一种支持LTE标准的Turbo码译码装置及方法与流程
本发明属于移动通信系统技术领域,尤其涉及一种Turbo码译码装置及方法。
背景技术:
Turbo码具有固有的并行性、高编码增益,且由于Turbo码很好地应用了香农信道编码定理中的随机性编译码条件而获得了接近香农限的译码性能和纠错性能,因此,Turbo码被WiMax、CCSDS、3GPP LTE、HSDPA等诸多通信标准所采纳。
LTE标准是被广泛采纳的一个通信标准,它采用的RSC编码器为(13,15)系统码,规定了188种不同Turbo码码块长度的Turbo码,码块长度从40~6144不等。因此,它既可以用于传输控制信息这种数据量比较少的短帧,也可以用于传输数据信息这种数据量很大的长帧。Turbo码的译码器目前大多采用基2算法或者基4算法来实现,基4算法的基本思想是将基2算法的前后两个时刻合并为一个时刻进行处理,在计算对数似然比时,由基2的1个输入变为2个输入,因此,基4译码算法存储器的访问次数只有基2算法的1/2,需存储的前后递归变量也变为原来的一半,但是需要考虑的分支度量数目则变为原来的2倍,需要更大规模的电路来进行处理,且单个分支度量的计算复杂度增大,导致一个时钟内处理不了,往往需要采用并行分块的方式来加快译码速度,但是这种处理方式由于受到分块数目、初始值计算等因素的限制往往不能支持LTE标准的全部码型。
技术实现要素:
因此,为解决上述问题,本发明特提出一种支持LTE标准的Turbo码译码装置及方法,该方法利用基2Turbo译码架构来实现LTE标准的Turbo码,并对其中的关键部分进行优化处理。
采用基2Turbo译码结构的好处:
1、采用基2Turbo译码算法能够在计算alpha和beta值时,可以一个时钟内计算完成,减少了关键路径的长度,因此,不需要采用多个数据块进行并行计算的方式,从而可以节约计算beta值初始值所耗费的计算资源;
2、采用基2Turbo译码算法虽然没有基4Turbo译码算法的计算速度快,但是前者比后者的计算过程要简单得多,所占用的资源也要少很多;
3、基2Turbo译码算法不但运算过程简单,而且由于状态数大量减少,因此,需要计算的分支度量gamma的数目也大大减少,从而节约了面积;
4、基4Turbo译码算法由于受到解交织参数、并行度等方面的约束,有些码块长度不适宜采用基4Turbo译码算法,特别是码块长度比较短的情形,而基2Turbo译码算法则对Turbo码码块长度没有特殊要求。
基2的Turbo译码器的基本结构如图1所示,它是一个迭代递归的过程。它由两个分量译码器(DEC1)和(DEC2)串行级联而成。首先,系统位信息和经过选择器的校验位信息一送入第一个分量译码器(DEC1),产生的外信息经过交织器,与经过交织的系统位信息以及经过选择器的校验位信息二一起被输入到第二个分量译码器(DEC2),产生的外信息经过解交织后送入到第一个分量译码器(DEC1)中,经过数次这样的迭代运算,对分量译码器(DEC2)输出的对数似然比进行解交织后送入判决模块进行判决即可得到最终的译码结果。其中,两个分量译码器之间的交织器与编码器内部所使用的交织器相同,解交织是该交织器的逆操作。
如图1所示,每个分量译码器有3个输入,
(1)从信道接收到的系统位信息或经过交织的系统位信息;
(2)从信道接收到的相应编码器的校验位信息
(3)从另一个分量译码器得到的每比特的似然信息La(uk)。
一种支持LTE标准188种码块长度的Turbo码译码的方法,利用基2Turbo译码架构来实现LTE标准的Turbo码,并对其中的关键部分进行优化处理,具体内容包括基于Log-Max-MAP算法的加比选运算单元、基于滑窗实现的递归计算单元和不同码块长度下滑窗长度的控制单元。
MAP算法需要遍历卷积码格图上的每一条路径,是性能最优的算法。它的基本思想是在接收序列为Y的条件下,计算每译码比特为+1或-1的概率。这相当于计算后验概率的对数似然值,即L(uk|Y),它可由式(1)获得
其中,(s',s)=>uk=+1表示在格图上,当第k时刻输入uk=+1时,由第k-1时刻状态Sk-1=s'到第k时刻状态Sk=s的所有可能的状态转移,(s',s)=>uk=-1的含义与此类似。αk(s)为第k时刻状态Sk=s的前向状态度量,βk(s)为第k时刻状态Sk=s的后向状态度量,γk(s',s)为第k-1时刻状态Sk-1=s'转移第k时刻状态Sk=s的分支转移度量,它们的计算公式分别为
