一种基于描述文本的云服务本体构建方法与流程
本发明涉及及面向服务的协同领域,尤其是一种云服务本体构建方法。
背景技术:
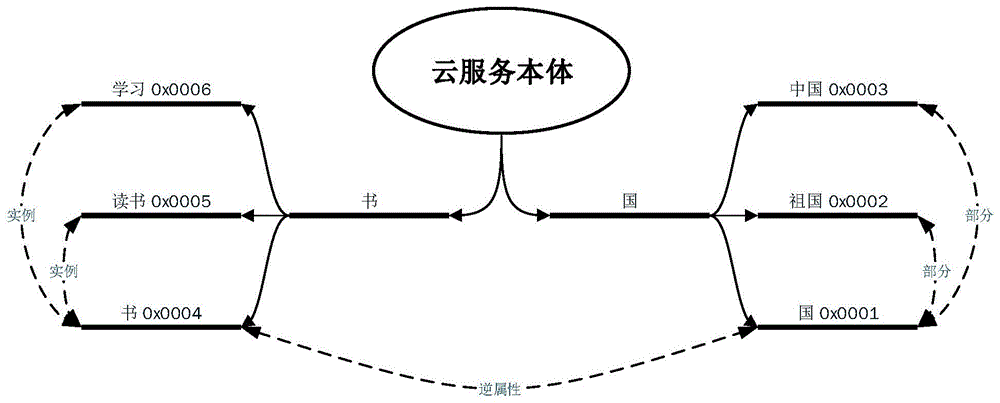
:云协同的核心功能之一是云服务存储及发现功能,而云服务本体构建是云服务存储及发现的重要技术之一。云服务本体构建是指基于云服务资源池中的云服务,定义一个云协同领域内的词汇及词汇之间的关系,从而能够在对资源的封装过程中对语义进行精确地描述,高效实现云服务的搜索与绑定。传统的云服务本体大多是由领域专家手工建立的。首先需要获取领域知识,即列出该领域中可能用到的概念词汇;然后根据领域中的需求,建立相应类及其之间的层次结构。通常而言,云服务本体的建立往往采用自行归纳的方式,主观意识较强,且在该领域中遵循的命名规范并非公认的命名规范。有些概念模型可能被其它应用者或机器错误解释,而只有建立者才能正确解释。这种手工建立的本体违背了本体不应具有二义性的本质,也不利于后期的更新和维护。因此,由领域专家人工建立云服务本体的方法在实际应用中主观性较强,不利于大规模应用。技术实现要素:为了克服现有技术的不足,本发明提供一种基于描述文本的云服务本体构建方法。本发明解决其技术问题所采用的技术方案包括以下步骤:步骤1:设目标领域云服务资源池中存储有m条云服务,云服务资源池中第i条云服务的描述文本由ni个字符组成,其中,i=1,2,...,m,将所有云服务的描述文本归集在一起,生成该云服务资源池的语料库;步骤2:对步骤1中获得的目标领域语料库进行n元切分,生成候选概念词汇集合mcna;云服务资源池中第i条云服务的描述文本式中desi代表第i条云服务描述文本的字符有序集合,cj为字符集合中的第j个字符;设desi的有序子集式中desi为服务资源池中第i条云服务的描述文本的一个有序子集,即候选概念词汇;取desi所有的候选概念词汇生成集合mi;设mcan={m1∪m2∪...∪mm},mcan为候选概念词汇集合,mm为云服务资源池中第m条云服务描述文本生成的所有候选概念词汇集合,则mcan中候选概念词汇数量步骤3:设第p条候选概念词汇的长度为lenp,在集合中出现的频次为freqp,在进行n元切分前对应的云服务描述文本长度为tlenp,候选概念词汇集合中最大词汇长度为max(len);设候选概念词汇权重选取阈值为wthre,本发明取wthre=0.2±0.1,对候选概念词汇集合mcan中每条候选概念词汇权重weight(p)与阈值wthre比对,若weight(p)>wthre,则将第p条候选概念词汇cp放入概念词汇集合mcon中,否则将第p条候选概念词汇抛弃,即mcon={cp|weight(p)>wthre};步骤4:对概念词汇集合mcon中的概念词汇进行聚类,聚类方法如下:(a)根据领域专家经验,选取云服务本体类数目k;(b)在概念词汇集合mcon中随机抽取k条概念词汇{d1,d2,...,dk},构成质心词汇集合mcent;(c)设云服务本体类集合class={m1,m2,...,mk},式中mj为云服务本体类下属概念词汇的集合,且为空集,其中,j=1,2,...,k;(d)设语义距离的计算公式为式中ngd(c1,c2)表示概念c1和c2间的语义距离,f(c1)、f(c2)分别表示包含概念c1和c2的云服务描述数,logf(c1,c2)表示同时含有概念c1和c2的云服务描述数,m表示云服务总数;(e)对mcon的所有概念词汇ci,分别在质心词汇集合mcent中选择一个与概念词汇ci对应的语义距离最小的质心词汇dj,即对于质心词汇集合中任意质心词汇d∈mcent,都成立|dis(ci,d)|≥|dis(ci,dj)|;将概念词汇ci放入云服务本体类集合class中的mj集合;(f)在概念词汇集合mcon中随机选择一条参考词汇cabs,在本体类集合class中的每一个mj集合中,分别寻找集合新质心cj,使得的绝对值最小,并将cj放入新质心词汇集合mcent_new中;(g)对比新质心词汇集合mcent_new