不良用户的识别方法、装置、设备和介质与流程
本技术实施例涉及通信,尤其涉及一种不良用户的识别方法、装置、设备和介质。
背景技术:
1、随着互连网技术的发展,人们的沟通和交流变得越来越简单,各种社交软件成为人们日常生活中必不可少的社交工具,能够帮助用户拓展自己的社交圈,结识更多志同道合的人。目前社交软件可以直接发消息给附近的陌生人,即支持陌生人社交模式。但是这类社交软件由于发送信息没有任何成本,所以就存在一些不良用户向正常用户发送骚扰信息、垃圾信息以及其他不良信息,给正常用户的使用带来了干扰,影响正常用户的使用体验。因此,需要对社交软件中存在的不良用户进行识别,以净化网络环境,避免正常用户的使用被不良用户所干扰。
2、目前识别不良用户可采用敏感词的识别方式,具体是基于敏感词库检测发言者发送的信息内是否包含预设敏感词,当包含预设敏感词时确定发言者为不良用户。然而,这种识别方式存在如下问题:其一,需要事先建立一个敏感词库,并定期更新该敏感词库;其二,对于发言内容中的歧义词等容易发生误判,导致不良用户的误判率较高;其三,虽然敏感词库有对应的识别策略,但是发言者可通过拆字、同音字、添加干扰字等变体手段来躲避不良用户的识别操作,导致不良用户的识别效果差。
技术实现思路
1、本技术提供一种不良用户的识别方法、装置、设备和介质,通过基于已知不良用户来识别陌生人社交场景下的潜在不良用户,以解决通过敏感词库识别不良用户时存在的需要维护敏感词库、识别误判率高以及识别效果差等问题,从而可以保证正常用户在陌生人社交场景下的使用体验。
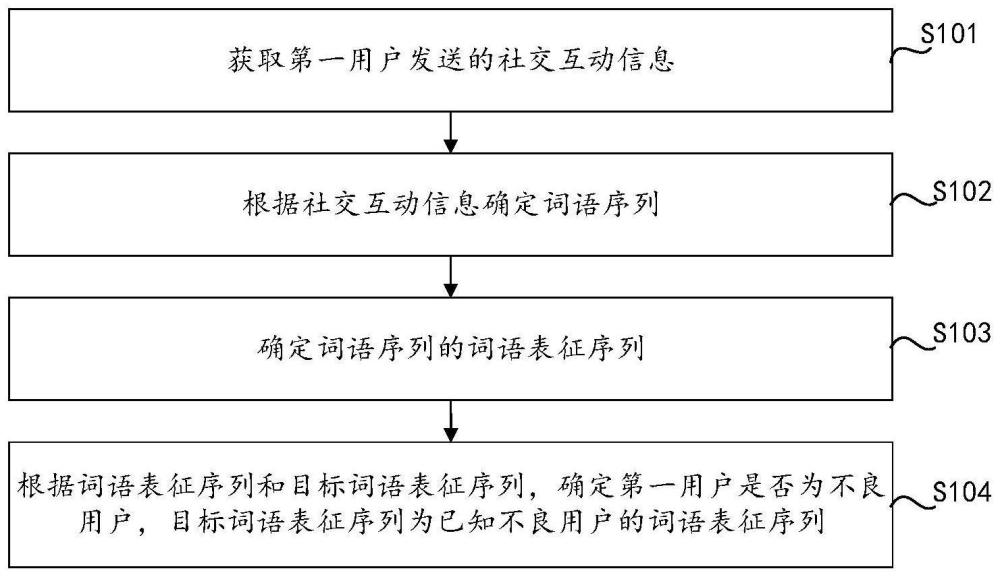
2、第一方面,本技术提供了一种不良用户的识别方法,包括:
3、获取第一用户发送的社交互动信息;
4、根据所述社交互动信息确定词语序列;
5、确定所述词语序列的词语表征序列;
6、根据所述词语表征序列和目标词语表征序列,确定所述第一用户是否为不良用户,所述目标词语表征序列为已知不良用户的词语表征序列。
7、在一些可选的实现方式中,所述根据所述词语表征序列和目标词语表征序列,确定所述第一用户是否为不良用户,包括:
8、确定所述词语表征序列和所述目标词语表征序列之间的相似度;
9、根据所述相似度确定所述第一用户是否为不良用户。
10、在一些可选的实现方式中,所述根据所述相似度确定所述第一用户是否为不良用户,包括:
11、当所述相似度大于相似度阈值时,确定所述第一用户为不良用户。
12、在一些可选的实现方式中,如果所述第一用户的数量为至少两个,则所述确定所述词语表征序列和所述目标词语表征序列之间的相似度,包括:
13、确定每个所述词语表征序列和所述目标词语表征序列之间的相似度;
14、相应的,所述根据所述相似度确定所述第一用户是否为不良用户,包括:
15、按照从大至小的顺序对所有相似度进行排序,得到第一排序结果;
16、按照从前至后的顺序从所述第一排序结果中选取预设数量目标相似度,并确定每个所述目标相似度对应的第一用户为不良用户。
17、在一些可选的实现方式中,所述确定所述词语表征序列和所述目标词语表征序列之间的相似度之后,还包括:
18、响应于根据所述相似度确定所述第一用户为可疑用户时,确定所述第一用户的交互特征;
19、将所述交互特征输入至分类模型,以通过所述分类模型基于所述交互特征确定所述第一用户为不良用户的得分;
20、根据所述第一用户为不良用户的得分,确定所述第一用户是否为不良用户。
