一种基于深度学习的图像目标快速检测方法与流程
本发明属于图像检测识别技术领域,特别涉及一种基于深度学习的图像目标快速检测方法。
背景技术:
图像目标检测一直是图像处理领域的热点,尤其针对小目标的高鲁棒性、高准确性以及高实时性的检测,具有重要的应用价值。本发明以软管式自主空中加油的锥套目标检测为例,展开方法的设计与实现。
软管式自主空中加油可以大幅度提升无人机的续航能力,它是加油机与受油机通过编队配合,由受油机自主定位前方加油机上锥套相对自身的位置,并通过精准的控制实现受油机与加油锥套的精准对接,其中受油机能够自主准确的定位加油锥套的相对位置尤为关键,为后续的精确控制提供导航信息。目前,软管式自主空中加油近距对接的定位导航手段为视觉导航辅助gps/ins组合导航,视觉导航负责提供加油锥套与受油机之间的相对位置关系,在导航系统中起到了关键性的作用,而锥套目标的图像检测是视觉导航必不可少的环节,国内外众多研究机构对锥套目标的检测技术开展了大量的研究。
软管式自主空中加油对锥套目标的检测提出了很高的要求,一方面,要求锥套目标的检测识别可靠性很高,尤其对于较远距离锥套小目标需要有较高的检测准确率以及成功率;另一方面对于图像信息的处理时间要尽可能短,以保证很高的实时性。
目标检测一直是图像处理领域研究的热点。如今,目标检测方法主要分为两大类:基于传统图像处理的目标检测方法和基于深度学习的目标检测方法。
传统的目标检测方法可表示为:目标特征提取->目标识别->目标定位。基于深度学习的目标检测可表示为:图像的深度特征提取->基于深度神经网络的目标识别与定位。传统的目标检测算法场景适应性差,对于光照变化剧烈、目标被遮挡、背景干扰严重、目标较小的情况下检测效果较差,因而逐渐被检测精度高、鲁棒性强的深度学习检测算法所取代。基于深度学习的目标检测主要可分为两类:基于区域建议的目标检测与识别算法,如r-cnn、fast-r-cnn、faster-r-cnn等;基于回归的目标检测与识别算法,如yolo、ssd等,其中基于回归的目标检测算法实时性较好。
技术实现要素:
发明目的:针对现有技术的问题,提供一种处理时间较短,识别可靠性高的基于深度学习的图像目标快速检测方法。
技术方案:为解决上述技术问题,本发明提供一种基于深度学习的图像目标快速检测方法,包括如下步骤:
(1)建立基于深度学习的第一级tinyyolo目标检测模型和第二级tinyyolo目标检测模型;
(2)向第一级tinyyolo目标检测模型输入含有目标的测试图像,网络的最后一层输出所有预测目标区域信息r1:
r1={ri|ri=(xi,yi,wi,hi,pi,c1i,c2i),i=1,2,...,845}
其中ri为第i个预测目标区域,xi为第i个区域左上角点的横坐标,yi为第i个区域左上角点的纵坐标,wi为第i个区域的宽度,hi为第i个区域的高度,pi为第i个区域中含有目标的概率值或置信度,c1i为第i个区域中目标为第一类(近距目标)的概率值,c2i为第i个区域中目标为第二类(远距目标)的概率值,i的取值范围为1~845,由非极大值抑制算法得到置信度最大的目标区域rk:
rk=(xk,yk,wk,hk,pk,c1k,c2k)
pk=max{pi,i=1,2,...,845}
根据目标区域rk的目标置信度pk及目标区域的宽高比判断检测是否成功,判断的条件如下:
若检测成功,进行步骤(3);若检测失败,进行步骤(4);
(3)根据检测区域与图像分辨率的尺寸关系确定检测区域是否为小目标区域,若为小目标则进行步骤(5),判断为小目标的条件如下所示:
w:图像宽度h:图像高度
若不是小目标则输出目标区域r:
r=(xk,yk,wk,hk)
(4)对输入的图片进行分块处理,然后对分块处理后的图像进行第一级tinyyolo网络检测;若依旧检测失败,则输出检测失败;若检测成功则进行步骤(3);
(5)对第一级tinyyolo网络检测输出的检测区域rk进行放大截取,然后输入至第二级tinyyolo网络,第二级tinyyolo网络最后一层输出所有预测目标区域信息r2:
r2={ri|ri=(xi,yi,wi,hi,pi,c1i,c2i),i=1,2,...,50}
与第一级tinyyolo网络相同,采用非极大值抑制算法得到置信度最大的目标区域rj=(xj,yj,wj,hj,pj,c1j,c2j),结合放大区域的左上角坐标(xk_e,yk_e),得到最终的输出目标区域为r:
r=(xk_e+xj,yk_e+yj,wj,hj)
