面向乘客舒适性的列车过隧道时长计算方法与流程
本发明涉及面向乘客舒适性的列车过隧道时长计算方法。
背景技术:
进入到21世纪以来,中国高铁发展历经从国外引进到吸收消化再到自主研发,高速列车在我国驱动长足的发展。研发科技人员投入大量精力保证列车的安全安全性之后,乘坐的舒适感成为当前相关研究的关注点。提升旅客列车全旅程的乘客乘车体验有利于提升高铁客运竞争力。全面的信息提示有利于让乘客掌握当前列车运行情况,提升乘客乘车体验。目前车内的提示信息包括气温和列车时速等,但是缺乏对列车通过隧道等特殊工况的相关信息提示。
列车在进入到隧道之后,会出现通讯信息缺失的情况,这使得身处互联网时代下的人们无所适从,使得乘客乘坐舒适感迅速下降。同时隧道中黑暗的密闭环境、车辆密闭性变差后造成的耳膜不适以及未知的隧道长度会使人产生极大的焦虑感。为此设计有效精准的过隧道时长定位方法,及时的告知乘客还需在隧道中等待的时长对提升乘体验感有十分重要的作用。列车通过隧道时长计算的核心是隧道内列车的准确定位。常见的列车定位方法有以下几种:
1、北斗gps定位式,运用北斗卫星定位可提供全方位、全天候、全天时的定位信息,但是不适用于隧道内的列车定位。
2、无线基站式,运用隧道两端的无线基站提供列车信息,有效减少了沿线轨旁设备的使用,但是不适用于隧道内的列车定位。
3、应答式,在铁路沿线布置多个轨旁设备,同时在列车上安装相应的车载设备,具有加好的精度,但是工程成本和维护成本巨大,实用性较差。
技术实现要素:
本发明所要解决的技术问题是,针对现有技术不足,提供一种面向乘客舒适性的列车过隧道时长计算方法,实现隧道内列车至隧道出口距离的智能感知,准确估算列车在隧道内的停留时间。
为解决上述技术问题,本发明所采用的技术方案是:一种面向乘客舒适性的列车过隧道时长计算方法,利用下式估算列车通过当前隧道的剩余时长:t=o(i)/fhz(o(i)-o(i-1));其中,列车当前位置距离隧道出口的距离的最终输出值o(i)=om(i)+ε(i);o(i)为当前样本点的模板匹配输出值;ε(i)为补偿误差输出结果;fhz为位置更新频率。
列车当前位置距离隧道出口的距离的最终输出值om(i)的具体确定过程包括:
1)采集隧道气压气象参数,构建隧道气压气象参数数据库;
2)基于隧道气象参数数据库,按照隧道所处的地理位置及隧道内外的气象情况对隧道气象参数数据库内的气象参数进行归类,得到区域内同类样本,实现属性相近的隧道群体的归类;
3)对区域内同类样本进行进一步划分,获取当前类别的典型样本;
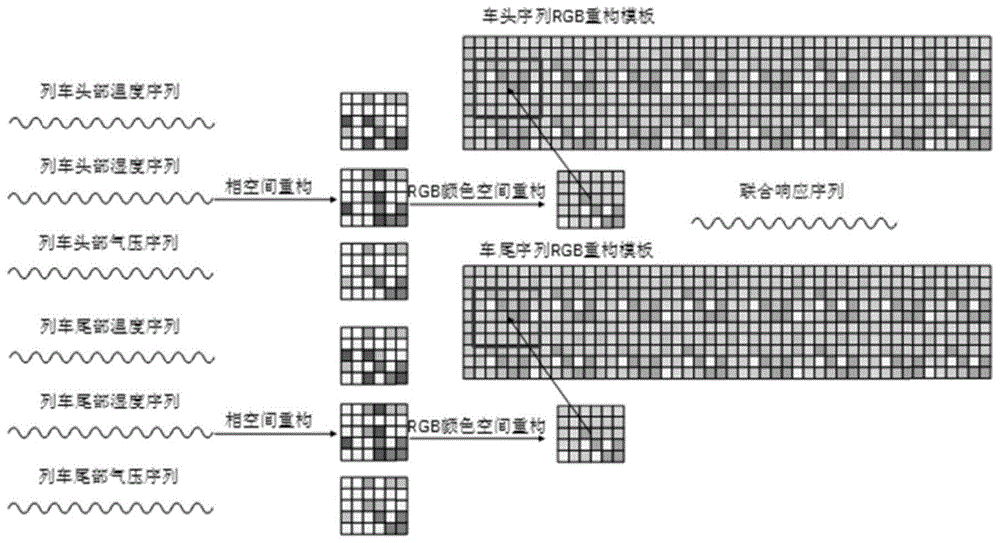
4)将典型样本进行相空间重构,获得列车头部和尾部气压气象参数演化性的彩色图像,即模板图像;所有典型样本对应的模板图像组成典型样本联合模板库;
5)分别采集列车当前位置头部和尾部的样本点及往前的一段时间的样本序列,进行相空间重构和rgb颜色空间组合,构建当前位置特征图像{ch,cf};将当前位置特征图像与典型样本联合模板库中的图像进行相关性计算,确定当前位置在典型样本联合模板库中的最佳匹配位置;
6)采用同类隧道群体的数据,以温度序列、湿度序列、气压序列为输入,以最佳匹配位置的预测误差为输出,训练最小二乘支持向量机,建立隧道里程预测误差补偿模型;
7)实时采集列车运行过程中的气压气象参数,构建当前状态特征图像,进行三维图像模板搜索匹配;确定误差补偿输入变量,误差补偿模型,将模板匹配模型输出与误差补偿模型输出融合,获取最终的距隧道出口里程值,即得到o(i)。
步骤2)的具体实现过程包括:
1)将隧道群归为n类;
2)获取当前区域中1年以来列车通过隧道前取值范围为[10,20]min内的平均气温分布,采用高斯分布函数对平均气温分布进行拟合,获取均值和方差值,将分布按照概率均分为10等份,同属于1等份的样本定义为当前区域下的同类样本。
