基于双谱特征对比学习的无监督通信辐射源个体识别方法
本发明涉及辐射源识别,特别是一种基于双谱特征对比学习的无监督通信辐射源个体识别方法。
背景技术:
1、通信辐射源个体识别(specific emitter identification,sei)通常指通过信号特征匹配,将截取到的通信信号与某一型号的电台个体相关联,从而实现侦察、识别等战术目的,其匹配的准确率关系到情报侦察的可靠性乃至整个电子战系统的作战效能(k.c.ho,w.prokopiw,and y.t.chan.“modulation identification of digital signals by thewavel-et transform”.in:iee proceedings-radar,sonar and navigation 147.4(2002),pp.169–176(cit.on p.1).)。对于实际战场环境言,我们常面临的是大量无标签信息的辐射源信号的分类问题,即无监督识别,其主要分为两个关键环节:特征提取和分类器设计。其中,如何从这些无标签信息的辐射源信号中提取出具有可区分性的数据特征影响着下游分类识别任务的性能。
2、传统的无监督通信辐射源个体识别常将人工特征与无监督算法结合起来,将接收到的辐射源信号进行预处理后,以人工方法提取信号的细微特征,如时频分析(yuan y,huang z,hao w,et al.specific emitter identification based on hilbert-huangtransform-b-ased time-frequency-energy distribution features(j).communications iet,2014,8(13):2404-2412.)、调制分析、高阶谱(zhang x d,shi y,bao z.a new feature vector using selected bispectra for signal classificationwith application in radar target recognition(j).ieee transactions on signalprocessing,2001,49(09):1875-1885.)、基于发射机器件非线性原理进行建模(a.c.polak,s.dolatshahi and d.l.goeckel,"identifying wireless users viatransmitter imperfections,"in ieee journal on selected areas incommunications,vol.29,no.7,pp.1469-1479,august 2011,doi:10.1109/jsac.2011.110812.)等,然后再采用聚类等无监督算法对这些特征进行分类,从而实现对辐射源的个体识别。然而,这些人工特征有明显的局限性,只能反映出辐射源信号的部分特征,而不具备很强的可区分性,往往识别效果不太理想。随着深度学习的不断研究,深度神经网络(deep neural network,dnn)强大的非线性拟合能力在图像识别、人脸检测中展现出优良的性能,在通信辐射源个体识别技术中更是初显锋芒。
3、在文献(中国船舶重工集团公司第七二四研究所.一种基于深度学习的辐射源信号多模型综合分类方法:cn202110751828.0(p).2021-09-07.)中,王佳铭等人利用深度卷积神经网络、长短时记忆网络构建综合网络模型,实现了对雷达辐射源信号的智能识别,具备很强的泛化能力;李立欣等人(西北工业大学,上海卫星工程研究所.基于混合神经网络的无线电信号调制识别网络及实现方法:cn202011368021.0(p).2021-03-26.)通过对卷积层提取的特征信息进行维度划分和循环门限控制,更充分利用信号在时间和空间的状态特征,提升了调制信号的分类性能;谢存祥等人(谢存祥,张立民,钟兆根.基于hilbert-huang变换与对抗训练的特定辐射源识别(j).系统工程与电子技术,2021,43(12):3478-3487.doi:10.12305/j.issn.1001-506x.2021.12.08.)在研究过程中建立起融合hilbert-huang变换与对抗训练的模型,这种模型在处理过程中将辐射源信号的关键时频点及其对应的能量值输入卷积神经网络进行训练,在训练样本较少时也能达到良好的识别结果;文献(s.wang,h.jiang,x.fang,y.ying,j.li and b.zhang,radio frequency fingerprintidentification based on deep complex residual network,in ieee access,vol.8,pp.204417-204424,2020.)