一种基于三维假设空间聚类的多人动作捕捉方法与流程
本发明涉及一种基于三维假设空间聚类的多人动作捕捉方法。
背景技术:
现有的三维人体姿态估计方法根据输入数据不同可以分为:基于单目rgb图像(序列);基于深度图像(序列);和基于多视图图像(序列)。基于单目rgb图像(序列)进行三维人体姿态估计是一个严重约束不足的问题,系统的观测输入为复杂自然图像,状态输出为高维人体姿态,由观测输入到状态输出过程是高度非线性的。3d姿态训练数据集的不足、不同人体尺寸和比例的差异、以及三维姿态空间的高维度,都使得三维姿态重建的可信性成为亟待解决的关键问题。基于深度图像(序列)的三维人体姿态估计方法有效缓解了基于单目图像方法的深度歧义问题。现有的基于深度的人体姿态估计方法所采用的深度图通常来自tof相机或kinect传感器。然而,kinect和tof都是主动传感器,因此仅限于没有红外线干扰的室内场景,并且只能在有限的范围内工作。基于多视图图像(序列)的方法可以有效克服单目三维姿态估计中的困难,并构建一个更真实适用的姿态估计系统。但现有的多视图方法通常都是独立地估计二维姿态和三维姿态,因此不能充分利用多视图三维几何信息。这些的方法的结果可能不满足多视图几何约束。
目前为止的大多数三维姿态估计方法在获取关节点深度信息方面都依赖于骨架模型和训练数据。骨架模型提供关节点之间几何约束,训练数据则提供了二维姿态与深度之间的统计关系。然而,三维姿态数据集获取困难、规模小;同时三维姿态的状态参数维度高、个体身材比例和大小的差异大。这导致三维姿态估计结果的可信度无法保证。其次,大部分三维姿态估计方法都只考虑场景只有一个人,很难扩展的到多人场景。
技术实现要素:
本发明的目的是针对现有技术的不足,提供一种可信的多人三维人体动作捕捉方法。
本发明是通过以下技术方案实现的:一种基于三维假设空间聚类的多人动作捕捉方法,包括以下步骤:
(1)从c个不同视角的相机中分别获取二维rgb图像,定义为{i1,...,ic},每个相机对应的投影矩阵定义为{p1,...,pc};对于获取的c个二维rgb图像,分别进行二维人体姿态的初步估计,即对于每一人体关节点,得到包含所有人的该关节候选点的初始二维位置集合;
人体骨架有由14个关节点定义。各个关节点名称如下:<head,neck,shoulder.l,elbow.l,wrist.l,shoulder.r,elbow.r,wrist.r,hip.l,knee.l,ankle.l,hip.r,knee.r,ankle.r>,关节点对应编号依次为<1,2,3,4,5,6,7,8,9,10,11,12,13,14>,各关节点对应的父关节点编号依次为<#,1,2,3,4,2,6,7,2,9,10,2,12,13>。其中#表示无父节点,每个关节点与父关节点之间形成一段连接,共13段连接。关节点9(hip.l)和关节点13(hip.r)与父关节点(neck)之间的连接没有固定骨长,其余关节点与父关节点之间均形成具有固定骨长的骨头,共11段骨头,标记为<b1,…,b11>;
所述二维人体姿态初步估计,以一张rgb图像作为输入,采用全卷积神经网络模型回归14个关节点的置信度图和关节点之间的亲和力场(partaffinityfield,paf)。对于图像ii,用hi,j,j∈{1,2,…,14}表示第j个关节点的置信度图,关节点j对应的候选点的二维位置
(2)二维关节点候选点在不同视图之间关联。
