一种基于深度学习算法的污染源异常数据识别方法与流程
本发明涉及数据处理技术领域,具体为一种基于深度学习算法的污染源异常数据识别方法。
背景技术:
污染源通常是指向环境排放或释放有害物质或对环境产生有害影响的场所、设备和装置,任何以不适当的浓度、数量、速度、形态和途径进入环境系统并对环境产生污染或破坏的物质或能量,统称为污染物,根据污染的产生过程可分为两类:1.一次污染物:由污染源释放的直接危害人体健康或导致环境质量下降的污染物;2.二次污染物:排放物质在一定环境条件下产生的一系列物理、化学和生物化学反应,导致环境质量下降,按污染物的来源可分为天然污染源和人为污染源,污染源天然污染源是指自然界自行向环境排放有害物质或造成有害影响的场所,如正在活动的火山,人为污染源是指人类社会活动所形成的污染源,后者是环境保护工作研究和控制的主要对象,人为污染源有多种分类方法,按排放污染的种类,可分为有机污染源、无机污染源、热污染源、噪声污染源、放射性污染源、病原体污染源和同时排放多种污染物的混合污染源等,随着社会的不断发展,人们的环保意识越来越高,因此需要对污染源的各项数据指标进行检测。
异常检测技术是在不影响网络性能的情况下,防止或减轻来自网络攻击的威胁,目前,异常检测是将具体实例技特征抽象为数据样本,再使用经典的模式分类算法如神经网络、决策树等对样本点进行分类,因此良好的特征表达对最终算法的准确性起着非常关键的作用,现有的污染源数据异常识别精度较低,且识别速度慢,不能通过深度学习模型算法来刻画数据的丰富信息和提高分类性能,无法达到在整个特征学习和数据异常是被的过程无人工提取的目的,不能解决有标签异常数据获取困难的问题,从而给人们对污染源数据的监控工作带来了极大的不便。
技术实现要素:
(一)解决的技术问题
针对现有技术的不足,本发明提供了一种基于深度学习算法的污染源异常数据识别方法,解决了现有的污染源数据异常识别精度较低,且识别速度慢,不能通过深度学习模型算法来刻画数据的丰富信息和提高分类性能,无法达到在整个特征学习和数据异常是被的过程无人工提取的目的,不能解决有标签异常数据获取困难的问题,从而给人们对污染源数据的监控工作带来了极大不便的问题。
(二)技术方案
为实现以上目的,本发明通过以下技术方案予以实现:一种基于深度学习算法的污染源异常数据识别方法,具体包括以下步骤:
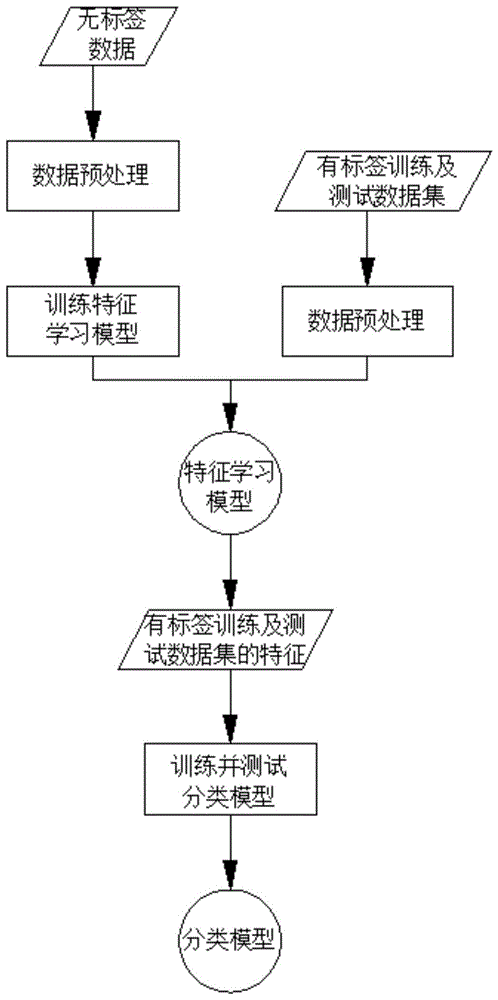
s1、首先系统处理模块会控制数据采集模块对外界污染源的检测数据进行采集,并将采集的数据传送至数据分类模块内进行分类,可将采集的污染源数据分成无标签数据和有表圈数据集,并将无标签数据传送至特征学习模型训练系统内进行深度学习处理,而有标签数据集传送至分类模型训练系统内进行分类训练和测试;
s2、模型的训练包括特征学习模型和分类模型的训练,其中数据预处理可对输入的数据进行标准化和归一化处理,并完成数据类型的转换,特征学习模型的训练以经过预处理的无标签数据作为输入,对特征学习模型进行无监各的训练,训练好的特征学习模型,可以直接用于学习数据的特征,将样本在原空间的表示变换到一个新的特征空间,分类模型的训练和测试应用有标签的训练集和测试集进行有监督的训练和测试;
s3、应用s2训练得到的特征学习模型,学习待分类数据的特征,然后将学习到的数据特征作为分类模型的输入,传送至下层数据训练系统内对数据进行分类,从第2层i=2开始,用i-1层特征作为本层的输入训练第层,其中第1层即原始输入,学习第层的初始编码参数w,b,并应用这些参数学习第i层的特征h,之后将学习的特征h作为下一层的输入,进入下层的训练,重复以上方法来训练所有层次,直到最后一层;
s4、在预训练之后,系统处理模块会控制神经网络编码单元对网络的输出和输入进行误差求解,以减小误差,同时系统处理模块会控制异常数据识别模块能够自动识别出异常污染源数据;
s5、系统处理模块会控制异常数据显示模块直接显示异常数据,或通过无线通讯单元无线将识别的异常数据无线传送至远程监控中心。
优选的,所述步骤s3中第1层为整个网络的输入,即原始数据最后一层特征为整个特征学习模型的输出,分类器的输入,w,b,分别表示第i层的网络权重和偏置值。
(三)有益效果
