一种低复杂度近似最大似然的多元LDPC码译码方法与流程
本发明属于无线通信技术领域,更进一步涉及信道编码技术领域中一种低复杂度近似最大似然的多元低密度奇偶检验ldpc(low-densityparity-check)码译码方法。本发明可用于机器类通信、远程指令链路和智能测量网络等短帧长应用领域中的差错控制译码。
背景技术:
多元低密度奇偶校验ldpc码自提出以来就引起了研究人员的关注。现有的研究结果表明,相比于二元低密度奇偶校验ldpc码,多元低密度奇偶校验ldpc码具有更好的纠错性能、更强的抗突发错误能力和更高的数据传输速率。
鉴于多元低密度奇偶校验ldpc码的上述优点,人们对多元低密度奇偶校验ldpc码的编译码方案做了许多研究。其中针对多元低密度奇偶校验ldpc码的译码方面,人们提出了多元和积译码算法qspa(q-arysum-productalgorithm)、基于快速傅里叶变换的多元和积译码算法fft-qspa(fastfouriertransformbasedq-arysum-productalgorithm)以及扩展最小和ems(extendedmin-sum)算法等迭代译码算法。由于低密度奇偶校验ldpc码的tanner图中存在环,迭代译码算法成为了低密度奇偶校验ldpc码的一种次优译码算法。当迭代译码算法陷入陷阱集时,算法将不会收敛,进而导致译码失败。
北京航空航天大学在其申请的专利文献“低复杂度的多进制ldpc码译码方法”(申请公告日:2014年9月17日,申请公告号:cn104052501a)中公开了一种低复杂度的多进制低密度奇偶检验ldpc码译码方法。该专利申请中的译码方法在迭代中采用多进制符号的二进制表示简化码字信息置信度的表示方式,每次迭代通过校验节点的计算更新边信息的置信度,在变量节点的计算中引入加权加强变量节点对边信息的使用效率,并且采用二进制的信息更新方式计算码字信息和外信息。该发明码字每个符号的信息长度远低于现有方法中的长度,边信息仅有一个有限域符号及其置信度,具有很低的存储复杂度,变量节点和校验节点的计算主要为整数加法和整数比较运算,只有少量的有限域运算和乘法运算,具有很低的计算复杂度。该方法虽然较之传统置信度传播bp(beliefpropagation)译码方法在一定程度上降低了译码复杂度,但是,该方法仍然存在的不足之处是,陷入陷阱集后译码不收敛,导致译码失败。
baldi等人在其发表的论文“ahybriddecodingschemeforshortnon-binaryldpccodes”(ieeecommunicationsletters,2014:2093-2096.)中提出了一种针对短码长多元低密度奇偶校验ldpc码的混合译码方法。该方法将置信度传播bp(beliefpropagation)方法和分级统计译码osd(orderedstatisticdecoding)方法结合,很大程度上解决了迭代译码算法陷入陷阱集不收敛的问题,得到了近似最大似然的译码性能。该方法存在的不足之处是:分级统计译码osd方法获取单个候选码字的计算复杂度较高而且需要获取的候选码字数量大,导致混合译码方法的整体计算复杂度高,译码效率低。
