动态环境下移动机器人的最优策略解决方法与流程
本发明涉及动态环境下移动机器人的最优策略生成方法。
背景技术:
近年来,随着科技的发展,人们生产、生活中对于智能化机器人的需求越来越大,对机器人智能化水平的要求也越来越高。智能机器人的应用必然涉及到机器人的运动,即机器人的路径规划,现行的路径规划方法如遗传算法、粒子群优化算、蚁群优化算法、模拟退火算法,都是根据给定的机器人运行环境规划出静态环境中的最优路径,而且对于路径的搜索都是在单步确定的情况下。而对于诸如人工神经网络算法、启发式搜索算法、基于采样的路径规划算法等,虽然能够适用于动态变化的环境,但是对于复杂任务和单步有多种选择的情况下,依旧无法很好的完成任务。基于线性时序逻辑(lineartemporallogic,ltl)理论的移动机器人路径规划方法采用线性时序任务公式描述实际应用中复杂的任务需求,并将环境信息与任务信息相融合以确保能够搜索出既符合环境信息,又满足任务需求的最优路径。但是对于单步有多种选择的情况,所需要并不是最优路径,而是能够满足任务需求的最优策略。
为了解决上述的问题,传统的解决办法是ltl-dra(确定性自动机)方法,用环境信息和dra相结合,能保证得出的最优策略既能完成给定的任务需求,又能使搜索代价相比上述的动态规划算法更小。但是,使用dra存在一种弊端,在某些情况,ltl公式并不能转化为dra,这使得传统的解决办法无法解决所有情况,另一方面,传统方法得到的mdp还存在一些冗余的状态,可以进一步的进行缩减。
nba(非确定性自动机)是为了解决dra所存在的情况而提出的,nba可以保证每一个ltl公式均可以转化为自动机图形,便于后续的操作。对于单步存在多种选择的情况,将模型构建成mdp(马尔科夫决策模型),解决马氏决策过程,采用策略迭代求解最优策略。
技术实现要素:
本发明要解决现有技术的上述问题,提供一种动态环境下移动机器人的最优策略解决方法。
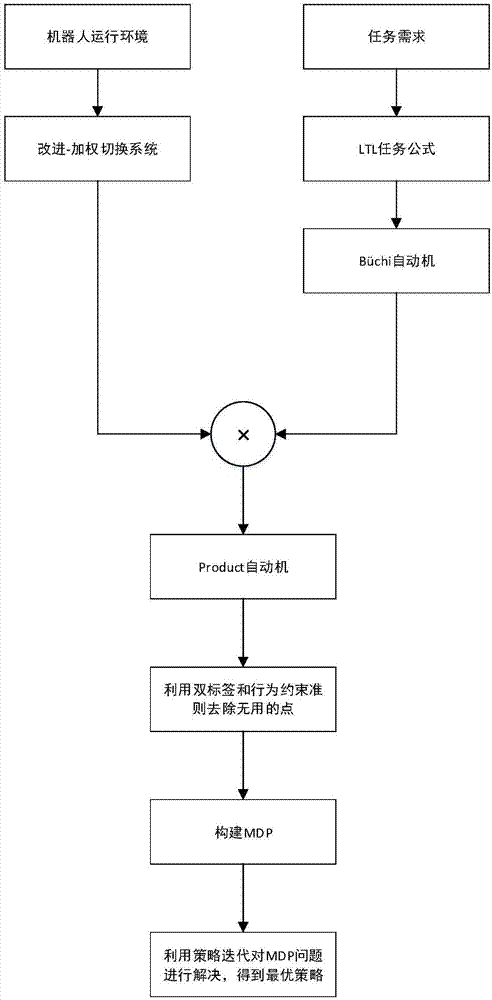
本发明利用线性时序逻辑(ltl)描述复杂任务需求,用nba代替传统的dra将ltl转换成图形表示,同时利用双标签和行为约束准则,去除多余的无用状态,简化mdp问题的解决。该发明流程图如图1所示,首先,根据机器人的运行环境,构建改进-加权切换系统,根据任务需求,利用线性时序逻辑(ltl)将任务需求数学表达化,利用ltl2ba工具包将ltl任务公式转化为büchi自动机;然后将2者进行笛卡尔乘积,得到product自动机,包含了任务需求和环境信息;将可行性网络拓扑图上的无用点去除(有些点只有输入或只有输出),再根据双标签和行为约束准则,进一步判断状态点的可用性,进而简化状态点的数量。将剩余的点构建成mdp模型,利用策略迭代的方法得出最优策略。该方法不仅解决了不存在dra的情况,还使得可用点数量的减少,构建的mdp复杂度下降,可以更快速的得到最优策略。
本发明的动态环境下移动机器人的最优策略解决方法,具体步骤如下:
步骤一构建改进-加权切换系统;
