车辆选型的方法及装置与流程
本发明涉及汽车技术领域,尤其涉及一种车辆选型的方法及装置。
背景技术:
由于汽车选型的复杂性、多因素性,针对不断变化的汽车需求,不同车型的汽车需求不同的整车性能指标,从而会选择不同的选型方案,同时,汽车内的零部件体系也需进行不断的改进及优化,以提高市场竞争力。
相关技术中,工程师在寻找与整车性能指标相匹配的选型方案过程中,通常由依靠自身经验与标杆分析的方法来进行选择指导工作,具有一定局限性;针对不同的选型方案,每一次车辆内零部件的变更,都需工程师重新进行仿真工作,以筛选出最优选型方案,导致车辆开发周期过长;针对现有车型,车辆的零部件体系通常以供应商能力与工程师经验为主体进行指导改进及优化,存在一定的偶然性,往往只能产生局部最优结果,无法产生车辆整体最优结果。
技术实现要素:
本发明旨在至少在一定程度上解决相关技术中的技术问题之一。
为此,本发明的第一个目的在于提出一种车辆选型的方法,针对不同的整车性能指标、不同的选型方案,可准确、快速的自动选择出符合整车性能指标的最优选型方案,缩短车辆的开发周期,并能针对现有车型对零部件系统提出准确的改进目标及优化方案。
本发明的第二个目的在于提出一种车辆选型的装置。
为达上述目的,本发明第一方面实施例提出了一种车辆选型的方法,包括:
获取车辆的当前仿真状态;
根据所述当前仿真状态和各零部件选型动作,分别生成所述车辆在所述当前仿真状态下执行各所述零部件选型动作所获得的瞬时奖赏值;
根据各所述瞬时奖赏值,更新所述车辆在所述当前仿真状态下执行各所述零部件选型动作所获得的绝对奖赏值;
根据更新后的各所述绝对奖赏值,确定目标选型方案。
本发明实施例提出的车辆选型的方法,首先获取车辆的当前仿真状态,根据当前仿真状态和各零部件选型动作,分别生成车辆在当前仿真状态下执行各零部件选型动作所获得的瞬时奖赏值,接着,根据各瞬时奖赏值,更新车辆在当前仿真状态下执行各零部件选型动作所获得的绝对奖赏值,然后,根据更新后的各绝对奖赏值,确定目标选型方案。根据当前仿真状态和各零部件选型动作来获取瞬时奖赏值,根据瞬时奖赏值更新绝对奖赏值,最后依据绝对奖赏值来确定目标选型方案,针对不同的整车性能指标、不同的选型方案,可准确、快速的自动选择出符合整车性能指标的最优选型方案,缩短车辆的开发周期,并能针对现有车型对零部件系统提出准确的改进目标及优化方案。
根据本发明的一个实施例,所述根据所述当前仿真状态和各零部件选型动作,分别生成所述车辆在所述当前仿真状态下执行各所述零部件选型动作所获得的瞬时奖赏值,包括:根据所述当前仿真状态和各所述零部件选型动作,采用强化学习算法生成所述瞬时奖赏值。
根据本发明的一个实施例,所述根据所述当前仿真状态和各所述零部件选型动作,采用强化学习算法生成所述瞬时奖赏值,包括:根据所述当前仿真状态和各所述零部件选型动作,采用动作值函数学习算法生成所述瞬时奖赏值。
根据本发明的一个实施例,所述根据所述当前仿真状态和各所述零部件选型动作,采用动作值函数学习算法生成所述瞬时奖赏值,包括:采用第一预设公式,生成所述瞬时奖赏值,所述第一预设公式为:其中,所述Q*(st,at)为所述车辆在所述当前仿真状态st下,执行所述零部件选型动作at达到下一仿真状态st+1所获得的所述瞬时奖赏值;所述R=f(st,at,st+1)为根据整车性能指标预设的回报函数;所述γ为预设的折减系数;所述Q*(st+1,an)为所述车辆在所述下一仿真状态st+1下执行所述零部件选型动作an所获得的所述瞬时奖赏值;所述A为预设的零部件选型集合。