技术实现要素:
本发明的目的在于针对上述已有技术的不足,提出一种低复杂度近似最大似然的多元低密度奇偶校验ldpc码译码方法,以较低复杂度解决了迭代译码算法陷入陷阱集不收敛的问题。
为了实现上述目的,本发明方法的思路是:首先采用基于快速傅里叶变换的和积算法fft-qspa对加噪的消息进行迭代译码,如果基于快速傅里叶变换的和积算法fft-qspa陷入陷阱集,不能在最大迭代次数内找到合法码字,那么再利用二元列表纠删译码led(listerasuredecoder)算法译码,从而使本方法达到近似最大似然的译码性能。
本发明方法的实现步骤如下:
(1)设置译码最大迭代次数i=100;
(2)进行迭代译码:
(2a)对多元低密度奇偶校验ldpc码进行二进制相移键控bpsk调制后,将调制后的信息送入加性高斯白噪声awgn信道进行加噪处理,得到加噪后的消息;
(2b)采用基于快速傅里叶变换的和积算法fft-qspa,对加噪后的消息进行迭代译码;
(3)判断在基于快速傅里叶变换的和积算法fft-qspa最大迭代次数内是否找到合法码字,若是,则执行步骤(19),否则,执行步骤(4);
(4)多元形式到二元形式的转换:
(4a)将基于快速傅里叶变换的和积算法fft-qspa的第
(4b)将基于快速傅里叶变换的和积算法fft-qspa的第
(4c)将基于有限域g(q)构造的多元低密度奇偶校验ldpc码的多元校验矩阵中的每一个元素h∈gf(q),替换为与其对应的矩阵表示形式,得到多元校验矩阵对应的二元校验矩阵,其中,h表示多元校验矩阵中的元素,q表示有限域gf(q)中元素的个数,∈表示属于符号;
(5)挑选删除比特位:
(5a)对二元消息向量的分量按绝对值的大小,从小到大排序,得到排序后的消息向量;
(5b)将排序后的消息向量前l1位对应的比特位依次标记为删除位,将这些删除位加入删除比特集合中;
(6)将挑选附加删除位的次数初始化为零;
(7)判断挑选附加删除位的次数是否等于最大挑选次数,若是,则执行步骤(19),否则,执行步骤(8);
(8)将挑选附加删除位的次数加1后,从排序后消息向量的第l1位分量对应的比特位到第l1+2l2位分量对应的比特位中,依次随机挑选l2个比特位,作为附加删除位,将这些附加删除位加入到删除比特集合中;
(9)对二元判决序列进行比特删除操作:
将步骤(4b)得到的二元判决序列,按照删除比特集合中的删除位进行比特删除操作,得到删除序列;
(10)对删除序列进行二元列表纠删译码:
利用二元列表纠删译码led算法,对删除序列进行译码,得到译码序列和残余删除比特集合;
(11)将比特翻转次数初始化为零;
(12)判断比特翻转次数是否等于最大比特翻转次数,若是,则执行步骤(14),否则,执行步骤(13);
(13)将二元列表纠删译码led算法输出的译码序列,按照残余删除比特集合中的比特位进行一次比特翻转,得到一个候选码字,将该候选码字列入候选码字列表中,将比特翻转次数加1后,执行步骤(12);
(14)确定当前欧氏最小距离:
(14a)按照下式,计算候选码字列表中的每一个候选码字的欧氏距离:
其中,uk表示候选码字列表中的第k个候选码字的欧氏距离,
(14b)找出所有候选码字中欧氏距离最小的候选码字后,将该欧氏距离作为当前最小欧氏距离;
(15)判断挑选附加删除位的次数是否为零,若是,则执行步骤(16),否则执行步骤(17);
(16)判断当前最小欧氏距离是否小于初始门限欧氏距离为106,若是,则执行步骤(18),否则,从步骤(8)得到的删除比特集合中去除附加删除比特后,返回步骤(7);
(17)判断当前最小欧氏距离是否小于当前门限欧氏距离,若是,则执行步骤(18),否则,从步骤(8)得到的删除比特集合中去除附加删除比特后,执行步骤(7);
(18)将当前最小欧氏距离的值赋给当前门限欧式距离后,执行步骤(7);
(19)译码结束:
将译码输出的估计码字取值为步骤(14b)中得到的当前欧氏距离最小的候选码字,译码结束。
本发明与现有技术相比具有以下优点:
第一,由于本发明将二元列表纠删译码led算法输出的译码序列,按照残余删除比特集合中的比特位进行比特翻转,克服了现有技术的迭代译码算法陷入陷阱集后译码不收敛,导致译码失败的问题,从而使得本发明获得了近似最大似然的性能。
第二,由于本发明利用二元列表纠删译码led算法对删除序列进行译码,得到的残余删除比特集合具有较少的元素个数,使得获取单个候选码字的复杂度降低和候选码字列表的元素个数减少,克服了现有技术获取单个候选码字的复杂度较高且需要获取的候选码字数量大,导致混合译码方法的整体计算复杂度高,译码效率低的问题,使得本发明以较低的复杂度达到了近似最大似然的性能。
附图说明
图1是本发明的流程图;
图2是采用本发明方法与现有技术方法的译码性能对比图;
图3是采用本发明方法与现有技术方法的译码复杂度对比图。
具体实施方式
下面结合附图对本发明做进一步描述。
参照附图1,对本发明的实现方法做进一步描述。
步骤1,设置译码最大迭代次数i=100。
步骤2,进行迭代译码。
对多元低密度奇偶校验ldpc码进行二进制相移键控bpsk调制后,将调制后的信息送入加性高斯白噪声awgn信道进行加噪处理,得到加噪后的消息。
采用基于快速傅里叶变换的和积算法fft-qspa,对加噪后的消息进行迭代译码。
步骤3,判断在基于快速傅里叶变换的和积算法fft-qspa最大迭代次数内是否找到合法码字,若是,则执行步骤(19),否则,执行步骤(4)。
所述的合法码字是指满足下列关系的序列:
h·v=0
其中,h表示多元低密度奇偶校验ldpc码的校验矩阵,v表示合法码字,·表示矩阵相乘操作。
步骤4,多元形式到二元形式的转换。
将基于快速傅里叶变换的和积算法fft-qspa的第2次迭代输出的多元消息向量转换成对应的二元消息向量。
将基于快速傅里叶变换的和积算法fft-qspa的第2次迭代输出的多元判决序列,转换成对应的二元判决序列。
将基于有限域g(q)构造的多元低密度奇偶校验ldpc码的多元校验矩阵中的每一个元素h∈gf(q),替换为与其对应的矩阵表示形式,得到多元校验矩阵对应的二元校验矩阵,其中,h表示多元校验矩阵中的元素,q表示有限域gf(q)中元素的个数,∈表示属于符号。
所述的多元校验矩阵转换成对应的二元校验矩阵步骤如下:
第一步,对于任意的0≤i≤q-2,有限域gf(q)中的元素αi的矩阵表示形式为ai,ai表示矩阵a的i次方,a定义为:
其中,q表示有限域gf(q)中元素的总数,q=2p,p表示本原多项式的系数的个数,α表示有限域gf(q)的本原元素,fj表示有限域gf(q)的本原多项式的第j个系数,j表示本原多项式的第j个系数的下标,j∈[0,p-1],∈表示属于符号;
第二步,将基于有限域g(q)构造的多元低密度奇偶校验ldpc码的多元校验矩阵中的每一个元素h∈gf(q),替换为与其对应的矩阵表示形式,其中,h表示多元校验矩阵中的元素。
步骤5,挑选删除比特位。
对二元消息向量的分量按绝对值的大小,从小到大排序,得到排序后的消息向量。
将排序后的消息向量前l1位对应的比特位依次标记为删除位,将这些删除位加入删除比特集合中。
步骤6,将挑选附加删除位的次数初始化为零。
步骤7,判断挑选附加删除位的次数是否等于最大挑选次数,若是,则执行步骤(19),否则,执行步骤(8)。
步骤8,将挑选附加删除位的次数加1后,从排序后消息向量的第l1位分量对应的比特位到第l1+2l2位分量对应的比特位中,依次随机挑选l2个比特位,作为附加删除位,将这些附加删除位加入到删除比特集合中。
所述l1和l2是指满足下列关系的整数:
l1+2l2≤n(l1>0,l2≥0)
其中,l1表示初始删除比特个数,l2表示附加删除比特的个数,n表示编码长度。
步骤9,对二元判决序列进行比特删除操作。
将步骤(4b)得到的二元判决序列,按照删除比特集合中的删除位进行比特删除操作,得到删除序列。
步骤10,对删除序列进行二元列表纠删译码。
利用二元列表纠删译码led算法,对删除序列进行译码,得到译码序列和残余删除比特集合。
步骤11,将比特翻转次数初始化为零。
步骤12,判断比特翻转次数是否等于最大比特翻转次数,若是,则执行步骤(14),否则,执行步骤(13)。
所述最大比特翻转次数是由下式得到:
其中,jmax表示最大比特翻转次数,min表示取最小值操作,∑表示求和操作,l表示残余删除比特集合中删除比特的个数,
步骤13,将二元列表纠删译码led算法输出的译码序列,按照残余删除比特集合中的比特位进行一次比特翻转,得到一个候选码字,将该候选码字列入候选码字列表中,将比特翻转次数加1后,执行步骤(12)。
步骤14,确定当前欧氏最小距离。
按照下式,计算候选码字列表中的每一个候选码字的欧氏距离:
其中,uk表示候选码字列表中的第k个候选码字的欧氏距离,
找出所有候选码字中欧氏距离最小的候选码字后,将该欧氏距离作为当前最小欧氏距离。
步骤15,判断挑选附加删除位的次数是否为零,若是,则执行步骤(16),否则执行步骤(17)。
步骤16,判断当前最小欧氏距离是否小于初始门限欧氏距离为106,若是,则执行步骤(18),否则,从步骤(8)得到的删除比特集合中去除附加删除比特后,返回步骤(7)。
步骤17,判断当前最小欧氏距离是否小于当前门限欧氏距离,若是,则执行步骤(18),否则,从步骤(8)得到的删除比特集合中去除附加删除比特后,执行步骤(7)。
步骤18,将当前最小欧氏距离的值赋给当前门限欧式距离后,执行步骤(7)。