将机器人所在的环境构建为一个改进-加权切换系统,加权切换系统是对环境的模型化,其定义为一个元组t:=(q,q0,r,π,l,wt),其中q为一个有限的状态集合,把环境中选中的节点作为状态集合;q0∈q代表了初始状态,即机器人所在的初始状态,运行起点;r→2q代表了切换关系,表明了各个状态之间(路径点之间)的连通关系;π代表原子命题,即每个状态点应该完成的动作;l:q→2π代表了标识函数集;wt代表切换权重,将其作为衡量值,即另一个标签。原子命题在加权切换系统中的作用是代表了各个状态的属性,当且仅当状态q处原子命题π为真时,π∈l(q)才成立,若q2∈r(q1),则q2为q1的后续状态;加权切换系统中的任意一条轨迹rt是由t中的有限个状态组成,即rt=q0q1q2...,其中对于任意的i≥0都有qi+1∈δ(qi)成立,轨迹rt包含了有限个标识函数o=o1o2o3...,其中oi∈l(qi)。如图2所示,是一个机器人的mdp过程,将它构建成加权切换系统,如图3所示,在q0执行pickup的动作,在q9处执行dropoff动作。
步骤二复杂任务数学表达化;
根据线性时序逻辑理论可以将复杂任务进行数学表达化;线性时序逻辑(ltl)是一种接近自然语言的高级语言,将时序逻辑算子g(始终),f(最终),x(接下来),u(直到)和布尔算子
这个任务表达了机器人在pickup之后,必须到达dropoff之后才能回到pickup,同理,机器人dropoff之后必须经过pickup才能回到dropoff。
步骤三生成büchi自动机;
为了使环境信息和任务信息相结合,需要通过ltl2ba工具包将线性时序任务公式φ转换为任务可行性图表的形式,即büchi自动机,将步骤三的公式转化为büchi自动机,如图4所示。büchi自动机是一个五元组b:=(sb,sb0,σb,δb,fb)。其中,sb代表一个有限的状态集;sb0∈sb代表了初始状态;σb代表了输入的字符表;δb∈sb×σb×sb代表了切换函数;fb∈sb代表了最终状态集。
步骤四构建任务可行性网络拓扑图;
将加权切换系统和büchi自动机进行笛卡尔乘积,得到包含环境信息和任务信息的任务可行性网络拓扑图p,即
步骤五状态点删减;
在步骤四得到的任务可行性网络拓扑图上,将一些无用点率先剔除,即不可到达点,有一些只有输入或者只有输出,这样的点是不可到达的,因为选择这些点将导致策略的中断,无法得到最优结果。引入双标签,一个标签是状态标签,即在转折点之前,此状态的状态标签值将和上一个状态标签一致,例如在p1处的状态为pickup,而转折点在p10,那么p2-p9的状态都是pickup,同理在p10之后,p1之前,p9-p2的状态都是dropoff。而不同的状态之间不能相连,也就是一个状态只能拥有一个状态标签。另一个标签是衡量值,选择距离,即各个状态和另外状态的距离,行为约束准则的思想来自实际中的法律约束,当机器人的下一个状态使衡量值低于这一状态,那么下一状态将被舍弃,如机器人在q1点任务,那么机器人将往p10处移动,加入机器人走到q4,下一步有两个状态可选择q5,q6,q4的衡量值为3,也就是离目标点只有3步距离,而q5离目标点有4步距离,q6离目标点有2步距离,那么将舍弃q5状态,而选择q6状态。通过双标签和行为约束准备,进一步简化任务可行性拓扑。如图5所示,经过双标签和行为约束准则去除不可用状态点,剩余的点用以构建mdp。
步骤六构建马尔科夫决策模型;
