人机自然交互与协作共融的金融支付同传翻译机和方法与流程
本发明涉及人机自然交互与协作共融、金融机具、同传翻译、翻译机、多模态深度语义理解和人工智能技术领域,具体涉及一种人机自然交互与协作共融的金融支付同传翻译机和方法。
背景技术:
多模态深度语义理解是指对文字、声音、图片、视频等多模态的数据和信息进行深层次多维度的语义理解,包括数据语义、知识语义、视觉语义、语音语义一体化和自然语言语义等多方面的语义理解技术。多模态深度语义理解不仅能让机器听清、看清,更能深入理解它背后的含义,深度地理解真实世界,进而更好地支撑各种应用。
多模态深度语义理解技术可以将大千世界中多元、异构和多模态的三元空间大数据,形成包含千亿节点、万亿关系的庞大数据语义网络,从中总结规律、提炼知识、发现价值,助力经济和社会发展。
目前的翻译机未能实现人机自然交互与协作共融,其中一个原因是,翻译机未能对翻译所涉及的生活环境、本地文化进行认知和洞察,从而要理解说话人的意图,而多模态深度语义理解技术有可能解决这个问题。
同声翻译又称同声传译、同传翻译、同步口译,常简称为“同传”,是译员在不打断讲话者演讲的情况下,不停地将其讲话内容传译给听众的一种口译方式。同声传译的最大优点在于效率高,可以保证讲话才作连贯发言,不影响或中断讲话者的思路,有利于听众对发言全文的通篇理解。
目前的商用翻译机是做不到同传翻译的,需要使用人用母语说一段话,翻译机翻译后播出外语,然后对话人说一段外语,翻译机翻译后播出母语,未能实现像正常的人与人聊天一样,你一句我一句地交流。
人在发音时,根据声带是否震动可以将语音信号分为清音跟浊音两种。浊音又称有声语言,携带者语言中大部分的能量,浊音在时域上呈现出明显的周期性;而清音类似于白噪声,没有明显的周期性。发浊音时,气流通过声门使声带产生张弛震荡式振动,产生准周期的激励脉冲串。这种声带振动的频率称为基音频率,相应的周期就成为基音周期。
基音频率与个人声带的长短、薄厚、韧性、劲度和发音习惯等有关系,在很大程度上反应了个人的特征。此外,基音频率还跟随着人的性别、年龄不同而有所不同。一般来说,男性说话者的基音频率较低,而女性说话者和小孩的基音频率相对较高。
基音周期的估计称谓基音检测,基音检测的最终目的是为了找出和声带振动频率完全一致或尽可能相吻合的轨迹曲线。到目前为止,基音检测的方法大致上可以分为三类:
时域估计法,直接由语音波形来估计基音周期,常见的有:自相关法、并行处理法、平均幅度差法、数据减少法等。
变换法,它是一种将语音信号变换到频域或者时域来估计基音周期的方法,首先利用同态分析方法将声道的影响消除,得到属于激励部分的信息,然后求取基音周期,最常用的就是倒谱法,这种方法的缺点就是算法比较复杂,但是基音估计的效果却很好。
混合法,先提取信号声道模型参数,然后利用它对信号进行滤波,得到音源序列,最后再利用自相关法或者平均幅度差法求得基音周期。语音信号是非稳态信号它的特征是随时间变化的,但在一个很短的时间段内可以认为具有相对稳定的特征即短时平稳性。因此语音具有短时自相关性。