本发明提供了一种基于深度学习算法的污染源异常数据识别方法。与现有技术相比具备以下有益效果:该基于深度学习算法的污染源异常数据识别方法,通过在具体包括以下步骤:s1、首先系统处理模块会控制数据采集模块对外界污染源的检测数据进行采集,并将采集的数据传送至数据分类模块内进行分类,可将采集的污染源数据分成无标签数据和有表圈数据集,s2、模型的训练包括特征学习模型和分类模型的训练,其中数据预处理可对输入的数据进行标准化和归一化处理,并完成数据类型的转换,特征学习模型的训练以经过预处理的无标签数据作为输入,对特征学习模型进行无监各的训练,训练好的特征学习模型,s3、应用s2训练得到的特征学习模型,学习待分类数据的特征,然后将学习到的数据特征作为分类模型的输入,传送至下层数据训练系统内对数据进行分类,从第2层i=2开始,用i-1层特征作为本层的输入训练第层,其中第1层即原始输入,s4、在预训练之后,系统处理模块会控制神经网络编码单元对网络的输出和输入进行误差求解,以减小误差,同时系统处理模块会控制异常数据识别模块能够自动识别出异常污染源数据,s5、系统处理模块会控制异常数据显示模块直接显示异常数据,或通过无线通讯单元无线将识别的异常数据无线传送至远程监控中心,可实现将特征学习算法以原始数据作为输入,而且学习过程采用无监督的特征学习过程,可大大增强污染源数据异常识别的精度,缩短了异常数据识别时间,实现了通过深度学习模型算法来刻画数据的丰富信息和提高分类性能,达到了在整个特征学习和数据异常是被的过程无人工提取的目的,很好的解决了有标签异常数据获取困难的问题,从而大大方便了人们对污染源数据的监控工作。
附图说明
图1为本发明模型训练的流程图;
图2为本发明异常识别的流程图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
请参阅图1-2,本发明实施例提供一种技术方案:一种基于深度学习算法的污染源异常数据识别方法,具体包括以下步骤:
s1、首先系统处理模块会控制数据采集模块对外界污染源的检测数据进行采集,并将采集的数据传送至数据分类模块内进行分类,可将采集的污染源数据分成无标签数据和有表圈数据集,并将无标签数据传送至特征学习模型训练系统内进行深度学习处理,而有标签数据集传送至分类模型训练系统内进行分类训练和测试;
s2、模型的训练包括特征学习模型和分类模型的训练,其中数据预处理可对输入的数据进行标准化和归一化处理,并完成数据类型的转换,特征学习模型的训练以经过预处理的无标签数据作为输入,对特征学习模型进行无监各的训练,训练好的特征学习模型,可以直接用于学习数据的特征,将样本在原空间的表示变换到一个新的特征空间,分类模型的训练和测试应用有标签的训练集和测试集进行有监督的训练和测试;
s3、应用s2训练得到的特征学习模型,学习待分类数据的特征,然后将学习到的数据特征作为分类模型的输入,传送至下层数据训练系统内对数据进行分类,从第2层i=2开始,用i-1层特征作为本层的输入训练第层,其中第1层即原始输入,学习第层的初始编码参数w,b,并应用这些参数学习第i层的特征h,之后将学习的特征h作为下一层的输入,进入下层的训练,重复以上方法来训练所有层次,直到最后一层;
s4、在预训练之后,系统处理模块会控制神经网络编码单元对网络的输出和输入进行误差求解,以减小误差,同时系统处理模块会控制异常数据识别模块能够自动识别出异常污染源数据;
s5、系统处理模块会控制异常数据显示模块直接显示异常数据,或通过无线通讯单元无线将识别的异常数据无线传送至远程监控中心。
本发明中,步骤s3中第1层为整个网络的输入,即原始数据最后一层特征为整个特征学习模型的输出,分类器的输入,w,b,分别表示第i层的网络权重和偏置值。
为了验证方法的有效性,本发明从某气体污染源数据检测中心采集的数据集中下载进行实验验证,本发明主要关注的是对异常数据的检测率,所以以全部自体集和100个异常数据样本作为训练集,剩余的100个异常数据样本作为测试集,结果表明,通过深度学习算法对污染源异常数据的识别率最高可达96.26%,因此采用本发明深度学习算法对污染源异常数据的识别准确度高,且识别速度快,十分有利于推广。
需要说明的是,在本文中,诸如第一和第二等之类的关系术语仅仅用来将一个实体或者操作与另一个实体或操作区分开来,而不一定要求或者暗示这些实体或操作之间存在任何这种实际的关系或者顺序。而且,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者设备所固有的要素。
尽管已经示出和描述了本发明的实施例,对于本领域的普通技术人员而言,可以理解在不脱离本发明的原理和精神的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由所附权利要求及其等同物限定。
-
 0访客 来自[中国] 2021年04月22日 20:47神经病多
0访客 来自[中国] 2021年04月22日 20:47神经病多