采用深度复数残差网络结合了特征提取和分类两个过程,建立了一种适用于辐射源识别的端到端模型,提高了识别准确率;文献(l.ying,j.li andb.zhang,"differential complex-valued convolutional neural network-basedindividual recognition of communication radiation sources,"in ieee access,vol.9,pp.132533-132540,2021.)利用差分复值卷积神经网络捕捉20个同类型通信辐射源基带i/q信号的非线性特征,识别率达到99.7%;文献(曲凌志,杨俊安,刘辉,黄科举.嵌入注意力机制的通信辐射源个体识别方法(j).系统工程与电子技术,2022,44(01):20-27.qulz,yang j a,liu h,huang k j.individual identification method of communicationradiation source with embedded attention mechanism(j).systems engineering andelectronic technology,2022,44(01):20-27.(in chinese))提出了一种在残差网络中嵌入双层注意力机制的通信辐射源识别方法,提高了识别准确率并且稳定性较好;文献(yanghaifen,zhang hao,wang houjun,et al.a novel approach for unlabeled samples inradiation source identification(j).系统工程与电子技术(英文版),2022,33(2):354-359.doi:10.23919/jsee.2022.000037.)首先在标记样本上训练网络,然后利用半监督学习来检测未标记的样本并自动标记新样本,实现了对未知辐射源个体的动态识别。
4、现有的基于深度学习的通信辐射源识别方法通常是在有标签数据集上进行的监督学习,但在实际非合作通信中,由于截取到的辐射源数据往往是没有先验信息的,因此限制了有监督学习的算法性能。在无监督学习算法中,聚类算法可以在没有任何标签的情况下将特征向量分组到不同的聚类簇中,如稀疏嵌入式k均值聚类、具有矩阵诱导正则化的多核k均值聚类等,但由于该方法要基于人工特征,大多数算法在复杂数据集上会产生较差的结果。为了解决特征表示不足的问题,深度聚类利用神经网络从图像中提取代表性信息,以获取更加具有区分性的特征表示,促进下游聚类任务(caron m,bojanowski p,joulin a,et al.deep clustering for unsupervised learning of visual features(c)//proceedings of the european conference on computer vision(eccv).2018:132-149.)。但这些算法往往是迭代地对特征进行分组,并使用后续分配来更新深度网络。在特征表示学习和聚类交替的过程中,往往会导致误差积累,从而影响聚类性能。
5、综上所述,深度神经网络在有标签数据集的分类识别问题上表现出色,而在无标签数据上往往难以取得令人满意的结果。
技术实现思路
1、本发明的目的在于针对无标签信息的通信辐射源数据特征难以提取,分类精度不高等问题,引用对比学习理论,提出一种基于双谱特征对比学习的无监督通信辐射源个体识别方法。
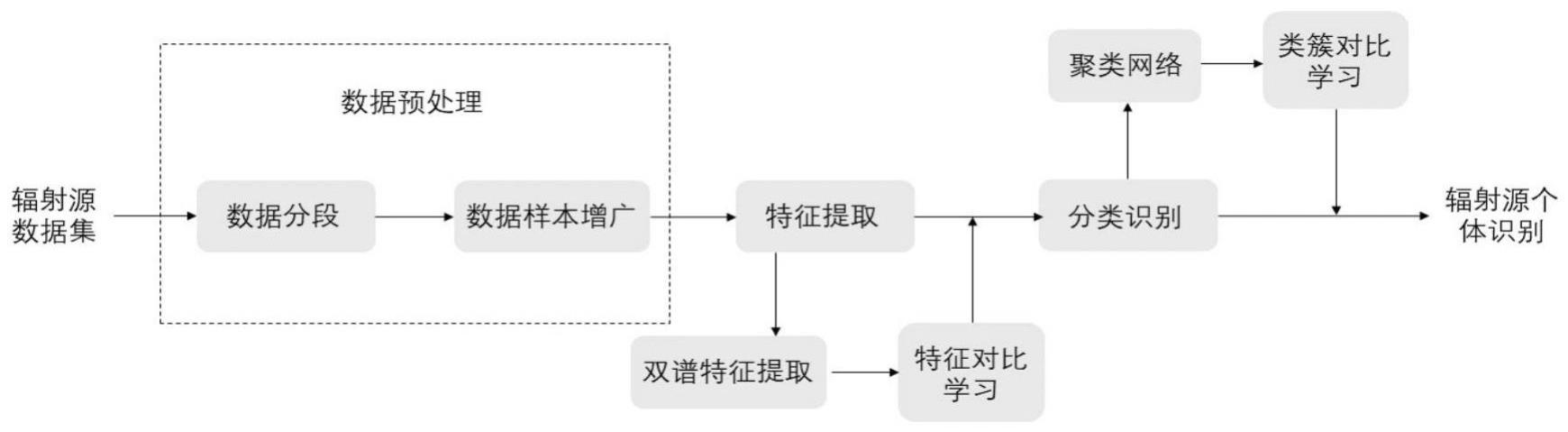
2、实现本发明目的的技术解决方案为:一种基于双谱特征对比学习的无监督通信辐射源个体识别方法,包括以下步骤:
3、步骤1、构建网络模型,输入数据集χ,设置训练次数e,批次数据量n,超参数τi、τc,类别数m;
4、步骤2、数据预处理:将时域信号数据进行归一化,并截取数据样本;
5、步骤3、数据增广:对每个信号样本随机进行随机裁剪、随机加噪声和翻转变换,以设定的概率独立地应用每个数据增广方法,生成正样本;
6、步骤4、双谱特征提取:对数据增广后的每个样本求取双谱特征,将一维的时域信号变成二维特征矩阵;
7、步骤5、从数据集χ中选取一个批次数据随机选取两种数据增广方式ta,tb,计算样本对对比损失lins;
8、步骤6、计算聚类对比损失lclu,并计算整体损失值l,通过最小化l来更新网络f,gi,gc的参数;
9、步骤7、对于数据集中的每个样本x,通过h=f(x)提取特征,通过c=argmaxgc(h)计算每个样本的聚类分配;
