基于多元LDPC码噪声增强的符号翻转译码方法与流程
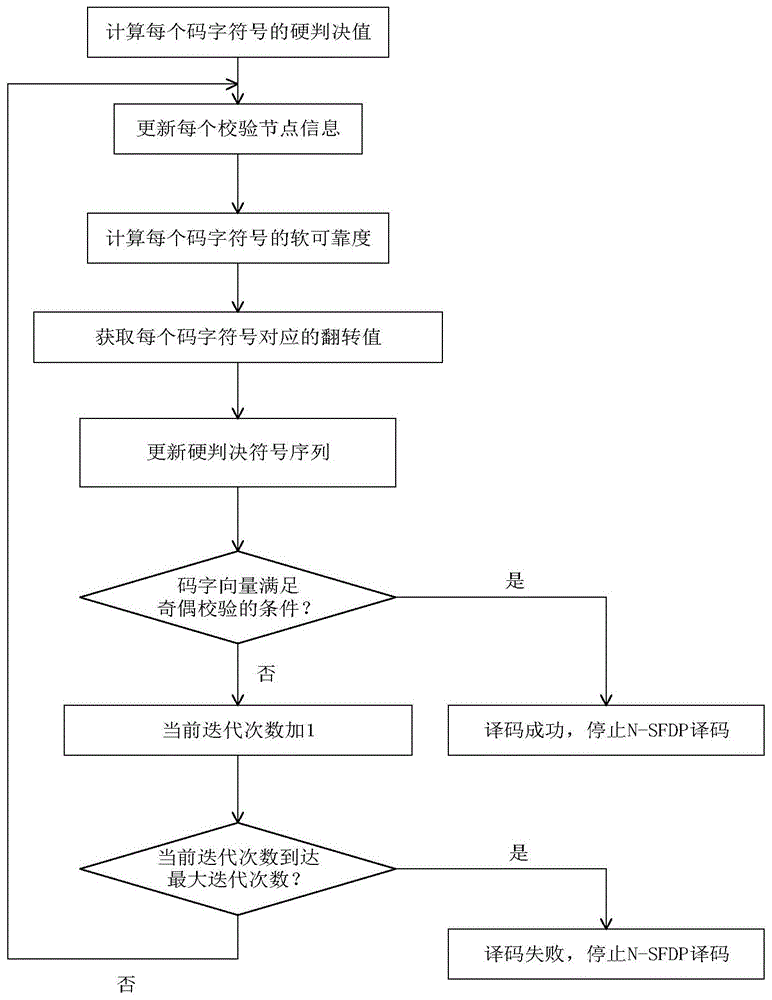
本发明属于通信技术领域,更进一步涉及信道编码技术领域中一种基于多元低密度奇偶检验ldpc(low-densityparity-checkcodes)码噪声增强的符号翻转译码sfd(symbolflippingdecoding)方法。本发明可实现对大数逻辑预测的多元低密度奇偶检验ldpc码进行符号翻转译码。
背景技术:
具有低译码复杂度和逼近香农限良好性能的低密度奇偶校验ldpc码已经被广泛应用于现代通信的深空通信、无线通信等领域中,并被802.11n、802.16e、10gbase-t等各种现代通信标准采纳。因此,低密度奇偶校验ldpc码及其译码方法已经成为近年来信道编码领域普遍关注的研究热点。对于短分组长度到中等分组长度的低密度奇偶校验ldpc码,多元低密度奇偶校验ldpc码的误比特率ber(biterrorrate)性能优于二元低密度奇偶校验ldpc码。然而传统的多元低密度奇偶校验ldpc码译码方法的不足之处是:译码复杂度较高,或者译码复杂度低但译码性能存在一定程度的损失。
广西大学在其申请的专利文献“一种基于硬可靠度信息的多元ldpc码译码方法”(申请公布日:2016年2月14日,申请公布号:cn105763203a,申请号:2016100846156)中公开了一种多元低密度奇偶校验ldpc码的译码方法。该方法通过将硬判决符号向量中每个二进制硬判决符号的可靠度按比特位进行整数化,在每次迭代中根据每个硬判决符号的可靠度确定每个二进制硬判决符号的取值,并进行译码校验,对变量节点通过按比特位加权的方式更新外信息及其可靠度后,进行下一次迭代,从而能够降低多元低密度奇偶校验ldpc译码的复杂度和存储负荷。该方法存在的不足之处是:译码过程中对于每个变量节点,根据其接收到的外信息与硬判决符号所对应的二进制表示之间的汉明距离对每个二进制硬判决符号的可靠度按比特位进行加权,使得更新变量节点外信息的复杂度较高。
qinhuang等人在其发表的论文“symbolflippingdecodingalgorithmsbasedonpredictionfornon-binaryldpccodes”(ieeetrans.commun.,2017,65,(5),pp.1913-1924.)中提出了一种基于大数逻辑预测的多元低密度奇偶校验ldpc码的符号翻转译码sfdp(symbolflippingdecodingalgorithmbasedonprediction)方法。该方法通过构造包含来自信道的软可靠度信息和来自校验节点的基于校验的硬可靠度信息的符号翻转目标函数,使得符号翻转译码sfd方法的翻转度量同时考虑到符号翻转前与符号翻转后的信息,从而使译码的错误性能大大提高。该方法存在的不足之处是:对于环长为6的多元低密度奇偶校验ldpc码,基于大数逻辑预测的符号翻转译码sfdp方法在高信噪比snr(signal-to-noiseratio)区域下会出现错误平层,并且该方法中没有具体说明如何选择与大数逻辑相关的权重系数。
技术实现要素:
本发明的目的在于针对上述已有技术的不足,提出一种基于多元低密度奇偶校验ldpc码噪声增强的符号翻转译码n-sfdp方法,用于解决译码性能低,误比特率低,以及如何选择与大数逻辑相关的权重系数的问题。