根据本发明的一个实施例,所述根据各所述瞬时奖赏值,更新所述车辆在所述当前仿真状态下执行各所述零部件选型动作所获得的绝对奖赏值,包括:采用第二预设公式,更新所述绝对奖赏值,所述第二预设公式为:Q′(st,at)=(1-α)Q(st,at)+αQ*(st,at),其中,所述Q′(st,at)为更新后的所述绝对奖赏值;所述α为预设的学习效率;所述Q(st,at)为更新前的所述绝对奖赏值。
为达上述目的,本发明第二方面实施例提出了一种车辆选型的装置,包括:
获取模块,用于获取车辆的当前仿真状态;
生成模块,用于根据所述当前仿真状态和各零部件选型动作,分别生成所述车辆在所述当前仿真状态下执行各所述零部件选型动作所获得的瞬时奖赏值;
更新模块,用于根据各所述瞬时奖赏值,更新所述车辆在所述当前仿真状态下执行各所述零部件选型动作所获得的绝对奖赏值;
确定模块,用于根据更新后的各所述绝对奖赏值,确定目标选型方案。
本发明实施例提出的车辆选型的装置,首先获取车辆的当前仿真状态,根据当前仿真状态和各零部件选型动作,分别生成车辆在当前仿真状态下执行各零部件选型动作所获得的瞬时奖赏值,接着,根据各瞬时奖赏值,更新车辆在当前仿真状态下执行各零部件选型动作所获得的绝对奖赏值,然后,根据更新后的各绝对奖赏值,确定目标选型方案。根据当前仿真状态和各零部件选型动作来获取瞬时奖赏值,根据瞬时奖赏值更新绝对奖赏值,最后依据绝对奖赏值来确定目标选型方案,针对不同的整车性能指标、不同的选型方案,可准确、快速的自动选择出符合整车性能指标的最优选型方案,缩短车辆的开发周期,并能针对现有车型对零部件系统提出准确的改进目标及优化方案。
根据本发明的一个实施例,所述生成模块具体用于:根据所述当前仿真状态和各所述零部件选型动作,采用强化学习算法生成所述瞬时奖赏值。
根据本发明的一个实施例,所述生成模块具体用于:根据所述当前仿真状态和各所述零部件选型动作,采用动作值函数学习算法生成所述瞬时奖赏值。
根据本发明的一个实施例,所述生成模块具体用于:采用第一预设公式,生成所述瞬时奖赏值,所述第一预设公式为:其中,所述Q*(st,at)为所述车辆在所述当前仿真状态st下,执行所述零部件选型动作at达到下一仿真状态st+1所获得的所述瞬时奖赏值;所述R=f(st,at,st+1)为根据整车性能指标预设的回报函数;所述γ为预设的折减系数;所述Q*(st+1,an)为所述车辆在所述下一仿真状态st+1下执行所述零部件选型动作an所获得的所述瞬时奖赏值;所述A为预设的零部件选型集合。
根据本发明的一个实施例,所述更新模块具体用于:采用第二预设公式,更新所述绝对奖赏值,所述第二预设公式为:Q′(st,at)=(1-α)Q(st,at)+αQ*(st,at),其中,所述Q′(st,at)为更新后的所述绝对奖赏值;所述α为预设的学习效率;所述Q(st,at)为更新前的所述绝对奖赏值。
附图说明
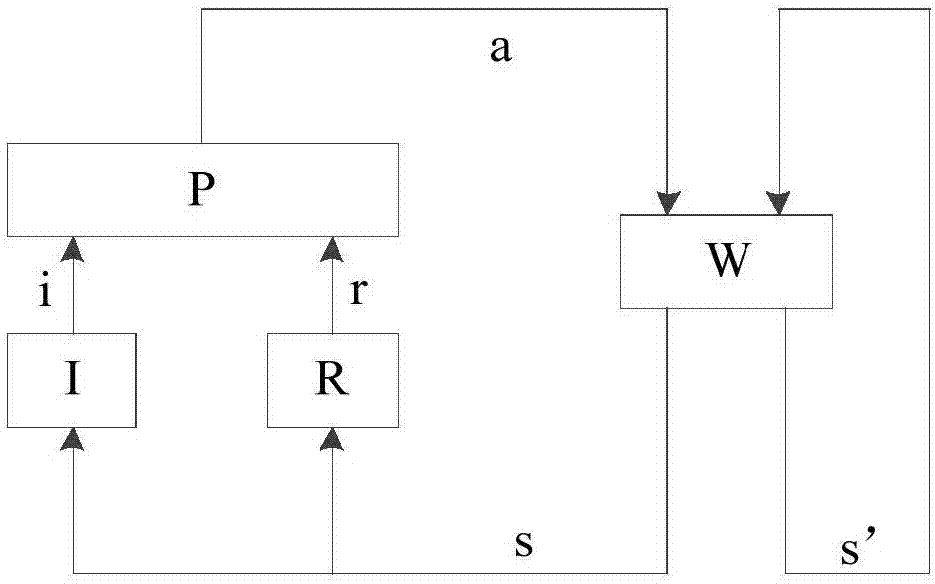
图1是强化学习基本框架结构图;
图2是根据本发明另一个实施例的车辆选型的方法的流程图;
图3是根据本发明一个实施例的车辆选型的装置的结构图。
具体实施方式
下面详细描述本发明的实施例,所述实施例的示例在附图中示出,其中自始至终相同或类似的标号表示相同或类似的元件或具有相同或类似功能的元件。下面通过参考附图描述的实施例是示例性的,旨在用于解释本发明,而不能理解为对本发明的限制。
下面结合附图来描述本发明实施例的车辆选型的方法及装置。
