用于音频和视频编辑的文本驱动编辑器的制作方法
所公开的技术总体上涉及用于视频编辑和组合视频节目的计算机实现的方法、系统和计算机程序。更具体地,本公开涉及用于基于从视频片段(video clip)的音频轨道中的转录语音导出的关键词或声音片段(soundbite)来编辑和组合视频节目的方法、系统和计算机程序。
背景技术:
1、本节中讨论的主题不应仅仅因为其在本节中被提及而被假定为现有技术。类似地,本节中提及的、或与作为背景技术提供的主题相关联的问题不应被假定为先前在现有技术中已被认识到。本节中的主题仅表示不同的方法,这些方法本身也可以对应于权利要求技术的实施方式。
2、视频编辑是将视频镜头、视频片段、特效和录音的片段编辑成最终视频节目的过程。在过去,非线性视频编辑(nonlinear video editing,nle)是在复杂且昂贵的专用机器上使用专用软件来执行的,但是随着时间的推移,视频编辑软件已经发展为可广泛地用于个人计算机、甚至计算机平板和智能电话。在过去十年中,随着越来越多的社交媒体视频平台广泛使用视频,对视频编辑软件的需求也在增长。社交媒体视频平台的指数增长使得内容创作者相应增长,这些内容创作者正在生成视频内容、编辑该视频内容并将该视频内容上传到社交媒体视频平台和其他地方。
3、在专业视频编辑中,计算机程序昂贵且复杂,需要对用户进行培训以使用通常较为复杂的用户界面。为了变得熟练,非线性视频编辑的用户必须获得专家级的知识和培训,以掌握非线性视频编辑系统的流程和用户界面。已知的非线性视频编辑系统由于复杂性而可能会让普通用户望而生畏。
4、此外,这类计算机程序在计算上是低效的。例如,这类计算机程序在编辑期间生成视频副本时浪费了处理资源以及存储器资源。例如,响应于从较大的数字视频中生成视频片段的用户命令,现有的计算机程序通常将会:1)从该数字视频中复制帧以生成独立的视频片段,或者2)复制整个数字视频,然后删除不被包括在视频片段中的视频帧。因此,现有的计算机程序浪费了大量的处理周期,同时导致与视频编辑任务相关的存储器使用量迅速膨胀。
技术实现思路
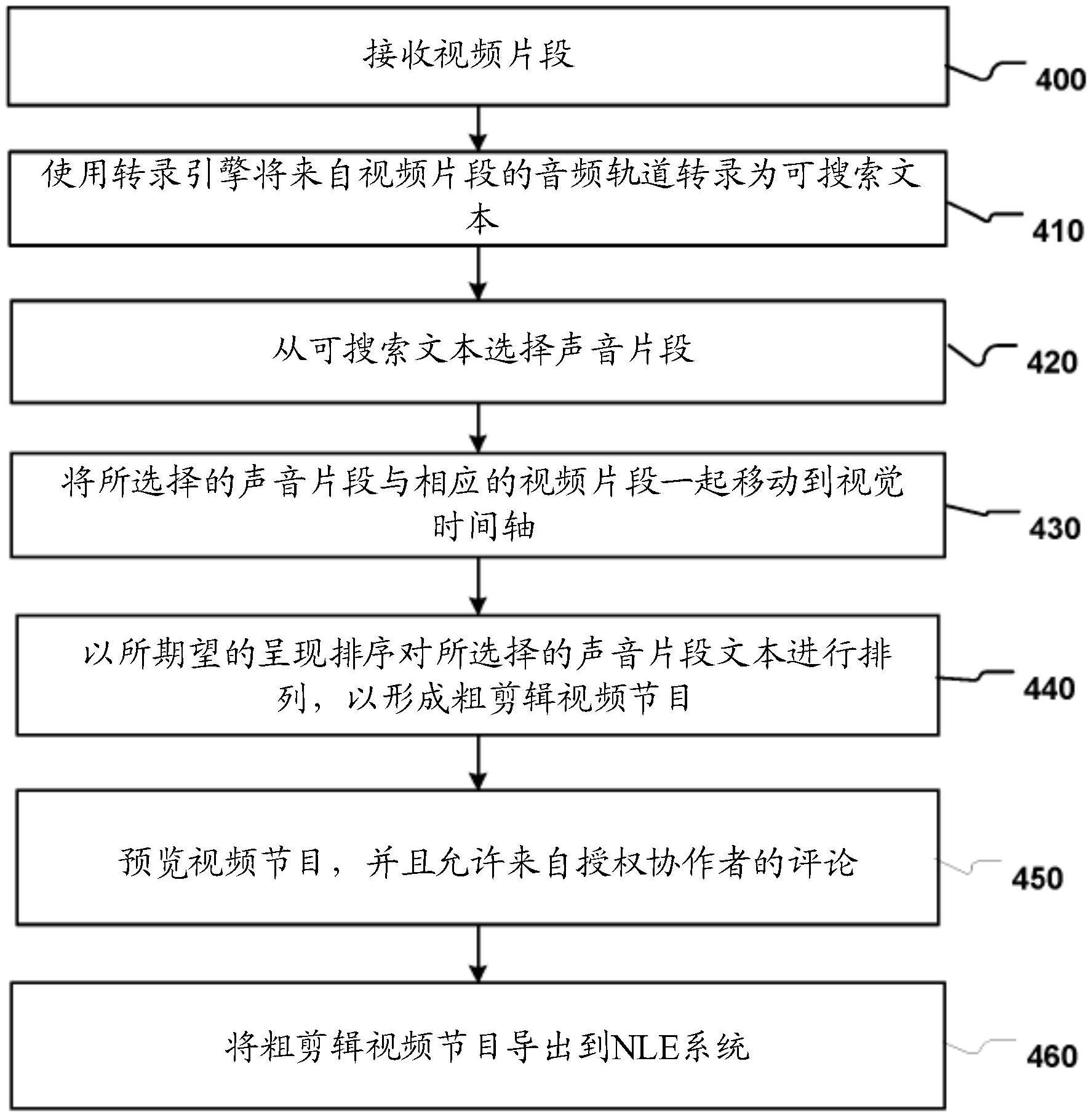
1、根据本公开的第一方面,提供了一种计算机实现的方法,包括:生成视频组合界面,该视频组合界面包括与数字视频相关联的视频回放窗口、以及显示该数字视频的音频轨道的转录的转录文本窗口;接收对从转录文本窗口中的音频轨道的转录选择一个或多个词语的指示;生成与所选择的一个或多个词语相对应的第一视频片段;以及在视频组合界面内生成包括该第一视频片段的视频时间轴。
2、生成视频组合界面可以响应于检测到从多个已上传的数字视频选择了数字视频。
3、接收对从转录文本窗口中的音频轨道的转录选择一个或多个词语的指示可以包括:接收对用户突出显示来自该转录中的一个或多个词语中的一者的指示;或者接收对用户选择与视频回放窗口相关联的一个或多个回放指示符的指示。
4、生成与所选择的一个或多个词语相对应的第一视频片段可以响应于检测到将所选择的一个或多个词语从转录文本窗口拖放到视频组合界面内的视频时间轴的用户交互。
5、该计算机实现的方法还可以包括:接收对从转录文本窗口中的音频轨道的转录选择附加词的指示;生成与所选择的附加词相对应的第二视频片段;以及将该第二视频片段添加到视频时间轴。
6、该计算机实现的方法还可以包括:响应于检测到与视频组合界面内的视频时间轴的用户交互,在视频时间轴内对第一视频片段和第二视频片段进行重新排序。
7、该计算机实现的方法还可以包括:响应于检测到从多个已上传的数字视频选择了附加数字视频:从视频组合界面内的视频回放窗口去除数字视频;从视频组合界面内的转录文本窗口去除该数字视频的音频轨道的转录;将附加视频添加到视频组合界面内的视频回放窗口;将附加视频的音频轨道的转录添加到视频组合界面内的转录文本窗口;以及将第一视频片段和第二视频片段保留在视频组合界面的视频时间轴内。
