照渲染头部位置图像的总体损失,总体损失包括优化损失和判决损失2个部分,光照渲染头部位置图像的总体损失为
loss=dref+djudge
步骤s3-3:训练光照生成对抗网络;
步骤s3-3-1:训练光照生成优化网络;
步骤s3-3-1-1:输入光照渲染头部位置图像renderheadpos;
步骤s3-3-1-2:计算光照优化头部位置图像refineheadpos;
步骤s3-3-1-3:计算光照优化头部位置图像的判决得分sjudge;
步骤s3-3-1-4:根据步骤步骤s3-2-3,计算光照渲染头部位置图像的总体损失loss;
步骤s3-3-1-5:调整光照生成优化的模型参数,并根据光照渲染头部位置图像的总体损失loss和梯度下降方法确定更新后的光照生成优化模型参数
步骤s3-3-2:训练光照生成判决网络;
步骤s3-3-2-1:重复步骤s3-2-2-4计算图像集合中所有图像的判决损失djudge;
步骤s3-3-2-2:调整光照生成判决的模型参数,并根据梯度下降方法确定更新后的光照生成判决模型参数
步骤s3-3-3:交替重复步骤s3-3-1和s3-3-2,迭代优化光照生成优化模型参数
步骤s3-3-4:将收敛后的光照生成优化模型参数
所述的产生生成对抗样本,包括以下步骤:
步骤s4-1:使用步骤s2,获得不同光照条件,不同拍摄视角,不同人物的光照渲染头部位置图像renderheadpos;
步骤s4-2:使用步骤s3-3-4训练后的光照生成对抗网络模型参数,生成优化后的的渲染光照头部位置图像refineheadpos;
步骤s4-3:使用光照生成判决模型,计算光照优化头部位置图像的判决得分sjudge;
步骤s4-4:设置逼真图像阈值,将判决得分sjudge大于0.5的作为逼真的渲染光照头部位置图像。
所述的构建头部姿态检测模型,包括以下步骤:
步骤s5-1:将逼真的渲染光照头部位置图像,和步骤s1-6获得的真实头部位置图像,均作为头部姿态检测的训练数据;
步骤s5-2:对头部姿态检测的训练数据进行类别标记ylisten,头部姿态训练数据中包括听课样本和不听课样本,其中ylisten为1表示认真听课,ylisten为0表示不听课;
步骤s5-3:设置头部姿态检测模型,使用7层的神经网络,其中前5层为卷积神经网络,第6层、第7层为全连接神经网络;
步骤s5-3-1:在判决网络中,前5层使用相同的参数,每层的滤波器尺寸为3*3,滤波器数量为64,池化方法为求和池化,即64通道中响应值求和结果,保留为最后的输出响应,激励函数形式为relu函数;
步骤s5-3-2:第6层的全连接层,将256特征神经元映射为4096特征神经元,全连接映射参数矩阵为256*4096;
步骤s5-3-3:第7层的全连接层,将4096特征神经元映射为单个神经元,全连接映射参数矩阵为4096*2,其中,最后输出层神经元的类别ylisten,其中ylisten为1表示认真听课,ylisten为0表示不听课;
步骤s5-4:使用步骤s5-1和步骤s5-2构建的训练集,对步骤s5-3构建的神经网络模型进行训练,获得训练后的头部姿态检测模型的参数wlisten。
所述的课堂头部姿态检测,包括以下步骤:
步骤s6-1:输入课堂实时采集视频,并提取视频帧;
步骤s6-2:使用步骤s1-6训练后的头部位置检测模型参数wheadpos,提取真实头部位置图像realheadpos;
步骤s6-3:使用步骤s5-4训练后的头部姿态检测模型的参数wlisten,计算学生头部姿态得分;
步骤s6-4:根据学生头部姿态得分,判断课堂学生是否在听课,其中ylisten为1表示认真听课,ylisten为0表示不听课;
步骤s6-5:对视频帧中的所有学生进行遍历,判断所有人的听课状态,计算不听课人数的比例;
步骤s6-6:设置不听课比例的状态阈值,如果全部不听课比例大于等于5%,则输出不听课状态,如果全部不听课比例小于5%,则输出正常听课状态。
所述的课堂听课异常检测,包括以下步骤:
步骤s7-1:输入实时监控视频,读取视频帧;
步骤s7-2:判断视频是否结束,如果监控视频结束,则结束课堂听课异常状态的实时判断;
步骤s7-3:如果监控视频仍然有效,使用步骤s6-6,对连续视频帧的不听课状态进行检测,提取每帧的不听课状态;