对于关节点j,该步骤对步骤1获得的来自c个视图的关节点候选点进行关联,实现同一个人的关节点在不同视图之间的对应。
(2.1)三维假设空间构建:
对于关节点j,通过两两三角化不同视图之间的二维关节点对,得到一组三维点,剔除以下无效三维点,剔除无效三维点后的集合为三维假设空间,用λj表示。
(a)集合中重投影误差大于阈值τ1(τ1=8)的三维点为无效三维点;
(b)不符合亲和力场准则约束的三维点为无效三维点:
假定关节点j的父关节点为p,两者之间形成一段连接p→j。则假设空间中三维点
其中,φp为关节点p的三维关节点候选点集合,xp关节点p的三维关节点,τ2=0.3,s(xa,xb)表示两个三维点xa和xb形成一段有效连接的置信度,定义如下:
s(xa,xb)表示关节点xa,和xb来自同一个人并形成该人二维骨架中的一段的置信度,pi表示第i个相机对应的投影矩阵。
(c)假定关节点j的父关节点为p,两者之间形成一段连接p→j。且该连接具有固定骨长,则进一步采用骨长准则剔除无效三维点,所述骨长准则如下:
其中,τ3=4cm,
(2.2)三维假设空间聚类
采用dbscan聚类方法对λj的三维关节点进行聚类,聚类时ε设置为15,最小聚类设置为2。通过聚类将不同人对应的三维点聚到同一个簇。如果一个簇的中心与两个以上父节点的三维候选点满足骨长准则,则对该簇进行分裂。分裂方法是:对于该簇的每个三维点,寻找其最优的满足骨长约束的父关节点候选点,根据父关节点候选点进行重新划分。所述的最优为
(3)三维关节点候选点重建。对于关节点j,将步骤2中同一簇中所有的三维点所对应的n个二维点建立匹配。以视图{i1,...,in}之间匹配的一组二维关节点候选点
(4)三维姿态解析。给定重建的所有人的所有关节点对应的三维候选点,姿态解析将属于同一个的人的三维关节点候选点关联,生成每一个人完整的三维骨架。
(5)姿态跟踪。上述步骤独立地估计每一帧对应的所有人的三维姿态,使用姿态跟踪方法来生成每个人的姿态轨迹,从而得到时序一致的姿态估计。
本发明的有益效果在于:能够实现严重遮挡,多人紧密交互,人数不定等复杂场景下三维人体姿态的鲁棒估计;可以实现对不同骨架尺寸,比例的人进行自动的全局三维人体姿态的可信估计估计;可以实现对快速运动场景下的稳定鲁棒的姿态跟踪。
附图说明
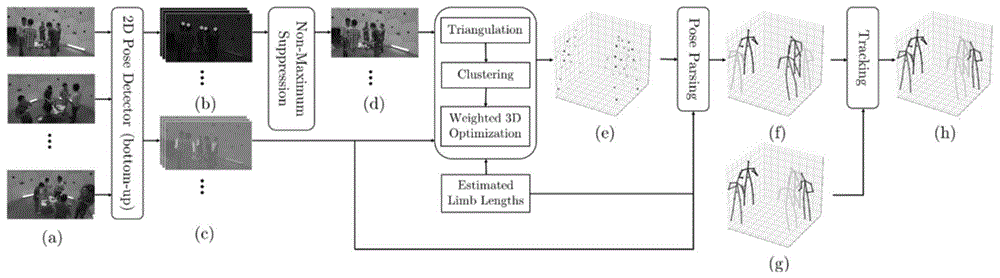
图1:本发明的方法流程图。主要包括基于卷积神经网络(cnn)的初始二维姿态估计,三维姿态重建,姿态跟踪等三个重要环节。
图2:人体骨架模型示意图。本发明考虑由14个关节点和13段连接(其中11段连接具有固定骨长)构成的人体骨架。
图3:三维假设空间示意图。图(a)为初始三维假设空间;图(b)为采用重投影误差准则剔除错误三维点之后的三维假设空间;图(c)为进一步采用亲和力场准则和骨长准则剔除错误三维点之后的三维假设空间;图(d)为采用dbscan聚类之后的三维假设空间。
图4:本发明在campus和shelf数据集上的部分实验结果图。
图5:本发明在panoptic数据集上的部分实验结果图。
图6:本发明部分室内,室外动作捕捉结果。
具体实施方式
