一种基于PIKAIA遗传算法和OpenMP共享内存模型的水质模型参数自动率定方法与流程
本发明属于水质模型参数率定领域,具体来说是一种结合了pikaia遗传算法和openmp共享内存模型的水质模型参数自动率定并行计算的方法。
背景技术:
计算机数值模型在江河湖库等水体中得到了广泛地应用,其中,水质模型常常作为江河湖库管理的重要工具之一。在实际应用中,各种水质模型都需要事先进行大量的参数调节(“调参”)工作,即不断调节各类参数,使得模型计算值与实测值最为吻合,而调节参数最为常见的方法则为人工试错法,这种方法既耗时又很难达到最优值,存在诸多弊端。
智能算法的诞生改变了这一局面,学者们借助各种各样的智能算法来做全局的优化算法,取得了不错的效果。遗传算法作为智能算法的一种,自1975年j.holland教授提出至今,已发展为最为活跃的智能算法之一,许多学者根据遗传算法的基本理论提出了各种各样的改进版本,本发明与水质模型结合的是pikaia遗传算法,即为其中一种。
并行计算是一种同时执行多条指令或处理多个数据的一种形式。相对于串行计算来说,并行计算可以在有限时间内解决复杂的计算的问题。并行计算已经发展了很多年,主要是在高性能计算方面。并行计算机可分为具有多核和多处理器的单台计算机、计算机集群等。目前主流的并行编程模型可以分为消息传递和共享内存两类,消息传递的标准是mpi,主流的共享内存模型是openmp,具有很好的可移植性,得到了几乎所有商业编译器的支持。本发明即采用openmp共享内存模型。
技术实现要素:
本发明的目的是利用pikaia遗传算法和openmp共享内存模型,提供一种优化时间短,适应度高的水质模型自动率定并行计算的方法。
本发明的目的是这样实现的:一种基于pikaia遗传算法和openmp共享内存模型的水质模型自动率定并行计算方法,包括如下步骤:
1)根据野外调查结果,确定模拟对象;
2)利用pikaia遗传算法和openmp共享内存模型,构建水质参数优化自动率定并行计算模型,根据待率定参数的取值范围,自动率定所选待率定参数的取值;
3)选定指标,验证模拟值与实测值变化趋势是否相符。
本发明中,步骤2)中自动率定并行计算模型的构建,具体步骤如下:
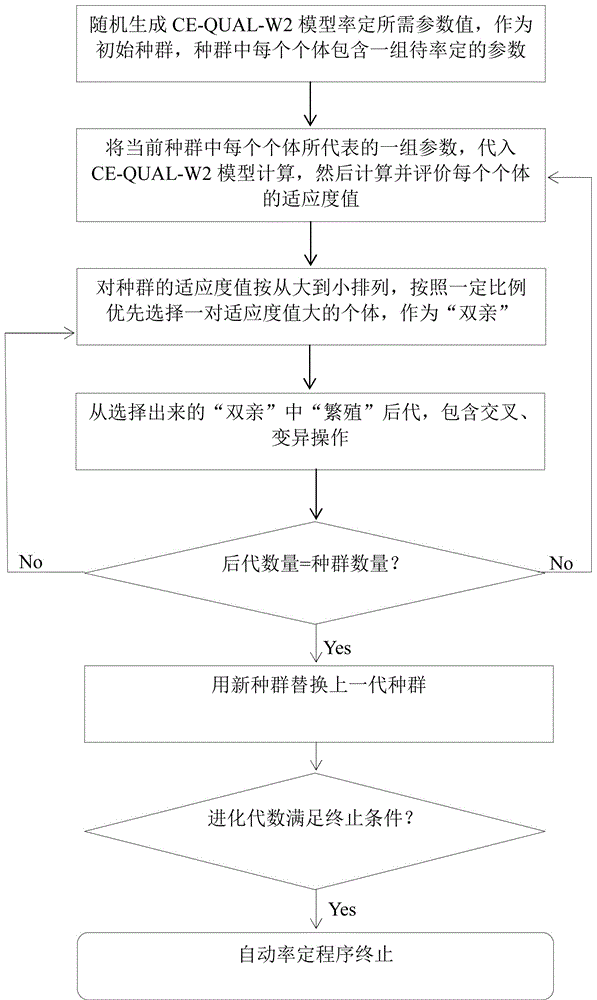
2-1)随机生成模型率定所需参数值,作为初始种群,种群中每个个体包含一组待率定的参数;
2-2)将步骤2-1)中所生成的种群中每个个体所代表的一组参数,代入模型计算,然后计算并评价每个个体的适应度值,适应度值采用公式1.1所示适应度函数计算;
式中,oi,j为实测值,pi,j为模拟值,m为实测与模拟匹配的数目,wi为权重因子,q为待率定参数的个数;
2-3)对种群的适应度值按从大到小排列,按照一定比例优先选择一对适应度值大的个体,作为“双亲”;该比例按照“轮盘赌”的方式进行确定,将该代所有种群的适应度从大到小排列,以最大的适应度值作为标准,计算所有种群的被选择概率,即所有适应度值除以该标准。按照每个种群被选择的概率,随机抽取作为“双亲”;
2-4)从步骤2-3)中选择出来的“双亲”中“繁殖”后代,包含交叉、变异操作;
2-5)对步骤2-4)中产生的后代种群数量做出判断,若与上一代种群数量相等,则用该新种群替换上一代种群;否则转步骤2-4);
对2-5)中种群进化代数做出判断,若已满足终止条件,则自动率定程序终止;否则转步骤2-2)。
本发明的特点及有益效果:本发明提出了一种结合了pikaia遗传算法和openmp共享内存模型的水质模型参数自动率定并行计算的方法,充分利用pikaia遗传算法,该算法与其他算法相比具有收敛速度快、适应性强等优点,尤其擅长处理多峰优化问题,并利用了所采用的遗传算法与其他算法相比具有收敛速度快、适应性强等优点,尤其擅长处理多峰优化问题。在遗传算法运行过程中,可能存在优良个体被破坏,导致平均适应度降低的情况,而pikaia遗传算法的精英模式可以保证最优个体不被替换掉而保留下来参与下一代计算。且pikaia遗传算法对种群运用“轮盘赌”的方法进行筛选“双亲”,可以很好地避免结果陷入局部最优解。
