工业领域的多文档阅读理解方法、装置、设备及存储介质与流程
本技术涉及人工智能,特别是涉及一种工业领域的多文档阅读理解方法、装置、设备及存储介质。
背景技术:
1、阅读和理解非结构化文本,然后回答有关问题的能力是人类的一项普通技能。但对于机器来说并不容易,教机器阅读人类自然语言一直是自然语言处理的长期目标。经过多年的努力,自然语言处理领域的研究人员使用了越来越强大的自然语言处理工具来分析和理解人类文本的不同方面。阅读理解可以被视为问答任务,这也是自然语言处理(nlp)的一种应用,其中模型应该回答用户提出的问题。机器通过任意使用一些复杂、非结构化、半结构化的知识库来回答问题,并将正确答案返回给用户。阅读理解(mrc:machine readingcomprehension)是自然语言处理领域一个重要的研究方向。多文档阅读理解旨在使用给定的多个文档回答相应的问题。阅读理解任务可视为人工智能的核心能力被广泛应用于搜索引擎和对话引擎中。
2、然而,目前阅读理解面临诸多挑战,例如,每篇文档的字数包含较多的单词,且各文档中存在较多的干扰,例如,存在跨度很高的词汇与答案相匹配,但是整个句子与答案却毫无关系。并且,在多各文档阅读理解中,每个问题的答案位置非常灵活,可能在它可能在一个文档中出现一次或多次,也可能在多个文档中出现多次。而在工业领域的阅读理解,其文档中会出现大量的词表外词汇,从而导致对文档的语义理解较为表面,为了解决这些问题从而得到精准的问题答案,对模型提出更高的要求。
技术实现思路
1、基于此,有必要针对上述技术问题,提供一种能够在多个文档中精准得到问题答案的基于深度交互融合的多文档阅读理解方法、装置及设备。
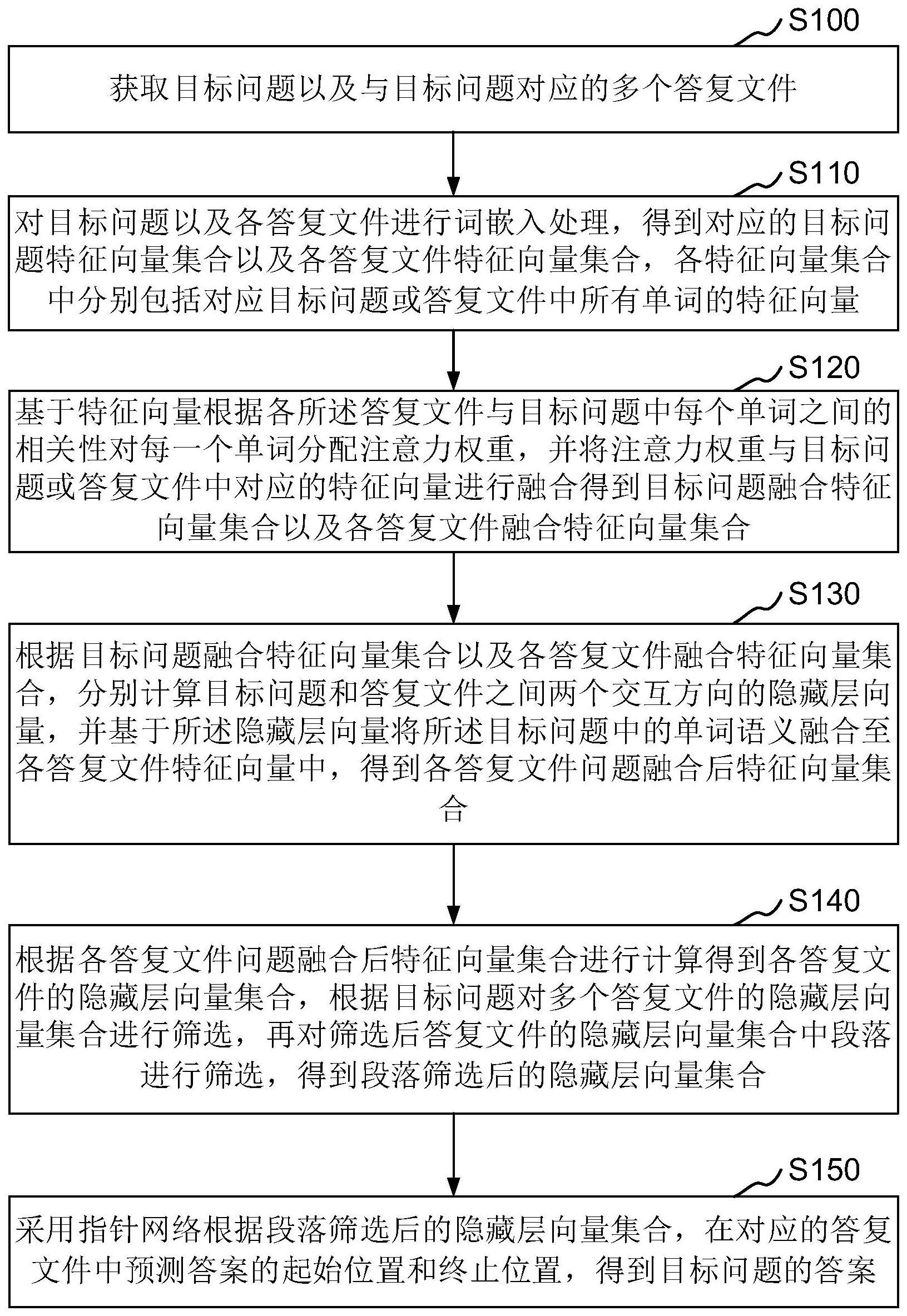
2、一种工业领域的多文档阅读理解方法,所述方法包括:
3、获取目标问题以及与所述目标问题对应的多个答复文件;
4、对所述目标问题以及各所述答复文件进行词嵌入处理,得到对应的目标问题特征向量集合以及各答复文件特征向量集合,各特征向量集合中分别包括对应目标问题或答复文件中所有单词的特征向量;
5、基于特征向量根据各所述答复文件与目标问题中每个单词之间的相关性对每一个单词分配注意力权重,并将注意力权重与目标问题或答复文件中对应的特征向量进行融合得到目标问题融合特征向量集合以及各答复文件融合特征向量集合;
6、根据所述目标问题融合特征向量集合以及各答复文件融合特征向量集合,分别计算目标问题和答复文件之间两个交互方向的隐藏层向量,并基于所述隐藏层向量将所述目标问题中的单词语义融合至各答复文件特征向量中,得到各答复文件问题融合后特征向量集合;
7、根据各所述答复文件问题融合后特征向量集合进行计算得到各所述答复文件的隐藏层向量集合,根据目标问题对多个答复文件的隐藏层向量集合进行筛选,再对筛选后答复文件的隐藏层向量集合中段落进行筛选,得到段落筛选后的隐藏层向量集合;
8、采用指针网络根据段落筛选后的隐藏层向量集合,在对应的答复文件中预测答案的起始位置和终止位置,得到所述目标问题的答案。
9、在其中一实施例中,所述基于特征向量根据各所述答复文件与目标问题中每个单词之间的相关性对每一个单词分配注意力权重,并将注意力权重与目标问题或答复文件中对应的特征向量进行融合得到目标问题融合特征向量集合以及各答复文件融合特征向量集合包括:
10、基于特征向量,根据各所述答复文件中每一个单词与目标问题中每一个单词之间的相关性,构建交叉注意力矩阵;