本发明旨在估计满足多视图几何约束和骨长约束的可信多人三维人体姿态。首先,本发明提出全自动的多人人体动作捕捉方法,不依赖于任何人体模型或人体骨长、颜色、体型等先验知识,不需要人工干预,人体分割等操作,具有高度的灵活性和实用性。其次,本发明提出了一种简单高效的二维骨骼关键点在多视图之间的关联技术,该技术基于三维假设空间聚类实现了二维关节点在多视图的关联,对错误的二维关节点估计非常鲁棒。最后,本发明提出可靠的多人姿态重建和跟踪技术,该技术通过综合考虑多视图几何约束、骨长约束和多视图图像信息,重建多个人的三维人体姿态,同时提出一种高效的姿态跟踪方法实现相邻帧之间的姿态跟踪,生成时序一致的三维骨架。本发明在不利用人体模型或假设任何人体先验知识的情况下,可以实现对不同体形的,人数不固定的多个人进行稳定可信地二维和全局三维人体姿态估计。本发明生成的姿态满足多视图几何约束和人体骨长约束,实现了在多人相互遮挡、紧密交互等极具挑战的场景下鲁棒可信的人体姿态估计。下面对本发明作进一步说明。
一种基于三维假设空间聚类的多人动作捕捉方法,方法流程图如图1所示,包括以下步骤:
(1)从c个不同视角的相机中分别获取二维rgb图像,定义为{i1,...,ic},如图1(a)所示,每个相机对应的投影矩阵定义为{p1,...,pc};对于获取的c个二维rgb图像,分别进行二维人体姿态的初步估计,即对于每一人体关节点,得到包含所有人的该关节候选点的初始二维位置集合;
人体骨架如图2所示,由14个关节点定义。各个关节点名称如下:<head,neck,shoulder.l,elbow.l,wrist.l,shoulder.r,elbow.r,wrist.r,hip.l,knee.l,ankle.l,hip.r,knee.r,ankle.r>,关节点对应编号依次为<1,2,3,4,5,6,7,8,9,10,11,12,13,14>,各关节点对应的父关节点编号依次为<#,1,2,3,4,2,6,7,2,9,10,2,12,13>。其中#表示无父节点,每个关节点与父关节点之间形成一段连接,共13段连接。关节点9(hip.l)和关节点13(hip.r)与父关节点(neck)之间的连接没有固定骨长,其余关节点与父关节点之间均形成具有固定骨长的骨头,共11段骨头,标记为<b1,…,b11>;
所述二维人体姿态初步估计,以一张rgb图像作为输入,采用全卷积神经网络模型回归14个关节点的置信度图(图1(b))和关节点之间的亲和力场(图1(c))。对于图像ii,用hi,j,j∈{1,2,…,14}表示第j个关节点的置信度图,关节点j对应的候选点的二维位置集合通过对置信度图hi,j进行非极大抑制获得(图1(d)),用
如下步骤2(二维关节点候选点在不同视图之间关联)和步骤3(三维关节点候选点重建)按照关节点编号顺序执行。对于关节点j,定义重建的三维关节点候选点集合为
(2)二维关节点候选点在不同视图之间关联。对于关节点j,该步骤对步骤1获得的来自c个视图的关节点候选点进行关联,实现同一个人的关节点在不同视图之间的对应。
(2.1)三维假设空间构建:
对于关节点j,通过两两三角化不同视图之间的二维关节点对,得到一组三维点,剔除以下无效三维点,剔除无效三维点后的集合为三维假设空间,用λj表示,如图3(a)所示。
(a)集合中重投影误差大于阈值τ1(τ1=8)的三维点为无效三维点,图3(b)展示了去除步骤(a)定义中无效三维点之后的结果,可以看到仍然存在部分错误的三维点满足重投影误差约束如果相应的两个二维候选点满足对极几何约束;
(b)不符合亲和力场准则约束的三维点为无效三维点:
假定关节点j的父关节点为p,两者之间形成一段连接p→j。则假设空间中三维点
其中,φp为关节点p的三维关节点候选点集合,xp关节点p的三维关节点,τ2=0.3,s(xa,xb)表示两个三维点xa和xb形成一段有效连接的置信度,定义如下:
s(xa,xb)表示关节点xa,和xb来自同一个人并形成该人二维骨架中的一段的置信度,pi表示第i个相机对应的投影矩阵。
(c)假定关节点j的父关节点为p,两者之间形成一段连接p→j。且该连接具有固定骨长,则进一步采用骨长准则剔除无效三维点,所述骨长准则如下:
其中,τ3=4cm,
(2.2)三维假设空间聚类
步骤(2.1)得到的三维假设空间是多个人之间共享的。三维假设空间聚类旨在划分该假设空间得到每个人对应的三维假设空间。本发明采用dbscan聚类方法,其好处在于无需实现知道簇的个数,并且对噪声点很鲁棒。聚类结果如图3(d)所示,不同颜色对应不同的簇。聚类后的每一个簇的三维点对应一个人,自然而然地,用于三角化同一个簇内三维点的所有二维候选关节点即相互关联,一组相互关联的二维点将用于重建一个三维关节点候选点。
一种特例是来自不同人的同一个关节点相距非常近的情况(例如:两个击右掌),此时,聚类方法无法对此进行判断从而将不同人对应的三维点聚到同一个簇,意味着丢失了一个三维关节点候选点。为了解决这个问题,如果一个簇的中心与超过一个父节点的三维候选点满足骨长准则,则对该簇进行分裂。分裂方法是:对于该簇的每个三维点,通过寻找其最优的满足骨长约束的父关节点候选点进行重新划分。
(3)三维关节点候选点重建。对于关节点j,对于关节点j,将步骤2中同一簇中所有的三维点所对应的n个二维点建立匹配。以视图{i1,...,in}之间匹配的一组二维关节点候选点
(4)三维姿态解析。给定重建的所有人的所有关节点对应的三维候选点(如图1(e)所示),姿态解析将属于同一个的人的三维关节点候选点关联,生成每一个人完整的三维骨架。本发明将cao等人提出的多人二维姿态解析方法扩展到三维。相应地,关节点候选点之间的连接置信度在三维空间中计算,即公式(1)。此外,每一段可能的连接还必须满足骨长约束。
(5)姿态跟踪。上述步骤独立地估计每一帧对应的所有人的三维姿态,本发明提出一个简单的姿态跟踪方法来生成每个人的姿态轨迹,从而得到时序一致的姿态估计,其中,同一个人的骨架用同一种颜色标记。给定不同帧对应的三维姿态估计,通过将它们在时序上关联来获得轨迹。该问题可以被看作是一个数据关联问题。本发明将该问题简化为相邻帧之间的二分匹配问题。初始化第一帧中每个姿态的轨迹,并采用贪心方式将轨迹标签在相邻帧之间进行传播,对于当前帧中没有匹配上的姿态,新建一个新的轨迹。
表1给出了本发明在shelf和campus数据集上的定量评价结果。表中数据采用pcp(percentageofcorrectparts)作为评价指标。从实验结果可以看出,本发明提出的方法远远好于现有的基于多视图的多人人体姿态估计方法。图4给出了本发明在shelf和campus数据集上的部分实验结果图。可以看出无论是针对室内场景还是室外场景,本发明均可进行有效地姿态估计。
表1
表2给出了本发明在panoptic数据集的不同序列上的定量评价结果。表中数据采用平均关节点误差mpjpe(meanperjointpositionerror)作为评价指标,单位:cm。从实验结果可以看出,本发明提出的方法在该数据集上的误差非常小,平均只有2.2cm。图5给出了本发明在该数据集上的部分实验结果图。
表2
本发明可用于无标记的多人人体动作捕捉,图6给出了部分室内,室外动作捕捉结果,本发明不依赖任何人体先验知识,可用于任何场景下多个人的动作捕捉。
- 还没有人留言评论。精彩留言会获得点赞!