基于对抗神经网络的单个图像生成多个图像的方法及系统与流程
本发明涉及图像处理领域,具体涉及基于对抗神经网络扩增图像的方法和系统。
背景技术:
现有对图像扩增的方法包括:基于传统图像处理的图像扩增、基于应用软件对图像进行处理扩增和基于现有对抗神经网络的图像扩增,主要存在以下问题:
1、基于图像处理的图像扩增是目前主流的图像扩增方式,包括翻转、旋转、缩放、随机裁剪或补零、色彩抖动、加噪声等,虽图像扩增的方式具有多样性,但扩增的图像为具有整体不变性,无法改变图像的本身轮廓特征。
2、通过软件对图像进行处理扩增是目前较为稳定的一种图像扩增的方式。以软件photoshop为例,其可以根据图像形态特征进行相应的变换,达到图像扩增的效果,但在实际应用中,具有以下两点不足,一个是人工成本和时间成本太高;变换的形态时根据软件使用者思想的变化而改变,可信度不高。
3、基于现有对抗神经网络的图像扩增是目前新兴的图像扩增方式,但其在训练生成器与判别器的过程中需要大量的原始图像。
技术实现要素:
本发明的目的是为了克服现有对图像扩增的方法及系统无法改变图像的本身轮廓特征、人工和时间成本高以及需要大量原始图像的问题,提供了一种基于对抗神经网络的单个图像生成多个图像的方法及系统。
本发明的基于对抗神经网络的单个图像生成多个图像的方法,对抗神经网络包括前置生成器、前置判别器、生成器g0~gt-1和判别器d0~dt-1,方法具体如下:
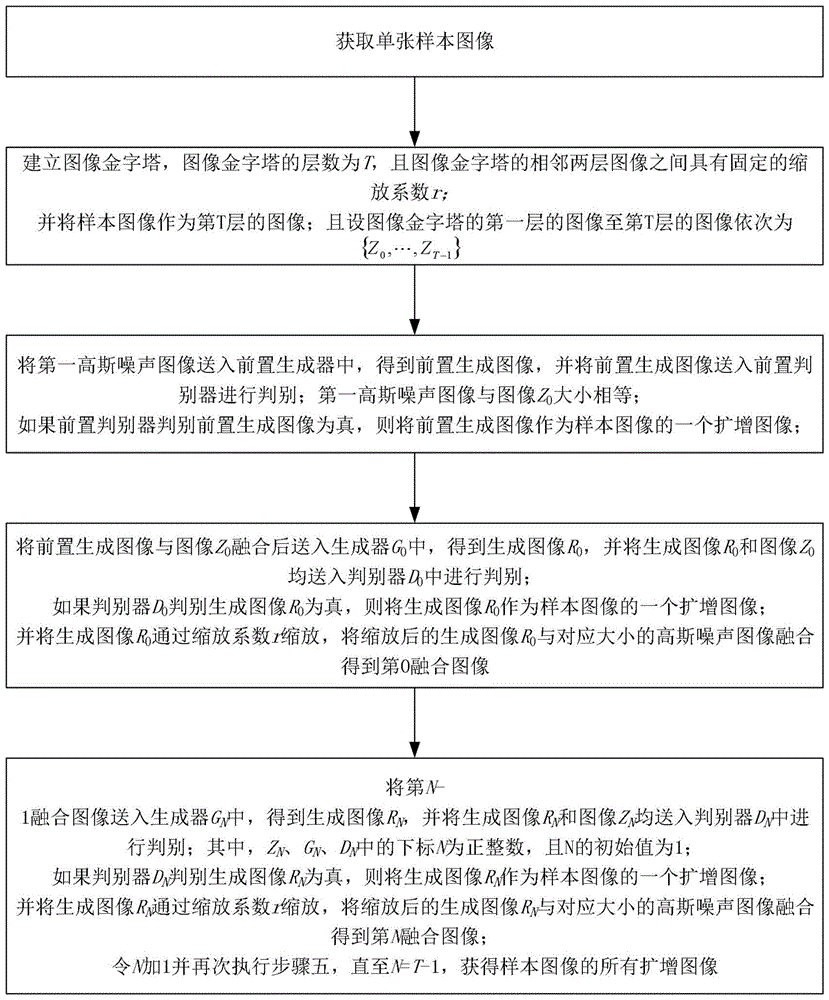
步骤一、获取单张样本图像;
步骤二、建立图像金字塔,图像金字塔的层数为t,且图像金字塔的相邻两层图像之间具有固定的缩放系数r;
并将样本图像作为第t层的图像;且设图像金字塔的第一层的图像至第t层的图像依次为{z0,…,zt-1};
步骤三、将第一高斯噪声图像送入前置生成器中,得到前置生成图像,并将前置生成图像送入前置判别器进行判别;第一高斯噪声图像与图像z0大小相等;
如果前置判别器判别前置生成图像为真,则将前置生成图像作为样本图像的一个扩增图像;
步骤四、将前置生成图像与图像z0融合后送入生成器g0中,得到生成图像r0,并将生成图像r0和图像z0均送入判别器d0中进行判别;
如果判别器d0判别生成图像r0为真,则将生成图像r0作为样本图像的一个扩增图像;
并将生成图像r0通过缩放系数r缩放,将缩放后的生成图像r0与对应大小的高斯噪声图像融合得到第0融合图像;
步骤五、将第n-1融合图像送入生成器gn中,得到生成图像rn,并将生成图像rn和图像zn均送入判别器dn中进行判别;其中,zn、gn、dn中的下标n为正整数,且n的初始值为1;
如果判别器dn判别生成图像rn为真,则将生成图像rn作为样本图像的一个扩增图像;
并将生成图像rn通过缩放系数r缩放,将缩放后的生成图像rn与对应大小的高斯噪声图像融合得到第n融合图像;
令n加1并再次执行步骤五,直至n=t-1,获得样本图像的所有扩增图像。
进一步地,步骤一中,设样本图像的大小为m×n×3,m≤n;
步骤二中,图像金字塔的第一层的图像大小为
