一种生态设计知识主动推送系统和方法与流程
本发明涉及计算机网络技术领域,尤其涉及一种生态设计知识主动推送系统和方法。
背景技术:
为了生态设计知识能够在短时间内被提取、选择和应用,并且考虑到设计过程中的动态性和可靠性,需要提出了一种生态设计知识主动推送系统和方法,用以缩短产品生态设计开发周期。
技术实现要素:
基于背景技术存在的技术问题,本发明提出了一种生态设计知识主动推送系统和方法,以汽车变速器的设计为例,来解释生态设计知识主动推送系统的有效性和合理性。
本发明采用的技术方案是:
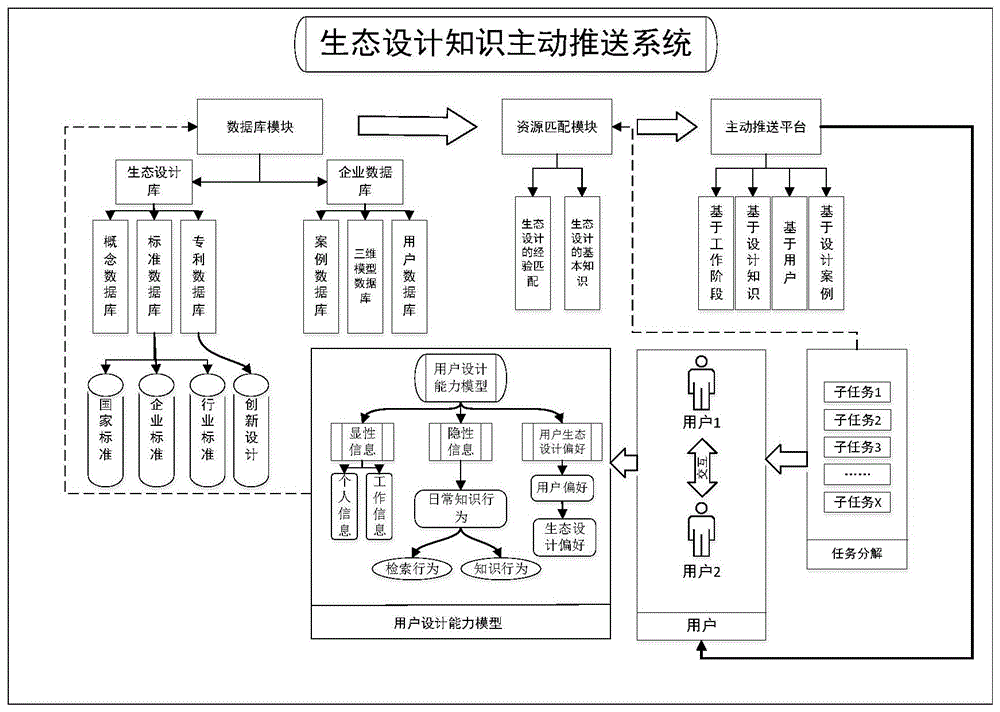
一种生态设计知识主动推送系统,其特征在于,包括:数据库模块、资源匹配模块、主动推送平台、用户设计能力模型;
所述数据库模块包括:生态设计库、企业数据库;生态设计库包括:概念数据库、标准数据库、专利数据库;标准数据库包括:国家标准、企业标准、行业标准;企业数据库包括:案例数据库、三维模型数据库、用户数据库;
所述资源匹配模块包括:生态设计的经验匹配、生态设计的基本知识;
所述主动推送平台包括:基于工作阶段、基于设计知识、基于用户、基于设计案例;
所述用户设计能力模型包括:显性信息、隐性信息、用户生态设计偏好;显性信息包括:个人信息、工作信息;隐性信息包括:检索行为、知识行为;
根据外界推送的随机任务分配给不同的用户,得出不同用户接受任务的能力,将用户信息全都存储到用户设计能力模型中,并且将用户设计能力模型细化为三大部分;用户设计能力模型完成之后,为了进一步扩大推送系统的数据库,建立数据库模块,再将用户设计能力模型中所有的数据存储在数据库模块中的企业数据库中,最终将数据库模块分成两大部分,为接下来的资源匹配提供数据;对于用户来说,任务分解产生的不同子任务能够体现用户的生态设计能力,将数据反馈到资源匹配模块后,加上数据库模块的数据支撑,建立资源匹配模块,根据用户的偏好信息,将资源匹配模块分成两大类;资源匹配模块建立之后,由于推送的范围过大,有经验的用户推送一批数据,没经验的用户推送一批数据,因此还需要将数据细分,最终建立主动推送平台;以工作阶段为例,在不同的工作阶段分别推送用户所需的内容,使用户更好的体验和利用主动推送系统的数据。
所述数据库模块是建立在计算机存储设备上的,具有根据数据结构组织、存储和管理数据的能力,用户可以对数据库中的文件数据进行添加、拦截、更新、删除操作;
所述资源匹配模块在检索资源时,通过任务分解的信息、根据用户的不同生态设计能力并提取的用户设计偏好信息,将执行以下计算和判断:当s值大于系统给出的阈值并且wni的值也大于系统给出的阈值时,用户将被视为具有生态设计经验的设计者,这些用户只需匹配企业数据库中的资源,这一过程称为生态设计的经验匹配;其他不满足上述条件的用户将被视为从未参与生态设计的设计者,由于用户没有生态设计背景知识,系统将首先根据任务分解的关键词搜索生态设计库,并匹配生态设计的基本知识;
所述主动推送平台的基于设计知识和基于用户的协同过滤算法通过找到与当前用户的历史行为类似的用户,然后推荐他们偏好的,同时是当前用户不具备的设计思路;对于有经验的用户需要向他们推送案例、三维模型、用户、专利数据库,对于无经验的用户需要向他们推送案例、三维模型、用户、专利、概念、标准数据库;所述主动推送平台的基于设计案例的推荐算法是根据当前的设计对象,推送该对象某一具体的生态设计实例;所述主动推送平台的基于工作阶段的推荐算法根据用户设计的不同阶段,将生态设计知识的推送分为以下四个阶段:概念规划阶段、产品设计阶段、性能提升阶段、反馈改进阶段;