10、步骤8、输出各聚类簇的one-hot编码,完成无监督通信辐射源个体识别。
11、进一步地,利用原始信号样本x与其正例之间的相似性、负例之间的差异性进行对比学习,提取更加具有区分度的特征表示ha,hb用于下游的分类识别任务;
12、根据ha,hb是由同一数据样本经两种增广方式得到的特征表示,在聚类时应属同一类,设计聚类损失函数,在簇类层面进行对比学习,完成分类识别任务;
13、定义正样本对为同一信号样本的两个增广样本,将其他样本对定义为负样本对。
14、进一步地,步骤1中的网络模型,具体如下:
15、将一维时间序列变成二维特征矩阵输入对比学习模块进行训练,选取残差网络作为对比学习的主干网络;
16、残差网络由残差块构建而成,其中的残差块又由多个级联的卷积层和一个短接组成,通过累加两者的输出值,再利用relu函数进行激活得到输出结果,通过串联残差块形成更深层的网络;通过实验对网络参数进行优化,确定网络模型进行特征对比学习:
17、在对模型进行训练时,将5部超短波电台的双谱特征图作为网络的输入,各电台取1500个数据样本,每个样本经数据增广处理后计算双谱特征;每个样本包含4096个数据点,特征矩阵维度设置为128×128;从中随机选取60%的数据作为训练集,20%作为验证集,20%作为测试集;
18、分别选取resnet-18和resnet-34作为主干网络,网络优化方法为adam方法,初始学习率设置为0.001,训练次数e设置为400次,批次数据量n设置为32,得到不同网络深度对应的识别结果,最终选取resnet-34作为对比特征提取的骨干网络。
19、进一步地,步骤5中,计算样本对对比损失lins,具体如下:
20、对于给定的一个信号样本xi,以设定的概率随机选取两种数据增广方式ta,tb构建样本对,得到两个相关样本表示为经同一样本增广而得的两个相关样本记为正样本对;
21、把一对样本输入到一个共享参数的深度神经网络f(·)进行对比训练提取特征,得到新的特征表征表示为
22、堆叠一个两层的非线性全连接层gi(·),通过将特征矩阵映射到应用对比损失的子空间,在和上进行对比损失的计算;
23、成对相似性通过余弦距离来衡量,即
24、
25、其中,k1,k2∈{a,b},i,j∈[1,n];
26、截取n段辐射源信号样本,对每个样本xi执行两种增广方式,得到2n个信号样本对于特定的某个样本有2n-1个样本对,将与其相关的增广样本记为正样本,得到正样本对剩下的2n-2对均记为负样本对;
27、在整个辐射源数据集合中,为了优化成对相似性,定义具体样本的对比损失形式如下:
28、
29、其中,τi是一个超参数,为了识别整个数据集中的所有正对,对每个增广样本计算样本对对比比损失,即:
30、
31、进一步地,步骤6中,计算聚类对比损失lclu,具体如下:
32、将得到的新特征表征输入到聚类网络gc(·)中,将聚为同一类;
33、设置网络输出矩阵y的维度满足ya∈rn×m,其中n是每批训练的样本数量,m是聚类簇的数量,ya,yb分别每批样本两次数据增广下的输出;由于每个样本只属于一个簇,y的行应该类似于one-hot分布;
34、当将数据样本投影到维度等于簇数的空间中时,特征的第i个元素被认为是属于第i个聚类簇的概率,y的第i列看作是第i个簇的表示,并且所有列应该彼此不同;
35、用另外一个两层的全连接层gc(·)将特征映射到一个m维的子空间,表示为其中是矩阵ya的第i行,是样本xi经过a增广方式后通过聚类网络的输出;
36、记矩阵ya的第i列为即数据样本第一次增广后的第i个聚类簇的表示,同样地,将与组合形成正簇对将另外2m-2个簇类对视为负簇对;
37、使用余弦距离来度量簇对之间的相似性,即:
38、
39、其中,k1,k2∈{a,b},i,j∈[1,m];
40、采用以下损失函数将簇与除之外的所有其他簇区分开来:
41、
42、其中,τc为聚类网络的超参数;
43、通过遍历所有簇,同时为了避免将大多数样本分配给同一类,聚类对比损失lclu定义如下:
44、
45、其中,是聚类簇分配概率的熵。
46、进一步地,步骤6中,计算整体损失值l,具体如下:
47、通过同时优化特征对比、聚类对比损失函数,作为整个无监督通信辐射源分类识别网络的优化,即:
48、l=lins+lclu
49、本发明与现有技术相比,其显著优点为:(1)首先利用两个参数共享的残差网络作为主干网络进行特征对比学习,然后将增广样本的矩形积分双谱特征输入对比学习模块,进一步学习更加具有区分力的特征表示,从而增强不同辐射源样本之间的特征可分离性;(2)利用提取到的新特征表示在聚类簇层面进行对比学习,完成分类识别任务,通过在实测超短波通信电台数据集上进行实验,该方法相比于其他无监督学习算法识别效果更好,能够达到77.8%的识别准确率。
- 还没有人留言评论。精彩留言会获得点赞!