且图像金字塔的层数t通过下式得到:
进一步地,步骤三中,前置生成器包括3个顺序连接的全卷积网络;
全卷积网络包括顺序连接的卷积核为3x3的卷积模块、批归一化batchnorm模块与泄露修正线性单元lr激活函数模块;
前置判别器的结构为卷积神经网络cnn分类器结构。
进一步地,步骤四和步骤五中,生成器g0~gt-1与判别器d0~dt-1均包括5个顺序连接的全卷积网络;
且每个判别器的输出矩阵的均值都作为对应判别器的二分类输出。
进一步地,步骤一中获取单张带有真实故障的样本图像的具体步骤如下:
步骤一一、对运动的待测物体进行逐行扫描,获取多个高清线阵图像,再将多个高清线阵图像拼接成完整的待测物体图像;
步骤二二、根据待测物体的参数,对待测物体的待检测部位进行截取得到子图,并在截取的子图中选取需要扩增且带有真实故障的图像作为样本图像。
本发明的基于对抗神经网络的单个图像生成多个图像的系统,对抗神经网络包括前置生成器、前置判别器、生成器g0~gt-1和判别器d0~dt-1,系统包括:
样本图像获取模块,用于获取单张样本图像;
图像金字塔模块,与样本图像获取模块连接,用于建立图像金字塔,图像金字塔的层数为t,且图像金字塔的相邻两层图像之间具有固定的缩放系数r;
并将样本图像作为第t层的图像;且设图像金字塔的第一层的图像至第t层的图像依次为{z0,…,zt-1};
前置生成判别模块,与图像金字塔模块连接,用于将第一高斯噪声图像送入前置生成器中,得到前置生成图像,并将前置生成图像送入前置判别器进行判别;第一高斯噪声图像与图像z0大小相等;
如果前置判别器判别前置生成图像为真,则将前置生成图像作为样本图像的一个扩增图像;
第一生成判别模块,与前置生成判别模块连接,用于将前置生成图像与图像z0融合后送入生成器g0中,得到生成图像r0并发送至第二生成判别模块,并将生成图像r0和图像z0均送入判别器d0中进行判别;
如果判别器d0判别生成图像r0为真,则将生成图像r0作为样本图像的一个扩增图像;
并将生成图像r0通过缩放系数r缩放,将缩放后的生成图像r0与对应大小的高斯噪声图像融合得到第0融合图像;
第二生成判别模块,与第一生成判别模块连接,用于接收第n-1融合图像及n,将第n-1融合图像送入生成器gn中,得到生成图像rn,并将生成图像rn和图像zn均送入判别器dn中进行判别;其中,zn、gn、dn中的下标n为正整数;
如果判别器dn判别生成图像rn为真,则将生成图像rn作为样本图像的一个扩增图像;
并将生成图像rn通过缩放系数r缩放,将缩放后的生成图像rn与对应大小的高斯噪声图像融合得到第n融合图像;
调用模块,同时与第一生成判别模块、第二生成判别模块连接,判别器d0完成判别后,令n等于1,并发送至第二生成判别模块,判别器dn每完成一次判别,令n加1并发送至第二生成判别模块,直至n=t-1,获得样本图像的所有扩增图像。
进一步地,样本图像获取模块中获取的样本图像的大小为m×n×3,m≤n;
图像金字塔模块中图像金字塔的第一层的图像大小为
且图像金字塔的层数t通过下式得到:
其中,r为缩放系数。