步骤19,译码结束。
将译码输出的估计码字取值为步骤(14b)中得到的当前欧氏距离最小的候选码字,译码结束。
本发明的效果可通过以下仿真进一步说明:
1.仿真条件:
本发明的实验仿真选用ccsds标准中gf(256)上码率为1/2码长为16的多元低密度奇偶检验ldpc码。表1是本发明方法所使用的仿真参数。表1中参数包括信噪比、初始删除比特个数l1、附加删除比特的个数l2和最大挑选次数ni。
2.仿真内容:
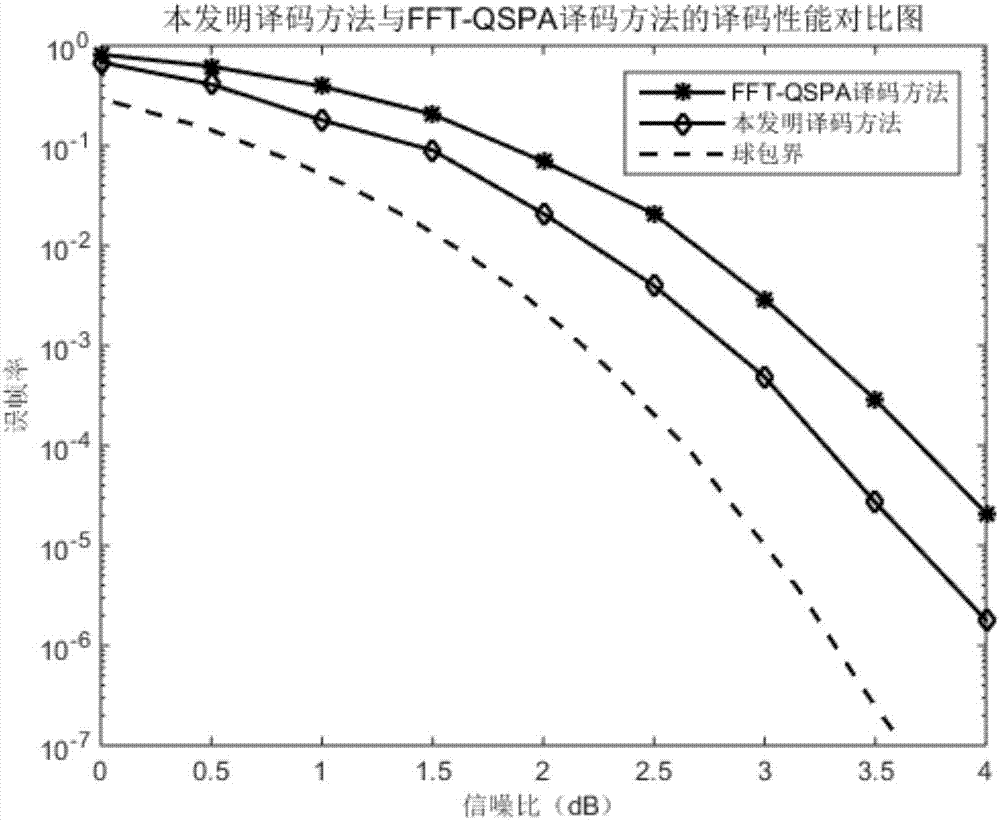
仿真1.对ccsds标准中gf(256)上码率为1/2码长为16的多元低密度奇偶检验ldpc码进行二进制相移键控bpsk调制,再经过加性高斯白噪声awgn信道加噪处理,最后分别采用本发明方法和现有技术方法进行译码,仿真结果如图2所示。
图2中以星形标记的曲线表示在加性高斯白噪声awgn信道下,基于快速傅里叶变换的和积算法fft-qspa在不同信噪比下的误帧率。
图2中虚线表示gf(256)上码率为1/2码长为16的多元低密度奇偶检验ldpc码的香农球包界。
图2中以菱形标示的曲线表示在加性高斯白噪声awgn信道下,本发明译码方法在不同信噪比下的误帧率。
由图2可以看出,在误帧率为10-4时,本发明方法与基于快速傅里叶变换的和积算法fft-qspa相比有0.4db的性能增益。相比于基于快速傅里叶变换的和积算法fft-qspa距离香农球包界1db左右的性能差距,本发明方法将与香农球包界的性能差距缩短至了0.6db。可见,本发明相比传统迭代译码算法具有更优的译码性能,达到了近似最大似然的译码性能。
仿真2.对ccsds标准中gf(256)上码率为1/2码长为16的多元低密度奇偶检验ldpc码进行二进制相移键控bpsk调制,再经过加性高斯白噪声awgn信道加噪处理,最后分别采用本发明方法和现有技术方法进行译码,译码复杂度如图3所示。
图3中以圆形标示的曲线表示在加性高斯白噪声信道awgn下,现有近似最大似然译码方法在不同信噪比下的平均二元操作次数。
图3中以叉形标示的曲线表示在加性高斯白噪声信道awgn下,现有本发明的译码方法在不同信噪比下的平均二元操作次数。
由图3可以看出,当信噪比较小,如信噪比等于0.5db时,现有近似最大似然译码方法平均需要4×109次二元操作,才能完成译码。而本发明的译码方法平均只需要8×107次二元操作,即可完成译码。可见,本发明译码方法的复杂度是现有近似最大似然译码方法复杂度的
由图3可以看出,当信噪比适中,如信噪比等于2.0db时,现有近似最大似然译码方法平均需要4×108次二元操作,才能完成译码。而本发明的译码方法平均只需要4×107次二元操作,即可完成译码。可见,本发明译码方法的复杂度是现有近似最大似然译码方法复杂度的
由图3可以看出,当信噪比适中,如信噪比等于4.0db时,现有近似最大似然译码方法与本发明的译码方法都平均需要1×106次二元操作,才能完成译码。由此可见,本发明的译码方法较之现有近似最大似然译码有复杂度低的特点。
表1本发明方法的仿真参数
- 还没有人留言评论。精彩留言会获得点赞!