将剩余的状态点构建mdp,把五重组m:=(t,s,a(i),p(.|i,a),r(i,a))称为一个马氏决策过程(mdp),其中选取行动的时间点被称为决策时刻,并用t记所有决策时刻的点集;s为有限个状态空间集;在状态i处的可用行动集a(i)称为行动空间;p(.|i,a)称为下一决策时刻系统所处的状态的概率分布;r(i,a)为决策者获得的报酬;构建完成mdp,使用策略迭代算法进行求解,得到最优策略。
本发明采用线性时序逻辑公式描述实际应用中的复杂的任务需求,并将任务信息和环境信息相融合得到可行性任务网络拓扑图,使得到的策略能满足任务的需求,更高效的执行任务。该发明在传统的ltl-dra(dra:确定性自动机)上进行创新,提出ltl-dba方法,避免了当任务需求为始终最终到达一个点p:φ=gfp时,因为使用传统方法而造成无法得到最优策略的情况。利用策略寻优效率与环境复杂度以及任务节点数成正比的特点,同时提出双标签模型,利用不同状态不相连和行为约束准则,得到更为简练的可行性任务网络拓扑图,将剩余的可行状态点构建mdp,同时利用策略迭代算法,得到最优策略。
本发明的优点是:相比传统的ltl-dra,有更好更广泛的适用性,能够好的得到最优策略。
附图说明:
图1为本发明的ltl-mdp策略生成图。
图2为本发明的马尔科夫决策模型。
图3为本发明的加权切换系统t。
图4为本发明的公式φ对应的büchi自动机。
图5为本发明的网络拓扑图。
具体实施方式
以下结合附图对本发明的ltl-mdp解决方法通过简单实例做进一步描述。
该发明流程图如图1所示,首先,根据机器人的运行环境图2,构建改进-加权切换系统图3,根据任务需求:机器人在pickup之后,必须到达dropoff之后才能回到pickup,同理,机器人dropoff之后必须经过pickup才能回到dropoff,利用线性时序逻辑(ltl)将任务需求数学表达化,利用ltl2ba工具包将ltl任务公式转化为büchi自动机;然后将2者进行笛卡尔乘积,得到product自动机,包含了任务需求和环境信息;将可行性网络拓扑图上的无用点去除(有些点只有输入或只有输出),再根据双标签和行为约束准则,进一步判断状态点的可用性,进而简化状态点的数量。将剩余的点构建成mdp模型,利用策略迭代的方法得出最优策略。该方法不仅解决了不存在dra的情况,还使得可用点数量的减少,构建的mdp复杂度下降,可以更快速的得到最优策略。具体步骤如下:
步骤一,构建改进-加权切换系统;
将机器人所在的环境构建为一个改进-加权切换系统,加权切换系统是对环境的模型化,其定义为一个元组t:=(q,q0,r,π,l,wt),其中q为一个有限的状态集合,把环境中选中的节点作为状态集合;q0∈q代表了初始状态,即机器人所在的初始状态,运行起点;r→2q代表了切换关系,表明了各个状态之间(路径点之间)的连通关系;π代表原子命题,即每个状态点应该完成的动作;l:q→2π代表了标识函数集;wt代表切换权重,将其作为衡量值,即另一个标签。原子命题在加权切换系统中的作用是代表了各个状态的属性,当且仅当状态q处原子命题π为真时,π∈l(q)才成立,若q2∈r(q1),则q2为q1的后续状态;加权切换系统中的任意一条轨迹rt是由t中的有限个状态组成,即rt=q0q1q2...,其中对于任意的i≥0都有qi+1∈δ(qi)成立,轨迹rt包含了有限个标识函数o=o1o2o3...,其中oi∈l(qi)。如图2所示,是一个机器人的mdp过程,将它构建成加权切换系统,如图3所示,在q1执行pickup的动作,在q10处执行dropoff动作。