αk(s)=∑all s'αk-1(s')γk(s',s) (2)
βk-1(s')=∑all sβk(s)γk(s',s) (3)
其中,式(4)中uk表示第k时刻的输入信息,表示第k时刻输入为uk的条件下编码器的第p(p=1,2)个输出,表示第k时刻的第p(p=1,2)个观测信号。
注意到MAP算法在计算后验对数似然比L(uk|Y)时,其中涉及大量的乘法、除法运算,Max-Log-MAP算法巧妙的将这些运算放到对数域中进行,这样可以将乘、除法转化为加、减法运算,从而可以大大简化计算复杂度。令Ak(s)=ln(αk(s)),Bk(s)=ln(βk(s)),Γk(s',s)=ln(γk(s',s)),则可以得到
为了计算得到每比特的对数似然比,必须先计算前、后向状态度量以及分支转移度量。但由于前向和后向状态度量迭代秩序正好相反,需要对前向状态度量(或后向状态度量)进行存储,直到相应的后向状态度量迭代计算完成,才可以进行对数似然比的计算,这必将导致译码延迟很大,特别是Turbo码码块长度较大的情况下,因此,在实际系统中难以承受。
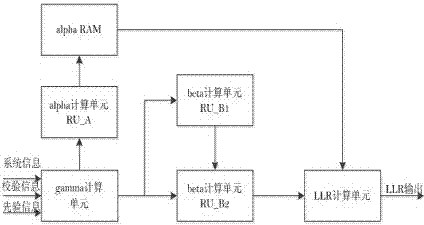
为了解决译码延时过大的问题,采用滑窗法来实现。它的基本原理为基2的Max-Log-MAP算法的滑窗结构如图2所示,它主要包括分支度量Gamma计算模块、前向状态度量Alpha递归计算模块RU_A,用于递归计算后向状态度量Beta起始值的模块RU_B1,用于递归计算Beta正确值的RU_B2模块和对数似然比LLR计算模块。
可以看出,滑窗法只需等待一个较小的译码延迟,大约传输3~5倍约束度码元个数的时间,然后就可以开始计算对数似然比,这个译码延迟与等待全部码元的前向度量迭代计算完毕相比,大大减少了译码延迟。
在本发明中为了支持各种码长,同时为了简化设计,因此考虑采用滑窗长度可变的形式来实现。将初始的188种码块长度翻译成对应的滑窗长度的整数倍,同时考虑到滑窗长度会影响结果的准确性,因此,所分配的滑窗应尽可能的大。另一方面,LTE标准中Turbo码的最小码块长度为40。因此,为了折中,本发明采用256作为最大滑窗长度,也就是说滑窗长度在40~256之间。那么计算滑窗的长度将满足2个条件:
1、滑窗的长度<=256;
2、码块长度是滑窗的长度的整数倍且尽可能的靠近256。
本设计关于滑窗长度的计算在intleav_addr模块中,它是通过事先计算完成之后存储到ROM的高位。因此,在设计中先利用ROM的低位地址找到对应码长的f1,f2参数,然后增加高位地址找到对应码块长度的滑窗长度,从而充分利用ROM空间。
本发明的有益效果是:
本发明提供了一种能够支持LTE标准中188种不同码块长度的Turbo码译码装置和方法。相比于基4Turbo译码算法和装置易受到并行度、初始值计算等因素制约其在Turbo码块长度较短的条件下不能适应的问题,本方法的好处在于通过采用滑窗长度可变的设计从而能够支持LTE标准中188种不同码块长度的码型,同时通过采用核心计算单元模块化的设计思路,降低算法实现占用的计算资源,同时加快算法的译码速度,提高译码的吞吐量。
附图说明
图1基2Turbo码译码器结构示意图;
图2基2Max-Log-MAP算法的滑窗结构;
图3基于滑动窗的基2Turbo码译码装置结构图;
图4基2SISO译码单元的模块计算单元;
图5基2SISO译码的模块计算单元的运算流程;
图6基2Turbo译码装置的性能曲线。
具体实施方式
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例的附图,对本发明中的技术方案进行清楚、完整的描述,显然所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护范围。
本发明实施例公开一种基2Turbo码译码装置和方法,请参见图3,它共包含①输入信息缓存、②外信息缓存、③beta值起始值计算、④系统信息缓存、⑤alpha值缓存、⑥alpha值计算、⑦beta值计算、⑧交织与解交织模块、⑨控制模块和⑩输出计算模块。
①输入信息缓存模块
这一模块主要用于开辟N个缓冲区间用于缓存输入信息,缓存区间的大小为1帧,N可以通过参数IN_BUFFER进行设置;
②外信息缓存模块
由于外信息都是当前计算出来的,同时在取外信息的同时还有其他的控制在写外信息。针对这种情况外信息做了乒乓操作;