与旧质心词汇集合mcent,若发生变化,转到步骤(c),否则转到步骤(h);(h)将云服务本体类集合class中的mj集合命名为质心词汇集合mcent中对应的质心词汇cj;至此,可获得云服务本体类集合{m1,m2,...,mk};步骤5:依据领域知识及概念词汇语义,人工为各个云服务本体类及其中所有概念词汇添加对象属性,对象属性关系包括:(a)若概念a和概念b有关系的同时,概念b和概念a有关系则定义a与b为逆属性关系;(b)若概念a和概念b,记a'={x|x∈a},b'={x|x∈b},如果对任意的x∈b',x都属于a',则定义a与b为继承关系;(c)若概念a是概念b的一部分,则定义a与b为部分关系;(d)若a是概念b的实例,则定义a与b为实例关系;(e)若a是概念b的属性,则定义a与b为属性关系;步骤6:为云服务本体类集合{m1,m2,...,mk}中所有的概念词汇添加数据属性:(a)一级属性包括但不限于唯一标识(id)、通用值属性、静态值属性、动态值属性等;(b)二级属性是一级属性的拓展,通用值属性(universalpro)指所有资源具有的基础属性,包括但不限于访问地址(url)、服务质量(qos)、服务状态(state)、使用成本(cost)和使用收益(income);静态值属性(staticpro)描述了云服务的基本信息,如资源种类、资源型号及与特定类型服务相关的属性;动态值属性(dynamicpro)描述了云服务的可变属性,表示云服务在使用、空闲、维护等阶段的各种不同状态的信息,如云服务的可持续工作时间等;部署属性(deploymentpro)是云服务的所处的位置坐标等;特有属性(specificpro)指与云服务类型相关的属性,不同类型的云服务具有不同的特有属性。本发明的有益效果是将云服务本体构建应用于云协同中,提出了基于云服务描述文本的半自主云服务本体构建方法,与传统的人工构建本体方法相比,充分利用了云服务功能描述的语义信息,可以更准确地构建云服务本体。附图说明图1是本发明已建立的云服务本体示意图。具体实施方式下面结合附图和实施例对本发明进一步说明。步骤1:设目标领域云服务资源池中存储有m条云服务,云服务资源池中第i条云服务的描述文本由ni个字符组成,其中,i=1,2,...,m,将所有云服务的描述文本归集在一起,生成该云服务资源池的语料库;步骤2:对步骤1中获得的目标领域语料库进行n元切分,生成候选概念词汇集合mcna;云服务资源池中第i条云服务的描述文本式中desi代表第i条云服务描述文本的字符有序集合,cj为字符集合中的第j个字符;设desi的有序子集式中desi为服务资源池中第i条云服务的描述文本的一个有序子集,即候选概念词汇;取desi所有的候选概念词汇生成集合mi;设mcan={m1∪m2∪...∪mm},mcan为候选概念词汇集合,mm为云服务资源池中第m条云服务描述文本生成的所有候选概念词汇集合,则mcan中候选概念词汇数量步骤3:设第p条候选概念词汇的长度为lenp,在集合中出现的频次为freqp,在进行n元切分前对应的云服务描述文本长度为tlenp,候选概念词汇集合中最大词汇长度为max(len);设候选概念词汇权重选取阈值为wthre,本发明取wthre=0.2±0.1,对候选概念词汇集合mcan中每条候选概念词汇权重weight(p)与阈值wthre比对,若weight(p)>wthre,则将第p条候选概念词汇cp放入概念词汇集合mcon中,否则将第p条候选概念词汇抛弃,即mcon={cp|weight(p)>wthre};步骤4:对概念词汇集合mcon中的概念词汇进行聚类,聚类方法如下:(a)根据领域专家经验,选取云服务本体类数目k;(b)在概念词汇集合mcon中随机抽取k条概念词汇{d1,d2,...,dk},构成质心词汇集合mcent;(c)设云服务本体类集合class={m1,m2,...,mk},式中mj为云服务本体类下属概念词汇的集合,且为空集,其中,j=1,2,...,k;(d)设语义距离的计算公式为式中ngd(c1