例如一段男声读“播放”两个字的声音wav文件,其为16khz采样率,16bit量化。整段语音长656.7ms,节点共10508个。人声读一个字,约300ms,目前便携设备处理音频信息需时约20ms,在对特定人提取声道模型参数后,利用特定人语音的短时自相关性,几乎可以同步检测到特定人语音的实时基音,误差约20%。
经测试,对于人的日常讲话,主动降噪技术可以平均降低7分贝,减去日常讲话中间的停顿,降低约10分贝。目前要完全消除人声,技术上还达不到,但利用语音短时自相关性可以分离出基音,人在低声讲话时,通过主动降噪,还有翻译后播放英语的正常音量的掩蔽效应,可以使特定方向的人听不到中文。
而目前商用主动降噪芯片主要应用在耳机,主要处理50hz-2khz的中低频信号,最大降噪频率支持2.5khz。
人能够发出的音频信号的频率范围是30hz到3.6khz,正常的语音频率范围是30hz到1.1khz。男:低音82~392hz,基准音区64~523hz,男中音123~493hz,男高音164~698hz女:低音82~392hz,基准音区160~1200hz,女中音123~493hz,女高音220~1.1khz。
因此,目前需要一种同传翻译机,首先在部分通用的特定场景,如旅游、社区生活、日常交流、校园生活,实现人机自然交互与协作共融,通过同传翻译机,不同母语的人,像正常的人与人聊天一样,你一句我一句地交流。
技术实现要素:
本发明实施例提供了人机自然交互与协作共融的金融支付同传翻译机以解决翻译机实现人机自然交互与协作共融的问题。
本发明的目的之一是,提供一种同传翻译机,使不同母语的人,像正常的人与人聊天一样,你一句我一句地交流。
本发明通过以下技术方案实现上述目的。
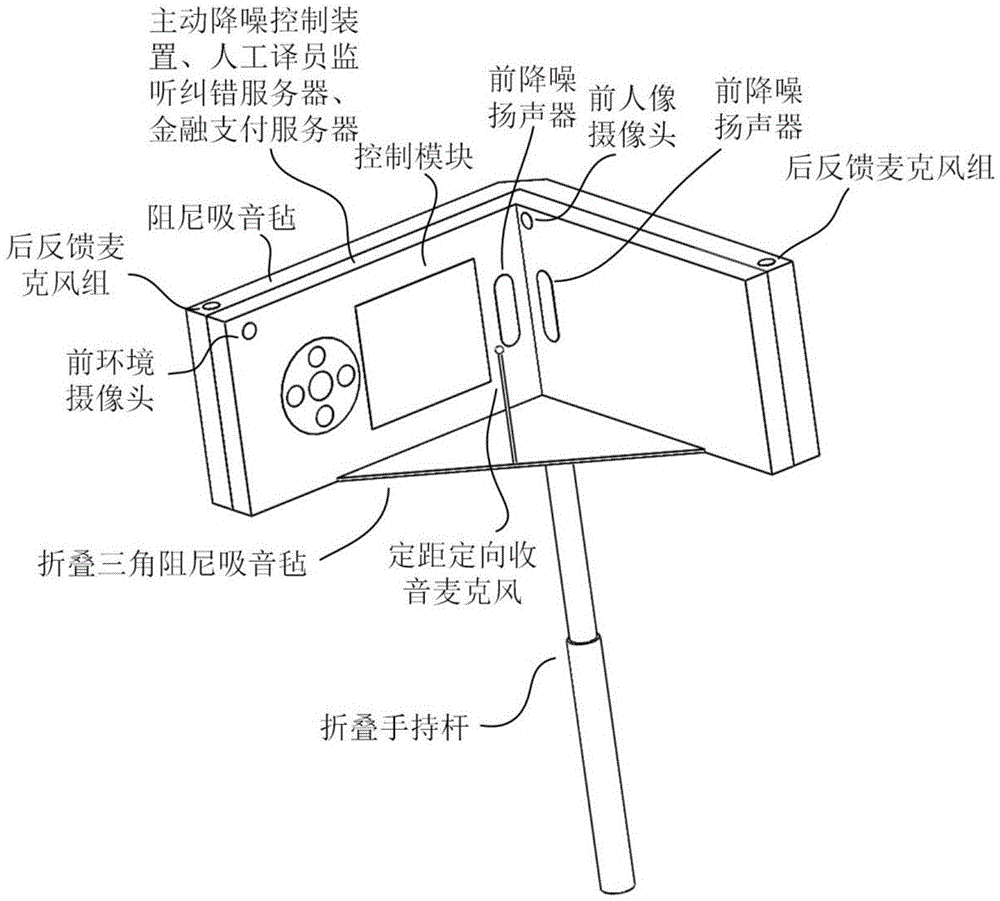
人机自然交互与协作共融的金融支付同传翻译机,包括翻译装置、主动降噪控制装置、折叠手持杆、阻尼吸音毡、折叠三角阻尼吸音毡、人工译员监听纠错服务器、金融支付服务器、环境摄像头组和挂耳耳机;所述的金融支付同传翻译机呈对折型状,收藏时折合,使用打开。
所述的翻译装置包括人工智能翻译引擎使用服务器、多模态深度语义理解服务器和控制模块;用于将使用人和对话人的讲话翻译成指定语言,分别发送到挂耳耳机和后指向放音扬声器,让对方收听。
人工智能翻译引擎使用服务器用于将使用人和对话人的讲话句子同时送谷歌翻译引擎、百度翻译引擎、科大讯飞引擎、微软翻译引擎,然后将4个翻译引擎返回结果进行人工智能语义分析,如果返回结果的差异未超标,选取使用人设定的翻译引擎的返回结果播放。
多模态深度语义理解服务器用于在将4个翻译引擎返回结果进行人工智能语义分析后,如果返回结果的差异超标,再送环境摄像头组拍摄到的3个方向的视频给多模态深度语义理解服务器进行面部表情捕捉和视频场景分析,要求多模态深度语义理解服务器通过面部表情和视频场景,返回4个翻译引擎返回结果的可信度,如果均低于一个标准,则通过金融支付服务器向人工译员远程纠错模块支付费用并请求人工核对;多模态深度语义理解服务器用于在翻译引擎开通面部表情与场景辅助翻译时,将分析结果连同待翻译句子一起送翻译引擎。
