二代测序RNA融合假阳性的过滤方法与流程
本发明涉及一种二代测序rna融合假阳性的过滤方法,属于生物信息。
背景技术:
1、next-generation sequencing(ngs),又称高通量测序,以高输出量和高深度为主要特色,能一次对数百万dna分子进行序列读取,其中rna ngs即为通过反转录酶将rna片段反转录成cdna,然后通过对这些cdna的测序来获得原本rna片段的序列信息。
2、融合基因(fusion gene)是指两个基因的部分序列结合在一起发生融合形成的嵌合基因;一般是由染色体易位、缺失、倒位等原因所致;这类嵌合基因通常会在后续的生物学过程中形成异常的转录本和蛋白质,从而导致肿瘤的发生。
3、融合基因检测已经被nccn、who指南纳入了肺癌、结直肠癌多个癌种的诊疗指南中。目前可用于检测融合基因的主要方法有:荧光原位杂交(fish)、免疫组织化学(ihc)、pcr、dna ngs、rna ngs。其中,rna ngs比起其他几种检测手段有其明显的优势。一方面,ngs不仅可以检测已知的特定融合基因,还能够检测未知的融合基因,并且不依赖检测人员的主观判断;另一方面,与dna ngs相比,rnangs在探针的设计方面更加简单,并且能够提升融合检出率,降低假阴性。此外,部分基因融合并不会形成新的融合转录本,而在rna ngs检测中这些融合不会出现。
4、目前rna ngs检测融合基因的生物信息分析领域已经有一套比较成熟的分析流程和多款比较成熟的分析软件。测序数据在质控、拼接后通过star、hisat2等软件比对到参考序列;随后用一系列比较成熟的软件能从中找到潜在的突变的位点:比如starfusion、fusioncatcher、jaffa、sopafuse、tophat-fusion、arriba等等。这些软件的算法各不相同,并且部分也有自己的过滤假阳性的功能;最终会呈现出许多预测的融合基因结果。
5、然而在实际的病例检测中,多数病例的驱动融合基因只有一个,极少数病例会有复数的驱动融合基因。即使自身存在着假阳性过滤流程,但是由于建库技术比对软件的局限性等问题,这些寻找融合基因的软件结果中仍不可避免地存在许多假的融合基因和非驱动融合基因。
6、与此同时,如果样本质量本身也不够好,那便会存在大量的假阳性,这在大样本量检测的时候会消耗相关人员非常多的时间并且非常依赖报告人员的经验。同时由于样本测序原因,部分真融合可能支持的read数很少而被软件自己过滤掉了,这可能会造成漏检。此外,部分基因的融合属于激活融合,会提高表达量,因此往往它们会有更多的read支持而被软件认为是高置信度的真阳性融合基因。
7、综上,目前缺乏一种能够有效过滤rna ngs检测结果中假阳性和找到驱动突变的技术手段。
8、机器学习是人工智能的一个分支,它旨在开发算法和技术,让计算机能够“学习”,即在没有明确编程的情况下自动改进其性能。它主要可以分为有监督学习、无监督学习和强化学习;在有监督学习中,算法通过训练数据集学习,该数据集包含输入向量和与之对应的目标输出,算法的目标是找到输入和输出之间的映射;无监督学习涉及到没有标签数据的情况,算法必须自己发现数据的结构和规律;强化学习则是一个关于奖励和惩罚的决策过程,算法学习如何在环境中采取行动,以最大化所获得的累计奖励。
9、机器学习在多个领域都有着广泛的应用,比如在医疗诊断中识别疾病模式,在金融市场预测股价,随着技术的不断进步和可用数据量的日益增加,机器学习正变得越来越重要。
10、支持向量机(support vector machine,svm)是一种非常流行的机器学习算法,主要可以用于模式识别、分类以及回归分析。
11、svm的核心思想是在特征空间中寻找最优的决策边界,即所谓的最大间隔超平面,它能够以最大的边缘将不同的类别分开。在二分类问题中,这个超平面是一条线(在二维空间)或是一个平面(在三维空间),在更高维的空间中则是一个超平面。所谓“支持向量”就是离这个决策边界最近的数据点,它们对于定义最大间隔有着决定性的作用。svm的优化目标就是最大化这些支持向量到决策边界的最小距离,进而构造出具有最好泛化能力的分类器。
12、支持向量机算法在许多问题上展示了优越的性能,特别是在小样本下的分类问题上。在选择合适的核函数和调整参数(如软间隔参数)时,svm能够展现出极高的精度,并且对于泛化误差的控制也较为出色。虽然在大规模数据集上svm的计算可能相对耗时,以及对于参数选择较为敏感,但它仍然是许多领域内不可或缺的机器学习工具之一。
技术实现思路
