基于跨模态注意力卷积神经网络的课程领域多模态文档分类方法与流程
本发明属于计算机应用领域、多模态数据分类、教育数据分类、图像处理、文本处理、特别涉及一种基于跨模态注意力卷积神经网络的课程领域多模态文档分类方法。
背景技术:
随着科学技术的发展,计算机在各个领域所要处理的数据从单一的图像,已经转变成形式和内容更加丰富的图像,文本,音频等多模态数据。多模态文档的分类在视频分类,视觉问答,社交网络的实体匹配等方面都有应用。多模态文档分类的准确性取决于,计算机是否能准确地理解文档内所蕴含图像和文本的语义和内容。然而,课程领域的图文混合多模态文档中的图像一般由线条和字符构成,在颜色和纹理等视觉特征上表现出较高的稀疏特性;多模态文档中的文本和图像的语义之间表现出局部关联的特点,这使得现有的多模态文档分类模型难以准确地构建出文档中图像和文本的语义特征向量,从而降低了多模态文档特征表达的准确性,阻碍了它们在多模态文档分类任务上的性能。
为了解决以上问题,本发明扩展了模型体系结构,提出了一种基于跨模态注意力卷积神经网络的课程领域多模态文档分类方法。这种方法可以很好的提取到课程领域中的稀疏图像特征,高效构建与图像语义局部细粒度语义关联的文本特征,能够更加准确地学习和特定对象相关的图像和文本特征之间关联关系,从而提高多模态文档分类的性能。
技术实现要素:
要解决的技术问题
课程领域的图文混合多模态文档数据中的图像视觉特征稀疏、文本和图像之间仅存在局部语义关联,这使得现有多模态文档分类模型很难准确地理解文档内文本和图像的语义和内容,这也极大影响了多模态分类的性能。针对上述问题,本发明提出一种基于跨模态注意力卷积神经网络的课程领域多模态文档分类方法,该方法能够更为高效的学习到具有特征稀疏性的课程领域图像的语义特征,并且能够更好的捕获到多模态文档中图像和文本之间的局部细粒度语义关联,准确表达多模态文档特征的同时,提高了计算机在课程领域多模态文档数据分类的性能。
技术方案
一种基于跨模态注意力卷积神经网络的课程领域多模态文档分类方法,其特征在于步骤如下:
步骤1:多模态文档数据的预处理
步骤1.1:每个多模态文档包含一张图像和一段文本描述,并附带多个语义标签;利用文档中的文本描述和文档标签集合构建词典;将出现频次小于13的标签删除,当多模态文档的语义标签数目为0时将该文档删除;
步骤1.2:数据预处理,对于图像数据随机裁剪成长宽为224*224的大小,并进行随机水平翻转;对于文本描述,将所有的文本长度截断和补齐成长度l,并用词向量模型学习文本中词的向量表示;
步骤2:基于注意力机制的深度跨模态特征提取
步骤2.1:采用基于空间和特征注意力机制cbam的稠密卷积神经网络densenet进行图像特征的表示构建,将得到的图像特征记为
步骤2.2:采用双向长短期记忆网络bilstm和文本注意力机制构建文本特征,其中文本注意力机制由两个卷积层和一个softmax分类器构成;将计算得到的权重记为
步骤3:基于注意力机制的分组跨模态融合
步骤3.1:将步骤2获得的图像特征x,分为r组,将每一组图像特征
步骤3.2:对每一组融合后的特征zi,利用通道注意力机制,计算每个通道上特征图的权重,将加权后的特征记为z′;
步骤3.3:将每一组取得具有权重的融合特征zi′通过一个全连接层;再将多组全连接层的输出向量,采用向量中对应元素相加的方式融合,然后通过sigmoid分类器,计算得到多模态文档在每个标签上的概率分布
根据权利要求1所述的一种基于跨模态注意力卷积神经网络的图像分类模型,其特征在于所述的步骤1.2中根据图像和文本本身的特征,对面向课程领域的多模态文档数据进行处理,对于第i个预处理好的多模态文档,最终得到(ri,ti,li):
(1)从课程领域的图文混合多模态文档数据中随机取样;
(2)对多模态文档的每一个图像:
(a)将图像进行缩放保持长宽比不变,最短边为256;再将图片随机裁剪为长宽224*224;并进行随机水平翻转;最后进行通道值归一化得到
(3)对多模态文档中每一个文本描述:
