一种大规模微博用户兴趣群体发现方法与流程
本发明属于数据挖掘技术领域,具体涉及一种大规模微博用户兴趣群体发现方法。
背景技术:
作为一个开放式网络平台,微博为用户提供了广阔的分享和交流空间。凭借实时、简洁、公开特性,微博拥有了庞大的用户。据2017年新浪微博用户发展报告显示:截止至2017年9月30日,新浪微博3.76亿的月活跃人数再创新高,比2016年同期增长27%。面对与日俱增的用户群体,微博运营商如何能够为用户提供更加精准的个性化服务是目前急需解决的一大难题。微博用户在平台上产生的海量数据中蕴含着丰富的用户行为信息,通过对用户数据的分析研究,发现兴趣偏好相近的用户群体,能为微博平台优化个性化服务提供支持。
通过对国内外学者研究成果的梳理与分析发现,目前关于数据挖掘技术在微博中应用的研究主要集中在信息传播、用户特征、用户网络结构等方面,而针对微博用户兴趣群体细分的研究相对缺乏。虽然有研究人员运用聚类算法实现了微博用户的细分,并证实了利用聚类算法对微博用户进行细分的可行性,但其只是采用了简单的k-means算法。一方面,不能解决k-means算法需要人为决定k值的不足;另一方面,随着待聚类微博用户数据集规模的不断增大,k-means算法的执行受到系统实际可用内存的限制。
技术实现要素:
本发明针对现有技术的不足,提出了一种基于calinski-harabasz改进sslok-means的大规模微博用户兴趣群体发现方法,为微博运营商挖掘用户大数据,进行微博个性化服务的优化、营销收益的提升提供了支持。
一种大规模微博用户兴趣群体发现方法,包括以下步骤:
步骤1),获取微博用户的信息;
步骤2),数据检验与预处理:包括数据检验、用户过滤、微博用户关注账号分类、微博用户兴趣的表示;
步骤3),数据标准化:计算微博用户的兴趣偏爱度、微博数据向量化;
步骤4),利用calinski-harabasez函数改进的sslok-means,进行微博数据聚类,自动确定聚类簇个数。
进一步,所述微博用户的信息包括用户基本信息和微博账号信息,所述用户基本信息包括用户名、性别、地区、注册时间,所述微博账号信息包括账号的名称、微博认证、简介、粉丝数量、关注数量。
进一步,所述数据检验包括数据可用性和相关性检验。
进一步,所述用户过滤方法具体为:将微博账号数量小于所有微博用户关注数量均值十分之一的微博用户标记为“沉默用户”,从数据表中剔除。
进一步,所述微博用户关注账号分类方法具体为:利用微博用户已关注的微博账号中的“简介”和“认证”字段来识别不同类别的账号,对关注列表账号进行分类。
进一步,所述微博用户兴趣的表示包括确定兴趣集合、剔除无效账号、映射兴趣集合,所述兴趣集合的确定是通过参考主流微博平台的分类体系以及微博大v的领域分类,将微博用户的兴趣进行分类,构成兴趣集合;所述剔除无效账号是将不能反映用户的兴趣偏好的账号剔除,过滤出能明显反映用户兴趣的账号;所述映射兴趣集合是指在兴趣集合中,总存在一个兴趣,使得账号集合中任意一个账号与该兴趣相对应。
进一步,所述微博用户的兴趣偏爱度为
进一步,所述微博数据向量化具体为:把微博数据看成文档,使得微博用户数据与文本文档对应,兴趣集合与特征主题对应,用户最终兴趣偏爱程度与权重对应,利用向量空间模型把微博数据转化成数值的二维表,完成向量化过程。
进一步,所述步骤4)具体为:
①构建标记集,驻留内存;
②聚类簇个数的参数k从2到
③利用calinski-harabasz函数对聚类结果的质量进行评价。
