一种语音交互方法、系统及装置与流程
本发明涉及语音交互技术领域,尤其是涉及一种语音交互方法、系统及装置。
背景技术:
随着移动互联网技术的不断进步,人们使用电子设备而出现的人机交互技术也在不断的发展,从普通的鼠标、键盘输入,到新近比较流行的轨迹球、触摸屏等,这些技术都以其良好的使用性能和输入速度,而得到了很好的普及和推广。
然而,以上这些技术都有一个共同的特点,就是需要用户通过敲击、滑动等操作来实现人与机器的交互,显然这并不符合在通常情况下人们沟通交流的方式。
随着语音识别技术的不断发展,根据客户的语音进行操作,为用户提供自然、友好的数据检索服务(例如家庭服务、宾馆服务、旅行社服务系统、订票系统、医疗服务、银行服务、股票查询服务等等)的方案也越来越成熟,这种方案更符合人的日常习惯,也更自然、更高效。例如:
d1:小米科技有限责任公司在2013年9月17日申请的公开号为cn103501382a的中国专利公开了一种语音服务提供方法、装置和终端,语音服务提供方法包括:接收应用程序发送的携带有待处理信息的语音服务请求;通过统一接口调用语音处理单元;通过统一接口获取语音处理单元对所述待处理信息进行处理后得到的结果信息,将结果信息反馈给应用程序。
d2:支持语音交互功能的小米ai音箱,其内容包括在线音乐、网络电台、有声读物、广播电台等,提供新闻、天气、闹钟、倒计时、备忘、提醒、时间、汇率、股票、限行、算数、查找手机、百科问答、闲聊、笑话、菜谱、翻译等各类功能。
但是,上述中的现有技术方案存在以下缺陷:现有的语音交互方案只能进行语音交互、控制智能家居等,不能帮用户在移动端进行服务操作(例如订车票、订机票、订景点、订酒店等)。
技术实现要素:
本发明的目的是提供一种语音交互方法、系统及装置。
发明目的一是:提供一种语音交互方法,其优点是用户能够通过语音在移动端进行服务查询和服务操作,更符合人们的日常操作习惯;
发明目的二是:提供一种语音交互系统,其优点是能够帮助用户在移动端高效的进行服务查询和服务操作;
发明目的三是:提供一种语音交互装置,其优点是能够使用户在移动端进行服务查询和服务操作时更自然、更高效。
本发明的上述发明目的一是通过以下技术方案得以实现的:
一种语音交互方法,包括:
获取移动终端录制的音频资源并将所述音频资源存储至本地服务器;
根据所述本地服务器存储的所述音频资源得到识别文本;
根据所述识别文本调用对应的后端查询接口;
所述后端查询接口根据所述识别文本得出反馈信息并将所述反馈信息返回至所述移动终端;
其中,所述反馈信息包括查询信息和/或下一步语音输入提示信息。
通过采用上述技术方案,将用户的录音存储到本地服务器,便于对录音进行分析和处理。而且,通过由录音转换的识别文本即可调用相关的服务用后端查询接口(例如订票接口、订酒店接口、订景点门票接口等),调用的后端查询接口能够根据识别文本得出反馈信息并将该反馈信息返回至移动终端,从而为用户呈现查询结果信息以及提醒用户进行下一步语音录入操作的提示信息。通过本方法,用户通过语音即可在移动端进行服务查询和服务操作,更符合人们的日常操作习惯。
本发明进一步设置为:获取移动终端录制的音频资源并将所述音频资源存储至本地服务器,包括:
检测所述移动终端的录音操作;
根据获取到的录音操作触发预设的语音识别指令,所述语音识别指令用于检测所述移动终端的录音状态信息;
在所述移动终端完成录音后,获取所述移动终端录制的音频资源id;
根据所述音频资源id下载所述移动终端中对应的音频资源并将下载的所述音频资源存储至本地服务器;
将所述音频资源转换为设定格式的音频资源。
通过采用上述技术方案,能够更加准确和高效的将音频资源下载到本地服务器,利于提高音频资源处理速度,进而提高用户体验。