(a)统计所有文本描述的长度,选取长度l,l=484,其中92%文本长度小于该长度;
(b)将所有的数据进行截断和补齐成一样的长度l;
(c)使用词向量,也被称为词嵌入,将字词序号映射到实数域上的向量,并对其权重进行训练;
(d)字词序号通过词嵌入,将一个维数为词字典数量的高维空间,嵌入到256维的低维连续空间,得到
(4)对多模态文档中每一个标签集:
(a)对于总分类数目n,设置一个n维向量,将对应文档的多个语义标签通过标签字典映射为0-1向量,得到
步骤2.1中所述的基于空间和特征注意力机制的稠密卷积神经网络进行图像特征的表示构建,具体在于:对于处理好的图像数据
其中
所述的denseblock模块由多层denselayer构成,每一层denselayer由两组批处理归一层,relu激活函数和一个卷积层构成,每层denselayer层会输出k个特征向量,而每层denselayer的输入的特征向量为k0+k*(i-1),k0表示初始输入特征数,其中i代表层数;所述的过渡transition模块相当于一个缓冲层,用于向下采样,由一个批处理归一层,relu激活函数,1*1的卷积层和2*2的平均池化层构成。步骤2.2中所述的基于文本注意力机制的双向长短期记忆网络,具体在于:
对于输入数据ti,利用bilstm提取文本序列的信息,获得的文本特征
所述的步骤2.2中所述bilstm模型,具体在于:
对于输入数据ti,利用bilstm提取文本序列的信息,获得的文本特征
it=σ(wiixt+bii+whih(t-1)+bhi),(3)
ft=σ(wifxt+bif+whfh(t-1)+bhf),(4)
gt=tanh(wigxt+big+whgh(t-1)(5)
+bhg),
ot=σ(wioxt+bio+whoh(t-1)+bho),(6)
ct=ft⊙c(t-1)+it⊙gt,(7)
ht=ot⊙tanh(ct),(8)
其中xt代表输入词的向量,ht代表t时刻的隐状态向量,ct代表t时刻的细胞状态向量,xi代表是t时刻的输入向量,h(t-1)代表上一层t-1时的隐状态向量或者是初始状态向量,wi,bi和bh均为可训练参数,it,ft,gt,ot分别代表输入,遗忘,细胞和输出门,σ表示sigmoid方程,tanh为激活函数,⊙为哈达玛积;可以得到与句子长度相同的隐状态向量集合[h0,h1,...,hl-1],l=484代表句子的长度。
所述的步骤2.2中所述文本注意力机制模块,具体在于:
对于由bilstm获得的文本特征
所述的步骤3中所述的基于注意力机制的分组跨模态融合模块,具体在于:
步骤3.1中,所述的图像特征和文本特征的分组融合如下:
对于从densenet-cbam中模型得到的图像特征
zi=x′twiy,(9)
其中
步骤3.2中,所述的对每一组融合后的特征zi,利用通道注意力机制,计算每个通道上特征图的权重,将加权后的特征记为zi′,其特征如下:
对于得到的融合后的特征{z0,z1,…,zr},利用通道注意力机制计算每个通道上特征图的权重,其中具体的计算过程如下:
其中σ表示为sigmoid函数,
步骤3.3中,所述将每一组取得具有权重的融合特征zi′通过一个全连接层;再将多组全连接层的输出向量,采用向量中对应元素相加的方式融合,然后通过sigmoid分类器,计算得到多模态文档在在每个标签上的概率分布
pi=zi′at+b,(13)
其中at,b为可训练参数。
有益效果
本发明提出的一种基于跨模态注意力卷积神经网络的课程领域多模态文档分类方法,对课程领域的多模态文档数据预处理;将注意力机制和稠密卷积网络相结合,提出了基于跨模态注意力的卷积神经网络,能更为有效的构建到具有稀疏性的图像特征;提出了面向文本特征构建的基于注意力机制的双向长短期记忆网络,可以高效构建与图像语义局部关联的文本特征;设计基于注意力机制的跨模态分组融合,能够更为准确地学习到文档中图像和文本局部关联关系,提高跨模态特征融合的准确率。在相同课程领域的数据集下,相比现有的多模态文档分类模型,该方法具有更好的性能,提高了多模态文档数据分类的准确率。