实现本发明目的的思路是:通过改变sfdp译码方法的翻转度量,将随机噪声扰动引入sfdp译码方法的目标函数中,从而增加sfdp译码方法逃离不期望的局部最大值的概率,大大提高译码性能。改变基于大数逻辑预测的符号翻转译码sfdp方法的翻转度量,将随机噪声扰动引入基于大数逻辑预测的符号翻转译码sfdp方法的目标函数中,动态地选择基于大数逻辑预测的符号翻转译码sfdp方法中与大数逻辑相关的权重系数,从而增加了现有技术的基于大数逻辑预测的符号翻转译码sfdp方法中目标函数逃离不期望的局部最大值的概率,大大提高译码器的误比特率性能,同时克服了当被翻转的硬判决符号具有较小的二进制汉明距离时,现有技术的基于大数逻辑预测的符号翻转译码sfdp方法在中高信噪比下易陷入局部陷阱集的缺点,从而降低环长为6的多元低密度奇偶校验ldpc码的错误平层,提高译码性能。
本发明方法的实现包括如下步骤:
步骤1,按照下式,计算初始迭代时加性高斯白噪声信道接收的每个码字符号的硬判决值:
其中,
步骤2,更新每个校验节点的信息:
第一步,按照下式,计算当前迭代时从校验节点传递给变量节点的外信息和:
其中,
第二步,用当前迭代时从校验节点传递给变量节点的外信息和,更新每个校验节点在当前迭代时的信息;
步骤3,利用软可靠度公式,根据加性高斯白噪声信道接收的信息,计算多元低密度奇偶检验ldpc码在当前迭代时每个码字符号的软可靠度;
步骤4,获取多元低密度奇偶检验ldpc码在当前迭代时每个码字符号对应的翻转值:
第一步,按照下式,计算多元低密度奇偶检验ldpc码在当前迭代时每个码字符号的翻转度量:
其中,
第二步,选择多元低密度奇偶检验ldpc码在当前迭代时每个码字符号翻转度量的最大值作为该码字符号的可靠度;
第三步,利用翻转目标函数,计算多元低密度奇偶检验ldpc码在当前迭代时每个码字符号的翻转目标函数值;
第四步,利用翻转公式,计算多元低密度奇偶检验ldpc码在当前迭代时每个码字符号的翻转值;
步骤5,更新多元低密度奇偶检验ldpc码在当前迭代时的硬判决符号序列:
第一步,取当前迭代时每个码字符号的翻转目标函数值最大值所对应的码字符号的序号,作为当前迭代时待翻转的码字符号的序号,若该序号与前一次迭代时翻转的码字符号的序号相等,则取当前迭代时每个码字符号的翻转目标函数值中第二大值所对应的码字符号的序号,作为当前迭代时待翻转的码字符号的序号;
第二步,用当前迭代时待翻转的码字符号的序号所对应的翻转值更新该序号所对应的硬判决值;
步骤6,判断当前迭代的码字向量是否满足停止译码条件,若是,则执行步骤7,否则,执行步骤2;
步骤7,译码成功。
本发明与现有技术相比具有以下优点:
第一,由于本发明通过改变sfdp译码方法的翻转度量计算公式,将随机噪声扰动引入sfdp译码方法的目标函数中,克服了现有技术译码复杂度较高,或者译码复杂度低但译码性能存在一定程度的损失的缺点,从而增加了现有技术的sfdp译码方法逃离不期望的局部最大值的概率,使得本发明大大地提高了译码性能。
第二,由于本发明使用随机噪声扰动,动态地改变sfdp译码方法中与大数逻辑相关的权重系数,克服了译码过程中更新变量节点外信息的复杂度较高的缺点,从而增加了现有技术的基于大数逻辑预测的符号翻转译码sfdp方法中目标函数逃离不期望的局部最大值的概率,使得本发明大大地提高了译码器的误比特率性能。