21、在一些可选的实现方式中,所述根据所述第一用户为不良用户的得分,确定所述第一用户是否为不良用户,包括:
22、如果所述第一用户的数量为一个,则当所述第一用户为不良用户的得分大于第一阈值时,确定所述第一用户为不良用户;
23、如果所述第一用户的数量为至少两个,则按照从大至小的顺序对每个所述第一用户为不良用户的得分进行排序,得到第二排序结果,按照从前至后的顺序从所述第二排序结果中选取预设数量目标得分,并确定每个所述目标得分对应的第一用户为不良用户。
24、在一些可选的实现方式中,所述确定所述第一用户是否为不良用户,包括:
25、确定所述第一用户为不良用户的得分与所述第一用户相对应的相似度之间的和值;
26、根据所述和值确定所述第一用户是否为不良用户。
27、在一些可选的实现方式中,所述根据所述和值确定所述第一用户是否为不良用户,包括:
28、如果所述第一用户的数量为一个,则当所述和值大于预设阈值时,确定所述第一用户为不良用户;
29、如果所述第一用户的数量为至少两个,则按照从大至小的顺序对所有和值进行排序,得到第三排序结果,按照从前至后的顺序从所述第三排序结果中选取预设数量目标和值,并确定每个所述目标和值对应的第一用户为不良用户。
30、在一些可选的实现方式中,所述确定所述词语序列的词语表征序列,包括:
31、将所述词语序列输入至词向量模型,以通过所述词向量模型基于所述词语序列生成所述词语表征序列。
32、在一些可选的实现方式中,所述词向量模型通过如下步骤训练得到,包括:
33、获取至少两个历史社交互动信息,所述历史社交互动信息为任一第一用户的至少两个历史社交互动信息或者至少两个第一用户的至少一个历史社交互动信息;
34、对每个所述历史社交互动信息进行分词处理和清洗处理,得到与每个所述历史社交互动信息对应的历史词语序列;
35、根据所有历史词语序列,对初始神经网络模型进行训练以得到词向量模型。
36、在一些可选的实现方式中,所述根据所有历史词语序列,对初始神经网络模型进行训练以得到词向量模型,包括:
37、将所有历史词语序列作为训练数据,对初始神经网络模型进行迭代训练直至训练后的模型损失函数最小化,并将损失函数最小化对应的模型确定为所述词向量模型;
38、或者,
39、对每个所述历史词语序列进行独热编码,将编码后的每个历史词语序列作为训练数据,对初始神经网络模型进行训练,以使训练后的模型基于词语间的共现关系将编码后的历史词语序列中每个词映射到一个向量,得到所述词向量模型。
40、在一些可选的实现方式中,所述对每个所述历史社交互动信息进行分词处理,包括:
41、根据预设分词词库对每个所述历史社交互动信息进行分词处理,所述预设分词词库包括通用分词和个性化词语,所述个性化词语基于社交场景类型确定。
42、在一些可选的实现方式中,如果所述第一用户的数量为至少两个,则确定所述词语序列的词语表征序列之后,还包括:
43、对每个所述词语表征序列进行长度归一化处理。
44、在一些可选的实现方式中,还包括:
45、响应于第二用户触发的匹配操作,获取所述第二用户的注册信息和/或喜好信息;
46、根据所述第二用户的注册信息和/或喜好信息,在候选用户池中筛选至少一个目标用户,所述目标用户用于与所述第二用户进行社交互动;
47、确定每个所述目标用户是否为不良用户;
48、如果任意所述目标用户为不良用户,则剔除所述不良用户,并将剩余目标用户推荐给所述第二用户。
