一种基于遥感物候同化和粒子群优化算法的区域冬小麦估产方法与流程
本发明涉及农业遥感技术领域,更具体涉及一种基于遥感物候同化和粒子群优化算法的区域冬小麦估产方法。
背景技术:
作物生长模型以光、温、水、土壤等条件为环境驱动变量,运用数学物理方法和计算机技术,对作物生育期内光合、呼吸、蒸腾等重要生理生态过程及其与气象、土壤等环境条件以及耕作、灌溉、施肥等技术条件的关系进行定量描述和预测,再现农作物生长发育及产量形成过程。由于作物生长模型机理性较强,包含参数较多,因此参数的可靠性是影响模型应用的关键问题。大多数模型是在田间尺度上建立和检验的,将其扩展到区域尺度乃至全球尺度存在着困难,不同的区域气候、土壤、作物和水文要素等不同,模型预测的准确性也不同,因此如何高效地实现作物生长模型参数本地化,获得可靠稳定的参数仍是当前研究的热点问题。
目前,利用数据同化技术把遥感反演参数融合到作物机理过程模型,是改进区域作物生长模拟精度和提高作物估产精度的重要途径。在遥感数据选择方面,随着研究范围的扩大,以modis为代表的中分辨率遥感数据应用更为广泛。然而,modis叶面积指数(lai)在冬小麦区域存在的严重低估现象使得同化标准modislai后产量模拟严重偏低。同时,作物生长模型仅依靠自身模拟能力或同化关键状态变量对实际物候进行估算时,会不可避免地出现物候偏差,最终直接影响产量模拟结果。因此,如何充分挖掘现有成熟遥感产品(例如中分辨率的modislai及其衍生产品)显著提升作物生长模型的区域估产能力,满足区域农业估产的业务化需求仍是当前亟需解决的问题。
另外,由于作物生长模型的设计最初是基于田间站点尺度的,模型的参数本地化需要大量精细的田间作物生长参数和田间管理措施数据,因此当将模型推广到区域尺度时存在资料获取困难的问题。现有一些研究将田间、站点尺度的模型参数进行空间插值,由此实现参数区域化。但是插值参数受插值方法,插值区域气候、土壤、作物和水文等的影响存在很大的不确定性,常常导致区域产量模拟精度不高。
为了解决基于田间站点的作物生长模型本地化参数难以适用于区域尺度的问题,遥感数据同化作物生长模型技术被广泛应用到区域作物估产中。现有的很多遥感数据同化方案中,为了尽可能避免因遥感数据误差所带来的同化精度影响,对作物生长参数进行高密度的实地采样观测从而确保高分辨率遥感数据向状态变量(例如lai)的反演精度,辐射模型的校验精度或实现对现有遥感产品的二次修正。然而,当研究范围进一步扩大时,大范围内高密度、高频率的地表观测需求将在时间、人力、金钱成本方面都面临巨大的压力,区域农业估产难以实现业务化应用。
因此,需要新的技术以至少部分解决现有技术中存在的局限。
技术实现要素:
为了解决上述技术问题,本发明提供了一种基于遥感物候信息,有效实现作物生长模型参数本地化的区域作物估产方法。
根据本发明的一方面,提供一种基于遥感物候同化和粒子群优化算法的区域冬小麦估产方法,包括如下步骤:
s1:获取运行作物生长模型所需要的数据,所述作物生长模型为mcwla-wheat,所述数据包括气象数据和土壤属性数据;
s2:获取研究区域全生育期内的遥感lai数据,并按时间序列合成,对每个格点单元的lai节点数据使用三次样条插值得到连续的lai曲线;
s3:识别s2步骤所得到的lai曲线的第一拐点和第二拐点(峰值),将其分别作为冬小麦返青期和抽穗期的标志,各个格点单元的成熟期由农气站的记录进行反距离加权插值获得;
s4:将s3步骤中能够同时识别出返青期和抽穗期的格点作为冬小麦种植区域,用于实施后续的步骤;
s5:基于s3和s4步骤获得的冬小麦种植格点的物候信息,使用二分法逐格点逐年优化作物生长发育参数,所述生物发育参数包括营养生长期前期生长速率参数、营养生长期后期生长速率参数和生殖生长期生长速率参数;