发明利用openmp共享内存模型,openmp共享内存模型是一种并行编程模型,具有优化时间短,适应度高的特点,具有很好的可移植性,得到了几乎所有商业编译器的支持。并行计算是一种同时执行多条指令或处理多个数据的一种形式。相对于串行计算来说,并行计算可以在有限时间内解决复杂的计算问题。所采用的并行编程模型可以同时执行多条指令或处理多个,在有限时间内解决复杂的计算问题,大大缩短了优化时间。
实际应用表明,本发明有效地解决了狭长型水库中水质模型参数率定的问题,针对不同情境下的水质等指标的变化而导致整个体系参数需要重新率定优化的问题,有很好的适应度。也可以很好地解决其他各大综合水质模型的研究问题。运用本方法可以很好地一次得到最优解,避免陷入局部最优解。解决了传统水质模型手动率定耗时长效率低的问题。可以让水质模型更好地投入实际使用,解决实际工程中的水污染水治理等问题。
本发明通过采用同时采用pikaia遗传算法和openmp共享内存模型,充分利用两者的优点,得到了一种优化时间短,适应度高的水质模型自动率定并行计算的方法。
附图说明
下面结合附图和实施例对本发明作进一步说明。
图1是本发明的流程图。
具体实施方式
如图1所示,本发明具体实施方式以ce-qual-w2水质模型为例,对香溪河库湾进行了复合多藻种的模拟。
模拟时,是基于pikaia遗传算法和openmp共享内存模型的水质模型自动率定并行计算方法,具体实例包括如下步骤:
1)根据野外调查结果,确定模拟对象,本实例选取了5种常见优势藻种作为模拟对象,分别为甲藻、硅藻、绿藻、蓝藻、隐藻;
2)利用pikaia遗传算法和openmp共享内存模型,构建水质参数优化自动率定并行计算模型,自动率定所选待率定参数的取值。所选自动率定参数及其取值范围见附表1,参数最终优化结果见附表2。
3)选定指标,验证模拟值与实测值变化趋势是否相符,本实例选择了正磷酸盐(po43--p),硝氮(no3--n),可溶性二氧化硅(dsio2)及叶绿素a(chla)四个指标。
上述方案中,基于pikaia遗传算法的并行自动率定计算过程,在一台双cpu共20核40线程的工作站上进行,考虑到计算成本及工作站运行其他程序的需要,设置种群数为36,也即使用了36线程,可以同时进行36个种群的运行与评价,使得优化时间大为缩短,进化代数为100,pikaia遗传算法相关参数取值见附表3,步骤3)具体包括如下步骤:
(1).随机生成模型率定需参数值,作为初始种群,种群中每个个体包含一组待率定的参数;
(2).将(1)中所生成的种群中每个个体所代表的一组参数,代入模型计算,然后计算并评价每个个体的适应度值,适应度值采用公式1.1所示适应度函数计算;
式中,oi,j为实测值,pi,j为模拟值,m为实测与模拟匹配的数目,wi为权重因子,q为待率定参数的个数
(3).对种群的适应度值按从大到小排列,按照一定比例优先选择一对适应度值大的个体,作为“双亲”;该比例按照“轮盘赌”的方式进行确定,将该代所有种群的适应度从大到小排列,以最大的适应度值作为标准,计算所有种群的被选择概率,即所有适应度值除以该标准。按照每个种群被选择的概率,随机抽取作为“双亲”;
(4).从选择出来的“双亲”中“繁殖”后代,包含交叉、变异操作;
(5).对(4)中产生的后代种群数量做出判断,若与上一代种群数量相等,则用该新种群替换上一代种群;否则转步骤(4)。
(6).对(5)中种群进化代数做出判断,若已满足终止条件,则自动率定程序终止;否则转步骤(2)。
附表1自动率定参数表及取值范围
附表2水质模型参数优化结果表
附表3pikaia遗传算法参数表
其中,变异模式有6种,分别为:
(1)单点固定概率变异;
(2)单点基于适应度值可变概率变异;
(3)单点基于距离可变概率变异;
(4)单点固定概率+蠕变;
(5)单点基于适应度值可变概率变异+蠕变;
(6)单点基于距离可变概率变异+蠕变。
繁殖模式有3种,分别为:
(1)一次更新所有种群,替换原有老种群;
(2)稳态逐渐更新种群,采用随机方式替换老种群,不管适应度大小;
(3)稳态逐渐更新种群,采用去掉适应度最差的个体策略,替换老种群。
精英模式开关有两种状态:0和1,0为关,1为开。
当繁殖模式为1或2时,打开精英开关可以保证最优个体不被替换掉而保留下来参与下一代计算。
输出控制开关有3种状态:0、1、2,分别对应无输出、基本输出、详细输出。
- 还没有人留言评论。精彩留言会获得点赞!