步骤s7-4:如果没有出现不听课状态,则清除不听课状态,清除不听课状态的开始时间,清除课堂听课异常状态;
步骤s7-5:如果出现不听课状态,则进行课堂听课异常判断;
步骤s7-5-1:如果首次出现不听课状态,则初始化当前时间为不听课状态的开始时间,初始化不听课持续时间为1帧;
步骤s7-5-2:如果不是首次出现不听课状态,则更新不听课状态的持续时间,增加持续时间1帧;
步骤s7-5-3:如果不听课状态的持续时间达到50帧,则输出现课堂听课异常状态;
步骤s7-6:重复步骤s7-1到步骤s7-5实现对课堂听课实时数据的分析,并提供课堂听课异常状态检测,实现实时判断。
与现有技术相比,本发明的优势如下:
(1)针对背景环境复杂,存在大量非头部区域的无效信息干扰的问题,本发明通过使用深度神经网络,提高了对头部区域定位的准确性,降低非头部区域对不听课状态判断的干扰。
(2)头部姿态数据会随着头部姿态、光照条件、摄像机拍摄拍摄角度等因素的变化而变化,从而对头部姿态数据的准确性造成一定影响。本发明通过3d模型和环境光渲染方法,多次生成渲染光照下的课堂图像集合,为头部姿态检测模型提供了更多的数据样本,有利于模型的成分训练。
(3)通过光照生成对抗网络,对多次生成渲染光照进行优化,生成更逼真的对抗样本,避免渲染光照样本与真实数据特征的不一致性,提高模型训练的有效性。本发明基于生成对抗网络,能够实现头部姿态的有效检测,有利于课堂听课状态的判断,有利于提高持续时间的异常听课状态判断的准确性。
附图说明
下面结合附图对本发明进一步说明:
图1为基于光照生成对抗网络的课堂听课异常检测方法的流程图。
图2(a)为头部位置提议模型。
图2(b)为采集的真实课堂头部姿态数据。
图3为课堂学生3d模型与光照渲染环境。
图4(a)为光照生成对抗网络模型。
图4(b)为光照优化头部位置图像。
图5为头部姿态检测模型。
图6为不听课状态检测模型。
图7为课堂异常听课状态检测模型。
具体实施方式
下面结合附图及具体实施方式详细介绍本发明。本发明为基于光照生成对抗网络的课堂听课异常检测方法,具体流程如图1所示,本发明的实现方案分为以下步骤:
步骤s1:采集真实课堂头部姿态数据,具体操作步骤包括:
步骤s1-1:采集真实课堂视频;
步骤s1-2:获取课堂视频中的视频帧,并进行滑动窗口采样,获得候选头部位置图像,每个头部位置图像包含rgb三层颜色通道;
步骤s1-3:构建头部位置检测模型,共8层的神经网络模型,其中前6层为卷积神经网络,第7层和第8层为全连接网络,如图2(a);
步骤s1-3-1:前6层卷积神经网络使用相同的参数,每层的滤波器尺寸为3*3,滤波器数量为256,池化方法为求和池化,即256通道中响应值求和结果,保留为最后的输出响应,激励函数形式为relu函数;
步骤s1-3-2:第7层的全连接层,将256特征神经元映射为4096特征神经元,全连接映射参数矩阵为256*4096;
步骤s1-3-3:第8层的全连接层,将4096特征神经元映射为单个神经元,全连接映射参数矩阵为4096*2,其中,最后输出层神经元的类别为1表示是头部位置图像,0表示不是头部位置图像;
步骤s1-4:对步骤s1-2获取的候选头部位置图像进行标记,获得头部训练数据,和非头部训练数据,构建头部位置检测训练集;
步骤s1-5:使用步骤s1-4获取的头部位置检测训练集,对步骤s1-3构建的头部位置检测模型进行训练,获得训练后的头部位置检测模型参数wheadpos;
步骤s1-6:对步骤s1-2获取的候选头部位置图像,使用训练后的头部位置检测模型参数wheadpos,进行人脸判断,可以辨别出头部和非头部,从而可以提取测试视频的真实头部位置图像realheadpos,如图2(b);
步骤s2:生成渲染光照课堂头部姿态数据,具体操作步骤包括:
步骤s2-1:设计课堂学生3d模型;
步骤s2-2:在课堂学生3d模型中设置学生听课的头部姿态;
步骤s2-3:在课堂学生3d模型中设置光照条件;
步骤s2-4:在课堂学生3d模型中设置摄像机拍摄角度;
步骤s2-5:根据步骤s2-1,步骤s2-2,步骤s2-3,步骤s2-4,步骤s2-5设置的条件,如图3,进行多次拍摄,获取渲染光照下的课堂图像集合;
