一种用于构造高维卷积加速神经网络的方法与流程
本发明涉及一种高维卷积技术,特别是一种用于构造高维卷积加速神经网络的方法。
背景技术:
高维卷积广泛应用于各种学科,如视觉匹配中用级联卷积表示广义拉普拉斯距离、全连接的crfs推论中采用了高维高斯卷积进行有效的信息传递、将双边滤波器转换为维度升高的高维空间中的卷积,等等。但由于高维卷积的计算复杂度较高,存在严重的性能问题,所以在过去的几十年里,人们采用了手工的方法为高斯卷积设计快速算法,但最近对各种非高斯卷积的需求已经出现,争议性也越来越大,而且原来的手工加速方法是一项耗时费力的工作,已经不再适用于多种不同类型的卷积。
当前最流行的高斯模糊加速算法splatting-blurring-slicing(sbs)归功于数据缩减和可分离内核,首先像素被“splatting”(下采样)到网格上以减小数据大小,然后对网格顶点进行“blurring”(模糊)操作,最后通过“slicing”(上采样)产生每个像素的滤波值。由于可分离的模糊内核,在这些顶点上执行的d-d高斯模糊可以视为若干可分离的1-d滤波器的总和,因此一个d-d卷积(1)的计算复杂度从o(rd)减少到了o(rd),又因为splatting之后滤波窗口变得很小,计算复杂度可粗略地视为与半径r无关的o(d),但是该算法不能逼近非高斯卷积而且对于如何改善逼近误差没有理论依据。
现在流行的双边网格和全自显晶体格加速方法都属于sbs流程,我们的方法是将sbs重新设计为一个加速神经网络accnet,是目前首个通过神经网络对高维卷积进行加速的方法,有以下几个优势:1、为基于sbs的加速算法提供了统一的视角;2、卷积层权重与激活函数g一起定义了splatting、blurring和slicing卷积,所以可以轻松地从训练有素的网格中获得新的splatting、blurring和slicing卷积,以实现任意的卷积。这种能力赋予我们的网络以端到端的特征;3、accnet可以在训练中保证最小的逼近误差。
技术实现要素:
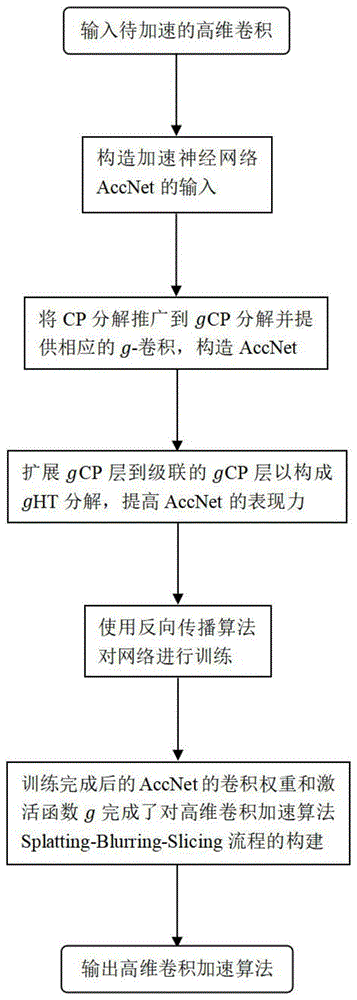
本发明的目的在于提供一种用于构造高维卷积加速神经网络的方法,包括以下步骤:
步骤1;输入待加速的高维卷积;
步骤2,构造加速神经网络accnet的输入;
步骤3,将cp分解扩展到gcp分解并提供相应的g-卷积,构成加速神经网络accnet;
步骤4,扩展gcp分解到级联gcp分解;
步骤5,计算函数sum和激活函数g的梯度并对网络进行训练;
步骤6,从训练有素的accnet中提取高维卷积的加速算法。
本发明与现有技术相比,具有以下优点:(1)为基于sbs(splatting-blurring-slicing)流程的加速算法提供了统一的视角;(2)加速网络的卷积层权重与激活函数g一起定义了splatting、blurring和slicing操作,所以可以轻松地从训练有素的加速神经网络中获得新的splatting、blurring和slicing操作,以实现任意的卷积。这种能力赋予我们的网络以端到端的特征;而且本专利是高维卷积加速领域首例神经网络加速方式;(3)加速神经网络(accnet)可以在训练中保证最小的逼近误差。
下面结合说明书附图对本发明作进一步描述。
附图说明
图1是本发明的流程图。
图2(a)是gcp层演示图,图2(b)是级联gcp层演示图,图2(c)是accnet的演示图。
具体实施方式
结合图1,一种用于产生快速高维卷积算法的加速神经网络accnet,包含(1)将splatting、blurring和slicing操作解释为卷积;(2)gcp分解和g-卷积;(3)扩展gcp层;(4)accnet的构造和训练;(5)提取sbs流程,共五个过程。
将splatting、blurring和slicing操作解释为卷积包括以下步骤:
步骤1,splatting将空间素化为规则网格,并将输入嵌入到网格的离散化顶点中,以减小数据大小。每个顶点的值是其附近输入值的加权和,即splatting操作以s为步幅进行卷积,这里s表示晶体格顶点之间的间隔。
步骤2,slicing是splatting的逆操作。由于slicing值是相邻顶点的加权和,所以slicing操作也等同于卷积操作,更准确的说,slicing表现为完全卷积网络的反卷积层,它是通过卷积进行上采样的。
