基于静态胎记的软件抄袭检测方法与流程
本发明涉及程序特征发现以及软件版权保护领域,对两个不同开发者发布的程序通过提取其静态胎记进行对比计算其发布程序之间相似度大小,以判断两程序之间是否存在抄袭现象,是一种软件抄袭检测的方法;
背景技术:
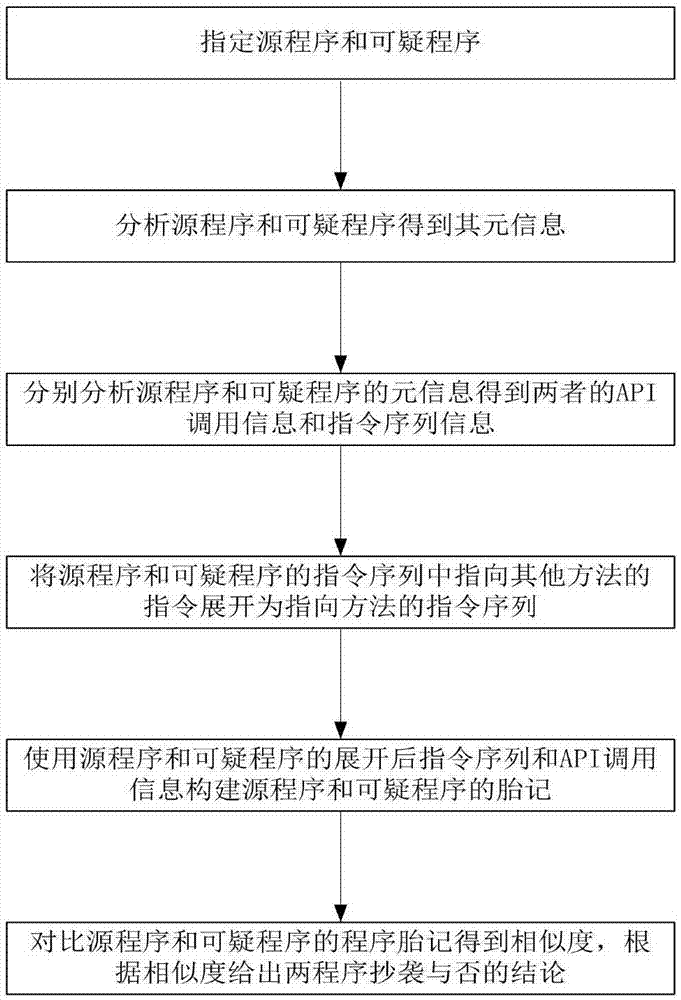
:伴随着计算机技术以及计算机网络的迅猛发展,软件已经成为我们日常生活中不可或缺的一部分,并且为人们的生活带来了极大的便利以及数以亿万记的经济效益;然而软件作为一种数字产品在有着传输便利性的同时也为其版权保护带来了相当的难度,许多别有用心的人可以轻易地在网络上获得目标软件并且通过一些技术手段来将其破解并且以低廉的价格再发行出去,为软件的开发者带来重大损失;在这种现状之下,许多相关学者以及工作人员已经在做有关软件保护的研究,思路大致可以说从软件和硬件两方面来对程序进行加密和保护;若从硬件方面来进行保护,主流有三种手段,一是将程序写入可携带设备,如光盘或加密狗等等,由人对硬件进行保管;二是将程序绑定于cpu之上,一个cpu唯一对应于一个程序,这种方法对于cpu的制造有一定的要求;三是在cpu中增加一个解密单元,对于要执行的程序预先进行加密,只有在执行到程序时再由解密单元进行解密来运行;基于硬件的程序保护大多需要购买专门的硬件,将程序与硬件配合才可以正确执行;若从软件方面进行保护,主流大致有代码加壳,代码混淆,软件水印,软件胎记等技术;而静态软件胎记提取技术与其他技术相比较之下主要有以下两点优势,第一,其技术主要是对源码或中间码进行分析而无需额外插入任何代码,减少人为插入代码导致程序被恶意分析的可能性;第二,与同类的动态提取软件胎记技术相比较之下,这种方法可以更全面的覆盖软件的全部执行过程,而动态执行通常只能覆盖软件的一部分执行路径,增强了胎记的可信度,并且若软件需要频繁交互,提取动态胎记所花费的时间与用户体验代价要比静态胎记大得多;这两方面优势保证了静态软件胎记技术在盗版检测,代码抄袭等方面的实用性;但目前来说静态软件胎记的提取主要有以下难点,第一,大部分的静态软件胎记在面对代码迷惑时表现的非常一般,有的甚至不具备抗迷惑能力;第二,在可以程序的获取上,基本只能拿到其二进制代码或中间代码而无法拿到源代码,这样许多依赖源代码才能够使用的胎记提取,如基于关键词的胎记提取,就无法使用;针对以上情况,需要找到一种更好的软件胎记提取方法,这种方法生成的胎记在具有可信性的同时应兼具有一定的抗迷惑性,不限制于某特定平台或语言,且可以处理多种形式的文件;技术实现要素:本发明要解决的问题是:提出一种新的静态软件胎记提取办法,以克服现有软件胎记的抗迷惑性弱,检测结果不准确的缺陷;本发明的目的通过以下技术手段实现:基于静态胎记的软件抄袭检测方法,包括以下步骤:步骤一、由用户指定源工程pa和pa中的源类a以及可疑工程pb和pb中的可疑类b,再选定迭代深度d{d≥0};步骤二、静态分析a,b编译后得到的中间文件classa和classb,将a中所记录的na个方法的信息结构化的存储在中,同时将a中所有api调用的字面量存储在中;将b中所记录的nb个方法的信息结构化的存储在中,同时将b中所有api调用的字面量存储在中;分别比较和和得到类在api调用方面的相似度simapi和类在指令序列比较方面的相似度simins;步骤三、计算源类a与可疑类b的相似度,相似度计算公式为其中f(x)为sigmod函数,f(x)作用为将输入映射到[0,1]区间内,α为相似度在api调用方面的权重,β为相似度在指令序列方面的权重,而bais为偏置,bais的作用为调整f(x)的净输入;步骤四、最终根据步骤三中得到的源类a与可疑类b的相似度,判断两个类是否存在抄袭关系,若sima,b∈[0,ε],则判定两类之间存在抄袭;若sima,b∈[1-ε,1],则判定两类之间不存在抄袭;否则sima,b∈(ε,1-ε),则无法判定,其中ε为一个小于0.5的检测阈值;本发明的进一步改进之处在于所述步骤二中类在api调用方面的相似度simapi的比较步骤如下:统计包含的类调用数目,记为m1,包含的类调用数目,记为m2,其中相同的类调用数目m1∩m2,和中所有不重复的类调用数目为m1∪m2,源类a与可疑类b在api调用方面的相似度为本发明的进一步改进之处在于所述步骤二中类在指令序列比较方面的相似度simins的比较步骤如下:①.对方法m剥离操作数并记录;②.建立矩阵matrix[na][nb],其中matrix[i][j]所存储的值为源类a中第i个方法与可疑类b中第j个方法的相似度;③.