进一步,所述执行sslok-means聚类算法具体为:从聚类数据集中顺序读取数据点进入内存,直至内存空间填满,对内存中的数据点、压缩数据的信息ss、移出数据的信息outs、标记集labels进行有限内存中的半监督聚类,直至收敛,对内存中的数据点按照归属以及聚集情况进行压缩和丢弃,判断待聚类数据集中是否仍有数据点,如果有,继续读取数据,否则,聚类过程结束。
本发明的有益效果为:
本发明吸收半监督学习的思想,采用基于calinski-harabasz改进的sslok-means聚类算法进行聚类分析。首先,calinski-harabasz有效性判别函数解决了sslok-means聚类算法需要事先人为决定k值的问题。其次,sslok-means算法针对大规模数据集,利用驻留主存的标记集指导聚类过程,相比k-means,使聚类效率以及聚类结果的质量得到了进一步的提高。本发明将该新技术引入用于微博用户样本数据集,对其进行聚类分析,依据聚类结果对微博用户按照兴趣偏好进行了群体划分,并为每个兴趣群体提出了针对性的个性化推荐建议,对微博个性化服务的提升具有理论指导意义和实践价值。
附图说明
图1为一种基于calinski-harabasz改进sslok-means的大规模微博用户兴趣群体发现方法的流程图;
图2为sslok-means聚类过程图;
图3为sslok-means一次聚类重新收敛以后的聚类结果图;
图4为样本数据与标准数据年龄分布情况对比图。
具体实施方式
下面结合附图及实施例对本发明作进一步的说明,但本发明的保护范围并不限于此。
本发明将一种基于calinski-harabasz改进sslok-means的大规模微博用户兴趣群体发现方法用于微博用户样本数据集,对其进行聚类分析,依据聚类结果对微博用户按照兴趣偏好进行了群体划分,并为每个兴趣群体提出了针对性的个性化推荐建议。
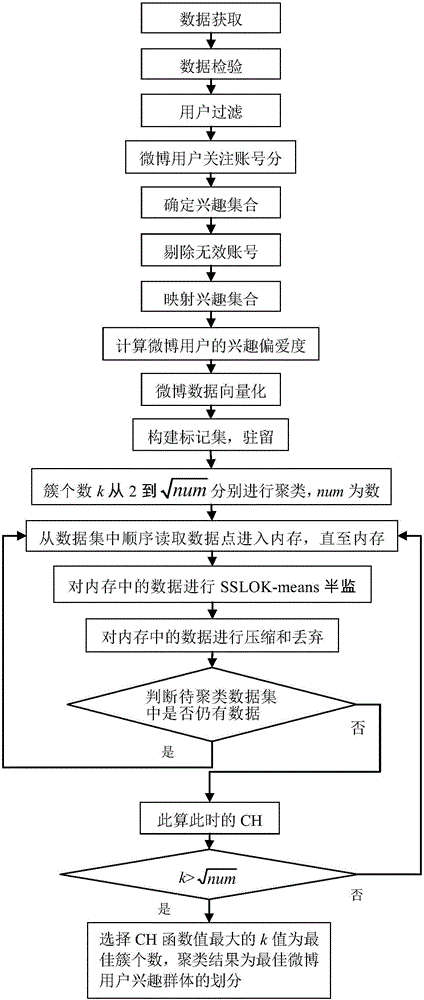
如图1所示,一种基于calinski-harabasz改进sslok-means的大规模微博用户兴趣群体发现技术,包括步骤:
步骤1),数据获取
利用网络爬虫工具抓取微博用户的信息,包括用户名、性别、地区、注册时间以及关注列表中微博账号的名称、微博认证、简介、粉丝数量、关注数量。
步骤2),数据检验与预处理
步骤2.1),数据检验
在进行聚类分析之前,需要检验样本数据能否代表总体,选取性别、年龄、地区三个指标,将样本数据与标准数据进行对比。
在聚类之前,检测变量之间是否具有相关性至关重要。若变量之间具有强相关性,那么这些变量所代表意义的权重就会增大,对这样的变量进行聚类没有意义,可用pearson相关系数、spearman相关系数等进行检验。
步骤2.2),用户过滤
在爬取的微博用户中,会存在“沉默用户”,这类用户的主要特征是关注列表中的微博账号数量很少,不能真实地反映该用户的兴趣偏好,需要剔除。因此,将关注列表中微博账号数量小于所有微博用户关注数量均值十分之一的微博用户标记为“沉默用户”,从数据表中剔除。
步骤2.3),微博用户关注账号分类
利用微博用户已关注的微博账号中的“简介”和“认证”字段来识别不同类别的账号,对关注列表账号进行分类。依据主流分类方式,将所关注的微博账号分为亲朋好友、知名人士、功能性三类微博。亲朋好友的微博即用户的朋友、亲人的微博;知名人士的微博是指在特定领域有代表性的知名人士的微博账号;功能性微博指具有一定社交功能的账号,一般包括各个行业的官方认证账号、新闻媒体的资讯账号等。
步骤2.4),微博用户兴趣的表示
一方面,并不是关注列表中所有的账号都能反映用户的兴趣偏好,需要将不能反映用户兴趣的账号剔除。另一方面,功能类似的账号能够反映用户同一类的兴趣偏好,需要对账号进行整合归类。