11、基于所述交叉注意力矩阵以及softmax函数为所述目标问题以及各答复文件中每个单词分配注意力权重;
12、基于各单词的注意力权重分别对目标问题特征向量集合以及各答复文件特征向量集合中各单词的特征向量进行重新表示;
13、采用双向循环神经网络对重新表示后的目标问题特征向量以及各答复文件特征向量进行上下文语义融合,得到所述目标问题融合特征向量集合以及各答复文件融合特征向量集合。
14、在其中一实施例中,通过双向注意力机制根据所述目标问题融合特征向量集合以及各答复文件融合特征向量集合,分别计算目标问题到各答复文件,以及各答复文件到目标问题两个方向的隐藏层向量;
15、基于双向循环神经网络将两个方向的隐藏层向量进行融合后,得到对应各答复文件的答复文件问题融合后特征向量集合。
16、在其中一实施例中,所述根据各所述答复文件问题融合后特征向量集合进行计算得到各所述答复文件的隐藏层向量集合包括:
17、根据各所述答复文件问题融合后特征向量集合采用softmax函数进行计算,得到各答复文件之间的自注意力权重;
18、基于双向循环神经网络,根据各答复文件之间的自注意力权重以及计算对应各所述答复文件的隐藏层向量。
19、在其中一实施例中,采用逻辑回归模型,并基于多任务方式对多个答复文件的隐藏层向量集合进行答复文件以及段落的筛选,得到所述段落筛选后的隐藏层向量集合。
20、在其中一实施例中,在对多个答复文件的隐藏层向量集合,以及对筛选后答复文件的隐藏层向量集合中段落进行筛选时包括:
21、各所述答复文件的隐藏向量集合中包括对应各段落的隐藏向量;
22、通过映射向量,将目标问题特征向量集合以及答复文件的隐藏向量或某段落的隐藏向量映射至同一空间中,分别对各答复文件以及各段落进行打分得到相应的分数;
23、根据预设的答复文件筛选阈值以及段落筛选阈值分别对各答复文件以及段落进行筛选,得到段落筛选后的隐藏层向量集合。
24、在其中一实施例中,所述采用指针网络根据段落筛选后的隐藏层向量集合,在对应的答复文件中预测答案的起始位置和终止位置,得到所述目标问题的答案包括:
25、通过指针网络根据段落筛选后的隐藏层向量集合,在对应答复文件中预测每个字符为答案起始位置以及终止位置的概率分布;
26、根据起始位置以及终止位置的最大概率预测答案在答复文件中的位置,以得到问题答案。
27、一种工业领域的多文档阅读理解装置,所述装置包括语义理解模块、问答交互模块、文档线索理解模块以及线索标注模块;
28、所述语义理解模块,用于对获取的目标问题以及各所述答复文件进行词嵌入处理,得到对应的目标问题特征向量集合以及各答复文件特征向量集合,各特征向量集合中分别包括对应目标问题或答复文件中所有单词的特征向量,再基于特征向量根据各所述答复文件与目标问题中每个单词之间的相关性对每一个单词分配注意力权重,并将注意力权重与目标问题或答复文件中对应的特征向量进行融合得到目标问题融合特征向量集合以及各答复文件融合特征向量集合;
29、所述问答交互模块,用于根据所述目标问题融合特征向量集合以及各答复文件融合特征向量集合,分别计算目标问题和答复文件之间两个交互方向的隐藏层向量,并基于所述隐藏层向量将所述目标问题中的单词语义融合至各答复文件特征向量中,得到各答复文件问题融合后特征向量集合;
30、所述文档线索理解模块,用于根据各所述答复文件问题融合后特征向量集合进行计算得到各所述答复文件的隐藏层向量集合,根据目标问题对多个答复文件的隐藏层向量集合进行筛选,再对筛选后答复文件的隐藏层向量集合中段落进行筛选,得到段落筛选后的隐藏层向量集合;