对矩阵matrix[na][nb],记录每一行最大值为则源类a与可疑类b在指令序列方面的相似度为本发明的进一步改进之处在于所述步骤二中类在指令序列比较方面的相似度simins的比较步骤①剥离操作数具体实施步骤如下:ⅰ.遍历m中包含m个有序指令ins1,ins2,...insm,记正在遍历的指令为insj,若insj是一个调用其他方法的指令,且调用的方法是类所在工程p中存在的方法,则用该方法的指令序列替代insj;当ins1,ins2,...insm遍历完毕后d=d-1;ⅱ.重复ⅰ,直到d=0或m中任意一项的指令序列中都不包含指向工程p中存在的方法的指令时,停止;ⅲ.将m中每一个指令剥离操作数,生成m在迭代深度为d时的指令序列seq并记录;本发明的进一步改进之处在于所述步骤二中类在指令序列比较方面的相似度simins的比较步骤②比较两个方法的剥离操作数后指令序列具体实施步骤如下:ⅰ.记方法m1在迭代深度为d时剥离了操作数的指令序列为seq1,其长度为len1;记方法m2在迭代深度为d时剥离了操作数的指令序列为seq2,其长度为len2;用户指定该次检测的碎片阈值为threshold;ⅱ.构建lcs比较矩阵lcs[len1][len2],其中lcsi,j记录了seq1在i位置上的指令与seq2在j位置上的指令的比较情况;若seqi≠seqj,则令lcsi,j=0;若seqi=seqj且i=0||j=0,则令lcsi,j=1;若seqi=seqj且i≠0&j≠0,则令lcsi,j=lcsi-1,j-1+1;ⅲ.定义trace为lcsr,s,...,lcsi-1,j-1,lcsi,j,lcsi+1,j+1,...,lcsp,q,其中lcsr,s=1,并且lcsp+1,q+1=0||p=len1||q=len2;找出lcs比较矩阵中所有的trace,遍历所有trace,若该trace中最大元素值大于threshold,则将该最大元素值添加到集合pieces中;ⅳ.两个方法的相似度计算公式为附图说明图1为本发明的流程图图2为本发明所用示例对比程序对的源程序与可疑程序的源码与中间码对比图图3为本发明所用示例对比程序对的源程序与可疑程序的lcs比较矩阵图4为本发明阐述方法与传统k-gram方法在比对junit4.0-basetestrunner与junit4.x-basetestrunner的相似度的对比图图5为本发明阐述方法与传统k-gram方法在比对soot-2.5.0-soot.main与junit4.x-basetestrunner时相似度的对比图图6为本发明与传统k-gram方法在面对同一经过迷惑的程序对时其给出的相似度对比图具体实施方式如图1,本发明实施的具体步骤如下:(1)选择源jar包与可疑jar包,进行解压,由用户设置起始源类;起始可疑类;迭代深度,阈值;(2)根据迭代深度建立方法迭代栈,迭代深度不得超过迭代深度,并且根据解压后的文件夹建立文件映射系统,从起始方法开始解析class文件并记录其中指令序列信息,对每一个方法按照方法调用顺序形成栈帧,模拟方法执行过程,将其中的指令按执行顺序记录为listinstruction;(3)在模拟执行过程中将class文件的常量池信息中所有的constant_class信息记录为setimport;(4)根据步骤(2)中得到的信息,使用lcs算法进行指令相似度对比,得到指令序列特征的相似度,记为siminstruction;(5)根据步骤(3)中得到的信息,以及api调用方面的相似度计算公式,得到api特征的相似度,记为simapi;(6)根据步骤(4),(5)中的相似度使用sigmod函数输出最终的相似度;(7)根据步骤(6)中得到的相似度判断源类与可疑类是否存在抄袭关系,即:下面将通过具体的实施例来说明本发明的实施;例如,在迭代深度为3时,对以下java程序进行api特征提取得到类a的api特征为:在迭代深度为3时,最终得到类a中function方法的指令序列特征为:其中,粗体部分将会被记录,最终得到的seqa如下:{new,dup,invokespecial,aload_0,invokespecial,return,iload_1,invokevirtual,lconst_1,new,dup,invokespecial,aload_0,invokespecial,return,iload_1,invokevirtual,iconst_2,iload_1,imul,i2l,lreturn,new,dup,invokespecial,aload_0,invokespecial,return,iload_1,invokevirtual,iconst_3,iload_1,isub,i2l,lreturn,ldiv,ladd,l2d,dreturn,pop2,return}在迭代深度为3时,对以下java程序进行api特征提取在迭代深度为3时,对以下java程序进行api特征提取最终得到类fakea的api特征为在迭代深度为3时,最终得到类中fun方法的指令序列如下:其中,粗体部分将会被记录,最终得到的seqfakea如下:{new,dup,invokespecial,aload_0,invokespecial,return,iload_1,invokevirtual,lconst_1,new,dup,invokespecial,aload_0,invokespecial,return,iload_1,invokevirtual,iconst_2,iload_1,imul,i2l,lreturn,new,dup,invokespecial,aload_0,invokespecial,return,iload_1,invokevirtual,iconst_3,iload_1,isub,i2l,lreturn,ldiv,ladd,l2d,dreturn,pop2,return}最终,得到两个类在api调用方面的相似度为:由于两个类都只有一个方法,因此只产生一个lcs比较矩阵,不难看出两个序列完全相同,故为1;最终得到的相似度为通过实验来验证本方法的抗迷惑性和可信性;为了说明本发明的可信性,分析一个程序的不同小版本和两个不同程序来说明本方法的有效性;(1)实验对象在选择实验对象时,测试程序选用junit4.0-4.5版本和soot-2.5.0来作为实验的对象,junit是单元测试的常用工具,而soot是对程序进行静态分析时常用的工具,两者都很常见且具有代表性;是两个完全不同用途的程序;(2)评估准测本发明的目标是希望对提取到程序的可信健壮胎记并进行对比,设置检测阈值γ1为0.8,γ2为0.5;当实验结果大于γ1,就认为两程序之间存在很大可能是拷贝关系,当实验结果小于γ2,就认为两程序之间是独立开发;否则将认定为无法判定;(3)实验实施及结果分析程序1程序2相似度junit4.0-assertjunit4.1-assert0.9992177junit4.0-activetestsuitjunit4.1-activetestsuit0.9782422junit4.1-comparisoncompactorjunit4.2-comparisoncompactor0.9994042junit4.2-basetestrunnerjunit4.3-basetestrunner0.9996096junit4.3-resultprinterjunit4.4-resultprinter0.9996223junit4.4-testsetupjunit4.5-testsetup0.9989239junit4.4-testsetupsoot2.5.0-pack0.11920292junit4.2-resultprintersoot2.5.0-abstracttrap0.13185965junit各个小版本之间相似度较高,而junit和soot之间的相似度较低,可以说明方法的有效性;经过proguard进行代码迷惑以后,选取其中同源类,进行相似度对比,由本方法生成的胎记得到的相似度均值为0.84,最终判定为抄袭;而由k-gram胎记得到的相似度其均值为0.52,最终判定为不确定;实验首先验证了本方法所述胎记的可信性,验证类同程序得到较高的相似度,验证独立开发程序得到较低的相似度,以上两点说明使用本方法所述胎记进行抄袭检测,其结果是可靠的;随后验证了本方法所述胎记的抗迷惑性,由本方法所述胎记得到源程序c与其迷惑程序c'的相似度均值为0.84,而由skb得到c与c'之间相似度均值只有0.52;由这两种胎记得到的检测结果完全不同,由skb得到的相似度我们只能得出两程序的关系是无法判定,而由本方法所述胎记得到的相似度可以得出两程序之间存在抄袭关系;这说明本方法所述胎记在检测经过迷惑的抄袭程序上表现要优于传统的skb,即本方法所述胎记的抗迷惑性比skb要强。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1