进一步的,所述步骤(1)中建立基于深度学习的第一级tinyyolo目标检测模型和第二级tinyyolo目标检测模型的具体步骤如下:
(1.1)获取目标图像数据集,人工标注目标检测样本,按照voc格式生成第一级tinyyolo目标检测样本库;
(1.2)设计第一级tinyyolo目标检测网络,并通过训练得到第一级tinyyolo目标检测模型;
(1.3)根据第一级tinyyolo目标检测模型与第一级tinyyolo目标检测样本库自动生成第二级tinyyolo目标检测样本库:
例:第一级tinyyolo目标检测样本:图片ii,人工标注的目标区域ri=(xi,yi,wi,hi),第一级tinyyolo目标检测模型m1:
将ii输入模型m1得到检测网络输出的目标区域r′i=(x′i,y′i,w′i,h′i),若区域r′i与ri的重叠率在0.5以上,则认为该图片可作为第二级tinyyolo目标检测样本。以区域ri′的中心为中心进行放大与偏移的变换,分别放大3倍r′i_3、3.4倍r′i_3.4以及3.8倍r′i_3.8,然后进行上下左右的平移操作,生成若干个图像区域以及对应的目标区域,以放大3倍r′i_3无偏移为例展开如下说明:
生成图片ii(r′i_3)以及目标区域ri=(xi-x′i_3,yi-y′i_3,wi,hi),作为第二级tinyyolo目标检测样本。
(1.4)设计第二级tinyyolo目标检测网络,并通过训练得到第二级tinyyolo目标检测模型。
进一步的,所述步骤(4)中对输入的图片i进行分块处理的具体步骤如下:
(4.1)分别对全局图像i的宽高均匀分为11等份,生成11*11的网格;
(4.2)假设目标处于图像的中部区域,忽略网格最外边缘的图像区域;
(4.3)对内部9*9的网格图像区域进行四个子区域(i1~i4)的分割处理,如下所示,其中w、h分别为全局图像i的宽、高尺度
进一步的,所述步骤(5)中对第一级tinyyolo网络检测输出的检测区域rk进行放大截取的具体步骤如下:
(5.1)以检测区域rk的中心为中心,对区域rk放大3.6倍,得到放大区域rk_expand:
rk_expand=(xk_e,yk_e,wk_e,hk_e)
wk_e=min{3.6·wk,w-xk_e}
hk_e=min{3.6·hk,h-yk_e}
(5.2)截取放大区域i(rk_expand),并记录放大区域的左上角坐标(xk_e,yk_e)以便恢复第二级tinyyolo检测结果的区域信息。
与现有技术相比,本发明的优点在于:
(1)本发明具有可靠性:采用深度学习对大量的锥套目标检测样本进行训练,得到的检测模型相较于传统的图像检测识别模型鲁棒性强、准确性高,对于光照、遮挡、尺度、旋转以及背景干扰具有较强的抗干扰能力。
(2)本发明具有实时性:借鉴tinyyolo目标检测网络的小巧快速,本发明在其基础上进行设计改进,成功实现了在提升精度的同时没有明显增加检测处理耗时,保证了目标检测的实时性。
(3)对于小目标的检测成功率以及准确率的提升一直是图像检测领域的难点,本发明基于yolo目标检测算法,设计级联的深度学习目标检测框架,克服了了小目标检测成功率高且准确率高的难题,同时保证了算法的实时性。
附图说明
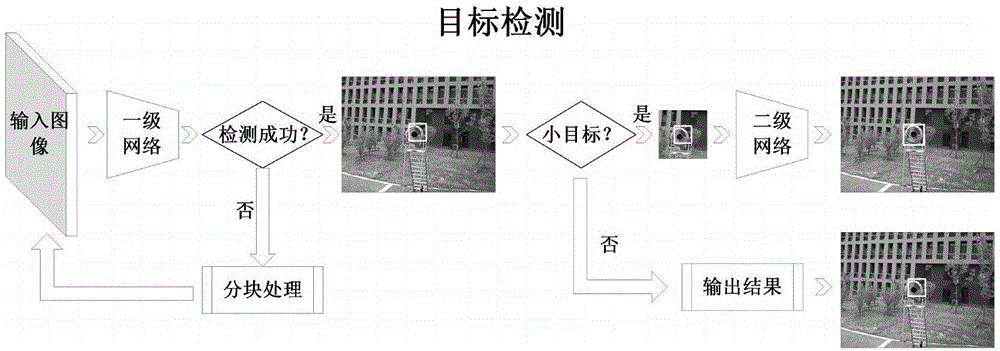
图1为本发明的方法流程图;
图2为具体实施例中第一级tinyyolo算法的检测网络结构图;
图3为具体实施例中第二级tinyyolo算法的检测网络结构图;
图4为具体实施例中第二级检测网络训练样本库生成算法图;
图5为具体实施例中图像分块算法原理图;
图6为具体实施例中检测算法精确度对比图;
图7为具体实施例中检测算法成功率对比图;
图8为具体实施例中检测算法耗时对比图;
图9为具体实施例中检测算法结果示意图。
具体实施方式
下面结合附图和具体实施方式,进一步阐明本发明。本发明描述的实施例仅仅是本发明的一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动的前提下所得到的其他实施例,都属于本发明所保护的范围。
参照图1所示,本发明所述的一种基于深度学习的图像目标快速检测方法,包括如下步骤:
1)目前主流的目标检测数据库基本上为通用目标的检测数据样本库,不适合本文的检测目标——加油锥套,因而本文首先建立加油锥套检测样本库。首先通过相机拍摄加油锥套视频、网络搜索空中加油视频等手段获取含有锥套的视频数据;然后将视频数据转换为图片数据集,对图片进行锥套目标的检测数据标注,标注的内容为:目标的区域信息(位置及尺寸)和目标的类别;最后将得到的标注结果按照voc格式转换为最终的锥套目标检测样本库。