步骤2.4.1),确定兴趣集合
通过参考主流微博平台,如新浪、腾讯、搜狐微博等的分类体系以及微博大v的领域分类,将微博用户的兴趣分为十大类,构成兴趣集合h,分别为:时尚购物、美食、旅游摄影、体育、影视娱乐、音乐、游戏动漫、文学阅读、行业工作和it数码。
步骤2.4.2),剔除无效账号
设一个微博用户关注列表中的账号集合为p(p1,p2,p3,...,pn)(n∈n+),其中pi(i∈n)代表用户关注列表中的一个账号,将归为“亲朋好友”的这类不能反映用户的兴趣偏好的账号剔除,过滤出能明显反映用户兴趣的账号,构成关注账号集合l(l1,l2,l3,...,lm)(m∈n+),其中
步骤2.4.3),映射兴趣集合
在兴趣集合h中,总能找到一个兴趣hi,使得账号集合l中任意一个账号li都能够与hi相对应,即
步骤3),数据标准化
经过数据预处理,得到每个微博用户关注账号集合l的个数count(l)以及每一个微博用户在兴趣集合h中对应的兴趣偏好count(hi)(i=1,2,...,10)。借鉴向量空间模型,对已有数据进行标准化处理,将非结构化的数据转化为结构化的数据。
步骤3.1),计算微博用户的兴趣偏爱度
微博用户对任一兴趣的偏爱程度,可由映射到该兴趣的账号个数count(hi)(i=1,2,...,10)与该用户关注列表中账号集合l的个数count(l)的比值来反映,设用户对任一兴趣hi的偏爱程度为
步骤3.2),微博数据向量化
向量空间模型可描述为:对于某一个文本文档di,特征主题tj(j=1,...,n)是互不相同的单词,tj在文本di中的权重记为wij,即文本di可被表示为:v(di)=((t1,wil),(t2,wi2),...,(tn,win))。使得微博用户数据与文本文档di对应,兴趣集合hi(i=1,2,...,10)与特征主题tj(j=1,...,n)对应,用户最终兴趣偏爱程度g(hi)与权重wij对应,利用此方法完成微博用户数据的向量化,用户对兴趣的偏好最终向量化成为一个数值二维表。
步骤4),利用calinski-harabasez函数改进的sslok-means,进行微博数据聚类
ch函数的定义为
步骤4.1),构建标记集,驻留内存
在考虑标记人工成本的前提下,从数据集中以人工的方式标记少量的数据集,标记数据所属类别。这些标记集驻留主存,指导sslok-means的聚类过程,提高聚类效率和聚类结果的质量。
步骤4.2),聚类簇个数的参数k从2到
步骤4.2.1),从数据集中顺序读取数据点进入内存,直至内存空间填满,达到数据分批聚类的目的。
步骤4.2.2),对内存中的数据点、ss(压缩数据的信息)、outs(移出数据的信息)、labels(标记集)进行有限内存中的半监督聚类,直至收敛。聚类过程如图2和3所示。在这个步骤的聚类过程中,ss的所属关系可以发生改变,或者出现新的ss,如图3所示的new集。outs的所属关系不可以发生变化,一直从属于对应的mc(主类),用于累计记录该聚类信息。此过程中的outs以及ss并不存储相关具体的数据点,而是利用一个三元组(sumj,sumsqj,numj)代替,其中
假设outs∈mc,xj∈mc,j=1,...,n,n为目标聚类数,部分数据集如果满足压缩条件(在聚类数目为目标聚类数n倍的前提下,
在单次聚类过程中,为使得算法可以受控最终收敛结束,可以定义一个很小值的结束标识ε,例如ε=1e-8。如果连续两次聚类循环中,所有聚类中心的偏移总量move<=ε,则认为本次聚类收敛结束。
步骤4.2.3),对内存中的数据点进行压缩和丢弃