进一步地,前置生成判别模块包括前置生成器g和前置判别器d;
前置生成器g包括3个顺序连接的全卷积网络;
全卷积网络包括顺序连接的卷积核为3x3的卷积模块、批归一化batchnorm模块与泄露修正线性单元lr激活函数模块;
前置判别器d的结构为卷积神经网络cnn分类器结构。
进一步地,第一生成判别模块包括生成器g0和判别器d0,第二生成判别模块包括生成器g1~gt-1和判别器d1~dt-1;
生成器g0~gt-1与判别器d0~dt-1均包括5个顺序连接的全卷积网络;
且每个判别器的输出矩阵的均值都作为对应判别器的二分类输出。
进一步地,样本图像获取模块包括:
图像扫描拼接模块,用于对运动的待测物体进行逐行扫描,获取多个高清线阵图像,再将多个高清线阵图像拼接成完整的待测物体图像;
子图截取选择模块,与图像扫描拼接模块连接,用于根据待测物体的参数,对待测物体的待检测部位进行截取得到子图,并在截取的子图中选取需要扩增且带有真实故障的图像作为样本图像。
本发明的有益效果是:
采用图像金字塔的方式,对图像进行逐层对抗训练。使得小尺寸图像生成主体轮廓,大尺寸图像生成主体细节,保证生成图像具有原图像大部分主体信息的同时,保留部分细节信息。并且
与基于现有图像处理的图像扩增相比,本方法及系统扩增后的图像具有一定的形态特征变化。
与基于应用软件对图像进行处理扩增相比,本方法及系统可以节省大量人工成本和时间成本的同时具有较高的可信度。
与基于现有对抗神经网络的图像扩增方式相比,本方法及系统仅需单张样本图像即可。
附图说明
图1为具体实施方式一的基于对抗神经网络的单个图像生成多个图像的方法的流程图;
图2为本发明的基于对抗神经网络的单个图像生成多个图像的方法及系统的原理图;
图3为本发明的基于对抗神经网络的单个图像生成多个图像的方法及系统中图像金字塔的结构示意图;
图4为本发明的基于对抗神经网络的单个图像生成多个图像的方法及系统中样本图像示意图;
图5为本发明的基于对抗神经网络的单个图像生成多个图像的方法及系统中扩增图像示意图。
具体实施方式
需要特别说明的是,在不冲突的情况下,本申请公开的各个实现方式之间或实现方式包括的特征之间可以相互组合。
具体实施方式一,本实施方式的基于对抗神经网络的单个图像生成多个图像的方法,对抗神经网络包括前置生成器、前置判别器、生成器g0~gt-1和判别器d0~dt-1,如图1所示,方法具体如下:
步骤一、获取单张样本图像;
步骤二、建立图像金字塔,图像金字塔的层数为t,且图像金字塔的相邻两层图像之间具有固定的缩放系数r;
并将样本图像作为第t层的图像;且设图像金字塔的第一层的图像至第t层的图像依次为{z0,…,zt-1};
步骤三、将第一高斯噪声图像送入前置生成器中,得到前置生成图像,并将前置生成图像送入前置判别器进行判别;第一高斯噪声图像与图像z0大小相等;
如果前置判别器判别前置生成图像为真,则将前置生成图像作为样本图像的一个扩增图像;
步骤四、将前置生成图像与图像z0融合后送入生成器g0中,得到生成图像r0,并将生成图像r0和图像z0均送入判别器d0中进行判别;