所述用户设计能力模型主要是指用户的个人相关信息和先前产品开发的历史数据,包括设计领域、前期设计研究的平均时间、设计意图与生态设计概念的关联度,以及在设计产品达到性能之前的产品测试的平均次数;显性信息的提取主要是指可以直接利用的用户相关信息的数据提取和记录,显性信息主要由用户首次登陆系统时,用户输入所产生,它主要分为两个主要部分:(1)用户个人信息:它主要包括姓名,性别,年龄,教育,职业,(2)用户工作信息:它主要包括企业,部门,职位,设计领域,常用软件;隐性信息的提取不需要用户的主动参与,它由系统在不干扰用户的情况下跟踪用户的浏览行为和操作从而自动获取,隐性信息中包含的主要行为是用户的日常知识行为,它包括检索行为和知识行为(浏览,评估,上传,下载,收集,标签),可以使用javascript记录用户操作,而使用工程软件的相关操作记录可以在操作日志中获取;用户生态设计偏好的功能模型是知识推送系统的关键部分之一,根据用户生态设计的设计偏好功能模型,将设计知识和任务分配给对该领域更感兴趣的用户。
一种生态设计知识主动推送方法,其特征在于,按如下步骤进行:
步骤1、将推送的任务分解成不同的子任务,随机推送给不同的用户,根据用户对象处理任务的能力不同,进而做出用户设计能力模型,用户生态设计偏好的功能模型是用户设计能力模型的关键部分之一,用户生态设计偏好的矩阵模型表达,如下所示:
p=[ed1,n1;ed2,n2;…edi,ni;…edk,nk](1)
式中,ed代表典型的生态设计领域,可分为并行设计,模块化设计,创新设计,轻量化设计,再制造设计,低碳设计和拆卸设计;如果之前产品设计中涉及到该生态设计领域,则将其分配为1,未涉及则将其分配为0;n代表的是在对相应生态设计领域进行隐性信息的提取时,该领域典型关键词的出现次数;
步骤2、将用户设计能力模型中存储的用户信息存放在数据库模块中的企业数据库中,并且将三维模型和案例数据库中的数据存放在企业数据库中,同时将生态设计数据库中的数据存放在生态设计库中,为接下来的资源匹配提供数据支撑;
步骤3、根据数据库模块所提供的数据,对不同的用户进行资源匹配,通常检索资源是根据任务分解的信息来完成;根据用户的不同生态设计能力和方程(1)提取的用户设计偏好信息,系统将执行以下计算和判断:
式中,s指的是系统提取的用户生态设计行为的总次数,ssystem代表的是系统给出的用户生态设计行为总次数的阈值,wni指的代表的是当前用户在相关的生态设计领域中的用户偏好权重,wnsystem是指系统给出的用户偏好权重的阈值;
步骤4、当系统提取的用户生态设计行为的总次数s值大于系统给出的阈值并且当前用户在相关的生态设计领域中的用户偏好权重wni的值也大于系统给出的阈值时,用户将被视为具有生态设计经验的设计者,这些用户只需匹配企业数据库中的资源;
步骤5、当系统提取的用户生态设计行为的总次数s值小于系统给出的阈值,或者当前用户在相关的生态设计领域中的用户偏好权重wni的值也小于系统给出的阈值时,用户将被视为从未参与生态设计的设计师,这些用户只需匹配生态设计的基本知识;
步骤6、对于匹配企业数据库和匹配生态设计的基本知识的用户,需要根据不同用户能力,推送相应的数据库;每个数据库中的资源比较筛选的具体过程显示在等式(3)中:
wz=λ×wt+(1-λ)×ws(3)
式中,wz指的是匹配资源的综合权重,该值介于0-1之间,λ是指资源要求的时效性比重,wt代表的是匹配资源的时效性,具体计算如公式(4)所示,ws代表的是匹配资源的与设计内容间的相似性,具体计算如公式(5)所示:
式中,δt是指当前系统时间减去系统内资源的存储时间,该值的单位是日;d指的是存储时间不到一年的匹配资源的时效性衰减系数;zdistance指的是数据库中匹配的资源和任务之间的存储距离;资源匹配模块将首先根据任务分解的关键词搜索生态设计知识库,并匹配生态设计的基本知识;
步骤7、资源匹配完成后,建立主动推送平台,并且将平台数据反馈到用户阶段,对于不同的用户进行相应的资源推送;对于有经验的用户,根据用户的不同需要,分别推送案例、三维模型、用户、专利数据库;对于无经验的用户,根据需要推送案例、三维模型、用户、专利、概念、标准数据库。
本发明的优点是:
结果表明,当产品特性与生态设计相关时,本发明的推送系统和方法可以缩短设计时间并优化设计过程。