控制模块包括触摸屏幕、返回键、主页键、功能键、音量减键、音量加键、对话键和通讯单元;对话键位于折叠手持杆上。
所述的主动降噪控制装置包括前主动降噪模块、定距定向收音麦克风、前降噪扬声器、后主动降噪模块、后反馈麦克风组、后降噪扬声器组、掩盖模块、后指向收音麦克风和后指向放音扬声器。
前主动降噪模块用于通过定距定向收音麦克风在使用人嘴边拾取使用人说话的声音,生成大小相等、相位差180度的反向声波,由前降噪扬声器播放,消减使用人的声音;定距定向收音麦克风放置在折叠三角阻尼吸音毡的最长边中间,使用时拨起贴近到使用人嘴边,固定使用人嘴到所述同传翻译机的距离。
后主动降噪模块预先由使用人设定本人声道模型参数,从后反馈麦克风组拾取使用人说话声音和前降噪扬声器发出且未能与使用人说话声音抵消干净的反向声波,提取出使用人说话的声音基音,计算出部分泛音,合成后,由带通滤波器根据折叠定距定向收音麦克风的声音,生成大小相等、相位差180度的反向声波,由后降噪扬声器组播放,消减使用人在同传翻译机后面的声音。
掩盖模块用于在后指向放音扬声器播放预定的声音,提醒对话人,有人通过翻译机与其讲话,并借此掩盖使用人说话的声音。
后指向收音麦克风用于接收对话人讲话的声音,送翻译模块翻译。
后指向放音扬声器用于将译文播放给对话人收听,可选择投射号角定向扬声器或超声波定向扬声器,用于用译文掩盖使用人的声音。
所述的折叠手持杆包括对话键,用于支撑人机自然交互与协作共融的金融支付同传翻译机,可以收入和拉出。
所述的阻尼吸音毡用于包裹人机自然交互与协作共融的金融支付同传翻译机,吸收和消减使用人的声音。
所述的折叠三角阻尼吸音毡在金融支付同传翻译机收藏时,折叠在中间,金融支付同传翻译机打开时,在金融支付同传翻译机下方以三角形打开,用于吸收消减使用人声音和放置定距定向收音麦克风。
所述的人工译员监听纠错服务器用于连接到外语教师服务工作室,由外语教师进行即时外语纠错服务或事后外语纠错服务。
所述的金融支付服务器用于向外语教师服务工作室支付外语纠错费用,启用人工译员监听纠错服务器,当屏幕提示支付时,使用人按折叠手持杆的对话键确认支付。
所述的环境摄像头组包括前环境摄像头、前人像摄像头、后环境摄像头;前环境摄像头用于拍摄使用人方向的现场场景,前人像摄像头用于拍摄使用人面部,进行面部表情捕捉;后环境摄像头拍摄对话人方向的现场场景,并从中剪裁出对话人面部的画面,进行面部表情捕捉。
所述的挂耳耳机用于使用人收听对话人讲话的译文。
所述的部分泛音,频率分别为基频的2、3倍,在便携设备处理能力增加时,可按基频的整倍数增加泛音。
一种人机自然交互与协作共融的金融支付同传翻译机的使用方法,步骤如下。
a、使用人打开人机自然交互与协作共融的金融支付同传翻译机,折叠三角阻尼吸音毡自然打开,拉出折叠手持杆,拨起定距定向收音麦克风使其贴近嘴边,设置翻译语种、翻译差异标准、翻译可信度标准、使用人声道模型参数和用于掩盖的声音。
b、使用人调整身体姿势,正对着对话人并距离1米,持折叠手持杆的手指按下对话键,同传翻译机同时进行步骤c到g。