如果判别器d0判别生成图像r0为真,则将生成图像r0作为样本图像的一个扩增图像;
并将生成图像r0通过缩放系数r缩放,将缩放后的生成图像r0与对应大小的高斯噪声图像融合得到第0融合图像;
步骤五、将第n-1融合图像送入生成器gn中,得到生成图像rn,并将生成图像rn和图像zn均送入判别器dn中进行判别;其中,zn、gn、dn中的下标n为正整数,且n的初始值为1;
如果判别器dn判别生成图像rn为真,则将生成图像rn作为样本图像的一个扩增图像;
并将生成图像rn通过缩放系数r缩放,将缩放后的生成图像rn与对应大小的高斯噪声图像融合得到第n融合图像;
令n加1并再次执行步骤五,直至n=t-1,获得样本图像的所有扩增图像。
具体地,为使本发明生成的扩增图像具有原始样本数据的细节特征,本发明模型采用通过小尺寸图像生成主体轮廓,大尺寸图像生成主体细节的思想来进行设计。
设图像金字塔从顶层(第一层)到底层(第t层)的图像依次为{z0,z1,...,zt-1},则本方法的网络模型原理具体步骤如下,如图2所示:
1、将大小为
2、将
3、将r0乘以固定的缩放系数r后与对应大小的高斯噪声图像x1,送入第二个生成器g1中,得到第二个生成图像r1,然后将z1和r1送入第二个马尔可夫判别器d1中进行判别;
4、将r1乘以固定的缩放系数r后与对应大小的高斯噪声图像x2,送入第三个生成器g2中,得到第三个生成图像r2,然后将z2和r2送入第三个马尔可夫判别器d2中进行判别;
5、以此类推,直至将rt-2乘以固定的缩放系数r后与对应大小的高斯噪声图像xt-1,送入第t个生成器gt-1中,得到生成图像rt-1,然后将zt-1和rt-1送入第t个马尔可夫判别器dt-1中进行判别。
进一步地,步骤一中,设样本图像的大小为m×n×3,m≤n;
步骤二中,图像金字塔的第一层的图像大小为
且图像金字塔的层数t通过下式得到:
具体地,动车外部的机械结构组成上具有较高的复杂度,部分零部件在动车行驶的过程中起到了至关重要的作用,为保证动车安全快速的形式,这些零部件的完好性变得尤为重要。由于真实故障具有未知性、异质性、稀有性和多样性,导致真实故障的数据样本较少,进而无法实现高精度的故障检测。因此,首先需要对动车真实故障图像进行生成。本方法中动车故障图像生成的方法是使用多个对抗神经网络模型训练不同尺度的单张真实故障图像,进而生成多张故障图像,本方法可以很好的解决动车真实故障图像稀少的问题。其基本思想是:将选取的取带有真实故障的图像送入本方法的模型进行训练,然后对选取的样本进行生成。基于对抗神经网络的单个铁路动车故障图像生成多个故障图像的方法具体如下:
建立图像金字塔,由于铁路动车故障样本是根据动车发生故障的位置或者零部件进行截取,因此截取的图像大小非定值,为实现样本生成的准确性,本方法不直接采用传统的缩放处理,而是根据图像大小通过缩放的方式建立图像金字塔。设图像大小为m×n×3(m≤n)(其中3为通道值),为确保金字塔顶层图像含有原始图像的主体轮廓信息,根据先验知识,手动将顶层图像大小设置为