s6:在s5步骤获得优化作物生长发育参数之后,再使用粒子群算法优化生物物理过程参数,以完成参数本地化,其中所述生物物理过程参数包括与土壤水分平衡、光合、呼吸作用以及产量形成模块相关的参数,
其中粒子群算法优化包括:
(1)根据生物物理过程参数的先验取值区间进行随机抽样,使用拉丁超立方体抽样法(latinhypercubesampling)抽取n套初始化参数,称为一个初始输入粒子群;重复进行m次粒子群抽取,共形成m个初始输入粒子群共m*n套初始化参数,其中,m和n为大于1的自然数;
(2)将其中一个初始粒子群带入作物生长模型进行运行,调用粒子群优化算法模块,设定适宜度为模拟产量和实际记录产量之间的误差,使用的适宜度评价指标是标准均方根误差,公式如下:
式中,rmse为均方根误差,nrmse为标准均方根误差,n是数据个数,s和o分别表示模拟和观测产量,
当满足以下迭代终止条件之一时,则结束当前粒子群优化:
a)全局最优适宜度小于10%;
b)全局最优适宜度在连续5次循环后无法提高0.0001%;
c)粒子群连续更新超过100次。
(3)重复过程(2)直到m个初始粒子群均到达迭代终点,然后将m个粒子群的整体最优解作为全局最优参数组,完成参数本地化工作;
s7:将本地化后的作物生长发育参数和生物物理过程参数带入作物生长模型运行,获得各个格点产量,汇总获得冬小麦种植区域的总产量。
根据本发明的一个实施方案,步骤s1中所述作物生长模型为mcwla-wheat。
根据本发明的一个实施方案,其中步骤s1中所述气象数据包括每日最高气温、最低气温、太阳辐射、相对湿度、降水和风速,所述土壤属性数据包括基于土壤质地的渗透率和有效田间持水量。
根据本发明的一个实施方案,其中步骤s2中,所述遥感lai数据来自北京师范大学反演制作的glasslai(globallandsurfacesatellites(glass)leafareaindex(lai))产品。
根据本发明的一个实施方案,其中在s3步骤中,根据lai曲线识别返青期和抽穗期包括:对研究区域冬小麦返青期和和抽穗期的可能时期进行划定以避免将其他地物误识别为冬小麦,在划定的可能时期内进行识别,其中对返青期的识别满足如下条件:
(1)返青期节点(第一拐点)之前的遥感反演数据维持在较低值的水平,不存在异常的较高值;
(2)返青期节点(第一拐点)之后的遥感反演数据需要识别出连续上升趋势;
其中对抽穗期的识别满足如下条件:
(1)峰值节点(第二拐点)前至少有连续三期的遥感数据反映出上升趋势;
(2)峰值节点(第二拐点)后至少有连续三期的遥感数据呈现下降趋势。
根据本发明的一个实施方案,其中步骤s5中,所述作物生长发育参数来自mcwla-wheat模型。
与现有技术相比,本发明具有诸多的优点:
1.采用的作物生长模型是为满足区域尺度作物生长模拟需求所开发的mcwla(modeltocapturethecrop-weatherrelationshipoveralargearea)模型,该模型基于大区域尺度进行开发,数据准备资料获取容易。
2.使用的遥感产品包括glasslai(globallandsurfacesatellites(glass)leafareaindex(lai))产品,该产品是对modislai产品的改进,在生产过程中已经包括了s-g滤波预处理,在数据质量上有一定提升且具有更好的时间完整性和空间连续性,节省大量遥感数据预处理的时间成本。
3.本发明中基于遥感数据的物候反演方法可以快速准确地得到大区域的精细物候信息。