c、后指向放音扬声器发出预定的语音,礼貌地引起对话人注意,同时,使用人低声说出第一句母语,定距定向收音麦克风拾取语音并分别送到翻译装置和主动降噪控制装置。
d、前主动降噪模块接收到使用人声音后,生成反向声波,由前降噪扬声器对着使用人的口部播放,抵消使用人的声音。
e、后主动降噪模块接收到使用人声音后,按使用人声道模型参数,用自相关法提取出使用人声音的基音,计算出部分泛音并合成,作为干净的语音,从后反馈麦克风组拾取的使用人说话声音和前降噪扬声器声音作为含噪的语音,通过带通滤波器得出使用人在同传翻译机后面的声音并反相,从而得到的反向声波由后降噪扬声器组播放,抵消使用人在同传翻译机后面的声音。
f、人工智能翻译引擎将使用人讲话句子同时送谷歌翻译引擎、百度翻译引擎、科大讯飞引擎、微软翻译引擎,然后将4个翻译引擎返回结果进行人工智能语义分析,如果返回结果的差异未超标,选取使用人设定的翻译引擎的返回结果播放。
g、如果返回结果的差异超标,再送环境摄像头组拍摄到的3个方向的视频和4个翻译引擎的返回结果给多模态深度语义理解服务器进行面部表情捕捉和视频场景分析,返回4个翻译引擎返回结果的可信度,选取符合标准的返回结果在后指向放音扬声器播放给对话人收听;如果均低于一个标准,则通过金融支付服务器向人工译员远程纠错模块支付费用并请求人工核对。
h、对使用人的每一句话重复步骤d到g,直到使用人说完一段话。
i、后指向收音麦克风接收到对话人正常说出的第一句外语后,重复步骤f到g,其中翻译引擎返回结果在挂耳耳机中播放给使用人收听;对对话人的每一句话重复本步骤,直到对话人说完一段话。
j、重复步骤d到i,直到对话完成,使用人按下对话键结束对话。
本发明方法的有益效果是:通过分析对话双方的面部表情和现场场景,让翻译更准确,提供一种同传翻译机,消减对话一方的母语,使不同母语的人,像正常的人与人聊天一样,你一句我一句地交流。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
图1a:一种人机自然交互与协作共融的金融支付同传翻译机内侧。
图1b:一种人机自然交互与协作共融的金融支付同传翻译机外侧。
图2:一种人机自然交互与协作共融的金融支付同传翻译机的使用方法。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
实施例l一种人机自然交互与协作共融的金融支付同传翻译机。
如图la所示,本发明实施例人机自然交互与协作共融的金融支付同传翻译机,包括翻译装置、主动降噪控制装置、折叠手持杆、阻尼吸音毡、折叠三角阻尼吸音毡、人工译员监听纠错服务器、金融支付服务器、环境摄像头组和挂耳耳机;所述的金融支付同传翻译机呈对折型状,收藏时折合,使用打开。
所述的翻译装置包括人工智能翻译引擎使用服务器、多模态深度语义理解服务器和控制模块;用于将使用人和对话人的讲话翻译成指定语言,分别发送到挂耳耳机和后指向放音扬声器,让对方收听。