图1是强化学习基本框架结构图,如图1所示,强化学习基本框架中智能体Agent包括:输入模块I、强化模块R、策略模块P和内部世界模型W;输入模块I把环境状态映射成Agent的感知,强化模块R根据环境状态的迁移赋给Agent奖赏值r,策略模块P更新Agent的内部世界模型W,同时使Agent根据某种策略选择一个动作作用于环境。
图2是根据本发明一个实施例的车辆选型的方法的流程图,如图2所示,该车辆选型的方法包括:
S101,获取车辆的当前仿真状态。
本发明实施例中,可通过仿真工具获取当前车辆的仿真状态。
S102,根据当前仿真状态和各零部件选型动作,分别生成车辆在当前仿真状态下执行各零部件选型动作所获得的瞬时奖赏值。
本发明实施例中,可根据当前仿真状态和各零部件选型动作,采用例如强化学习算法生成当前仿真状态下执行各零部件选型动作所获得的瞬时奖赏值,作为一种可行的实施方式,强化学习算法具体可为动作值函数学习算法,即Q-learning算法,例如,可预先设置第一预设公式,生成当前仿真状态下执行各零部件选型动作所获得的瞬时奖赏值,其中,第一预设公式为:其中,Q*(st,at)为车辆在当前仿真状态st下,执行零部件选型动作at达到下一仿真状态st+1所获得的瞬时奖赏值;R=f(st,at,st+1)为根据整车性能指标预设的回报函数;γ为预设的折减系数;Q*(st+1,an)为车辆在下一仿真状态st+1下执行零部件选型动作an所获得的瞬时奖赏值;A为预设的零部件选型集合。
S103,根据各瞬时奖赏值,更新车辆在当前仿真状态下执行各零部件选型动作所获得的绝对奖赏值。
本发明实施例中,可预先设置第二预设公式,更新车辆在当前仿真状态下执行各零部件选型动作所获得的绝对奖赏值,第二预设公式可为:Q′(st,at)=(1-α)Q(st,at)+αQ*(st,at),其中,Q′(st,at)为更新后的绝对奖赏值;α为预设的学习效率;Q(st,at)为更新前的绝对奖赏值。
S104,根据更新后的各绝对奖赏值,确定目标选型方案。
本发明实施例中,获取S103步骤更新后的当前仿真状态下执行各零部件选型动的绝对奖赏值后,根据各绝对奖赏值,确定目标选型方案,例如,将绝对奖赏值最大的方案,确定为目标选型方案。
本发明实施例提出的车辆选型的方法,首先获取车辆的当前仿真状态,根据当前仿真状态和各零部件选型动作,分别生成车辆在当前仿真状态下执行各零部件选型动作所获得的瞬时奖赏值,接着,根据各瞬时奖赏值,更新车辆在当前仿真状态下执行各零部件选型动作所获得的绝对奖赏值,然后,根据更新后的各绝对奖赏值,确定目标选型方案。根据当前仿真状态和各零部件选型动作来获取瞬时奖赏值,根据瞬时奖赏值更新绝对奖赏值,最后依据绝对奖赏值来确定目标选型方案,针对不同的整车性能指标、不同的选型方案,可准确、快速的自动选择出符合整车性能指标的最优选型方案,缩短车辆的开发周期,并能针对现有车型对零部件系统提出准确的改进目标及优化方案。
图3是根据本发明一个实施例的车辆选型的装置的结构图,如图3所示,该车辆选型的装置包括:
获取模块21,用于获取车辆的当前仿真状态;
生成模块22,用于根据当前仿真状态和各零部件选型动作,分别生成车辆在当前仿真状态下执行各零部件选型动作所获得的瞬时奖赏值;
更新模块23,用于根据各瞬时奖赏值,更新车辆在当前仿真状态下执行各零部件选型动作所获得的绝对奖赏值;
确定模块24,用于根据更新后的各绝对奖赏值,确定目标选型方案。
需要说明的是,前述对车辆选型的方法的实施例的解释说明也适用于该车辆选型的装置,此处不再赘述。