附图说明
图1为本发明实例中所述方法的模型图。
图2为本发明实例中所述方法的输入数据构建图。
图3为本发明实例中所述的图像特征提取的模型图。
图4为本发明实例中所述的文本特征提取的模型图。
图5为本发明实例中所述的分组跨模态融合的模型图。
图6a为对比不同模型在相同数据集下图像多标签分类的准确率比较图。
图6b为对比不同模型在相同数据集下图像多标签分类的损失比较图。
图6c为对比不同模型在相同数据集下图像多标签分类top-3比较图。
图6d为对比不同模型在相同数据集下图像多标签分类top-5比较图。
图7为本发明实例中所采用的数据集样本图。
具体实施方式
现结合实施例、附图对本发明作进一步描述:
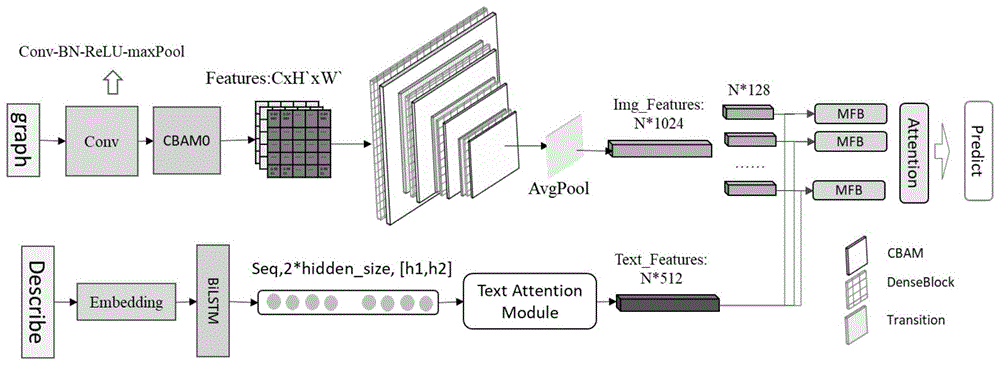
本发明拟提出的基于跨模态注意力卷积神经网络的课程领域多模态文档分类方法,主要分为五个模块:1)多模态文档数据的预处理。2)基于注意力机制的稠密卷积神经网络图像特征构建。3)基于注意力机制的双向长短期记忆网络文本特征构建。4)基于注意力机制的分组跨模态融合。5)多模态文档的多标签分类。整个方法的模型图如图1所示,具体如下所述:
1.多模态文档数据的预处理
将图文混合多模态文档表示成
基于跨模态注意力卷积神经网络的课程领域多模态文档分类方法的多模态文档数据的预处理的模型如图2,通过随机裁剪翻转图片,基于整体数据集文本描述的长度,将所有的文本长度截断和补齐成一样的长度l,并用词向量模型学习文本中词的向量表示,最后得到输入到网络中的各个参数
对于第i个预处理好的多模态文档,最终得到(ri,ti,li):
(1)从课程领域的图文混合多模态文档数据中随机取样。
(2)对多模态文档中的每一个图像:
将图像进行缩放保持长宽比不变,最短边为256;再将图片随机裁剪为长宽224*224;并将图像进行随机水平翻转;最后进行通道值归一化得到
(3)对多模态文档中每一个文本描述:
(a)统计所有文本描述的长度,选取长度l,l=484,其中92%文本长度小于长度l:
(b)将所有的数据进行截断和补齐成一样的长度l;
(c)使用词向量(wordvector),也被称为词嵌入(wordembedding),将字词序号映射到实数域上的向量,并对其权重进行训练;
(d)字词序号通过词嵌入,将一个维数为词字典数量的高维空间,嵌入到256维的低维连续空间,得到
(4)对多模态文档中每一个标签集:
对于总分类数目n,设置一个n维向量,将对应文档的多个语义标签通过标签字典映射为0-1向量,得到
2.基于注意力机制的深度跨模态特征构建
基于注意力机制的深度跨模态特征提取包括两个部分:1)基于注意力机制的稠密卷积神经网络图像特征构建,2)基于注意力机制的双向长短期记忆网络文本特征构建。将注意力机制和稠密卷积网络相结合,对图像进行特征提取;提出面向文本特征构建的基于注意力机制的双向长短期记忆网络;由此获得具有权重的图像特征
2.1基于注意力机制的稠密卷积神经网络
对于处理好的图像数据
对于多模态文档输入的图像特征
表1:densenet-cbam模型结构表
其中k代表growthrate,_layer代表denseblock中的层数,也就是denselayer的层数。每层denselayer的输出记为hi,每个hi都会产生k个特征向量,对于第i层denselayer的输入为xi,i∈_layer:
xi=hi([x0,x1,…xi-1]),(1)
由此每层denselayer的输入的特征向量可表示为k0+k*(i-1),k0表示初始输入特征数。对于transition模块,相当于一个缓冲层,用于向下采样,由一个批处理归一层,relu激活函数,1*1的卷积层和2*2的平均池化层构成。
对于每层denseblock和transition之间添加一层cbam模块,通过cbam模块计算特征图的权重,利用cbam中的通道子模块可以计算得到特征图的权重,利用cbam中的空间子模块,可以得到特征图中每个部位的权重。