49、在一些可选的实现方式中,所述响应于第二用户触发的匹配操作之后,还包括:
50、获取所述第二用户的历史社交互动信息;
51、根据所述第二用户的历史社交互动信息,确定所述第二用户是否为不良用户;
52、如果所述第二用户为不良用户,则限制所述第二用户匹配到正常用户,或者拒绝所述第二用户触发的匹配操作。
53、第二方面,本技术提供了一种不良用户的识别装置,包括:
54、信息获取模块,用于获取第一用户发送的社交互动信息;
55、第一确定模块,用于根据所述社交互动信息确定词语序列;
56、第二确定模块,用于确定所述词语序列的词语表征序列;
57、识别模块,用于根据所述词语表征序列和目标词语表征序列,确定所述第一用户是否为不良用户,所述目标词语表征序列为已知不良用户的词语表征序列。
58、在一些可选的实现方式中,所述识别模块,包括:
59、第一确定单元,用于确定所述词语表征序列和所述目标词语表征序列之间的相似度;
60、第二确定单元,用于根据所述相似度确定所述第一用户是否为不良用户。
61、在一些可选的实现方式中,所述第二确定单元,具体用于:当所述相似度大于相似度阈值时,确定所述第一用户为不良用户。
62、在一些可选的实现方式中,如果所述第一用户的数量为至少两个,则所述第一确定单元,具体用于:确定每个所述词语表征序列和所述目标词语表征序列之间的相似度;
63、相应的,所述第二确定单元,具体用于:
64、按照从大至小的顺序对所有相似度进行排序,得到第一排序结果;
65、按照从前至后的顺序从所述第一排序结果中选取预设数量目标相似度,并确定每个所述目标相似度对应的第一用户为不良用户。
66、在一些可选的实现方式中,所述识别模块,包括:
67、第三确定单元,用于响应于根据所述相似度确定所述第一用户为可疑用户时,确定所述第一用户的交互特征;
68、第四确定单元,用于将所述交互特征输入至分类模型,以通过所述分类模型基于所述交互特征确定所述第一用户为不良用户的得分;
69、第五确定单元,用于根据所述第一用户为不良用户的得分,确定所述第一用户是否为不良用户。
70、在一些可选的实现方式中,所述第五确定单元,具体用于:
71、如果所述第一用户的数量为一个,则当所述第一用户为不良用户的得分大于第一阈值时,确定所述第一用户为不良用户;
72、如果所述第一用户的数量为至少两个,则按照从大至小的顺序对每个所述第一用户为不良用户的得分进行排序,得到第二排序结果,按照从前至后的顺序从所述第二排序结果中选取预设数量目标得分,并确定每个所述目标得分对应的第一用户为不良用户。
73、在一些可选的实现方式中,所述识别模块,还包括:
74、和值确定单元,用于确定所述第一用户为不良用户的得分与所述第一用户相对应的相似度之间的和值;
75、第六确定单元,用于根据所述和值确定所述第一用户是否为不良用户。
76、在一些可选的实现方式中,所述第六确定单元,具体用于:
77、如果所述第一用户的数量为一个,则当所述和值大于预设阈值时,确定所述第一用户为不良用户;
78、如果所述第一用户的数量为至少两个,则按照从大至小的顺序对所有和值进行排序,得到第三排序结果,按照从前至后的顺序从所述第三排序结果中选取预设数量目标和值,并确定每个所述目标和值对应的第一用户为不良用户。
79、在一些可选的实现方式中,所述第二确定模块,具体用于:将所述词语序列输入至词向量模型,以通过所述词向量模型基于所述词语序列生成所述词语表征序列。