本文针对锥套目标在图像中的尺寸及显示的细节不同划分为两类目标:远距离锥套(目标小、细节特征少)、近距离锥套(目标大、细节特征丰富)。
最终通过linux平台下的c++和opencv图像处理库,将视频数据进行处理,得到接近20000张锥套目标检测样本图片,作为第一级tinyyolo网络模型的训练数据集。
2)tinyyolo算法的检测网络结构如图2所示。网络由9个卷积层和6个池化层构成,输入的图像归一化为416×416×3的标准输入。训练时设计的参数如下:batch:64、学习率:0.001(step:80000以内),0.0001(step:80000-90000),0.00001(step:90000-100000);
3)针对第一级tinyyolo目标检测网络输出的结果准确度不高的问题,本发明设计第二级tinyyolo目标检测网络,网络结构如图3所示,类似第一级检测网络的结果,只是在具体某一层的图像尺度发生了相应的变化。本文设计的第二级网络是在第一级网络检测结果基础上进行目标检测,因此需要针对性的设计第二级网络的训练样本库。本文设计第二级检测网络训练样本库生成算法,如图4所示;
首先输入图像经过第一级tinyyolo训练的网络模型得到检测区域r1;然后对区域r1进行放大与偏移的变换,分别放大3倍、3.4倍以及3.8倍,然后以区域r1为中心进行上下左右的平移操作,生成27个图像区域;最后结合输入的人工标注的目标区域rect信息,得到输出图像以及对应的新标注信息newrect。该算法基于第一级训练网络的样本集生成第二级检测网络的训练样本,且整个过程可通过程序代码的设计自主运行,无需进行人工标注的介入,且生成的样本具有图像尺寸小、检测目标区域的图像占比大且基本一致的特性,便于第二级网络模型的简化设计;
4)相比第一级网络的输入图像,第二级网络的输入图像尺寸小、检测目标区域的图像占比大且基本一致,因而该网络不需要将图像划分为13×13的网格;同时每个网格预测的边框个数也不需要设置为5个。本文设计第二级检测网络的输入归一化为160×160×3,输出为5×5×14的特征输出图,将输入图像划分为5×5的网格。每个网格预测2个边框,每个边框7维信息,总共形成25个14维的向量。相比第一级网络的169个35维的向量,该二级检测网络的输出要小得多,检测处理耗时相应减少,同时保证了较小目标检测的精度,tinyyolo第二级检测网络结构如图3所示。训练时设计的参数如下:batch:64、学习率:0.001(step:160000以内),0.0001(step:160000-180000),0.00001(step:180000-2000000)。
5)tinyyolo第一级目标检测的流程如下:
a)将待检测的图像输入检测网络,得到13×13×35的特征输出图;
b)13×13将输入图像划分为169个网格,对于每个网格预测5个边框(anchorbox),每个边框包含7维信息(4维坐标信息、1维目标置信度、2维目标类别信息,本文将锥套目标分为远距锥套与近距锥套两类),总共形成169个35维的向量;
c)将上一步预测出的13×13×5个目标边框,先根据阈值消除概率小的目标边框,再用非极大值抑制(non-maximumsuppression,nms)去除冗余窗口,得到检测目标的区域信息。
6)针对目标在图像中的占比较小的情况,由于tinyyolo检测网络只将输入图像划分为13×13的网格,存在网格划分不精细,导致小目标的检测失败。本文设计小目标图像分块检测算法,针对检测失败的情况启用小目标图像分块检测。具体的图像分块算法如下所示。
根据输入图像的分辨率,均匀划分成11×11的网格区域。设计分块区域的尺寸为6×6网格区域,忽略目标在图像最边缘的情况,将内部区域按照图5所示的方案划分为4个分块子区域,编号为1-4。
按照编号顺序依次对分块子区域进行目标检测算法的处理。当检测到目标区域时,停止对后续分块子区域的检测。该图像分块算法的引入大大提升了小目标检测的召回率;同时本文设计的图像分块算法由于分块子区域互有重叠,避免了检测目标因图像分块产生的拆分现象。
7)本发明整个算法结构图如图1所示,针对未训练过的实验场景进行目标检测算法的性能测试,包括检测精准度、检测成功率以及检测耗时等三个方面。分别编程实现传统的tinyyolo目标检测算法与本文改进的目标检测算法(tinyyolov2算法),对两种算法的处理结果数据进行分析得到如图6~图9所示的检测的结果。
- 还没有人留言评论。精彩留言会获得点赞!