③beta值起始值计算模块
由于采用滑窗结构所以需要计算beta的初始值,一般情况下计算的长度为滑窗的长度,但是最后一个滑窗由于尾比特的存在,因此只需要利用尾比特计算4个值就可以得到beta初始值的准确值。同时在这个模块里面完成了读取时候关于系统信息的交织处理;
④系统信息缓存模块
该模块用于缓存滑窗大小的系统信息,由于alpha计算模块,beta计算模块和beta值起始值计算模块都需要操作这个ram,且它们需要用到的系统信息分属于三个相邻的滑窗,因此,在里面做了3个ram的轮寻操作,从而有效的避免了数据存储时候的冲突;
⑤alpha值缓存模块
该模块的ram用于存储alpha计算的中间变量,虽然此时已经不存在交织等操作,但是由于beta值的计算是逆序的,当前alpha计算模块和beta计算模块的输出分别对应的是相邻滑窗的alpha和beta值,因此,要利用它们计算LLR值时,需要存储alpha的值,所以在这个操作里面需要采用乒乓操作;
⑥alpha值计算模块
alpha计算按照alpha运算规则进行计算即可;
⑦beta值计算模块
该模块需要完成计算beta的任务之外还需要完成计算外信息和最大释然信息,以及产生存储外信息和最大释然所需要的解交织地址;
⑧交织与解交织模块
交织与解交织是Turbo码编译码中的一个核心模块,本发明中采用具有伪随机特性的QPP交织器。在Turbo译码过程中,alpha值的计算按顺序进行,而beta值计算按逆向计算,因此,需要产生beta的交织/解交织地址:
Address(i)=f1×i+f2×i2 (6)
Address(i+1)=f1×(i+1)+f2×(i+1)2 (7)
Address(i+1)=(f1×i+f2×i2)+2f2×i+f1+f2 (8)
其中,i=0,1,…,K,K表示译码码块长度,f1和f2为QPP交织器参数。因此,通过上述分析可知,交织/解交织地址可以通过迭代的方式实现,从而可以节约乘法器资源。根据式(8)可知,交织地址的增量为2×f2,初值为f1+f2,对于逆向推导只需要知道当前的地址交织增量为-2×f2就可以推导出所需要的交织地址。因此,在intleav_addr模块中获取f1和f2参数后,将每个滑窗位置的交织地址存储到指定的RAM中,那么无论后续运算到哪个滑窗都可以找出对应的交织地址从而很容易推导出下一个交织地址;
⑨控制模块
控制模块用于控制整个模块的迭代次数,还根据当前Turbo译码属于DEC1还是DEC2,对系统信息和外信息选择交织、解交织操作;
⑩输出计算模块
输出计算模块,只是用于解交织计算,以及完成解扰计算。在解扰计算中,为了减少译码延时,可以利用ram的特性,一次性输出8bit进行并行解扰。
根据上述分析,图3所示基2Turbo译码的核心计算单元可以独立为一个模块,如图4所示。可以看出,无论是当前计算的是顺序地址还是交织地址,这个模块都是可用的,而顺序地址或者说交织地址不同点在于beta初始值计算模块中用到的系统信息和beta值计算模块得到的外信息是否需要加上交织地址抑或是解交织地址。因此,在这种译码框架下,可以将不同地址的计算方式统一了。
滑窗过程的运算流程如图5所示。为了实现滑窗运算过程的流水线处理,首先进行一次beta初始值的计算,这一次计算出的beta初始值不会用到,但是它会将系统信息存储到④系统信息存储模块。而后在同一时刻并行计算相邻滑窗的beta初始值、beta值和alpha值,从而提高系统译码的吞吐量。
图6给出了本发明中的基2Turbo译码器所占用FPGA资源的情况,其中,系统信息、校验信息等采用12比特量化,而alpha值、beta值等则采用16比特量化,Turbo译码迭代4次。可以看出,发明的Turbo译码器占用的资源相对较少。
不同Turbo码块长度门限信噪比的情况图给出了发明的Turbo译码装置不同Turbo码块长度的码型在满足误比特率小于10e-3的条件下其门限信噪比的情况。仿真中的信号为QPSK调制信号,可以看出,信噪比阈值的实测曲线与趋势分析曲线基本一致,当码块长度较小时,其门限信噪比比较高,例如,当码长为48时,信噪比阈值为2.01dB;而当码块长度较小时,其门限信噪比相对要低一些,例如,当码块长度为2944、3072、4224、5696、6016等,其门限信噪比仅为-1dB。
- 还没有人留言评论。精彩留言会获得点赞!