步骤s2-6:对渲染光照下的课堂图像集合,使用步骤s1-5训练后的头部位置检测模型参数wheadpos,获得光照渲染头部位置图像renderheadpos;
步骤s3:针对听课姿态检测,构建光照生成对抗网络,具体操作步骤包括:
步骤s3-1:设置光照生成对抗网络,其中前4层为光照生成优化网络,第5层到第11层为光照生成判决网络,如图4(a);
步骤s3-1-1:设置光照生成优化网络,使用4层的卷积神经网络;
步骤s3-1-1-1:在优化网络中,每层的卷积神经网络使用相同的参数,每层的滤波器尺寸为3*3,滤波器数量为256,池化方法为最大池化,即256通道中最大的响应值保留为最后的输出响应,激励函数形式为relu函数;
步骤s3-1-1-2:将光照生成优化网络中的所有参数,记做wref;
步骤s3-1-1-3:输入图像经过光照生成优化网络,会得到优化后的图像,优化后的图像和原始图像分辨率相同;
步骤s3-1-2:设置光照生成判决网络,使用7层的神经网络,其中前5层为卷积神经网络,第6层、第7层为全连接神经网络;
步骤s3-1-2-1:在判决网络中,前5层使用相同的参数,每层的滤波器尺寸为3*3,滤波器数量为64,池化方法为求和池化,即64通道中响应值求和结果,保留为最后的输出响应,激励函数形式为relu函数;
步骤s3-1-2-2:第6层的全连接层,将256特征神经元映射为4096特征神经元,全连接映射参数矩阵为256*4096;
步骤s3-1-2-3:第7层的全连接层,将4096特征神经元映射为单个神经元,全连接映射参数矩阵为4096*2,其中,最后输出层神经元的类别yreal,yreal为1表示是真实头部位置图像,0表示光照优化头部位置图像;
步骤s3-1-2-4:将光照生成判决网络中的所有参数,记做wjudge;
步骤s3-1-2-5:将一张光照渲染图像,输入光照生成判决网络,可以判决出其得分较接近于0;将一张真实头部位置图像,输入光照生成判决网络,可以判决出其得分较接近于1;
步骤s3-2:求解光照生成对抗网络的目标损失;
步骤s3-2-1:计算光照渲染图像的优化损失;
步骤s3-2-1-1:将光照渲染头部位置图像renderheadpos,输入步骤s3-1-1光照生成优化网络,获得光照优化头部位置图像refineheadpos;
步骤s3-2-1-2:求解光照渲染头部位置图像的优化损失,即光照优化头部位置图像refineheadpos和光照渲染头部位置图像renderheadpos的距离,使用1范数来计算2张图像之间的距离,即
dref=||renderheadpos-refineheadpos||1
步骤s3-2-2:计算图像的判决损失;
步骤s3-2-2-1:构建头部位置图像集合imgheadpos,其中包含真实头部位置图像realheadpos和光照优化头部位置图像refineheadpos;
步骤s3-2-2-2:根据图像类型,对头部位置图像集合imgheadpos设置图像标记yreal,yreal为1表示是真实头部位置图像,0表示光照优化头部位置图像;
步骤s3-2-2-3:将头部位置图像imgheadpos,输入步骤s3-1-2光照生成判决网络,获得判决得分sjudge;
步骤s3-2-2-4:根据判决得分和图像标记,并求解一张图像的判决损失
步骤s3-2-3:求解光照渲染头部位置图像的总体损失,总体损失包括优化损失和判决损失2个部分,光照渲染头部位置图像的总体损失为
loss=dref+djudge
步骤s3-3:训练光照生成对抗网络;
步骤s3-3-1:训练光照生成优化网络;
步骤s3-3-1-1:输入光照渲染头部位置图像renderheadpos;
步骤s3-3-1-2:计算光照优化头部位置图像refineheadpos;
步骤s3-3-1-3:计算光照优化头部位置图像的判决得分sjudge;
步骤s3-3-1-4:根据步骤步骤s3-2-3,计算光照渲染头部位置图像的总体损失loss;
步骤s3-3-1-5:调整光照生成优化的模型参数,并根据光照渲染头部位置图像的总体损失loss和梯度下降方法确定更新后的光照生成优化模型参数
步骤s3-3-2:训练光照生成判决网络;
步骤s3-3-2-1:重复步骤s3-2-2-4计算图像集合中所有图像的判决损失djudge;