本发明进一步设置为:根据所述本地服务器存储的所述音频资源得到识别文本,包括:
检测所述音频资源转换的进度;
在所述音频资源转换完成后,调用自然语言识别接口将转换后的所述设定格式的音频资源转为识别文本并将所述识别文本进行语义化处理;
将经过语义化处理的所述识别文本进行拆分并提取一类特征信息,所述一类特征信息包括时间信息、地理目标信息和目的信息中的至少一种。
通过采用上述技术方案,能够快速提取服务查询和服务操作的关键信息,从而快速响应及快速为用户提供反馈信息。
本发明进一步设置为:根据所述识别文本调用对应的后端查询接口,包括:
获取所述一类特征信息的种类数值m;
判断所述种类数值m是否等于预设值n;
若所述种类数值m等于所述预设值n,则调用对应的后端查询接口;
若所述种类数值m小于所述预设值n,则根据缺少的一类特征信息种类在提问库中提取对应的提问信息;
将所述提问信息以文字和/或语音的形式展示给用户;
获取所述用户根据所述提问信息录制的补充音频资源;
根据所述补充音频资源得到补充识别文本;
将所述补充识别文本进行拆分并提取补充一类特征信息;
将所述补充一类特征信息与所述一类特征信息进行整合并形成新的一类特征信息。
通过采用上述技术方案,当从用户语音中提取的关键信息不完整时,能够引导用户继续录入相关语音,从而顺利且高效的完成整个服务查询和服务操作的流程。
本发明进一步设置为:若所述种类数值m小于所述预设值n,则根据缺少的一类特征信息的种类在提问库中提取对应的提问信息,包括:
若所述种类数值m小于所述预设值n,则根据缺少的一类特征信息种类在提问库中提取对应的候选提问信息;
根据所述候选提问信息产生针对所述缺少的一类特征信息种类的提问数据集,所述提问数据集包括与所述缺少的一类特征信息种类对应的至少一个候选提问信息和所述至少一个候选提问信息中的每一个候选提问信息被用作提问信息的优先级;
根据所述提问数据集计算出条件概率模型,所述条件概率模型包括所述至少一个候选提问信息和所述至少一个候选提问信息中的每一个候选提问信息历史呈现给所述用户的频率;
根据所述条件概率模型和所述提问数据集对所述至少一个候选提问信息中的每一个候选提问信息进行综合排序,并将排序最前的候选提问信息作为提问信息。
通过采用上述技术方案,能够按照候选提问信息历史呈现给用户的频率为用户匹配最佳的提问信息,利于提高用户的视觉新鲜感,从而达到提高用户体验的目的。
本发明的上述发明目的二是通过以下技术方案得以实现的:
一种语音交互系统,包括:
获取模块,其用于获取移动终端录制的音频资源并将所述音频资源存储至本地服务器,所述本地服务器还用于将所述音频资源转换为设定格式的音频资源;
提取模块,其用于根据所述本地服务器转换得到的所述设定格式的音频资源得到识别文本;
调用模块,其用于根据所述提取模块得到的所述识别文本调用对应的后端查询接口,所述后端查询接口用于根据所述识别文本得出反馈信息;
反馈模块,其用于将所述后端查询接口得出的所述反馈信息返回至所述移动终端;
其中,所述获取模块获取所述移动终端录制的所述音频资源前,先获取与所述音频资源对应的音频资源id,然后根据所述音频资源id下载所述移动终端内的所述音频资源;所述反馈信息包括查询信息和/或下一步语音输入提示信息。
通过采用上述技术方案,用户触发系统的语音录入功能且语音录入完成后,系统会自动下载该用户语音并将该用户语音转为识别文本。系统根据该识别文本,即可调用对应的查询接口,从而向用户终端返回查询结果信息以及返回用于提醒用户进行下一步语音录入操作的提示信息。通过本系统,能够帮助用户在移动端高效的进行服务查询和服务操作。
本发明进一步设置为:所述提取模块包括:
检测单元,其用于检测所述本地服务器中的所述音频资源的转换进度;