满足压缩条件的数据点集被ss所替代,相应数据点被清除出主存。满足丢弃条件的数据点被移出主存,进入outs集合。从而在主存中清出空间,读入另外的数据点集。
步骤4.2.4),判断待聚类数据集中是否仍有数据点,如果有,跳转步骤4.2.1),否则,聚类过程结束,算法终止,计算此时的ch值。
步骤4.3),利用calinski-harabasz函数对聚类结果的质量进行评价。选择ch函数值最大的k值为最佳簇个数,聚类结果为最佳的微博用户兴趣群体的划分。
实施条件:实验环境为thinkpad20fwa00vcd,cpu为corei7-6700@2.6ghz,内存8gb,win1064位操作系统,网络爬虫工具,matlab平台。
实施例1:
对新浪微博用户大数据进行聚类分析,发现微博用户兴趣群体,并针对不同的兴趣群体提供个性化的服务,为微博个性化服务的优化、营销收益的提升提供了支持。
1、利用“八爪鱼采集器”抓取了627位普通用户的新浪微博信息,通过对已收集的627位微博用户的信息进行过滤,剔除掉60位“沉默用户”,最终保留了567位有效的微博用户的信息,完成用户的过滤过程。本实施例新浪微博数据预处理后如表1所示,表1中选取前5行数据为例进行示例。
表1用户兴趣的偏好向量
2、样本数据检验:
1)在进行聚类分析之前,需要检验样本数据能否代表总体,否则聚类没有意义。根据2010官方发布的《微博媒体特性及用户使用状况研究报告》(以下简称《报告》),选取性别、年龄、地区三个指标,将样本数据与标准数据进行对比,结果如下:
①性别。本次实验所采集的567位新浪微博用户中,男性243位,女性324位,分别占比42.9%和57.1%。而《报告》中微博用户标准男性比例为39%,女性为61%。样本数据的男女比例与标准数据相差不大,数据具有可信度。
②年龄。本次实验采集的567位用户中,18岁以下39人,占比6.88%,18-30岁364人,占比64.20%,30岁以上164人,占比28.92%。与《报告》中标准年龄占比对比见图4。样本数据与标准数据基本一致。
③地区。本次实验所采集的样本数据所在区域有江苏、河北、辽宁、黑龙江、北京、河南、天津、海南、新疆、广西、广东、深圳、山东、福建、吉林、香港、浙江、湖北、海外、宁夏、四川、重庆、云南,样本数据具备普遍性,具有可信度。
因此,本实施例选取的样本数据能够代表国内微博用户整体情况,通过可用性检验。
2)在聚类之前,检测变量之间是否具有相关性至关重要。若变量之间具有强相关性,那么这些变量所代表意义的权重就会增大,对这样的变量进行聚类没有意义,本实施例采用pearson模型对十个兴趣进行相关性检验,结果如表2所示。
表2pearson相关性检验结果
由表2可知,十个兴趣之间的变量相关性均小于0.3,因此,十个兴趣之间相关性弱,样本数据通过变量相关性检验。
数据分析结果表明:样本数据通过了可用性和变量相关性检验,能够用于聚类分析。
3、基于ch改进sslok-means的聚类分析
利用matlab平台实现了semisupervisedlabelsonescank-means(sslok-means)算法。在驻留主存的标记集的指导下,每次读取100个样本数据集进行聚类,聚类个数k取值范围设为2≤k≤10,最终得到9组不同结果。对9组数据的结果进行calinsi-harabasz(ch)函数的有效性判别,最终得到不同聚类个数k值对应的有效性ch值,算法中间输出结果见表3。
表3ch值对比
由表3可知,当k取6时,有效性函数ch最大,基于calinski-harabasz改进的sslok-means聚类算法将聚类个数k自动选取为6并完成了聚类,获得了新浪微博用户兴趣群体划分的结果。