其中,图像金字塔层数t根据下式计算得出,且在计算过程中图像金字塔中各层图像大小与层数t均为正整数。这样图像金字塔层数仅与图像的短边长有关。
进一步地,步骤三中,前置生成器包括3个顺序连接的全卷积网络;
全卷积网络包括顺序连接的卷积核为3x3的卷积模块、批归一化batchnorm模块与泄露修正线性单元lr激活函数模块;
前置判别器的结构为卷积神经网络cnn分类器结构。
进一步地,步骤四和步骤五中,生成器g0~gt-1与判别器d0~dt-1均包括5个顺序连接的全卷积网络;
且每个判别器的输出矩阵的均值都作为对应判别器的二分类输出。
具体地,图2中w表示图像融合,s表示图像乘以固定的缩放系数r,前置生成器g是带有3个格式为卷积核为(3x3)+批归一化(batchnorm)+泄露修正线性单元(lr,leakyrelu)激活函数的全卷积网络,选择全卷积网络是因为可以生成任意大小和宽高比的图像。
前置判别器d采用传统cnn分类器结构。后续的生成器gi(i=0,1,...,t-1)是带有5个格式为卷积核为(3x3)+batchnorm+leakyrelu的全卷积网络。后续的判别器di(i=0,1,...,t-1)是采用马尔可夫判别器,其结构与生成器gi相同。与传统cnn分类器结构的判别器不同,马尔可夫判别器输出的是一个矩阵,矩阵中的每一个输出,代表着原图中一个感受野,最后取输出矩阵的均值作为二分类的输出。与判别器d相比判别器di可以更好的判别样本细节特征。
进一步地,步骤一中获取单张带有真实故障的样本图像的具体步骤如下:
步骤一一、对运动的待测物体进行逐行扫描,获取多个高清线阵图像,再将多个高清线阵图像拼接成完整的待测物体图像;
步骤二二、根据待测物体的参数,对待测物体的待检测部位进行截取得到子图,并在截取的子图中选取需要扩增且带有真实故障的图像作为样本图像。
具体地,步骤一中获取单张带有真实故障的样本图像的具体步骤如下
步骤一一为图像获取:
在动车铁轨两侧以及底部配备高清线阵成像设备,列车通过触发传感器,启动图像采集设备,并对缓慢运动的动车进行逐行扫描,获取多个大小为1440*1440的高清线阵图像,而后根据动车的轴距信息和先验知识将其拼接成完整列车图像。
步骤一二为待扩增子图图像截取:
同样根据列车轴距、车型和先验知识对动车不同的模块或者零部件进行截取,并在截取的子图中人工选取带需要扩增且带有真实故障的图像。
模型测试
将单个铁路动车真实故障图像使用本方法的模型进行测试,带有真实故障的样本图像如图4所示,测试结果得到的扩增图像如图5所示。
从图5中可以看出生成的扩增图像与原样本图像主体信息具有较高的相似度,其细节信息特征具有一定的差异,可以有效地改善现有技术中的不足。因此,本方法可以很好的解决真实故障的数据样本较少,后续无法实现高精度的故障检测的问题和现有技术中的不足。
具体实施方式二,本实施方式的基于对抗神经网络的单个图像生成多个图像的系统,所述对抗神经网络包括前置生成器、前置判别器、生成器g0~gt-1和判别器d0~dt-1,系统包括:
样本图像获取模块1,用于获取单张样本图像;