处理单元,其用于当所述检测单元检测到所述音频资源转换完成后,调用自然语言识别接口将转换后的所述设定格式的音频资源转为识别文本并将所述识别文本进行语义化处理;
提取子单元,其用于将经过语义化处理的所述识别文本进行拆分并提取一类特征信息,所述一类特征信息包括时间信息、地理目标信息和目的信息中的至少一种。
通过采用上述技术方案,能够快速提取到用户语音中的关键信息,从而为用户的服务查询和服务操作提供快速响应支持。
本发明进一步设置为:所述调用模块包括:
识别单元,其用于获取所述识别文本中一类特征信息的种类数值m;
判断单元,其用于判断所述种类数值m是否等于预设值n;
调用子单元,其用于当所述判断单元判断所述种类数值m等于所述预设值n时,调用对应的后端查询接口;其还用于当所述判断单元判断所述种类数值m小于所述预设值n时,根据缺少的一类特征信息种类在提问库中提取对应的提问信息;
反馈子单元,其用于将所述调用子单元提取的所述提问信息以文字和/或语音的形式展示给用户;
获取子单元,其用于获取所述用户根据所述提问信息录制的补充音频资源;
补充单元,其用于根据所述获取子单元获取的所述补充音频资源得到补充识别文本;
拆分单元,其用于将所述补充单元得到的所述补充识别文本进行拆分并提取补充一类特征信息;
整合单元,其用于将所述拆分单元提取的所述补充一类特征信息与所述提取子单元提取的所述一类特征信息进行整合并形成新的一类特征信息。
通过采用上述技术方案,能够引导用户录入正确的语音信息,从而顺利且高效的帮用户完成整个服务查询和服务操作的流程,用户体验佳。
本发明进一步设置为:所述调用子单元包括:
匹配单元,其用于当所述判断单元判断所述种类数值m小于所述预设值n时,根据缺少的一类特征信息种类在提问库中提取对应的候选提问信息;
数据集子单元,其用于根据所述匹配单元提取的所述候选提问信息产生针对所述缺少的一类特征信息种类的提问数据集,所述提问数据集包括与所述缺少的一类特征信息种类对应的至少一个候选提问信息和所述至少一个候选提问信息中的每一个候选提问信息被用作提问信息的优先级;
模型计算单元,其用于根据所述提问数据集计算出条件概率模型,所述条件概率模型包括所述至少一个候选提问信息和所述至少一个候选提问信息中的每一个候选提问信息历史呈现给所述用户的频率;
排序单元,其用于根据所述条件概率模型和所述提问数据集对所述至少一个候选提问信息中的每一个候选提问信息进行综合排序,并将排序最前的所述候选提问信息作为所述提问信息。
通过采用上述技术方案,在前一环节用户语音中的关键信息不完整的情况下,系统最终向用户呈现的是最优的提问信息,利于提高用户体验。
本发明的上述发明目的三是通过以下技术方案得以实现的:
一种语音交互装置,包括上述的语音交互系统。
通过采用上述技术方案,用户通过语音即可进行服务查询和服务操作,能够使用户在移动端进行服务查询和服务操作时更自然、更高效。
综上所述,本发明的有益技术效果为:
1、用户通过语音即可在移动端进行服务查询和服务操作,更符合人们的日常操作习惯;
2、通过将用户语音转为识别文本,并通过识别文本调用对应的后端查询接口,能够帮助用户在移动端高效的进行完整的服务查询流程和完整的服务操作流程;
3、当用户语音中的关键信息不完整时,用户能够根据移动终端展示的优选的提问信息继续录入补充音频资源,从而使用户在移动端进行服务查询和服务操作时更自然、更高效。
附图说明
图1是本发明实施例一示出的语音交互方法的流程示意图;
图2是本发明实施例一示出的步骤s10的流程示意图;
图3是本发明实施例一示出的步骤s20的流程示意图;
图4是本发明实施例一示出的步骤s30的流程示意图;
图5是本发明实施例一示出的子步骤s33的流程示意图;
图6是本发明实施例二示出的语音交互系统的结构示意图;