步骤3)的具体实现过程包括:
1)对每个时间序列进行自回归差分滑动平均模型建模,提取各个序列的自回归项、差分项和移动回归项的参数,区域内同类样本的所有特征量组成特征矩阵a;
2)对区域内同类样本的所有特征量组成的特征矩阵a进行降维处理,选取贡献程度最大的m个主成分表征原始特征矩阵a的信息,获取变换后的矩阵a';
3)定义核函数k=αkrbf+βklinear+(1-α-β)klaplace;其中,krbf为径向基核函数,klinear为线性核,klaplace为拉普拉斯核函数,将a'矩阵中的特征值映射到核函数k对应的特征空间;
4)优化核函数的系数α,β和类别数目n。聚类过程将样本分成n类,每类样本组成一个样本簇。确定优化目标函数
5)按上述设定参数,采用灰狼优化算法优化的k-means聚类算法实现降维后特征的聚类,获取每个聚类样本簇的聚类中心及距离聚类中心最近的5个样本对应的原始时间序列
步骤5)的具体实现过程包括:
1)确定列车当前位置头部和尾部的温度、湿度和气压时间序列中当前样本点及往前的19个采样点;
2)采用延迟坐标法进行相空间重构,获取6个代表列车头尾部温度湿度气压演化特性的二维重构矩阵,将6个矩阵分头尾按照rgb颜色空间组合,形成当前位置特征图像{ch,cf};
3)将当前位置特征图像与模板库中的图像进行卷积运算
4)对所有gi序列中的元素进行由大到小的排序,确定的最大的5个元素为候选元素,候选元素对应的排序前所在位置为候选位置,候选位置对应的距隧道出口里程值为sj,j=1,2,…5;
5)将候选位置对应的距隧道出口里程值取均值确定为当前的模板匹配输出值,即模板匹配输出值
步骤6)的具体实现过程包括:
1)定义输入样本i=(th,hh,ph,tf,hf,pf),其中th=(t1,t2…,t19,t20)为隧道内列车头部当前样本点及往前19个样本点的温度时间序列;hh为长度为20的列车头部湿度时间序列,ph为长度为20的列车头部气压时间序列,th为长度为20的列车尾部温度时间序列,hh为长度为20的列车尾部湿度时间序列,ph为长度为20的列车尾部气压时间序列。输出样本为当前位置对应的里程误差值ε;输入和输出组合y={i,ε}构成建模样本;
2)划分训练样本和验证样本和测试样本,得到训练集和测试集;
3)对输入样本i中每个维度的特征进行二进制编码,当某维度的特征对应的编码值为1时,该特征被选择作为lssvm模型的输入变量,当某维度的特征对应的编码值为0时,该维度的特征被舍弃;将60个维度特征随机初始化编码为0或1;
4)基于当前特征编码值,确定输入特征,采用训练集数据训练lssvm模型;将验证集数据输入训练好的lssvm模型,获取模型输出序列为
5)采用二进制蚁狮算法进行迭代优化运算,确定最优的输入特征和lssvm模型,该模型为lssvm里程预测误差补偿模型。
步骤7)的具体实现过程包括:
1)采集列车通过隧道前取值范围为[10,20]min内的平均气温分布,确定当前状态所属于的样本类别,利用安装在列车头部和尾部的温度湿度传感器,获取当前的温度湿度序列;
2)依据当前平均气温确定当前状态所属的样本类别,提取相应的模板库;
3)在模板模板库中确定最佳匹配位置,输出当前样本点的模板匹配输出值om(i);
4)获取当前状态的模型输入向量i,代入训练好的lssvm模型,获取补偿误差输出结果ε(i);
5)融合三维模板匹输出值和lssvm模型输出值,获取当前位置距离隧道出口的距离的最终输出值为o(i)=om(i)+ε(i)。
与现有技术相比,本发明所具有的有益效果为:本发明利用人工智能大数据分析技术,充分挖掘隧道内气压气象参数随隧道深度变化的潜在规律。通过列车两端获取的温度、湿度和气压时间序列数据,实现隧道内列车至隧道出口距离的智能感知。在此基础上实现列车还需在隧道内停留时间的有效估算。可为乘客提供准确的信息提示,有利于提升乘客乘车体验。同时本发明所述方法在建模完成后只需要车载温度、湿度和气压传感器即可实现输入数据采集,无需任何轨旁设备,具有较大的推广价值。