80、在一些可选的实现方式中,还包括:模型构建模块,所述模型构建模块用于执行如下步骤:
81、获取至少两个历史社交互动信息,所述历史社交互动信息为任一第一用户的至少两个历史社交互动信息或者至少两个第一用户的至少一个历史社交互动信息;对每个所述历史社交互动信息进行分词处理和清洗处理,得到与每个所述历史社交互动信息对应的历史词语序列;根据所有历史词语序列,对初始神经网络模型进行训练以得到词向量模型。
82、在一些可选的实现方式中,所述模型构建模块,具体用于:
83、将所有历史词语序列作为训练数据,对初始神经网络模型进行迭代训练直至训练后的模型损失函数最小化,并将损失函数最小化对应的模型确定为所述词向量模型;
84、或者,
85、对每个所述历史词语序列进行独热编码,将编码后的每个历史词语序列作为训练数据,对初始神经网络模型进行训练,以使训练后的模型基于词语间的共现关系将编码后的历史词语序列中每个词映射到一个向量,得到所述词向量模型。
86、在一些可选的实现方式中,所述模型构建模块,具体用于:根据预设分词词库对每个所述历史社交互动信息进行分词处理,所述预设分词词库包括通用分词和个性化词语,所述个性化词语基于社交场景类型确定。
87、在一些可选的实现方式中,如果所述第一用户的数量为至少两个,所述装置还包括:长度处理模块,用于对每个所述词语表征序列进行长度归一化处理。
88、在一些可选的实现方式中,还包括:
89、操作响应模块,用于响应于第二用户触发的匹配操作,获取所述第二用户的注册信息和/或喜好信息;
90、用户筛选模块,用于根据所述第二用户的注册信息和/或喜好信息,在候选用户池中筛选至少一个目标用户,所述目标用户用于与所述第二用户进行社交互动;
91、第四确定模块,用于确定每个所述目标用户是否为不良用户;
92、处理模块,用于如果任意所述目标用户为不良用户,则剔除所述不良用户,并将剩余目标用户推荐给所述第二用户。
93、在一些可选的实现方式中,还包括:
94、历史信息获取模块,用于获取所述第二用户的历史社交互动信息;
95、第五确定模块,用于根据所述第二用户的历史社交互动信息,确定所述第二用户是否为不良用户;
96、控制模块,用于如果所述第二用户为不良用户,则限制所述第二用户匹配到正常用户,或者拒绝所述第二用户触发的匹配操作。
97、第三方面,本技术提供了一种电子设备,包括:
98、处理器和存储器,所述存储器用于存储计算机程序,所述处理器用于调用并运行所述存储器中存储的计算机程序,以执行如第一方面实施例所述的不良用户的识别方法。
99、第四方面,本技术提供了一种计算机可读存储介质,用于存储计算机程序,所述计算机程序使得计算机执行如第一方面实施例所述的不良用户的识别方法。
100、第五方面,本技术提供了一种包含程序指令的计算机程序产品,当程序指令在电子设备上运行时,使得电子设备执行如第一方面实施例所述的不良用户的识别方法。
101、本技术实施例公开的技术方案,至少具有如下有益效果:
102、通过基于第一用户发送的社交互动信息确定词语序列,并基于词语序列确定词语表征序列,进而根据词语表征序列和已知不良用户的词语表征序列,识别第一用户是否为不良用户。本技术通过基于已知不良用户来识别陌生人社交场景下的潜在不良用户,以解决通过敏感词库识别不良用户时存在的需要维护敏感词库、识别误判率高以及识别效果差等问题,从而可以保证正常用户在陌生人社交场景下的使用体验。
- 还没有人留言评论。精彩留言会获得点赞!