图7是本发明实施例三示出的调用子单元的结构示意图。
图中,10、获取模块;20、提取模块;21、检测单元;22、处理单元;23、提取子单元;30、调用模块;31、识别单元;32、判断单元;33、调用子单元;34、反馈子单元;35、获取子单元;36、补充单元;37、拆分单元;38、整合单元;40、反馈模块;50、匹配单元;51、数据集子单元;52、模型计算单元;53、排序单元。
具体实施方式
以下结合附图对本发明作进一步详细说明。
实施例一
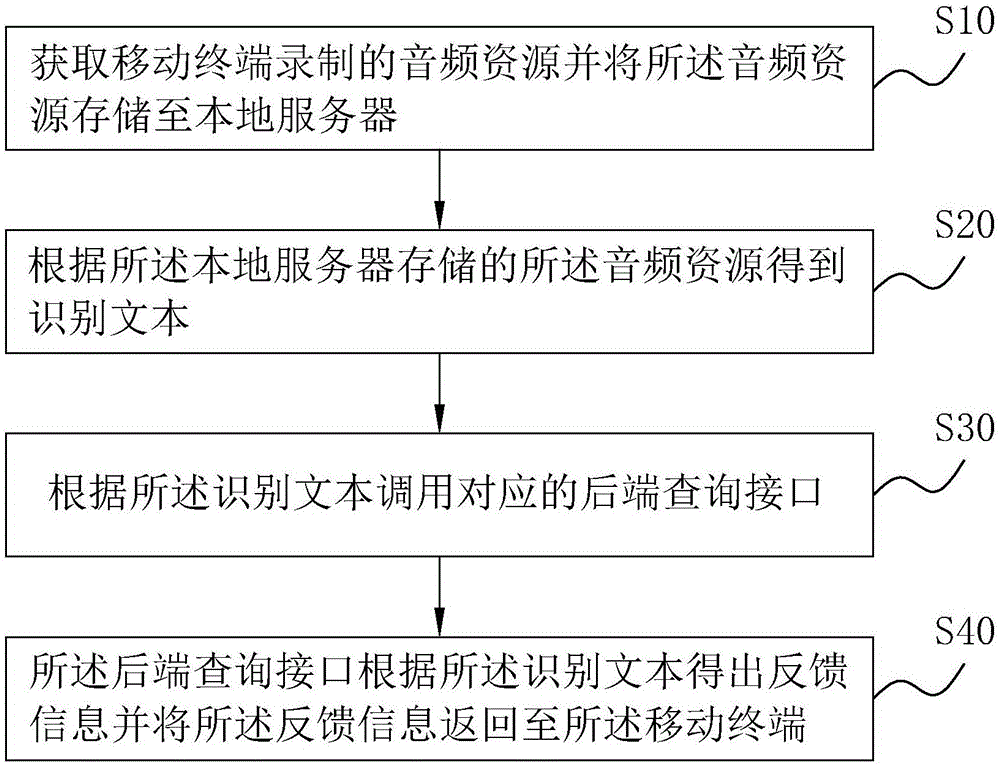
参照图1,为本发明公开的一种语音交互方法,包括以下步骤:
s10、获取移动终端录制的音频资源并将音频资源存储至本地服务器。
需要说明的是,移动终端录制的音频资源的格式为amr格式。本步骤基于原生客户端(例如微信、qq)的语音录制功能(即本发明方法是基于原生客户端),当用户触发本发明方法的语音识别功能时,前端javascript代码调用原生客户端暴露的jsapi,让用户间接触发原生客户端内的自然语言识别功能。
s20、根据本地服务器存储的音频资源得到识别文本。
具体的,从原生客户端下载的用户语音会存储在本地服务器中,便于对用户语音进行分析,从而得到准确的识别文本。
s30、根据识别文本调用对应的后端查询接口。
具体的,后端查询接口包括用于订购火车票等车票的“站站”查询接口、用于订购酒店的酒店查询接口、用于订购景点门票等的景点查询接口等。
s40、后端查询接口根据识别文本得出反馈信息并将反馈信息返回至移动终端。
其中,反馈信息包括查询信息和/或下一步语音输入提示信息。具体的,以订购火车票为例,当用户语音中含有的关键信息(例如出发城市、到达城市、出发日期、发车时间等)完整时,即向该用户展示对应的车次信息和下一步语音输入提示信息(例如提示用户语音输入车次号、坐席类型等);当用户车次、坐席选择完毕后,继续向用户呈现相应的反馈信息以及下一步的语音输入提示信息(例如乘客信息、手机号信息等);在用户信息全部确认完成后,会自动提交相应订单并向用户展示订单状态信息(例如正在提交、提交成功、提交失败等)。
参照图2,步骤s10包括以下子步骤:
s11、检测移动终端的录音操作。具体的,即检测用户是否正在使用本发明方法的录音功能。
s12、根据获取到的录音操作触发预设的语音识别指令,语音识别指令用于检测移动终端的录音状态信息。具体的,当检测到用户正在使用本发明方法的录音功能时,还会检测该录音的状态信息,即检测录音是否完成或录音中途取消(参照微信app中录音取消功能)。
s13、在移动终端完成录音后,获取移动终端录制的音频资源id。
s14、根据音频资源id下载移动终端中对应的音频资源并将下载的音频资源存储至本地服务器。
s15、将音频资源转换为设定格式的音频资源。具体地,本地服务器下载的音频资源格式为amr,转换后的音频资源格式为mp3。
参照图3,步骤s20包括以下子步骤:
s21、检测音频资源转换的进度。具体的,在音频格式转换过程中,服务器会集成一个转换进度条,以便于对音频资源的转换进度进行捕捉。
s22、在音频资源转换完成后,调用自然语言识别接口将转换后的mp3格式的音频资源转为识别文本并将该识别文本进行语义化处理。
s23、将经过语义化处理的识别文本进行拆分并提取一类特征信息,一类特征信息包括时间信息、地理目标信息和目的信息中的至少一种。
其中,若经过语义化处理的识别文本能够对应语义分析的模板,则继续对其进行拆分并提取一类特征信息;若经过语义化处理的识别文本不能够对应语义分析的模板,则生成空白文本,即步骤s30中后端查询接口不进行查询相关运作。