步骤3,blurring是卷积的别名。在1-d情况下,卷积的完整内核实现需要每个像素rd次(乘加)运算,其中r是卷积核的半径。如果内核是可分离的,通过沿着每个轴方向顺序执行1-d卷积可以对其进行加速(则每个像素需要dr次操作)。在数学上,可分离的内核k是秩为1的张量(d维向量{kn,n=1,…,d}的外积),如式(2),继而内核k的卷积变为式(3),其中,i是输入的图像,i'是滤波后的输出图像,k代表滤波核函数。
k=k1○k2…○kd(2)
i′=k*i=k1*k2…kd*i(3)
对于任意内核,可以通过张量分解(cp分解)将其重新表示为若干秩为1的张量的总和,得到式(4)和式(5)。其中n表示图像i的总深度(维度),i表示图像的第i个维度,ωi则表示图像的第i维的滤波核函数的权重,
gcp分解和g-卷积包括以下步骤:
本质上,是通过神经网络分解滤波内核,因为一旦得到式(4),就可以根据式(5)对卷积进行加速。在这两个等式中,基本构建块是乘法和加法。如果其中一个被其他操作替换,就获得了新的cp分解式(4)和可分离卷积式(5),即得到了新的splatting,blurring和slicing操作。所以将式(4)推广到gcp分解并提供相应的g-卷积
步骤4,将式(4)中每个元素
假设激活函数g:r×r→r表示乘法,
有
其中a×gb=g(a,b)=ab。
设g为激活函数,
使得
此外,用g替代式(1)中的乘法并获得g-卷积式(7)
把式(6)带入式(7),得到式(8),其顺序执行n个1-dg-卷积。
步骤5,式(7)中的kpq和iq形成两个d阶张量,并用
定义lj是一个向量并将
定义
定义
定义
激活函数g为这三个操作引入了非线性。
图2a描述了gcp层的整个框架,其中输入是矩阵,g-aff映射把由输入中的黑线表示的
扩展gcp层包含以下步骤:
步骤6,级联gcp层作为ght(ghierarchicalturker)分解:神经网络的表达能力与层的深度密切相关,所以级联多个gcp层以扩展其表现力。如果把g-mul池中的全局池更换为局部池,输出即为矩阵。类似地,如果增加最后一个操作的输出数(g-avg池转换为g-aff映射),则输出将是一个向量。通过这种方式,gcp层将矩阵映射到另一个矩阵,可以将两个cp层级联在一起。图2b提供了两个级联gcp层的演示,将第一个gcp层的最后一个g-aff映射和第二个gcp层的第一个g-aff映射合并为一个g-aff映射。
步骤7,级联gcp实现了ght分解,用g替换ht分解中的乘法。例如,对于具有两层的4阶张量k的ght分解可以表示为(11)
其中
其中n2表示阶数(4阶张量k,为4),n1表示图像的维度
把(11)放入卷积公式,得到(12)
其中
比较(12)与图2b中的结构,运算符
accnet的构造和训练包含以下步骤:
步骤8,输入:步骤5、6、7中都假设
步骤9,由于双边网格或全自显晶体格上的每个顶点pi的模糊值都取决于其邻域的值(图像块
步骤10,splatting构成跨步卷积。理论上来说,卷积核k是任意的。在这里,我们假设k=k1○g…○gkd是accnet中的一阶张量,原因如下:1、accnet采用三层来近似卷积结果,尽管splatting层的操作是简单的,也可以通过增加blurring层的复杂度来减少逼近误差。2、blurring层的输入张量的每个切片必须是秩为1的矩阵,并且对于一阶输入张量
步骤11,blurring:采用级联gcp层来构成accnet的blurring层,因为它比单个gcp层具有更强大的表现力。图2c提供了两个gcp层示例。对于每个切片
步骤12,slicing:定义
步骤13,g函数:该函数在我们的accnet中起着重要作用。首先,它为accnet引入了非线性,增强了accnet的表现力。其次,它定义了新的卷积,使用g-conv操作,我们可以很容易地定义新的splatting,blurring和slicing操作。实际上存在很多g函数满足关联性g(g(a,b),c)=g(a,g(b,c))和交换性g(a,b)=g(b,a)。这里列出我们在accnet中使用的两个g函数:(1)g(a,b)=max{a,0};(2)g(a,b)=max{ab,0}。
步骤14,可以很容易地根据各卷积层权重获得输入的加权和sum,并计算sum和g函数的梯度。而accnet作为这两个基础计算的组合,可以通过反向传播算法进行训练。
提取sbs加速算法包含以下步骤:
步骤15,从训练有素的accnet网络中提取其卷积层的权重和激活函数,两者结合,自动定义splatting、blurring和slicing操作,即实现了任意高维卷积的最优加速算法。
- 还没有人留言评论。精彩留言会获得点赞!