4、新浪微博用户兴趣群体划分结果描述
经过sslok-means聚类分析以及ch函数判别后,得到最合理的簇的个数为6,各簇中的样本数目见表4,各个聚类中心间的距离见表5,最终的聚类中心见表6。
表4聚类数目为6的各簇中的记录数
表5聚类数目为6的各簇中心间的距离
由表5可得,各个簇中心间的差异显著,其中第2簇和第3簇聚类中心之间的距离最大为55.5,第5簇和第6簇聚类中心之间的距离最小,为26.8。
表6聚类数目为6的最终聚类中心
为了更加直观的描述各个簇中个体对每个兴趣的偏爱程度,将聚类中心数字离散化,设定[0,2)内为极弱兴趣,[2,10)为较弱兴趣,[10,15)内为中等兴趣,[15,25)内为较强兴趣,[25,100]内为强烈兴趣,经过处理之后的聚类中心结果见表7。
表7兴趣离散化处理结果
5、新浪微博用户兴趣群体划分结果分析及个性化推荐服务建议
采用基于ch函数改进的sslok-means算法对微博用户的信息进行聚类分析,最终将用户分为6类兴趣偏好不同的兴趣群体,每个群体具有不同的特征。从6个簇内部分析,即纵向观察兴趣离散化处理结果(表7),可以得出6类用户的不同特征。6类用户按照簇1~簇6的顺序依次可归纳为:知识型、物质型、it类、事业型、网络型和均衡型。针对每一种类型的兴趣群体根据表7给出了个性化的推荐建议。
(1)知识型。样本数量中等,为90个。此类兴趣群体中的用户对“文字阅读”有浓厚的兴趣,对行业工作有较强兴趣,对“时尚购物”有中等兴趣,但对其他类兴趣较弱,尤其对体育领域的兴趣极弱。这类用户喜欢阅读,时常关注行业领域的新闻动态,对时尚购物也比较感兴趣。因此,他们的需求主要集中在阅读以及实用信息的获取上,注重生活品质的提高以及自身修养的提高,追求有质量的生活。
针对这类用户,微博平台应定期向他们推送有深度的文学资讯阅读方面的账号,此类账号的推送比例约为一次推送的40%(表6)。此外,还应向他们推送一部分实用的行业相关的高质量账号,此类账号的推送比例约为一次推送的20%。对于有关时尚搭配、潮流品牌的账号,此类账号的推送比例约为一次推送的12%。另外,由于此类用户对体育兴趣极弱,可以向此类用户在间隔多次推送之后进行少量体育账号的推送,进行兴趣诱导尝试。
(2)物质型。样本数量较大,为123个。此类兴趣群体中的用户特征是对“时尚购物”有浓厚的兴趣,对“美食”和“文学阅读”有中等程度的兴趣,对其他领域的兴趣较弱。这类用户关注时尚潮流,追求物质生活。时尚的生活方式对他们有很强的吸引力。此外,他们还对美食及阅读有一定的兴趣。
针对这类用户,应定期向他们推送有深度的有关时尚品牌、潮流动向、服饰搭配、明星潮人的微博账号,此类账号的推送比例约为一次推送的50%。此外,还可以在获取用户的位置信息后,向他们推荐当地美食、口碑佳的饭馆等。此类账号的推送比例约为一次推送的12%,推送的比例可以根据用户使用微博的时间进行适当调整。比如若用户在就餐时间使用微博,可适当增加推送比例,非就餐时间可适量减少推送比例。同样,由于此类用户对体育兴趣极弱,可以向此类用户在间隔多次推送之后进行少量体育账号的诱导推送。
(3)it类。样本数量较少,为55个。此类兴趣群体中的用户对“it数码”有浓厚的兴趣,同时对“文学阅读”和“行业工作”有中等兴趣。这类用户属于技术型用户,喜欢关注一些互联网动态,it领域的前沿知识,对电子产品有浓厚的兴趣,时常关注行业工作相关资讯,注重自身技能的提升。