具体的,以订购火车票为例,时间信息为出发日期和发车时间(发车时间可以为具体的“几点钟”,也可以为“上午”、“下午”、“晚上”等时间范围概念,出发日期可以为“明天”、“后天”等日期概念),地理目标信息为出发城市和到达城市(当用户用于其它服务例如订景点时,地理目标信息则为“目标城市”),目的信息为车票(即订购火车票,当用户用于其它服务例如订酒店时,目的信息则为“酒店”)。
应注意的是,当时间信息、地理目标信息和目的信息均获取完成且为用户展示了反馈信息后,会进入下一环节的语音交互。以订购火车票为例,在向用户展示对应的车次信息后,会向该用户展示下一环节的语音输入提示信息(例如提示用户语音输入车次号、坐席类型等),当用户录制完成相关的语音资源后,将该语音资源进行文本转化并提取的一类特征信息即为车次号信息和坐席类型信息;当该环节结束后,还会进入用户信息录入并确认的环节以及提交订单的环节,直至用户的订单提交完成或用户放弃订购。
参照图4,步骤s30包括以下子步骤:
s31、获取一类特征信息的种类数值m。
s32、判断种类数值m是否等于预设值n。
其中,以订购火车票的第一个环节(即向用户展示车次信息的环节)为例,m≤3,n=3;当进入订购火车票的第二环节(即用户确认车次和坐席的环节)时,m≤2,n=2;当进入订购火车票的第三环节(即用户录入乘客信息的环节)时,m≤2,n=2。
s33、判断种类数值m是否等于预设值n。若种类数值m小于预设值n,则根据缺少的一类特征信息种类在提问库中提取对应的提问信息。若种类数值m等于所述预设值n,则进入子步骤s39。
s34、将提问信息以文字和/或语音的形式展示给用户。
s35、获取用户根据提问信息录制的补充音频资源。
s36、根据补充音频资源得到补充识别文本。
s37、将补充识别文本进行拆分并提取补充一类特征信息。
s38、将补充一类特征信息与相应的一类特征信息进行整合并形成新的一类特征信息。
s39、调用对应的后端查询接口。
参照图5,步骤s33中“若种类数值m小于预设值n,则根据缺少的一类特征信息种类在提问库中提取对应的提问信息”包括以下子步骤:
s50、若种类数值m小于预设值n,则根据缺少的一类特征信息种类在提问库中提取对应的候选提问信息。具体地,缺少的一类特征信息种类可能是一种也可能是多种,若缺少的一类特征信息种类是多种,则在提问库中提取的候选提问信息是与缺少的多种一类特征信息种类对应的。例如,在订购车票的第一环节,若缺少出发城市和出发日期,则候选提问信息可以为“请提供您的出发城市和出发日期”。
s51、根据候选提问信息产生针对缺少的一类特征信息种类的提问数据集,提问数据集包括与缺少的一类特征信息种类对应的至少一个候选提问信息和至少一个候选提问信息中的每一个候选提问信息被用作提问信息的优先级。
s52、根据提问数据集计算出条件概率模型,条件概率模型包括至少一个候选提问信息和至少一个候选提问信息中的每一个候选提问信息已经呈现给过用户的频率。
s53、根据条件概率模型和提问数据集对至少一个候选提问信息中的每一个候选提问信息进行综合排序,并将排序最前的候选提问信息作为最终的提问信息。
具体的,假设提问数据集中与缺少的一类特征信息种类对应的候选提问信息有w个,则通过条件概率模型将这w个候选提问信息分为集合一和集合二,其中,集合一内的候选提问信息已经呈现给过用户的频率均小于或等于1/w,集合二内的候选提问信息已经呈现给过用户的频率均大于1/w。对这w个候选提问信息进行综合排序时,集合二内的候选提问信息排序在后,集合一内的候选提问信息排序在前,且集合一内的候选提问信息按照被用作提问信息的优先级从前往后排列。最终,集合一内排序最前的候选提问信息被作为提问信息,这个被作为提问信息的候选提问信息在集合一内的优先级最高。
实施例二