8、根据本公开的第二方面,提供了一种系统,包括:至少一个物理处理器;以及包括计算机可执行指令的物理存储器,所述计算机可执行指令在由物理处理器执行时,使物理处理器执行包括以下各项的动作:生成视频组合界面,该视频组合界面包括与数字视频相关联的视频回放窗口、以及显示该数字视频的音频轨道的转录的转录文本窗口;接收对从转录文本窗口中的音频轨道的转录选择一个或多个词语的指示;生成与所选择的一个或多个词语相对应的第一视频片段;以及在视频组合界面内生成包括该第一视频片段的视频时间轴。
9、生成视频组合界面可以响应于检测到从多个已上传的数字视频选择了数字视频。
10、物理存储器还可以包括计算机可执行指令,所述计算机可执行指令在由物理处理器执行时,使物理处理器执行包括以下各项的动作:通过以下动作接收对从转录文本窗口中的音频轨道的转录选择一个或多个词语的指示:接收对用户突出显示来自该转录中的一个或多个词语中的一者的指示;或者接收对用户选择与视频回放窗口相关联的一个或多个回放指示符的指示。
11、生成与所选择的一个或多个词语相对应的第一视频片段可以响应于检测到将所选择的一个或多个词语从转录文本窗口拖放到在视频组合界面内的视频时间轴的用户交互。
12、物理存储器还可以包括计算机可执行指令,所述计算机可执行指令在由物理处理器执行时,使物理处理器执行包括以下各项的动作:接收对从所述转录文本窗口中的所述音频轨道的所述转录选择附加词的指示;生成与所选择的附加词对应的第二视频片段;以及将该第二视频片段添加到视频时间轴。
13、物理存储器还可以包括计算机可执行指令,所述计算机可执行指令在由物理处理器执行时,使物理处理器执行包括以下各项的动作:响应于检测到与视频组合界面内的视频时间轴的用户交互,在视频时间轴内对第一视频片段和第二视频片段进行重新排序。
14、物理存储器还可以包括计算机可执行指令,所述计算机可执行指令在由物理处理器执行时,使物理处理器执行包括以下各项的动作:响应于检测到从所述多个已上传的数字视频选择了附加数字视频:从视频组合界面内的视频回放窗口去除数字视频;从视频组合界面内的转录文本窗口去除该数字视频的音频轨道的转录;将附加视频添加到视频组合界面内的视频回放窗口;将附加视频的音频轨道的转录添加到视频组合界面内的转录文本窗口;以及将第一视频片段和第二视频片段保留在视频组合界面的视频时间轴内。
15、根据本公开的第三方面,提供了一种计算机可读介质,该计算机可读介质包括一个或多个计算机可执行指令,该一个或多个计算机可执行指令在由计算设备中的至少一个处理器执行时,使该计算设备执行包括以下各项的动作:生成视频组合界面,该视频组合界面包括与数字视频相关联的视频回放窗口、以及显示该数字视频的音频轨道的转录的转录文本窗口;接收对从转录文本窗口中的音频轨道的转录选择一个或多个词语的指示;生成与所选择的一个或多个词语相对应的第一视频片段;以及在视频组合界面内生成包括该第一视频片段的视频时间轴。该介质可以是非暂态的。
16、计算机可读介质还可以包括计算机可执行指令,所述计算机可执行指令在由计算设备中的至少一个处理器执行时,使该计算设备执行包括以下各项的动作:通过以下动作接收对从转录文本窗口中的音频轨道的转录选择一个或多个词语的指示:接收对用户突出显示来自该转录中的一个或多个词语中的一者的指示;或者接收对用户选择与视频回放窗口相关联的一个或多个回放指示符的指示。
17、生成与所选择的一个或多个词语相对应的第一视频片段可以响应于检测到将所选择的一个或多个词语从转录文本窗口拖放到视频组合界面内的视频时间轴的用户交互。
18、计算机可读介质还可以包括计算机可执行指令,所述计算机可执行指令在由计算设备中的至少一个处理器执行时,使该计算设备执行包括以下各项的动作:接收对从转录文本窗口中的音频轨道的转录选择附加词的指示;生成与所选择的附加词相对应的第二视频片段;以及将该第二视频片段添加到视频时间轴。
19、计算机可读介质还可以包括计算机可执行指令,所述计算机可执行指令在由计算设备中的至少一个处理器执行时,使该计算设备执行包括以下各项的动作:响应于检测到与视频组合界面内的视频时间轴的用户交互,在视频时间轴内对第一视频片段和第二视频片段进行重新排序。