步骤二,复杂任务数学表达化;
根据线性时序逻辑理论将复杂任务进行数学表达化;线性时序逻辑(ltl)是一种接近自然语言的高级语言,将时序逻辑算子g(始终),f(最终),x(接下来),u(直到)和布尔算子
这个任务表达了机器人在pickup之后,必须到达dropoff之后才能回到pickup,同理,机器人dropoff之后必须经过pickup才能回到dropoff。
步骤三,生成büchi自动机;
为了使环境信息和任务信息相结合,通过ltl2ba工具包将线性时序任务公式φ转换为任务可行性图表的形式,即büchi自动机,将步骤三的公式转化为büchi自动机,如图4所示。büchi自动机是一个五元组b:=(sb,sb0,σb,δb,fb)。其中,sb代表一个有限的状态集;sb0∈sb代表了初始状态;σb代表了输入的字符表;δb∈sb×σb×sb代表了切换函数;fb∈sb代表了最终状态集。
步骤四,构建任务可行性网络拓扑图;
将加权切换系统和büchi自动机进行笛卡尔乘积,得到包含环境信息和任务信息的任务可行性网络环境拓扑图p,即
步骤五,状态点删减;
在步骤四得到的任务可行性网络拓扑图上,率先剔除一些无用点,然后引入双标签,一个标签是状态标签,即在转折点之前,此状态的状态标签值将和上一个状态标签一致,在p1处的状态为pickup,而转折点在p10,那么p2-p9的状态都是pickup,同理在p10之后,p1之前,p9-p2的状态都是dropoff。而不同的状态之间不能相连,也就是一个状态只能拥有一个状态标签。另一个标签是衡量值,本模型选择距离,即各个状态和另外状态的距离,行为约束准则的思想来自实际中的法律约束,当机器人的下一个状态使衡量值低于这一状态,那么下一状态将被舍弃,机器人在q1点任务,那么机器人将往p10处移动,机器人走到q6,下一步有三个状态可选择q5,q7,q9,q5的衡量值为3,也就是离目标点只有3步距离,而q7离目标点有2步距离,q9离目标点有2步距离,所以将舍弃q5状态,而选择q7,q9状态。通过双标签和行为约束准备,进一步简化任务可行性拓扑。如图5所示,经过双标签和行为约束准则去除不可用状态点,剩余的点用以构建mdp。
步骤六,构建马尔科夫决策模型。
将剩余的状态点构建mdp,把五重组m:=(t,s,a(i),p(.|i,a),r(i,a))称为一个马氏决策过程(mdp),其中选取行动的时间点被称为决策时刻,并用t记所有决策时刻的点集;s为有限个状态空间集;在状态i处的可用行动集a(i)称为行动空间;p(.|i,a)称为下一决策时刻系统所处的状态的概率分布;r(i,a)为决策者获得的报酬;构建完成mdp,使用策略迭代算法进行求解,得到最优策略。
本发明采用nba来作为ltl的合成自动机,避免使用dra而造成一些ltl不存在dra自动机的情况,将环境信息和任务公式相结合得到任务可行性网络拓扑图,通过双标签和行为约束准则,去除无用点,将剩余的状态点组成构建mdp,利用策略迭代算法得到最优策略,实验结果表明本发明所提出的方法很好的解决了这类问题。
本说明书实施例所述的内容仅仅是对发明构思的实现形式的列举,本发明的保护范围不应当被视为仅限于实施例所陈述的具体形式,本发明的保护范围也及于本领域技术人员根据本发明构思所能够想到的等同技术手段。
- 还没有人留言评论。精彩留言会获得点赞!