参照图6,为本发明公开的一种语音交互系统,包括获取模块10、提取模块20、调用模块30和反馈模块40。获取模块10用于获取移动终端录制的音频资源并将音频资源存储至本地服务器,本地服务器还用于将音频资源转换为设定格式的音频资源。
需要说明的是,移动终端录制的音频资源的格式为amr格式,本地服务器转换后的音频资源的格式为mp3格式。获取模块10是基于原生客户端(例如微信、qq)的语音录制功能(即本系统是基于原生客户端),当用户触发系统的语音识别功能时,前端javascript代码调用原生客户端暴露的jsapi,让用户间接触发原生客户端内的自然语言识别功能。
参照图6,提取模块20用于根据本地服务器转换得到的mp3格式的音频资源得到识别文本。调用模块30用于根据提取模块20得到的识别文本调用对应的后端查询接口,后端查询接口用于根据识别文本得出反馈信息。反馈模块40用于将后端查询接口得出的反馈信息返回至移动终端,移动终端将该反馈信息以语音和/或文字的方式展示给用户。
需要说明的是,获取模块10获取移动终端录制的音频资源前,先获取与音频资源对应的音频资源id,然后根据该音频资源id下载移动终端内的音频资源,并将下载的音频资源存储至本地服务器。
其中,后端查询接口包括用于订购火车票等车票的“站站”查询接口、用于订购酒店的酒店查询接口、用于订购景点门票等的景点查询接口等,反馈信息包括查询信息和/或下一步语音输入提示信息。具体的,以订购火车票为例,当用户语音中含有的关键信息(例如出发城市、到达城市、出发日期、发车时间等)完整时,即向该用户展示对应的车次信息和下一步语音输入提示信息(例如提示用户语音输入车次号、坐席类型等);当用户车次、坐席选择完毕后,继续向用户呈现相应的反馈信息以及下一步的语音输入提示信息(例如乘客信息、手机号信息等);在用户信息全部确认完成后,会自动提交相应订单并向用户展示订单状态信息(例如正在提交、提交成功、提交失败等)。
参照图6,提取模块20包括检测单元21、处理单元22和提取子单元23。检测单元21用于检测本地服务器中的音频资源的转换进度。当检测单元21检测到音频资源转换完成后,处理单元22会调用自然语言识别接口将转换后的mp3格式的音频资源转为识别文本,并将该识别文本进行语义化处理。提取子单元23用于将经过语义化处理的识别文本进行拆分并提取一类特征信息。其中,若经过语义化处理的识别文本能够对应语义分析的模板,则继续对其进行拆分并提取一类特征信息;若经过语义化处理的识别文本不能够对应语义分析的模板,则生成空白文本,后端查询接口接收空白文本后不进行查询相关运作。
具体的,一类特征信息包括时间信息、地理目标信息和目的信息中的至少一种。以订购火车票为例,时间信息为出发日期和发车时间(发车时间可以为具体的“几点钟”,也可以为“上午”、“下午”、“晚上”等时间范围概念,出发日期可以为“明天”、“后天”等日期概念),地理目标信息为出发城市和到达城市(当用户用于其它服务例如订景点时,地理目标信息则为“目标城市”),目的信息为车票(即订购火车票,当用户用于其它服务例如订酒店时,目的信息则为“酒店”)。
应注意的是,当时间信息、地理目标信息和目的信息均获取完成且反馈模块40向移动终端返回了反馈信息后,会进入下一环节的语音交互。以订购火车票为例,在反馈模块40向移动终端发送了对应的车次信息后,反馈模块40还会向该移动终端发送下一环节的语音输入提示信息(例如提示用户语音输入车次号、坐席类型等)。当用户录制完成相关的语音资源后,获取模块10会获取该音频资源并将该音频资源存储至本地服务器,另外,提取模块20会将该语音资源进行文本转化并提取一类特征信息,此处的一类特征信息为车次号信息和坐席类型信息。当该环节结束后,还会进入乘客信息录入并确认的环节以及提交订单的环节,直至用户的订单提交完成或用户放弃订购。