,c2)表示概念c1和c2间的语义距离,f(c1)、f(c2)分别表示包含概念c1和c2的云服务描述数,logf(c1,c2)表示同时含有概念c1和c2的云服务描述数,m表示云服务总数;(e)对mcon的所有概念词汇ci,分别在质心词汇集合mcent中选择一个与概念词汇ci对应的语义距离最小的质心词汇dj,即对于质心词汇集合中任意质心词汇d∈mcent,都成立|dis(ci,d)|≥|dis(ci,dj)|;将概念词汇ci放入云服务本体类集合class中的mj集合;(f)在概念词汇集合mcon中随机选择一条参考词汇cabs,在本体类集合class中的每一个mj集合中,分别寻找集合新质心cj,使得的绝对值最小,并将cj放入新质心词汇集合mcent_new中;(g)对比新质心词汇集合mcent_new与旧质心词汇集合mcent,若发生变化,转到步骤(c),否则转到步骤(h);(h)将云服务本体类集合class中的mj集合命名为质心词汇集合mcent中对应的质心词汇cj;至此,可获得云服务本体类集合{m1,m2,...,mk};步骤5:依据领域知识及概念词汇语义,人工为各个云服务本体类及其中所有概念词汇添加对象属性,对象属性关系包括:(a)若概念a和概念b有关系的同时,概念b和概念a有关系则定义a与b为逆属性关系;(b)若概念a和概念b,记a'={x|x∈a},b'={x|x∈b},如果对任意的x∈b',x都属于a',则定义a与b为继承关系;(c)若概念a是概念b的一部分,则定义a与b为部分关系;(d)若a是概念b的实例,则定义a与b为实例关系;(e)若a是概念b的属性,则定义a与b为属性关系;步骤6:为云服务本体类集合{m1,m2,...,mk}中所有的概念词汇添加数据属性:(a)一级属性包括但不限于唯一标识(id)、通用值属性、静态值属性、动态值属性等;(b)二级属性是一级属性的拓展,通用值属性(universalpro)指所有资源具有的基础属性,包括但不限于访问地址(url)、服务质量(qos)、服务状态(state)、使用成本(cost)和使用收益(income);静态值属性(staticpro)描述了云服务的基本信息,如资源种类、资源型号及与特定类型服务相关的属性;动态值属性(dynamicpro)描述了云服务的可变属性,表示云服务在使用、空闲、维护等阶段的各种不同状态的信息,如云服务的可持续工作时间等;部署属性(deploymentpro)是云服务的所处的位置坐标等;特有属性(specificpro)指与云服务类型相关的属性,不同类型的云服务具有不同的特有属性。本发明的实施例包括以下几个步骤:1.获取语料库对目标云协同系统所使用的云服务资源池中所有云服务的描述文本进行统计归纳,生成该云服务资源池的语料库。2.将语料库中m条云服务的描述文本切分成短语,生成候选概念词汇集合mcna,步骤如下:(a)云服务资源池中第i条云服务的描述文本式中desi代表第i条云服务描述文本的字符有序集合,cj为字符集合中的第j个字符;(b)设desi的有序子集式中desi为服务资源池中第i条云服务的描述文本的一个有序子集,也被称为候选概念词汇;取desi所有的候选概念词汇生成集合mi;(c)设mcan={m1∪m2∪...∪mm},式中mcan为候选概念词汇集合,mm为云服务资源池中第m条云服务描述文本生成的所有候选概念词汇集合,且上式中,num为mcan中候选概念词汇数量。3.筛选有效概念词汇(a)计算候选概念词汇权重设第p条候选概念词汇的长度为lenp,在集合中出现的频次为freqp,在进行n元切分前对应的云服务描述文本长度为tlenp,候选概念词汇集合中最大词汇长度为max(len),候选概念词汇权重计算公式为:(b)基于权重筛选有效概念词汇选取合适的阈值wthre,对候选概念词汇集合mcna中每条候选概念词汇权重weight(p)与阈值wthre比对,若weight(p)>wthre,则将第p条候选概念词汇cp放入概念词汇集合mcon中,即mcon={cp|weight(p)>wthre};(c)人工删除无效概念词汇;4.概念词汇聚类筛选出的有效概念词汇需要进行聚类,方可用于云服务本体的构建。对概念词汇集合mcon中的概念词汇聚类,方法如下:(a)选取合适的云服务本体类数目k;(b)在概念词汇集合mcon中随机抽取k条概念词汇{d1,d2,...,dk},构成质心词汇集合mcent;(c)设云服务本体类集合class={m1,m2,...,mk},式中mj(j=1,2,...,k)为云服务本体类下属概念词汇的集合,且为空集;(d)设语义距离的计算公式为:上式中ngd(c1,c2)表示概念c1和c2间的语义距离,f(c1)、f(c2)分别表示包含概念c1和c2的云服务描述数,logf(c1,c2)表示同时含有概念c1和c2的云服务描述数,m表示云服务总数;(e)对mcon的所有概念词汇ci,分别在mcent中选择一个与之对应的语义距离最短的质心词汇dj,即对于任意d∈mcent,都成立|dis(ci,d)|≥|dis(ci,dj)|;将概念词汇ci放入云服务本体类集合class中的mj集合;(f)在概念词汇集合mcon中随机选择一条参考词汇cabs,在本体类集合class中的每一个mj集合中,分别寻找集合新质心cj,使得绝对值最小,并将cj依次放入新质心词汇集合mcent_new中;(g)对比新质心词汇集合mcent_new与旧质心词汇集合mcent,若发生变化,转到(c),否则转到(h);(h)将云服务本体类集合class中的mj集合命名为质心词汇集合mcent中对应的质心词汇cj;通过步骤(a)至步骤(h),获得云服务本体类集合{m1,m2,...,mk}。5.添加对象属性依据领域知识及概念词汇语义,人工为各个云服务本体类及其中所有概念词汇添加对象属性。定义1:若概念a和概念b有关系的同时,概念b和概念a有关系则定义a与b为逆属性关系。定义2:若概念a和概念b,记a'={x|x∈a},b'={x|x∈b},如果对任意的x∈b',x都属于a',则定义a与b为继承关系。定义3:若概念a是概念b的一部分,则定义a与b为部分关系。定义4:若概念a是概念b的实例,则定义a与b为实例关系。定义5:若概念a是概念b的属性,则定义a与b为属性关系。6.添加数据属性为云服务本体类集合{m1,m2,...,mk}中所有的概念词汇添加数据属性,主要包括:(a)一级属性包括但唯一标识(id)、通用值属性、静态值属性、动态值属性等;(b)二级属性是一级属性的拓展,通用值属性(universalpro)指所有资源具有的基础属性,如访问地址(url)、服务质量(qos)、服务状态(state)、使用成本(cost)和使用收益(income)等;静态值属性(staticpro)描述了云服务的基本信息,如资源种类、资源型号及与特定类型服务相关的属性;动态值属性(dynamicpro)描述了云服务的可变属性,表示云服务在使用、空闲、维护等阶段的各种不同状态的信息,如云服务的可持续工作时间等;部署属性(deploymentpro),是云服务的所处的位置坐标等;特有属性(specificpro)指与云服务类型相关的属性,不同类型的云服务具有不同的特有属性。假设云服务资源池中包含10个云服务,其描述如表1所示:序号云服务描述序号云服务描述1为中国喝彩6读书忌死读2祝福祖国7读书求理3祖国在心中8学习读书4我爱你中国9好好学习5国富则民强10学而不思表1资源池中云服务描述文本1.获取语料库将云服务资源池中10条云服务描述归纳整理,生成该云服务资源池的语料库:{‘为中国喝彩’,‘祝福祖国’,‘祖国在心中’,‘我爱你中国’,‘国富则民强’,‘读书忌死读’,‘读书求理’,‘学习读书’,‘好好学习’,‘学而不思’}2.对语料库中文本进行n元切分,生成候选概念词汇集合。语料库中第1条云服务描述文本des1={‘为’,‘中’,‘国’,‘喝’,‘彩’},des1的所有有序子集构成集合m1={‘为’,‘为中’,‘为中国’,‘为中国喝’,‘为中国喝彩’,‘中’,‘中国’,‘中国喝’,‘中国喝彩’,‘国’,‘国喝’,‘国喝彩’,‘喝’,‘喝彩’,‘彩’},后9条云服务描述文本同理。