针对此类用户,应该向其推荐it互联网领域的优质账号,定期向他们推送最新电子数码产品的信息,此类账号的推送比例约为一次推送的42%;定期向他们推荐优质的文字阅读账号,此类账号的推送比例约为一次推送的11%;定期向他们推送行业资讯相关优质账号,此类账号的推送比例约为一次推送的11%;另外,由于此类用户对音乐兴趣极弱,可以向此类用户在间隔多次推送之后进行少量音乐账号的推送,进行兴趣诱导尝试。此外,这类技术型用户往往比较熟悉互联网相关技术,如果存在有关互联网相关技术的问题,可以向他们寻求帮助。
(4)事业型。样本数量最多,为142个。此类兴趣群体中的用户对“行业工作”类微博有强烈的兴趣,对“时尚购物”和“文字阅读”有中等兴趣,对“体育”、“影视娱乐”和“游戏动漫”兴趣极弱。他们重点关注与具体行业相关的新闻资讯类、实用技巧类的信息。此类用户属于事业型用户,他们注重提升自身技能,希望能够获得与自己领域相关的行业信息。
针对此类用户,在获取用户选定的特定领域的前提下,应该向用户重点推荐与其有关的领域内的深度知识类账号,此类账号的推送比例约为一次推送的50%;定期向他们推送优质的文字阅读账号信息,此类账号的推送比例约为一次推送的15%;还可以定期向他们推荐一些浅层的时尚购物相关的信息,以满足他们对提高生活质量的需求,此类账号的推送比例约为一次推送的13%;另外,由于此类用户对“体育”、“影视娱乐”和“游戏动漫”兴趣极弱,可以向此类用户在间隔多次推送之后进行少量相关资讯信息的推送,进行兴趣诱导。
(5)网络型。样本数量较少,为37个。此类兴趣群体中的用户对“体育”领域有着浓厚的兴趣,他们热衷于关注一些体育明星、赛事官网、体育竞技类的微博账号,同时对“文字阅读”有较强兴趣,对“影视娱乐”有中等兴趣。此类用户大多以大学生为主,时间较为宽裕,他们对学习类的知识兴趣较大,对一些娱乐性质的信息具有一定的兴趣。
对于此类用户,应该根据用户所选择的具体体育项目,向他们有针对性地推荐有关体育项目的赛事预告、体坛明星等信息,此类账号的推送比例约为一次推送的30%;定期向此类用户推荐优质的文字阅读、考试资讯技能提升类账号,此类账号的推送比例约为一次推送的17%;此外,这类用户对影视娱乐有一定的兴趣,可以定期向他们推送与电视剧、电影相关的讯息,此类账号的推送比例约为一次推送的14%。
(6)均衡型。样本数量较大,为120个。此类兴趣群体中的用户对各个兴趣没有特别的偏好,基本对“美食”、“时尚购物”、“旅游摄影”、“影视娱乐”、“文字阅读”以及“行业”类的信息兴趣均衡,此类用户属于均衡类的用户,兴趣广泛,可以推测他们性格偏外向,容易接受新鲜事物。
针对此类用户,向他们推荐各兴趣类别的信息,各类账号的推送比例约为一次推送的15%;此外,还可以向他们推荐一些新鲜事物的消息以及有关社交类的微博账号,比如今日头条、同乡会等。
以上对6类不同兴趣群体的用户进行了具体分析,详细描述了6类用户的典型特征,并对不同类型用户个性化推荐的内容提出了针对性建议。针对不同类型的用户群体特征进行的个性化推荐,能够提升用户的使用体验,增加用户粘性,进而提高微博平台运营的经济效益。
实验结果表明,基于calinski-harabasz改进sslok-means大数据聚类技术是一种有效的新型微博用户兴趣群体发现技术,微博兴趣群体的发现结果为微博个性化服务的优化、营销收益的提升提供了支持
以上实施例仅用于说明本发明的设计思想和特点,其目的在于使本领域内的技术人员能够了解本发明的内容并据以实施,本发明的保护范围不限于上述实施例。所以,凡依据本发明所揭示的原理、设计思路所作的等同变化或修饰,均在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!