20、计算机可读介质还可以包括计算机可执行指令,所述计算机可执行指令在由计算设备中的至少一个处理器执行时,使该计算设备执行包括以下各项的动作:响应于检测到从多个已上传的数字视频选择了附加数字视频:从视频组合界面内的视频回放窗口去除数字视频;从视频组合界面内的转录文本窗口去除该数字视频的音频轨道的转录;将附加视频添加到视频组合界面内的视频回放窗口;将附加视频的音频轨道的转录添加到视频组合界面内的转录文本窗口;以及将第一视频片段和第二视频片段保留在视频组合界面的视频时间轴内。
21、并入内容
22、如在本文中完全阐述的,将以下材料通过引用并入:
23、于2018年5月2日提交的、名称为“machine learning based speech-to-texttranscription cloud intermediary”的第62/666,017号美国临时专利申请;
24、于2018年5月2日提交的、名称为“deep learning based speech-to-texttranscription cloud intermediary”的第62/666,025号美国临时专利申请(案卷号为simn 1000-2);
25、于2018年5月2日提交的、名称为“expert deep neural networks for speech-to-text transcription”的第62/666,050号美国临时专利申请(案卷号为simn 1000-3);
26、a.van den oord,s.dieleman,h.zen,k.simonyan,o.vinyals,a graves,n.kalchbrenner,a senior,和k.kavukcuoglu,"wavenet:a generative model for rawaudio,"arxiv:l609.03499,2016;
27、s.b.arik,m.chrzanowski,a coates,g.diamos,a gibiansky,y.kang,x.li,j.miller,a ng,j.raiman,s.sengupta和m.shoeybi,"deep voice:real-time neuraltext-to-speech,"arxiv:l702.07825,2017;
28、j.wu,"introduction to convolutional neural networks,"南京大学,2017。
29、i.j.goodfellow,d.warde-farley,m.mirza,a courville和y.bengio,"convolutional networks,"deep learning,mit press,2016;
30、f.chaubard,r.mundra和r.socher,"cs 224d:deep learning for nlp,lecturenotes:part i,"2015;
31、f.chaubard,r.mundra和r.socher,"cs 224d:deep learning for nlp,lecturenotes:part ii,"2015;
32、f.chaubard,r.mundra和r.socher,"cs 224d:deep learning for nlp,lecturenotes:part iii,"2015;
33、f.chaubard,r.mundra和r.socher,"cs 224d:deep learning for nlp,lecturenotes:part iv,"2015;
34、f.chaubard,r.mundra和r.socher,"cs 224d:deep learning for nlp,lecturenotes:part v,"2015;以及
35、y.fan,m.potok和c.shroba,"deep learning for audio,"2017。
- 还没有人留言评论。精彩留言会获得点赞!