4.本发明充分发挥了遥感数据和作物生长模型的优势,把遥感观测的lai时序曲线所存在的物候信息有效利用到作物生长模型参数本地化工作中,避免了直接使用绝对lai数据存在产量模拟偏低的问题,同时也解决了作物生长模型在模拟过程中存在的物候偏移问题。
5.本发明在县级尺度上的粒子群参数优化方案可以快速高效地获得全局最优解,最终基于最优参数组模拟的产量精度远远高于当前同类发明。
附图说明
附图中相同的附图标记标示了相同或类似的部件或部分。本发明的目标及特征考虑到如下结合附图的描述将更加明显,附图中:
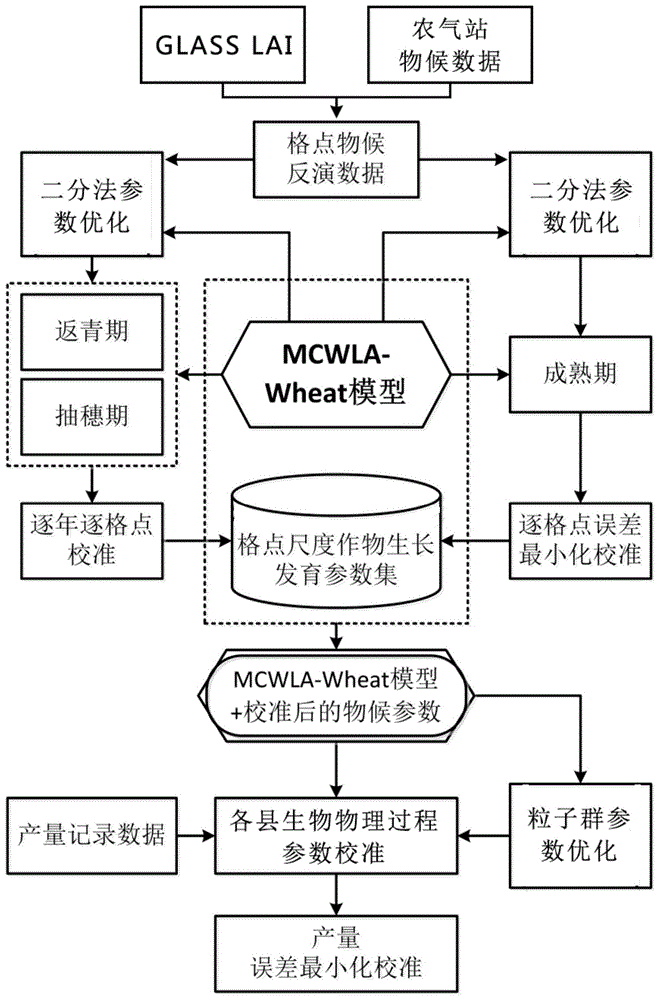
图1是根据本发明一个实施方案的基于遥感物候同化和粒子群优化算法的区域冬小麦估产方法的流程示意图。
图2是根据本发明一个实施方案的应用本发明方法模拟区域冬小麦产量的结果图。
具体实施方式
为清楚的说明本发明中的方案,下面给出优选的实施例并结合附图详细说明。以下的说明本质上仅仅是示例性的而并不是为了限制本公开的应用或用途。
应该理解的是,本发明所引用的作物生长模型和遥感模型本身是已知的,例如模型的各个子模块、各种参数、运行机制等等,因此本发明重点阐述优化参数的过程。
图1是根据本发明一个实施方案的基于遥感物候同化和粒子群优化算法的区域冬小麦估产方法的流程示意图。如图1所示,本发明提供了一种基于遥感物候信息,有效实现作物生长模型参数本地化的区域作物估产方法,具体步骤如下:
s1:获取运行作物生长模型所需要的数据;例如其中所采用的作物生长模型可以为mcwla(modeltocapturethecrop-weatherrelationshipoveralargearea)系列模型中的mcwla-wheat。当然也可以采用其他合适的作物生长模型。mcwla模型是一系列为满足区域尺度作物生长模拟需求所开发的作物生长模型,已经应用在了国内外多个作物生长模拟研究中,表现稳健。s1步骤所需的数据可以包括气象数据和土壤属性数据。气象数据可以包括每日最高气温、最低气温、太阳辐射、相对湿度、降水和风速。土壤属性数据可以包括基于土壤质地的渗透率和有效田间持水量。这些数据可以通过现场监测或者现有的记录数据来获取。
s2:对研究区域全生育期内的遥感lai数据按时间序列合成,对每个格点单元的lai节点数据使用三次样条插值得到连续的lai曲线。使用的遥感数据可以是北京师范大学反演制作的glasslai(globallandsurfacesatellites(glass)leafareaindex(lai))产品,,该产品可从北京师范大学全球变化数据处理与分析中心(http://www.bnu-datacenter.com/)和马里兰大学全球土地利用数据库(http://glcf.umd.edu/data/helpme.shtml)获得。该产品是对modislai产品的改进,其在生产过程中已经包括了s-g滤波预处理,在数据质量上有一定提升且具有更好的时间完整性和空间连续性。应该理解,也可使用其他合适的遥感lai数据。
s3:识别s2得到的lai曲线的第一拐点和第二拐点,第二拐点即为峰值,将其分别作为冬小麦返青期和抽穗期的标志,各个格点单元的成熟期由农气站的记录进行反距离加权插值获得。
其中,s3根据lai曲线识别返青期和抽穗期具体为:首先,对研究区域冬小麦返青期和和抽穗期的可能时期进行划定以避免将其他地物误识别为冬小麦。然后,在划定的可能时期内进行识别,其中对返青期的识别需要满足如下条件:
(1)返青期节点之前的遥感反演数据维持在较低值的水平,不存在异常的较高值;可以通过与lai最高值相比较来判断所谓的较高值和较低值。例如可以设定大约在lai最高值的15%以下是判断为较低值的水平,超过最高lai最高值的50%可以判断为较高值的水平;
(2)返青期节点之后的遥感反演数据需要识别出连续上升趋势;