参照图6,调用模块30包括识别单元31、判断单元32、调用子单元33、反馈子单元34、获取子单元35、补充单元36、拆分单元37和整合单元38。识别单元31用于获取识别文本中一类特征信息的种类数值m,判断单元32用于判断种类数值m是否等于预设值n。其中,以订购火车票的第一个环节(即向用户展示车次信息的环节)为例,m≤3,n=3;在订购火车票的第二环节(即用户确认车次和坐席的环节),m≤2,n=2;在订购火车票的第三环节(即用户录入乘客信息的环节),m≤2,n=2。
参照图6,当判断单元32判断种类数值m等于预设值n时,调用子单元33会调用对应的后端查询接口。当判断单元32判断种类数值m小于预设值n时,调用子单元33根据缺少的一类特征信息种类在提问库中提取对应的提问信息。反馈子单元34用于将调用子单元33提取的提问信息发送给移动终端,移动终端以文字和/或语音的形式将该反馈信息展示给用户。获取子单元35用于获取用户根据提问信息录制的补充音频资源。补充单元36用于根据获取子单元35获取的补充音频资源得到补充识别文本。拆分单元37用于将补充单元36得到的补充识别文本进行拆分并提取补充一类特征信息。整合单元38用于将拆分单元37提取的补充一类特征信息与提取子单元23提取的一类特征信息进行整合并形成新的一类特征信息。形成新的一类特征信息后,识别单元31会重新检测该新的一类特征信息的种类数值m,并且判断单元32会重新判断该种类数值m是否等于预设值n,从而判断调用子单元33是否调用对应的后端查询接口。
参照图7,调用子单元33包括匹配单元50、数据集子单元51、模型计算单元52和排序单元53。当判断单元32判断种类数值m小于预设值n时,匹配单元50根据缺少的一类特征信息种类在提问库中提取对应的候选提问信息。具体地,缺少的一类特征信息种类可能是一种也可能是多种,若缺少的一类特征信息种类是多种,则在提问库中提取的是与缺少的多种一类特征信息种类对应的候选提问信息。例如,在订购车票的第一环节,若缺少出发城市和出发日期,则候选提问信息可以为“请提供您的出发城市和出发日期”。
参照图7,数据集子单元51用于根据匹配单元50提取的候选提问信息产生针对缺少的一类特征信息种类的提问数据集,提问数据集包括与缺少的一类特征信息种类对应的至少一个候选提问信息和至少一个候选提问信息中的每一个候选提问信息被用作提问信息的优先级。模型计算单元52用于根据提问数据集计算出条件概率模型,条件概率模型包括至少一个候选提问信息和至少一个候选提问信息中的每一个候选提问信息历史呈现给用户的频率。排序单元53用于根据条件概率模型和提问数据集对至少一个候选提问信息中的每一个候选提问信息进行综合排序,并将排序最前的候选提问信息作为提问信息。
需要说明的是,设提问数据集中与缺少的一类特征信息种类对应的候选提问信息有w个,模型计算单元52通过条件概率模型将这w个候选提问信息分为集合一和集合二,其中,集合一内的候选提问信息已经呈现给过用户的频率均小于或等于1/w,集合二内的候选提问信息已经呈现给过用户的频率均大于1/w。排序单元53对这w个候选提问信息进行综合排序时,集合二内的候选提问信息排序在后,集合一内的候选提问信息排序在前,且集合一内的候选提问信息按照被用作提问信息的优先级从前往后排列。最终,排序单元53将集合一内排序最前的候选提问信息作为提问信息,这个被作为提问信息的候选提问信息在集合一内的优先级是最高的。
实施例三
一种语音交互装置,包括实施例二。
本具体实施方式的实施例均为本发明的较佳实施例,并非依此限制本发明的保护范围,故:凡依本发明的结构、形状、原理所做的等效变化,均应涵盖于本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!