步骤s3-3-2-2:调整光照生成判决的模型参数,并根据梯度下降方法确定更新后的光照生成判决模型参数
步骤s3-3-3:交替重复步骤s3-3-1和s3-3-2,迭代优化光照生成优化模型参数
步骤s3-3-4:将收敛后的光照生成优化模型参数
步骤s4:优化光照课堂头部姿态数据,产生生成对抗样本,具体操作步骤包括:
步骤s4-1:使用步骤s2,获得不同光照条件,不同拍摄视角,不同人物的光照渲染头部位置图像renderheadpos;
步骤s4-2:使用步骤s3-3-4训练后的光照生成对抗网络模型参数,生成优化后的的渲染光照头部位置图像refineheadpos;
步骤s4-3:使用光照生成判决模型,计算光照优化头部位置图像的判决得分sjudge;
步骤s4-4:设置逼真图像阈值,将判决得分sjudge大于0.5的作为逼真的渲染光照头部位置图像,如图4(b);
步骤s5:使用生成对抗数据,构建头部姿态检测模型,如图5,具体操作步骤包括:
步骤s5-1:将逼真的渲染光照头部位置图像,和步骤s1-6获得的真实头部位置图像,均作为头部姿态检测的训练数据;
步骤s5-2:对头部姿态检测的训练数据进行类别标记ylisten,头部姿态训练数据中包括听课样本和不听课样本,其中ylisten为1表示认真听课,ylisten为0表示不听课;
步骤s5-3:设置头部姿态检测模型,使用7层的神经网络,其中前5层为卷积神经网络,第6层、第7层为全连接神经网络;
步骤s5-3-1:在判决网络中,前5层使用相同的参数,每层的滤波器尺寸为3*3,滤波器数量为64,池化方法为求和池化,即64通道中响应值求和结果,保留为最后的输出响应,激励函数形式为relu函数;
步骤s5-3-2:第6层的全连接层,将256特征神经元映射为4096特征神经元,全连接映射参数矩阵为256*4096;
步骤s5-3-3:第7层的全连接层,将4096特征神经元映射为单个神经元,全连接映射参数矩阵为4096*2,其中,最后输出层神经元的类别ylisten,其中ylisten为1表示认真听课,ylisten为0表示不听课;
步骤s5-4:使用步骤s5-1和步骤s5-2构建的训练集,对步骤s5-3构建的神经网络模型进行训练,获得训练后的头部姿态检测模型的参数wlisten;
步骤s6:使用生成对抗头部姿态检测模型,实现课堂头部姿态检测和不听课状态检测,如图6,具体操作步骤包括:
步骤s6-1:输入课堂实时采集视频,并提取视频帧;
步骤s6-2:使用步骤s1-6训练后的头部位置检测模型参数wheadpos,提取真实头部位置图像realheadpos;
步骤s6-3:使用步骤s5-4训练后的头部姿态检测模型的参数wlisten,计算学生头部姿态得分;
步骤s6-4:根据学生头部姿态得分,判断课堂学生是否在听课,其中ylisten为1表示认真听课,ylisten为0表示不听课;
步骤s6-5:对视频帧中的所有学生进行遍历,判断所有人的听课状态,计算不听课人数的比例;
步骤s6-6:设置不听课比例的状态阈值,如果全部不听课比例大于等于5%,则输出不听课状态,如果全部不听课比例小于5%,则输出正常听课状态;
步骤s7:使用生成对抗头部姿态检测模型,实现课堂听课异常检测,如图7,具体操作步骤包括:
步骤s7-1:输入实时监控视频,读取视频帧;
步骤s7-2:判断视频是否结束,如果监控视频结束,则结束课堂听课异常状态的实时判断;
步骤s7-3:如果监控视频仍然有效,使用步骤s6-6,对连续视频帧的不听课状态进行检测,提取每帧的不听课状态
步骤s7-4:如果没有出现不听课状态,则清除不听课状态,清除不听课状态的开始时间,清除课堂听课异常状态
步骤s7-5:如果出现不听课状态,则进行课堂听课异常判断
步骤s7-5-1:如果首次出现不听课状态,则初始化当前时间为不听课状态的开始时间,初始化不听课持续时间为1帧
步骤s7-5-2:如果不是首次出现不听课状态,则更新不听课状态的持续时间,增加持续时间1帧
步骤s7-5-3:如果不听课状态的持续时间达到50帧,则输出现课堂听课异常状态
步骤s7-6:重复步骤s7-1到步骤s7-5实现对课堂听课实时数据的分析,并提供课堂听课异常状态检测,实现实时判断。
- 还没有人留言评论。精彩留言会获得点赞!