对抽穗期的识别需要满足如下条件:
峰值节点前至少有连续三期的遥感数据反映出上升趋势;
峰值节点后至少有连续三期的遥感数据呈现下降趋势。
影响成熟期的遥感反演的因素较多,例如天气状况,农民的种植收获习惯,格点内可能存在的其他植被的生长以及背景噪音的影响等等都会影响对遥感反演的lai曲线末端的识别。因此,为了提高效率,各个格点单元的成熟期由农气站的记录进行反距离加权插值获得。反距离加权插值以样本点与待插值点间的距离为权重,待插值点与样本点越近,则该点权重越大,反之越小。反距离加权插值法为本领域普通技术人员所述熟知。例如其可以采用如下一般公式:
其中,
权重的确定计算公式为:
其中,di0是待插值点s0与样本点si之间的距离;p是指数,默认值是2。
s4:将s3步骤中能够同时识别出返青期和抽穗期的格点作为冬小麦种植区域,用于后续的研究步骤。
s5:基于s3和s4步骤获得的冬小麦种植格点的物候信息,使用二分法逐格点逐年优化作物生长发育参数。
其中,s5步骤中所述的作物生长发育参数可以为mcwla-wheat模型中的营养生长期前期生长速率参数、营养生长期后期生长速率参数和生殖生长期生长速率参数。针对作物生长模型中作物生长发育的模拟方程是一个时间上的单调函数,且每个发育阶段仅设置了一个待优化参数的特点,s5步骤选择了二分法实现对作物生长发育参数的优化。
s6:在s5获得最优作物生长发育参数之后再使用粒子群算法优化其他生物物理过程参数,以完成参数本地化过程。
其中,s6步骤中所述的生物物理过程参数包括涉及土壤水分平衡、光合、呼吸作用、产量形成等模块的参数,例如产量差异系数、土壤水胁迫因子对作物生长产生影响的阈值等。由于生物物理过程涉及参数较多,因此采用粒子群优化算法进行参数优化,具体如下:
(1)根据参数的先验取值区间进行随机抽样,使用拉丁超立方体抽样法(latinhypercubesampling)抽取n套(例如10套,当然也可以根据需要选择其他的数量)初始化参数,称为一个初始输入粒子群。为了有效避免粒子群算法在处理复杂多参数优化问题时可能陷入局部最优的情况,本研究重复进行了m次(例如5次,当然也可以根据需要选择其他的数量)粒子群抽取,共形成m个初始输入粒子群共m×n套初始化参数,其中,m和n为大于1的自然数。
(2)将其中一个初始粒子群带入作物生长模型例如mcwla-wheat模型进行运行,调用粒子群优化算法模块,设定适宜度为模拟产量和实际记录产量之间的误差,使用的适宜度评价指标是标准均方根误差,公式如下:
式中,rmse为均方根误差,nrmse为标准均方根误差,n是数据个数,s和o分别表示模拟和观测产量,
当满足以下迭代终止条件之一时,则结束当前粒子群优化:
a)全局最优适宜度(即最小nrmse)小于10%;
b)全局最优适宜度在连续5次循环后无法提高0.0001%;
c)粒子群连续更新超过100次。
(3)重复过程(2)直到5个初始粒子群均到达迭代终点,然后将m个粒子群的整体最优解作为全局最优参数组,完成参数本地化工作。
s7:将本地化后的作物生长发育参数和生物物理过程参数带入作物生长模型运行,获得各个格点产量,汇总获得冬小麦种植区域的总产量。
逐格点运行作物生长模型模拟产量,然后汇总到县域行政单元,基于县级冬小麦单产记录,以县级模拟产量的标准均方根误差最小作为最优适宜度判断标准,获得每个县的全局最优参数组,完成模型本地化校准工作。用本地化参数运行模型,输出县级单产模拟结果。
实施例
下面以河北、山东、河南和安徽四省的冬小麦种植区域作为研究区域,示例性说明本发明的方法的具体应用。