附图说明
图1为一种生态设计知识主动推送系统的示意框图。
图2为一种生态设计知识主动推送方法的步骤3、4、5的流程图。
图3为一种生态设计知识主动推送方法的步骤6的流程图。
图4为一种生态设计知识主动推送方法的步骤7的流程图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。
实施例。
如图1所示,一种生态设计知识主动推送系统,包括:数据库模块、资源匹配模块、主动推送平台、用户设计能力模型;
所述数据库模块包括:生态设计库、企业数据库;生态设计库包括:概念数据库、标准数据库、专利数据库;标准数据库包括:国家标准、企业标准、行业标准;企业数据库包括:案例数据库、三维模型数据库、用户数据库;
所述资源匹配模块包括:生态设计的经验匹配、生态设计的基本知识;
所述主动推送平台包括:基于工作阶段、基于设计知识、基于用户、基于设计案例;
所述用户设计能力模型包括:显性信息、隐性信息、用户生态设计偏好;显性信息包括:个人信息、工作信息;隐性信息包括:检索行为、知识行为;
根据外界推送的随机任务分配给不同的用户,得出不同用户接受任务的能力,将用户信息全都存储到用户设计能力模型中,并且将用户设计能力模型细化为三大部分;用户设计能力模型完成之后,为了进一步扩大推送系统的数据库,建立数据库模块,再将用户设计能力模型中所有的数据存储在数据库模块中的企业数据库中,最终将数据库模块分成两大部分,为接下来的资源匹配提供数据;对于用户来说,任务分解产生的不同子任务能够体现用户的生态设计能力,将数据反馈到资源匹配模块后,加上数据库模块的数据支撑,建立资源匹配模块,根据用户的偏好信息,将资源匹配模块分成两大类;资源匹配模块建立之后,由于推送的范围过大,有经验的用户推送一批数据,没经验的用户推送一批数据,因此还需要将数据细分,最终建立主动推送平台;以工作阶段为例,在不同的工作阶段分别推送用户所需的内容,使用户更好的体验和利用主动推送系统的数据。
所述数据库模块是建立在计算机存储设备上的,具有根据数据结构组织、存储和管理数据的能力,用户可以对数据库中的文件数据进行添加、拦截、更新、删除操作;
所述资源匹配模块在检索资源时,通过任务分解的信息、根据用户的不同生态设计能力并提取的用户设计偏好信息,将执行以下计算和判断:当s值大于系统给出的阈值并且wni的值也大于系统给出的阈值时,用户将被视为具有生态设计经验的设计者,这些用户只需匹配企业数据库中的资源,这一过程称为生态设计的经验匹配;其他不满足上述条件的用户将被视为从未参与生态设计的设计者,由于用户没有生态设计背景知识,系统将首先根据任务分解的关键词搜索生态设计库,并匹配生态设计的基本知识;
所述主动推送平台的基于设计知识和基于用户的协同过滤算法通过找到与当前用户的历史行为类似的用户,然后推荐他们偏好的,同时是当前用户不具备的设计思路;对于有经验的用户需要向他们推送案例、三维模型、用户、专利数据库,对于无经验的用户需要向他们推送案例、三维模型、用户、专利、概念、标准数据库;所述主动推送平台的基于设计案例的推荐算法是根据当前的设计对象,推送该对象某一具体的生态设计实例;所述主动推送平台的基于工作阶段的推荐算法根据用户设计的不同阶段,将生态设计知识的推送分为以下四个阶段:概念规划阶段、产品设计阶段、性能提升阶段、反馈改进阶段;
所述用户设计能力模型主要是指用户的个人相关信息和先前产品开发的历史数据,包括设计领域、前期设计研究的平均时间、设计意图与生态设计概念的关联度,以及在设计产品达到性能之前的产品测试的平均次数;显性信息的提取主要是指可以直接利用的用户相关信息的数据提取和记录,显性信息主要由用户首次登陆系统时,用户输入所产生,它主要分为两个主要部分:(1)用户个人信息:它主要包括姓名,性别,年龄,教育,职业,(2)用户工作信息:它主要包括企业,部门,职位,设计领域,常用软件;隐性信息的提取不需要用户的主动参与,它由系统在不干扰用户的情况下跟踪用户的浏览行为和操作从而自动获取,隐性信息中包含的主要行为是用户的日常知识行为,它包括检索行为和知识行为(浏览,评估,上传,下载,收集,标签),可以使用javascript记录用户操作,而使用工程软件的相关操作记录可以在操作日志中获取;用户生态设计偏好的功能模型是知识推送系统的关键部分之一,根据用户生态设计的设计偏好功能模型,将设计知识和任务分配给对该领域更感兴趣的用户。