本发明实施例提出的车辆选型的装置,首先获取车辆的当前仿真状态,根据当前仿真状态和各零部件选型动作,分别生成车辆在当前仿真状态下执行各零部件选型动作所获得的瞬时奖赏值,接着,根据各瞬时奖赏值,更新车辆在当前仿真状态下执行各零部件选型动作所获得的绝对奖赏值,然后,根据更新后的各绝对奖赏值,确定目标选型方案。根据当前仿真状态和各零部件选型动作来获取瞬时奖赏值,根据瞬时奖赏值更新绝对奖赏值,最后依据绝对奖赏值来确定目标选型方案,针对不同的整车性能指标、不同的选型方案,可准确、快速的自动选择出符合整车性能指标的最优选型方案,缩短车辆的开发周期,并能针对现有车型对零部件系统提出准确的改进目标及优化方案。
进一步的,在本发明实施例一种可能的实现方式中,生成模块22具体用于:根据当前仿真状态和各零部件选型动作,采用强化学习算法生成瞬时奖赏值。
进一步的,在本发明实施例一种可能的实现方式中,生成模块22具体用于:根据当前仿真状态和各零部件选型动作,采用动作值函数学习算法生成瞬时奖赏值。
进一步的,在本发明实施例一种可能的实现方式中,生成模块22具体用于:采用第一预设公式,生成瞬时奖赏值,第一预设公式为:其中,Q*(st,at)为车辆在当前仿真状态st下,执行零部件选型动作at达到下一仿真状态st+1所获得的瞬时奖赏值;R=f(st,at,st+1)为根据整车性能指标预设的回报函数;γ为预设的折减系数;Q*(st+1,an)为车辆在下一仿真状态st+1下执行零部件选型动作an所获得的瞬时奖赏值;A为预设的零部件选型集合。
进一步的,在本发明实施例一种可能的实现方式中,更新模块23具体用于:采用第二预设公式,更新绝对奖赏值,第二预设公式为:Q′(st,at)=(1-α)Q(st,at)+αQ*(st,at),其中,Q′(st,at)为更新后的绝对奖赏值;α为预设的学习效率;Q(st,at)为更新前的绝对奖赏值。
需要说明的是,前述对车辆选型的方法的实施例的解释说明也适用于该车辆选型的装置,此处不再赘述。
本发明实施例提出的车辆选型的装置,首先获取车辆的当前仿真状态,根据当前仿真状态和各零部件选型动作,分别生成车辆在当前仿真状态下执行各零部件选型动作所获得的瞬时奖赏值,接着,根据各瞬时奖赏值,更新车辆在当前仿真状态下执行各零部件选型动作所获得的绝对奖赏值,然后,根据更新后的各绝对奖赏值,确定目标选型方案。根据当前仿真状态和各零部件选型动作来获取瞬时奖赏值,根据瞬时奖赏值更新绝对奖赏值,最后依据绝对奖赏值来确定目标选型方案,针对不同的整车性能指标、不同的选型方案,可准确、快速的自动选择出符合整车性能指标的最优选型方案,缩短车辆的开发周期,并能针对现有车型对零部件系统提出准确的改进目标及优化方案。
在本说明书的描述中,参考术语“一个实施例”、“一些实施例”、“示例”、“具体示例”、或“一些示例”等的描述意指结合该实施例或示例描述的具体特征、结构、材料或者特点包含于本发明的至少一个实施例或示例中。在本说明书中,对上述术语的示意性表述不必针对的是相同的实施例或示例。而且,描述的具体特征、结构、材料或者特点可以在任一个或多个实施例或示例中以合适的方式结合。此外,在不相互矛盾的情况下,本领域的技术人员可以将本说明书中描述的不同实施例或示例以及不同实施例或示例的特征进行结合和组合。
尽管上面已经示出和描述了本发明的实施例,可以理解的是,上述实施例是示例性的,不能理解为对本发明的限制,本领域的普通技术人员在本发明的范围内可以对上述实施例进行变化、修改、替换和变型。
- 还没有人留言评论。精彩留言会获得点赞!