步骤s1,选择河北、山东、河南和安徽四省的冬小麦种植区域作为研究区域,共涉及159个县。研究区域地处111.5°e–118.2°e,32.1°n–38.8°n,地形以平原为主,占据了大部分华北平原的冬小麦主产区。气候属温带季风性气候,平均温度约15.6℃,年均降水量约834.5mm。获取以下数据:气象数据采用了拥有足够插值精度(r2>0.8),由yuan等人[1](yuanw,xub,chenz,xiaj,xuw,cheny,wux,fuy.(2015).validationofchina-wideinterpolateddailyclimatevariablesfrom1960to2011.theorapplclimatol119:689-700.)制作的全国0.5°×0.5°格网气象数据集中2000-2008年的部分,该数据集包含了mcwla-wheat模型模拟所需的天步长气象数据,包括最高气温(℃)、最低气温(℃)、太阳辐射(mj/m2)、相对湿度(%)、日总降水量(mm)、风速(m/s)等数据。模型模拟中的土壤属性数据来源于fao土壤数据库,包括基于土壤质地的渗透率和有效田间持水量,分辨率为5’。土壤属性数据库主要应用于土壤水平衡部分的计算。2001-2008年县级冬小麦单产记录从中国种植业信息网和县级统计年鉴上整理得出,主要用于作物生长模型的参数本地化与模拟效果评估。农业气象站的物候记录数据从中国气象数据网获得。遥感数据使用的是2001-2008年的glasslai产品,该产品的空间分辨率为1km,时间分辨率为8天,满足本发明的需求。
步骤s2,对研究区域全生育期内的glasslai数据按时间序列合成,对每个格点单元的lai节点数据使用三次样条插值得到连续的lai曲线。
步骤s3,识别s2得到的lai曲线的第一拐点和第二拐点,将其分别作为冬小麦返青期和抽穗期的标志。首先,对研究区域冬小麦返青期和和抽穗期的可能时期进行划定以避免将其他地物误识别为冬小麦。其中,根据研究区内的气候特征,返青期的时间设定在每年的2-3月,抽穗期设定在4月左右。然后,在划定的可能时期内进行识别,其中对返青期的识别需要满足如下条件:
(1)返青期节点之前的遥感反演数据维持在较低值的水平,本案例中选择大约在lai最高值的15%以下,不存在异常的高值,选择超过lai最高值的50%;
(2)返青期节点之后的遥感反演数据需要识别出连续上升趋势;
对抽穗期的识别需要满足如下条件:
(1)峰值节点前至少有连续三期的遥感数据反映出上升趋势;
(2)峰值节点后至少有连续三期的遥感数据呈现下降趋势;
影响成熟期的遥感反演因素较多,例如天气状况,农民的种植收获习惯,格点内可能存在的其他植被的生长以及背景噪音的影响等等都会影响对遥感反演的lai曲线末端的识别。因此,为了提高效率,各个格点单元的成熟期由农气站的记录进行反距离加权插值获得。
步骤s4,基于步骤s3识别返青期和抽穗期的原则,对初步划定的约65万个1km×1km格点2001-2008年的glasslai数据进行处理,如果一个格点在某一年的lai反演数据完全符合上述提取规则,则认为当地在当年种植了冬小麦,反之则认为该格点在当前年份没有种植冬小麦。最终,保留在2001-2008年期间至少有一年被识别为种植了冬小麦的格点,作为研究区域内冬小麦的种植区以及潜在的研究区。考虑大量格点的计算需要花费较高的时间成本,因此将格点数据分辨率重采样到8km以提高计算效率,也为大区域业务化应用做准备。
步骤s5,针对mcwla-wheat模型中作物生长发育的模拟方程是一个时间上的单调函数,且每个发育阶段仅设置了一个待优化参数的特点,选择了二分法逐格点逐年实现对作物生长发育参数的优化。对返青期和抽穗期相关参数的校准是基于格点尺度以及年步长进行的,每个格点在每一年都会对相关的作物生长发育参数进行重新校准以获得与遥感反演数据相匹配的物候模拟结果。对于成熟期相关参数的校准采用了参数先验的办法,即在2001-2008年对每个格点的成熟期进行参数校准,在每个格点获得一个使模拟和农气站插值成熟期年际误差最小的成熟期作物生长发育参数,然后将该参数应用于当前格点2001-2008年的模型模拟。