31、所述线索标注模块,用于采用指针网络根据段落筛选后的隐藏层向量集合,在对应的答复文件中预测答案的起始位置和终止位置,得到所述目标问题的答案。
32、一种计算机设备,包括存储器和处理器,所述存储器存储有计算机程序,所述处理器执行所述计算机程序时实现以下步骤:
33、获取目标问题以及与所述目标问题对应的多个答复文件;
34、对所述目标问题以及各所述答复文件进行词嵌入处理,得到对应的目标问题特征向量集合以及各答复文件特征向量集合,各特征向量集合中分别包括对应目标问题或答复文件中所有单词的特征向量;
35、基于特征向量根据各所述答复文件与目标问题中每个单词之间的相关性对每一个单词分配注意力权重,并将注意力权重与目标问题或答复文件中对应的特征向量进行融合得到目标问题融合特征向量集合以及各答复文件融合特征向量集合;
36、根据所述目标问题融合特征向量集合以及各答复文件融合特征向量集合,分别计算目标问题和答复文件之间两个交互方向的隐藏层向量,并基于所述隐藏层向量将所述目标问题中的单词语义融合至各答复文件特征向量中,得到各答复文件问题融合后特征向量集合;
37、根据各所述答复文件问题融合后特征向量集合进行计算得到各所述答复文件的隐藏层向量集合,根据目标问题对多个答复文件的隐藏层向量集合进行筛选,再对筛选后答复文件的隐藏层向量集合中段落进行筛选,得到段落筛选后的隐藏层向量集合;
38、采用指针网络根据段落筛选后的隐藏层向量集合,在对应的答复文件中预测答案的起始位置和终止位置,得到所述目标问题的答案。
39、一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现以下步骤:
40、获取目标问题以及与所述目标问题对应的多个答复文件;
41、对所述目标问题以及各所述答复文件进行词嵌入处理,得到对应的目标问题特征向量集合以及各答复文件特征向量集合,各特征向量集合中分别包括对应目标问题或答复文件中所有单词的特征向量;
42、基于特征向量根据各所述答复文件与目标问题中每个单词之间的相关性对每一个单词分配注意力权重,并将注意力权重与目标问题或答复文件中对应的特征向量进行融合得到目标问题融合特征向量集合以及各答复文件融合特征向量集合;
43、根据所述目标问题融合特征向量集合以及各答复文件融合特征向量集合,分别计算目标问题和答复文件之间两个交互方向的隐藏层向量,并基于所述隐藏层向量将所述目标问题中的单词语义融合至各答复文件特征向量中,得到各答复文件问题融合后特征向量集合;
44、根据各所述答复文件问题融合后特征向量集合进行计算得到各所述答复文件的隐藏层向量集合,根据目标问题对多个答复文件的隐藏层向量集合进行筛选,再对筛选后答复文件的隐藏层向量集合中段落进行筛选,得到段落筛选后的隐藏层向量集合;
45、采用指针网络根据段落筛选后的隐藏层向量集合,在对应的答复文件中预测答案的起始位置和终止位置,得到所述目标问题的答案。
46、上述工业领域的多文档阅读理解方法、装置、设备及存储介质,通过对目标问题以及各答复文件进行词嵌入处理,得到对应的目标问题特征向量集合以及各答复文件特征向量集合,通过模仿人类进行深层次阅读理解的过程,对目标问题特征向量集合以及各答复文件特征向量集合依次进行语义理解、问答交互、线索理解以及线索标注步骤后,在答复文件中获取问题答案,其中,在线索理解步骤,通过筛选答案所在位置概率较低的答复文件和段落后,以便于在后续可以更快更精准的获取问题答案。本方法适用于词表外单词较多的工业领域阅读理解。
- 还没有人留言评论。精彩留言会获得点赞!