1、本发明的主要目的是:基于现有技术条件,克服现有技术存在的问题,提供一种二代测序rna融合假阳性的过滤方法,能有效地从rna ngs的结果中尽可能过滤掉假阳性并且保留可能存在的驱动突变,从而有效减少报告人员的工作量。
2、本发明解决其技术问题的技术方案如下:
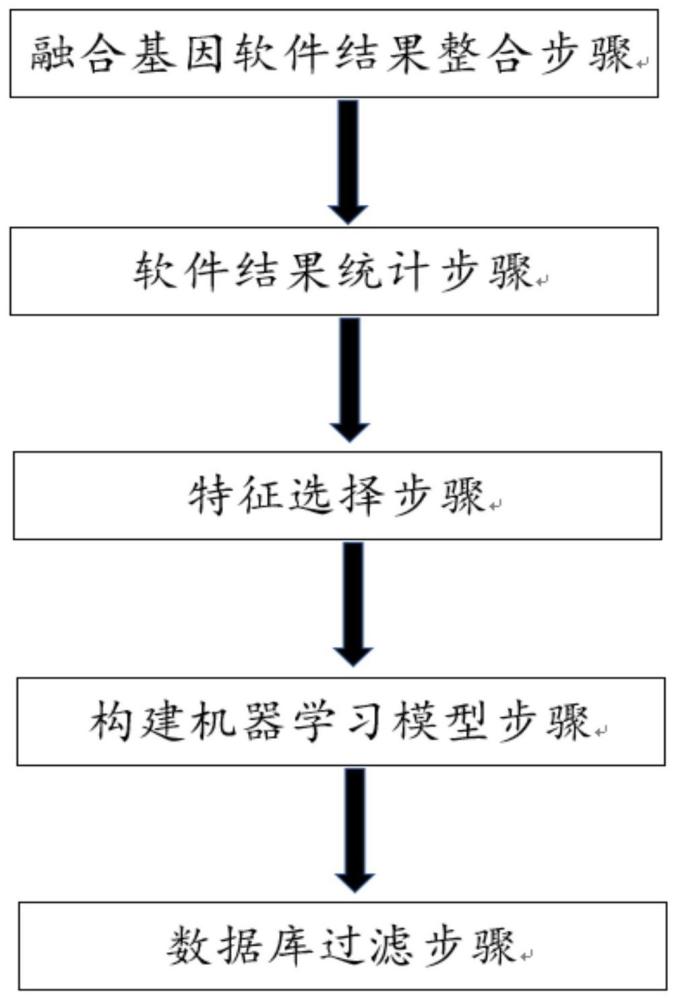
3、一种二代测序rna融合假阳性的过滤方法,包括以下步骤:
4、第一步、采用已获得的rna ngs数据;采用arriba软件处理rna ngs数据并获得第一预测结果;采用starfusion软件处理rna ngs数据并获得第二预测结果,或者/并且,采用fusioncatcher软件处理rna ngs数据并获得第三预测结果;在第一预测结果中,选择与第二预测结果中同时出现或者/并且与第三预测结果中同时出现的预测结果作为初步筛选结果。
5、第二步、将初步筛选结果中的真阳性和假阳性进行统计,并且做好标记,作为模型训练和检验的依据。
6、第三步、通过相关性检验对第二步所得结果进行验证,保留按预设标准判断为与假阳性关联度高的特征,收集这些特征的数据并加上标签作为训练和测试数据。
7、第四步、选择机器学习中的支持向量机svm作为分类模型,从第三步所得数据集中随机选择预设比例的数据作为训练集,将其余数据作为验证集,并且评估分类效果,调整模型参数,优先保证灵敏度使得驱动融合不能标记为假阳性。
8、第五步、采用以已知的假阳性融合基因构建的假阳性数据库;将第四步所得分类模型处理所得数据中标注为真阳性的结果以假阳性数据库过滤,最终得到融合基因预测结果。
9、本发明进一步完善的技术方案如下:
10、优选地,所述过滤方法还包括:第六步、采用已知驱动融合基因数据库;将在第五步中因支持read数未达阈值而被过滤掉但存在于已知驱动融合基因数据库的融合基因放入候补列表中;当第五步所得融合基因预测结果中找到了驱动融合基因时,则不予考虑该候补列表;当第五步所得融合基因预测结果中未发现驱动融合基因时,则验证该候补列表中的融合基因是否为驱动融合基因。
11、优选地,第三步中,与假阳性关联度高的特征选自:site1,site2,type,split_reads1,split_reads2,coverage1,coverage2,confidence,reading_frame,tags。
12、更优选地,第三步中,site1为第一个断点的位置信息;site2为第二个断点的位置信息;type表示产生融合的事件类型;split_read1表示具有锚点支持的左侧断点的支持读段数量,且其中不包含重复读段;split_read2表示具有锚点支持的右侧断点的支持读段数量,且其中不包含重复读段;coverage1表示左侧断点保留一侧的片段数,且其中包含重复读段;coverage2表示右侧断点保留一侧的片段数,且其中包含重复读段;confidence表示软件评估的该融合基因的置信度,选自high、medium、low之一;reading_frame表示该融合基因的3’端基因读码框是否完整,选自完整、不完整、无法判断之一;tags表示是否在数据库中有记录,该数据库包括mitelman数据库。
13、优选地,第二步中,根据已知的真阳性样本数据及假阳性样本数据对初步筛选结果中的数据按真阳性、假阳性贴标签作为标记,同时进行统计。
14、优选地,第三步中,利用统计软件包对对第二步所得结果进行特征和标签之间的相关性检验分析;预设标准为:相关性指标>0.7则判断为与假阳性关联度高。
15、优选地,第四步中,应用机器学习框架scikit-learn来训练和评估svm分类模型;使用包括fβ-measure在内的加权评估标准,其中β参数设定为5;评估分类效果时,分别参考混淆矩阵、roc曲线对svm分类模型进行性能验证。
16、优选地,第五步中,所述假阳性数据库根据已知的假阳性融合基因的变化而更新。
17、优选地,第六步中,所述已知驱动融合基因数据库的数据来源包括cosmic、chimerdb。
18、采用以上优选方案,可进一步优化各步骤的具体细节技术特征。
19、与现有技术相比,本发明方法通过综合多个融合基因分析软件的结果,并且提取与假阳性相关的特征构建特征矩阵,随后通过机器学习中的支持向量机算法(svm)构建预测模型,对软件预测的融合基因结果进行过滤,从而标记出结果中存在的假阳性。本发明可以有效从rna ngs的结果中尽可能过滤掉假阳性并且保留可能存在的驱动突变,从而有效减少报告人员的工作量。
- 还没有人留言评论。精彩留言会获得点赞!