cbam模块,由通道子模块和空间子模块构成,由此将注意力权重图和输入的特征图相乘,进行自适应特征细化。对于一个中间特征图
对于给定的特征图
σ表示为sigmoid函数,
σ表示为sigmoid函数,f7×7代表卷积核的大小为7x7,
2.2基于注意力机制的双向长短期记忆网络
对于输入数据ti,利用bilstm提取文本序列的信息,获得的文本特征
其中bilstm(bi-directionallongshort-termmemory),是由前向lstm与后向lstm组合而成。lstm对于输入序列中的每个元素,每一层计算如下函数:
it=σ(wiixt+bii+whih(t-1)+bhi),(6)
ft=σ(wifxt+bif+whfh(t-1)+bhf),(7)
gt=tanh(wigxt+big+whgh(t-1)(8)
+bhg),
ot=σ(wioxt+bio+whoh(t-1)+bho),(9)
ct=ft⊙c(t-1)+it⊙gt,(10)
ht=ot⊙tanh(ct),(11)
其中xt代表输入词的向量,ht代表t时刻的隐状态向量,ct代表t时刻的细胞状态向量,xi代表是t时刻的输入向量,h(t-1)代表上一层t-1时的隐状态向量或者是初始状态向量,wi,bi和bh均为可训练参数,it,ft,gt,ot分别代表输入,遗忘,细胞和输出门,σ表示sigmoid方程,tanh为激活函数,⊙为哈达玛积。可以得到与句子长度相同的隐状态向量集合[h0,h1,...,hl-1],l=484代表句子的长度。
由bilstm获得的文本特征
通过卷积操作将output转换为
u=wwoutput+bw,(12)
对于通过卷积操作获得的
通过softmax函数计算得到文本特征的权重αi,加权后的文本特征记为
y=∑lαi*outputi,(14)
3.基于注意力机制的分组跨模态融合
对于从基于注意力机制的深度跨模态特征构建中获得的图像特征
3.1图像特征和文本特征的分组融合
对于从densenet-cbam中训练得到的图像特征
zi=x′twiy,(15)
其中
3.2注意力机制
对与每一组融合后的特征zi,利用通道注意力机制,计算每个通道上特征图的权重mc(zi),其中具体的计算过程如下:
其中σ表示为sigmoid函数,
最后将每一组取得具有权重的融合特征zi′分别通过一个全连接层,对于多组全连接层的输出向量,采用对应元素相加的方式融合,然后通过sigmoid分类器,计算得到多模态文档在每个标签上的概率分布
pi=zi′at+b,(19)
其中at,b为可训练参数。
4.课程领域多模态文档数据多标签分类实验
我们使用的数据集为课程领域的图文混合多模态文档数据,每个多模态文档数据由一张图像,一段文本描述和多个语义标签构成。数据集中可供训练的多模态文档数据有871条,标签数目为41类。标签包括如表2所示:
表2:数据集中的标签集
其中课程领域多模态文档数据集中80%用于训练,20%用于测试。我们对比了不同其他预训练模型如vgg16,resnet34,densenet121,bilstm在相同数据集下的分类效果。整个模型的搭建使用pytorch深度学习框架,运行在gpu上,cuda版本为10.1.120。
4.1损失函数
我们采用一个基于最大熵的标准来优化一个多标签对所有损失,对于最后的分类结果x以及目标结果y。对于每次批量数据:
其中y[i]∈0,1,c代表总标签数目。
4.2评价与结果
表3:模型准确率对比表,展示了在相同数据集下不同模型所生成标签的精度和召回率被用作评价指标。对于每个多模态文档数据,采用top-3和top-5作为评价标准之一,top-k的含义为:如果top-k个概率最高的标签包含所有的真实标签,即认为预测正确。并计算了汉明损失(hammingloss),hammingloss表示所有标签中错误样本的比例,该值越小则网络的分类能力越强。实验中,主要使用map作为主要的评价标准,map的本质平均ap(averageprecision)值,ap值即为平均精确度。
表3:模型准确率对比表
- 还没有人留言评论。精彩留言会获得点赞!