一种生态设计知识主动推送方法,按如下步骤进行:
步骤1、将推送的任务分解成不同的子任务,随机推送给不同的用户,根据用户对象处理任务的能力不同,进而做出用户设计能力模型,用户生态设计偏好的功能模型是用户设计能力模型的关键部分之一,用户生态设计偏好的矩阵模型表达,如下所示:
p=[ed1,n1;ed2,n2;…edi,ni;…edk,nk](1)
式中,ed代表典型的生态设计领域,可分为并行设计,模块化设计,创新设计,轻量化设计,再制造设计,低碳设计和拆卸设计;如果之前产品设计中涉及到该生态设计领域,则将其分配为1,未涉及则将其分配为0;n代表的是在对相应生态设计领域进行隐性信息的提取时,该领域典型关键词的出现次数;
步骤2、将用户设计能力模型中存储的用户信息存放在数据库模块中的企业数据库中,并且将三维模型和案例数据库中的数据存放在企业数据库中,同时将生态设计数据库中的数据存放在生态设计库中,为接下来的资源匹配提供数据支撑;
步骤3、如图2所示,根据数据库模块所提供的数据,对不同的用户进行资源匹配,通常检索资源是根据任务分解的信息来完成;根据用户的不同生态设计能力和方程(1)提取的用户设计偏好信息,系统将执行以下计算和判断:
式中,s指的是系统提取的用户生态设计行为的总次数,ssystem代表的是系统给出的用户生态设计行为总次数的阈值,wni指的代表的是当前用户在相关的生态设计领域中的用户偏好权重,wnsystem是指系统给出的用户偏好权重的阈值;
步骤4、当系统提取的用户生态设计行为的总次数s值大于系统给出的阈值并且当前用户在相关的生态设计领域中的用户偏好权重wni的值也大于系统给出的阈值时,用户将被视为具有生态设计经验的设计者,这些用户只需匹配企业数据库中的资源;
步骤5、当系统提取的用户生态设计行为的总次数s值小于系统给出的阈值,或者当前用户在相关的生态设计领域中的用户偏好权重wni的值也小于系统给出的阈值时,用户将被视为从未参与生态设计的设计师,这些用户只需匹配生态设计的基本知识;
步骤6、如图3所示,对于匹配企业数据库和匹配生态设计的基本知识的用户,需要根据不同用户能力,推送相应的数据库;每个数据库中的资源比较筛选的具体过程显示在等式(3)中:
wz=λ×wt+(1-λ)×ws(3)
式中,wz指的是匹配资源的综合权重,该值介于0-1之间,λ是指资源要求的时效性比重,wt代表的是匹配资源的时效性,具体计算如公式(4)所示,ws代表的是匹配资源的与设计内容间的相似性,具体计算如公式(5)所示:
式中,δt是指当前系统时间减去系统内资源的存储时间,该值的单位是日;d指的是存储时间不到一年的匹配资源的时效性衰减系数;zdistance指的是数据库中匹配的资源和任务之间的存储距离;资源匹配模块将首先根据任务分解的关键词搜索生态设计知识库,并匹配生态设计的基本知识;
步骤7、如图4所示,资源匹配完成后,建立主动推送平台,并且将平台数据反馈到用户阶段,对于不同的用户进行相应的资源推送;对于有经验的用户,根据用户的不同需要,分别推送案例、三维模型、用户、专利数据库;对于无经验的用户,根据需要推送案例、三维模型、用户、专利、概念、标准数据库。
以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,根据本发明的技术方案及其发明构思加以等同替换或改变,都应涵盖在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!