取其并集可获得候选概念词汇集合mcna:mcan={‘为’,‘为中’,‘为中国’,‘为中国喝’,‘为中国喝彩’,‘中’,‘中国’,‘中国喝’,‘中国喝彩’,‘国’,‘国喝’,‘国喝彩’,‘喝’,‘喝彩’,‘彩’,‘祝’,‘祝福’,‘祝福祖’,‘祝福祖国’,‘福’,‘福祖’,‘福祖国’,‘祖’,‘祖国’,‘国’,‘祖’,‘祖国’,‘祖国在’,‘祖国在心’,‘祖国在心中’,‘国’,‘国在’,‘国在心’,‘国在心中’,‘在’,‘在心’,‘在心中’,‘心’,‘心中’,‘中’,‘我’,‘我爱’,‘我爱你’,‘我爱你中’,‘我爱你中国’,‘爱’,‘爱你’,‘爱你中’,‘爱你中国’,‘你’,‘你中’,‘你中国’,‘中’,‘中国’,‘国’,‘国’,‘国富’,‘国富则’,‘国富则民’,‘国富则民强’,‘富’,‘富则’,‘富则民’,‘富则民强’,‘则’,‘则民’,‘则民强’,‘民’,‘民强’,‘强’,‘读’,‘读书’,‘读书忌’,‘读书忌死’,‘读书忌死读’,‘书’,‘书忌’,‘书忌死’,‘书忌死读’,‘忌’,‘忌死’,‘忌死读’,‘死’,‘死读’,‘读’,‘读’,‘读书’,‘读书求’,‘读书求理’,‘书’,‘书求’,‘书求理’,‘求’,‘求理’,‘理’,‘学’,‘学习’,‘学习读’,‘学习读书’,‘习’,‘习读’,‘习读书’,‘读’,‘读书’,‘书’,‘好’,‘好好’,‘好好学’,‘好好学习’,‘好’,‘好学’,‘好学习’,‘学’,‘学习’,‘习’,‘学’,‘学而’,‘学而不’,‘学而不思’,‘而’,‘而不’,‘而不思’,‘不’,‘不思’,‘思’,}3.筛选有效概念词汇第1条候选概念词汇‘为’的长度为len1=1,在集合中出现的频次为freq1=1,在进行n元切分前对应的云服务描述文本‘为中国喝彩’的长度为tlen1=5,最大词汇长度为max(len)=5,由公式(1)得,第1条候选概念词汇权重其余候选概念词汇权重计算方法同理。选取阈值wthre=0.2,经对比后保留权重大于wthre的概念词汇,获得概念词汇集合mcon={‘中’,‘国’,‘祖’,‘读’,‘书’,‘好’,‘学’,‘习’,‘祖国’,‘中国’,‘读书’,‘学习’}。经人工判断,删除无效概念词汇后,概念词汇集合mcon={‘国’,‘书’,‘祖国’,‘中国’,‘读书’,‘学习’}。4.概念词汇聚类选取云服务本体类数目k=2,在概念词汇集合mcon={‘国’,‘书’,‘祖国’,‘中国’,‘读书’,‘学习’}中随机抽取2条概念词汇{‘国’,‘书’},构成质心词汇集合mcent;设云服务本体类集合class={m1,m2},且为空集;对于概念词汇c1=‘祖国’,分别计算其与质心词汇d1=‘国’与d2=‘书’的语义距离,由式(2)可得:由于ngd(c1,d1)<ngd(c1,d2),将c1归入本体类m1中,其余概念词汇同理,可获得m1={‘祖国’,‘中国’,‘国’},m2={‘书’,‘学习’,‘读书’};任取参考词汇cabs=‘国’,对本体类m1、m2分别寻找新质心d1、d2,获得新质心词汇集合mcent_new={‘国’,‘书’}。由于mcent_new=mcent,聚类过程完成,将本体类m1命名为‘国’,本体类m2命名为‘书’。5.添加对象属性依据领域知识及概念词汇语义可知,在本体类m1中,‘祖国’与‘国’、‘中国’与‘国’均为部分关系;在本体类m2中,‘学习’与‘书’、‘读书’与‘书’均为实例关系;‘国’与‘书’为逆属性关系。6.添加数据属性本实施例中仅为概念词汇添加唯一标识(id)属性,如表2所示:概念词汇唯一标识(id)概念词汇唯一标识(id)概念词汇唯一标识(id)国0x0001祖国0x0002中国0x0003书0x0004读书0x0005学习0x0006表2概念词汇唯一标识(id)属性至此,基于描述文本的云服务本体建立完成,示意图如图1所示。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1