附图说明
图1为时间序列相空间重构与rgb联合模板匹配示意图;
图2为本发明主流程图。
具体实施方式
本发明具体步骤如下:
步骤1:采集隧道气压气象参数,构建隧道气压气象参数数据库
通过分布于列车两端的车载传感器实时采集列车通过时隧道内的温度和湿度和气压序列,通过事先安装在隧道内和车上的应答装置采集列车在隧道内的里程时间序列,采样频率为10hz。采用列车进入隧道前tmin采集的温度和湿度的平均值作为当地温度湿度平均值的估计值。列车一次通过某隧道时位于列车两端的传感器采集的温度序列、湿度序列、气压序列及进入隧道前获取的所在区域的平均气温、平均湿度的估计值值构成1组隧道气象参数样本。辖区内所有列车1年内运行采集的隧道气象参数样本构成隧道气象参数数据库。t取值范围为[10,20],本发明中,t=10。
步骤2:隧道群气压气象参数分类
基于隧道气象参数数据库,按照隧道所处的地理位置及隧道内外的气象情况对数据库内的气象参数进行归类,实现属性相近的隧道群体的归类。具体实现流程如下:
步骤a1:按照中国建筑区划对中国气候特征的划分,根据数据库中的隧道样本所处的地理位置将隧道群归为7类。对每个区域内的隧道群分别建模。
步骤a2:获取当前区域中1年以来列车通过隧道前tmin内的平均气温分布,采用高斯分布函数对平均气温分布进行拟合,获取均值和方差值。将分布按照概率均分为10等份,同属于1等份的样本定义为当前区域下的同类样本。
步骤3:区域内同类样本典型样本表征
针对每个基于隧道类别粗划分输入属性集合获得的区域内同类样本进行进一步划分。具体包括以下子步骤:
步骤b1:针对样本簇中列车通过隧道时的温度、湿度和气压时间序列进行演化特征提取。具体步骤为对每个时间序列进行自回归差分滑动平均模型(arima)建模,提取各个序列的自回归项、差分项和移动回归项的参数。具体地,列车一次通过隧道采集的时间序列可采集6列时间序列,因此列车一次通过隧道提取的特征量可表示为a=(p1,d1,q1,p2,d2,q2,…,p6,d6,q6),区域内同类样本的所有特征量组成特征矩阵a。
步骤b2:采用主成分分析算法(pca)对区域内同类样本的所有特征量组成特征矩阵a进行降维处理。选取贡献程度最大的5个主成分表征原始特征矩阵a的信息,获取变换后的矩阵a'。
步骤b3:定义核函数
k=αkrbf+βklinear+(1-α-β)klaplace(1)
式中krbf为径向基核函数,klinear为线性核,klaplace为拉普拉斯核函数。将a'矩阵中的特征值映射到核函数k对应的特征空间。
步骤b4:确定优化的对象,采用灰狼优化算法(gwo)优化核函数的系数α,β和类别数目。其中α,β∈[0,1],类别数目为小于20的正整数。
步骤b5:确定优化目标函数
式中avg(ci)为簇ci中样本的平均距离,dcen(ci,cj)为簇ci与为簇cj中心点间的距离。
步骤b6:按上述设定参数,采用灰狼优化算法优化的k-means聚类算法实现降维后特征的聚类结果。获取每个聚类样本簇的聚类中心及距离聚类中心最近的5个样本对应的原始时间序列
步骤4:构建典型样本联合模板库
将典型样本进行相空间重构,设定延迟时间为1,窗口长度为5,采用延迟坐标法对温度、湿度和气压时间序列进行相空间重构,获取三个代表列车头部温度、湿度和气压演化特性和三个代表列车尾部温度、湿度和气压演化特性的二维重构矩阵,将三个矩阵按照rgb颜色空间组合,形成列车头部和尾部气压气象参数演化性的彩色图像即为模板图像{hi,fi},i=0,1,2…5。
步骤5:训练模板rgb彩色联合匹配模型
分别采集列车当前位置头部和尾部的样本点及往前的一段时间的样本序列,进行相空间重构和rgb颜色空间组合,构建当前位置特征图像{ch,cf}。将当前位置特征模块与模板库中图像进行相关性计算,确定当前位置在模板库中的最佳匹配位置。具体包括以下步骤:
步骤c1:列车当前位置头部和尾部的温度、湿度和气压时间序列中当前样本点及往前的19个采样点。
步骤c2:设定延迟时间为1,窗口长度为5,采用延迟坐标法进行相空间重构,获取6个代表列车头尾部温度湿度气压演化特性的二维重构矩阵,将6个矩阵分头尾按照rgb颜色空间组合,形成当前位置特征图像{ch,cf}。
步骤c3:将当前位置特征图像与模板库中的图像进行卷积运算
步骤c4:对所有gi序列中的元素进行由大到小的排序,确定的最大的5个元素为候选元素,候选元素对应的排序前所在位置为候选位置,候选位置对应的距隧道出口里程值为sj,j=1,2,…5。
步骤c5:将候选位置对应的距隧道出口里程值取均值确定为当前的模板匹配输出值,即模板匹配输出值
步骤6:建立联合模板匹配误差补偿模型
采用同类隧道群体的数据,以温度序列、湿度序列、气压序列为输入,以模板匹配模型的预测误差为输出,训练最小二乘支持向量机(lssvm),建立隧道里程预测误差补偿模型。具体包括以下步骤:
步骤d1:定义训练样本,定义输入样本i=(th,hh,ph,tf,hf,pf),其中th=(t1,t2…,t19,t20)为隧道内列车头部当前样本点及往前19个样本点的温度时间序列。类似的,hh为长度为20的列车头部湿度时间序列,ph为长度为20的列车头部气压时间序列,th为长度为20的列车尾部温度时间序列,hh为长度为20的列车尾部湿度时间序列,ph为长度为20的列车尾部气压时间序列。输出样本为当前位置对应的里程误差值ε。输入和输出组合y={i,ε}构成建模样本。针对每个同类隧道群体,选取3000个样本用于建立里程预测误差补偿模型。
步骤d2:划分训练样本和验证样本和测试样本。采用无放回随机采样的方式选取3000个样本中70%作为训练集,30%作为验证集。
步骤d3:确定优化对象,初始化优化值。采用二进制蚁狮算法优化模型的输入特征,即对输入样本i中每个维度的特征进行二进制编码,当某维度的特征对应的编码值为1时,该特征被选择作为lssvm模型的输入变量,当某维度的特征对应的编码值为0时,该维度的特征将被舍弃。将60个维度特征随机初始化编码为0或1。
步骤d4:确定优化目标函数。基于当前特征编码值,确定输入特征,采用训练集数据训练lssvm模型。将验证集数据输入训练好的lssvm模型,获取模型输出序列为
式中
步骤d5:输出优化预测模型。采用二进制蚁狮算法进行迭代优化运算,确定最优的输入特征和lssvm模型,该模型为lssvm里程预测误差补偿模型。
步骤7:获取测试数据,调用里程预测模型
列车运行过程中,采集实时气压气象参数,构建当前状态特征图像,进行三维图像模板搜索匹配;确定误差补偿输入变量,误差补偿模型。将模板匹配输出与误差补偿输出融合获取最终的距隧道出口里程值。具体包括以下步骤:
步骤e1:采集列车通过隧道前tmin内的平均气温分布。确定当前状态所属于的样本类别。利用安装在列车头部和尾部的温度湿度传感器,获取当前的温度湿度序列。
步骤e2:依据当前平均气温确定当前状态所属的样本类别,提取相应的模板库。
步骤e3:参照步骤3中的流程,在模板模板库中确定最佳匹配位置,输出当前样本点的模板匹配输出值om(i)。
步骤e4:参照步骤6中的流程c1的流程,获取当前状态的模型输入向量i,代入训练好的lssvm模型,获取补偿误差输出结果ε(i)。
步骤e5:融合三维模板匹输出值和lssvm模型输出值,获取当前位置距离隧道出口的距离的最终输出值为
o(i)=om(i)+ε(i)(5)
步骤8:出隧道预测剩余时长计算
可根据下式对列车通过当前隧道的剩余时长进行估算:
t=o(i)/fhz(o(i)-o(i-1))(6)
式中fhz为位置更新频率。
- 还没有人留言评论。精彩留言会获得点赞!