人工智能翻译引擎使用服务器用于将使用人和对话人的讲话句子同时送谷歌翻译引擎、百度翻译引擎、科大讯飞引擎、微软翻译引擎,然后将4个翻译引擎返回结果进行人工智能语义分析,如果返回结果的差异未超标,选取使用人设定的翻译引擎的返回结果播放。
多模态深度语义理解服务器用于在将4个翻译引擎返回结果进行人工智能语义分析后,如果返回结果的差异超标,再送环境摄像头组拍摄到的3个方向的视频给多模态深度语义理解服务器进行面部表情捕捉和视频场景分析,要求多模态深度语义理解服务器通过面部表情和视频场景,返回4个翻译引擎返回结果的可信度,如果均低于一个标准,则通过金融支付服务器向人工译员远程纠错模块支付费用并请求人工核对;多模态深度语义理解服务器用于在翻译引擎开通面部表情与场景辅助翻译时,将分析结果连同待翻译句子一起送翻译引擎。
控制模块包括触摸屏幕、返回键、主页键、功能键、音量减键、音量加键、对话键和通讯单元;对话键位于折叠手持杆上。
所述的主动降噪控制装置包括前主动降噪模块、定距定向收音麦克风、前降噪扬声器、后主动降噪模块、后反馈麦克风组、后降噪扬声器组、掩盖模块、后指向收音麦克风和后指向放音扬声器。
前主动降噪模块用于通过定距定向收音麦克风在使用人嘴边拾取使用人说话的声音,生成大小相等、相位差180度的反向声波,由前降噪扬声器播放,消减使用人的声音;定距定向收音麦克风放置在折叠三角阻尼吸音毡的最长边中间,使用时拨起贴近到使用人嘴边。
后主动降噪模块预先由使用人设定本人声道模型参数,从后反馈麦克风组拾取使用人说话声音和前降噪扬声器发出且未能与使用人说话声音抵消干净的反向声波,提取出使用人说话的声音基音,计算出部分泛音,合成后,由带通滤波器根据折叠定距定向收音麦克风的声音,生成大小相等、相位差180度的反向声波,由后降噪扬声器组播放,消减使用人在同传翻译机后面的声音。
掩盖模块用于在后指向放音扬声器播放预定的声音,提醒对话人,有人通过翻译机与其讲话,并借此掩盖使用人说话的声音。
后指向收音麦克风用于接收对话人讲话的声音,送翻译模块翻译。
后指向放音扬声器用于将译文播放给对话人收听,可选择投射号角定向扬声器或超声波定向扬声器,用于用译文掩盖使用人的声音。
所述的折叠手持杆包括对话键,用于支撑人机自然交互与协作共融的金融支付同传翻译机,可以收入和拉出。
所述的阻尼吸音毡用于包裹人机自然交互与协作共融的金融支付同传翻译机,吸收和消减使用人的声音。
所述的折叠三角阻尼吸音毡在金融支付同传翻译机收藏时,折叠在中间,金融支付同传翻译机打开时,在金融支付同传翻译机下方以三角形打开,用于吸收消减使用人声音和放置定距定向收音麦克风。
所述的人工译员监听纠错服务器用于连接到外语教师服务工作室,由外语教师进行即时外语纠错服务或事后外语纠错服务。
所述的金融支付服务器用于向外语教师服务工作室支付外语纠错费用,启用人工译员监听纠错服务器,当屏幕提示支付时,使用人按折叠手持杆的对话键确认支付。
所述的环境摄像头组包括前环境摄像头、前人像摄像头、后环境摄像头;前环境摄像头用于拍摄使用人方向的现场场景,前人像摄像头用于拍摄使用人面部,进行面部表情捕捉;后环境摄像头拍摄对话人方向的现场场景,并从中剪裁出对话人面部的画面,进行面部表情捕捉。