图像金字塔模块2,与样本图像获取模块1连接,用于建立图像金字塔,图像金字塔的层数为t,且图像金字塔的相邻两层图像之间具有固定的缩放系数r;
并将样本图像作为第t层的图像;且设图像金字塔的第一层的图像至第t层的图像依次为{z0,…,zt-1};
前置生成判别模块3,与图像金字塔模块2连接,用于将第一高斯噪声图像送入前置生成器中,得到前置生成图像,并将前置生成图像送入前置判别器进行判别;第一高斯噪声图像与图像z0大小相等;
如果前置判别器判别前置生成图像为真,则将前置生成图像作为样本图像的一个扩增图像;
第一生成判别模块4,与前置生成判别模块3连接,用于将前置生成图像与图像z0融合后送入生成器g0中,得到生成图像r0并发送至第二生成判别模块5,并将生成图像r0和图像z0均送入判别器d0中进行判别;
如果判别器d0判别生成图像r0为真,则将生成图像r0作为样本图像的一个扩增图像;
并将生成图像r0通过缩放系数r缩放,将缩放后的生成图像r0与对应大小的高斯噪声图像融合得到第0融合图像;
第二生成判别模块5,与第一生成判别模块4连接,用于接收第n-1融合图像及n,将第n-1融合图像送入生成器gn中,得到生成图像rn,并将生成图像rn和图像zn均送入判别器dn中进行判别;其中,zn、gn、dn中的下标n为正整数;
如果判别器dn判别生成图像rn为真,则将生成图像rn作为样本图像的一个扩增图像;
并将生成图像rn通过缩放系数r缩放,将缩放后的生成图像rn与对应大小的高斯噪声图像融合得到第n融合图像;
调用模块6,同时与第一生成判别模块4、第二生成判别模块5连接,判别器d0完成判别后,令n等于1,并发送至第二生成判别模块5,判别器dn每完成一次判别,令n加1并发送至第二生成判别模块5,直至n=t-1,获得样本图像的所有扩增图像。
进一步地,样本图像获取模块中获取的样本图像的大小为m×n×3,m≤n;
图像金字塔模块2中图像金字塔的第一层的图像大小为
且图像金字塔的层数t通过下式得到:
进一步地,前置生成判别模块3包括前置生成器g和前置判别器d;
前置生成器g包括3个顺序连接的全卷积网络;
全卷积网络包括顺序连接的卷积核为3x3的卷积模块、批归一化batchnorm模块与泄露修正线性单元lr激活函数模块;
前置判别器d的结构为卷积神经网络cnn分类器结构。
进一步地,第一生成判别模块4包括生成器g0和判别器d0,第二生成判别模块5包括生成器g1~gt-1和判别器d1~dt-1;
生成器g0~gt-1与判别器d0~dt-1均包括5个顺序连接的全卷积网络;
且每个判别器的输出矩阵的均值都作为对应判别器的二分类输出。
进一步地,样本图像获取模块1包括:
图像扫描拼接模块1-1,用于对运动的待测物体进行逐行扫描,获取多个高清线阵图像,再将多个高清线阵图像拼接成完整的待测物体图像;
子图截取选择模块1-2,与图像扫描拼接模块1-1连接,用于根据待测物体的参数,对待测物体的待检测部位进行截取得到子图,并在截取的子图中选取需要扩增且带有真实故障的图像作为样本图像。
- 还没有人留言评论。精彩留言会获得点赞!