步骤s6,由于生物物理过程涉及参数较多,因此采用粒子群优化算法以县为单位进行参数优化,即同一县内格点共用一套生物物理过程参数。逐年运行作物生长模型模拟各格点产量,然后汇总到县域行政单元,基于县级冬小麦单产记录,以2001-2008年模型模拟的县级产量的标准均方根误差最小作为最优适宜度判断标准,当满足迭代终止条件时,当前粒子群优化结束。粒子群参数优化方案具体如下:
(1)根据参数的先验取值区间进行随机抽样,使用拉丁超立方体抽样法(latinhypercubesampling)抽取10套初始化参数,称为一个初始输入粒子群。为了有效避免粒子群算法在处理复杂多参数优化问题时可能陷入局部最优的情况,本发明重复进行了5次粒子群抽取,共形成5个初始输入粒子群共50套初始化参数。
(2)将一个初始粒子群带入mcwla-wheat模型进行运行,调用粒子群优化算法模块,设定适宜度为模拟产量和实际记录产量之间的误差,使用的适宜度评价指标是标准均方根误差,公式如下:
式中n是总年份,s和o分别表示模拟和观测产量,
当满足以下迭代终止条件之一时,则结束当前粒子群优化:
a)全局最优适宜度小于10%;
b)全局最优适宜度在连续5次循环后无法提高0.0001%;
c)粒子群连续更新超过100次。
(3)重复过程(2)直到5个初始粒子群均到达迭代终点,然后将5个粒子群的整体最优解作为全局最优参数组,完成参数本地化。
将本地化后的作物生长发育参数和生物物理过程参数带入mcwla-wheat模型运行,获得各个格点产量,再结合各格点的冬小麦种植比例,按县域行政边界汇总,获得区域单产结果,图2为模型模拟的2001-2008年159个县的冬小麦单产情况图。
本发明实施例所述的一种基于遥感物候同化和粒子群优化算法的区域冬小麦估产方法,充分发挥了遥感数据和作物生长模型的优势,把遥感观测的lai时序曲线所存在的物候信息充分利用到作物生长模型参数本地化工作中,避免了直接使用绝对lai数据存在产量模拟偏低的问题,同时也解决了作物生长模型在模拟过程中存在的物候偏移问题。本发明针对不同县的气候、土壤、水文条件以及管理措施的差异,利用粒子群优化算法为每个县因地制宜地设置参数组,极大地提高了产量模拟精度。其中,2001-2008年159个县的冬小麦产量模拟均方根误差rmse为465kgha-1,决定系数r2为0.75,是目前国内同类型发明中适用研究区域最大,时间跨度最长,模拟精度最高的发明。
粮食的生产者与消费者都需要及时准确地了解粮食产量信息,根据本方法可以花费最少的时间和人力在冬小麦成熟期大面积地获得产量数据,为国家有关部门进行粮情判断、粮食调控等科学决策等提供重要的科学依据,并且可以作为粮食贸易的重要依据。
本发明充分利用了现有的成熟遥感产品在格点和县级尺度上实现作物生长模型参数本地化,节省了大量获取地面精细实测数据的时间、人力、金钱成本,避免了直接使用绝对lai数据存在产量模拟偏低的问题,同时也解决了作物生长模型在模拟过程中存在的物候偏移问题。大大提高了区域农业估产的精度和效率,为区域快速农业估产等业务化应用提供可能。
本文中应用了具体个例对本发明的原理及实施方式进行了阐述,以上实施例的说明只是用于帮助理解本发明的装置及其核心思想;同时,对于本领域的一般技术人员,依据本发明的思想,在具体实施方式及应用范围上均会有改变之处,综上所述,本说明书内容不应理解为对本发明的限制。
- 还没有人留言评论。精彩留言会获得点赞!