所述的挂耳耳机用于使用人收听对话人讲话的译文。
所述的部分泛音,频率分别为基频的2、3倍,在便携设备处理能力增加时,可按基频的整倍数增加泛音。
如图lb所示,一种人机自然交互与协作共融的金融支付同传翻译机外侧包括后反馈麦克风组、后降噪扬声器组、后环境摄像头、后指向收音麦克风和后指向放音扬声器。
实施例2一种人机自然交互与协作共融的金融支付同传翻译机的使用方法。
如图2所示,本发明实施例一种人机自然交互与协作共融的金融支付同传翻译机的使用方法,步骤如下。
a、使用人打开人机自然交互与协作共融的金融支付同传翻译机,折叠三角阻尼吸音毡自然打开,拉出折叠手持杆,拨起定距定向收音麦克风使其贴近嘴边,设置翻译语种、翻译差异标准、翻译可信度标准、使用人声道模型参数和用于掩盖的声音。
b、使用人调整身体姿势,正对着对话人并距离1米,持折叠手持杆的手指按下对话键,同传翻译机同时进行步骤c到g。
c、后指向放音扬声器发出预定的语音,礼貌地引起对话人注意,同时,使用人低声说出第一句母语,定距定向收音麦克风拾取语音并分别送到翻译装置和主动降噪控制装置。
d、前主动降噪模块接收到使用人声音后,生成反向声波,由前降噪扬声器对着使用人的口部播放,抵消使用人的声音。
e、后主动降噪模块接收到使用人声音后,按使用人声道模型参数,用自相关法提取出使用人声音的基音,计算出部分泛音并合成,作为干净的语音,从后反馈麦克风组拾取的使用人说话声音和前降噪扬声器声音作为含噪的语音,通过带通滤波器得出使用人在同传翻译机后面的声音并反相,从而得到的反向声波由后降噪扬声器组播放,抵消使用人在同传翻译机后面的声音。
f、人工智能翻译引擎将使用人讲话句子同时送谷歌翻译引擎、百度翻译引擎、科大讯飞引擎、微软翻译引擎,然后将4个翻译引擎返回结果进行人工智能语义分析,如果返回结果的差异未超标,选取使用人设定的翻译引擎的返回结果播放。
g、如果返回结果的差异超标,再送环境摄像头组拍摄到的3个方向的视频和4个翻译引擎的返回结果给多模态深度语义理解服务器进行面部表情捕捉和视频场景分析,返回4个翻译引擎返回结果的可信度,选取符合标准的返回结果在后指向放音扬声器播放给对话人收听,如果均低于一个标准,则通过金融支付服务器向人工译员远程纠错模块支付费用并请求人工核对。
h、对使用人的每一句话重复步骤d到g,直到使用人说完一段话。
i、后指向收音麦克风接收到对话人正常说出的第一句外语后,重复步骤f到g,其中翻译引擎返回结果在挂耳耳机中播放给使用人收听;对对话人的每一句话重复本步骤,直到对话人说完一段话。
j、重复步骤d到i,直到对话完成,使用人按下对话键结束对话。
本发明中应用了具体实施例对本发明的原理及实施方式进行了阐述,以上实施例的说明只是用于帮助理解本发明的方法及其核心思想;同时,对于本领域的一般技术人员,依据本发明的思想,在具体实施方式及应用范围上均会有改变之处,综上所述,本说明书内容不应理解为对本发明的限制。
- 还没有人留言评论。精彩留言会获得点赞!