第三,由于本发明采用动态的随机噪声扰动方式,对于不同的多元ldpc码,在不同信噪比snr下,选择相应不同的权重系数,克服了现有技术sfdp方法在高信噪比snr(signal-to-noiseratio)区域下会出现错误平层,在中高信噪比情况下易陷入局部陷阱集,并且没有具体说明如何选择与大数逻辑相关的权重系数的缺点,使得本发明能够在某些多元ldpc码中降低错误平层,选择了更好的权重系数,降低了译码的错误性能。
附图说明
图1是本发明的流程图;
图2是本发明与现有方法在snr=5.0db时译码结果对比图;
图3是本发明与现有方法针对码c1的译码性能对比图和译码收敛速度对比图;
图4是本发明与现有方法针对码c2的译码性能对比图和译码收敛速度对比图。
具体实施方式
下面结合附图对本发明做进一步描述。
下面结合附图1,对本发明的具体步骤做进一步描述。
步骤1,按照下式,计算初始迭代时加性高斯白噪声信道接收的每个码字符号的硬判决值:
其中,
步骤2,更新每个校验节点的信息:
第一步,按照下式,计算当前迭代时从校验节点传递给变量节点的外信息和:
其中,
第二步,用当前迭代时从校验节点传递给变量节点的外信息和,更新每个校验节点在当前迭代时的信息。
步骤3,利用下述软可靠度公式,根据加性高斯白噪声信道接收的信息,计算多元低密度奇偶检验ldpc码在当前迭代时每个码字符号的软可靠度:
其中,
步骤4,获取多元低密度奇偶检验ldpc码在当前迭代时每个码字符号对应的翻转值。
第一步,按照下式,计算多元低密度奇偶检验ldpc码在当前迭代时每个码字符号的翻转度量:
其中,
其中,添加的噪声扰动
第一种是均值为0,分布区间为[-a,a]的均匀随机变量。
第二种是均值为0,方差为σ2=λ2n0/2的高斯随机变量。其中,σ2表示方差,λ表示噪声规模参数,λ的取值范围为0<λ≤1,n0/2表示高斯函数的双边功率谱密度。所有高斯随机变量都是独立同分布的。
第二步,选择多元低密度奇偶检验ldpc码在当前迭代时每个码字符号翻转度量的最大值作为该码字符号的可靠度。
第三步,利用下述翻转目标函数,计算多元低密度奇偶检验ldpc码在当前迭代时每个码字符号的翻转目标函数值:
其中,
第四步,利用下述翻转公式,计算多元低密度奇偶检验ldpc码在当前迭代时每个码字符号的翻转值:
其中,
步骤5,更新多元低密度奇偶检验ldpc码在当前迭代时的硬判决符号序列:
第一步,取当前迭代时每个码字符号的翻转目标函数值最大值所对应的码字符号的序号,作为当前迭代时待翻转的码字符号的序号,若该序号与前一次迭代时翻转的码字符号的序号相等,则取当前迭代时每个码字符号的翻转目标函数值中第二大值所对应的码字符号的序号,作为当前迭代时待翻转的码字符号的序号。
第二步,用当前迭代时待翻转的码字符号的序号所对应的翻转值更新该序号所对应的硬判决值。
步骤6,判断当前迭代的码字向量是否满足停止译码条件,若是,则执行步骤7,否则,执行步骤2。
所述的停止译码条件是指满足以下的两个条件中的任意一种情形:
条件1:码字向量与多元低密度奇偶校验ldpc码的奇偶校验矩阵的转置的乘积为零向量。
条件2:基于噪声增强的符号翻转译码n-sfdp译码迭代次数达到100。
步骤7,译码成功。
下面结合仿真实验对本发明的效果做进一步的说明:
1.仿真实验条件:
本发明的仿真实验的硬件平台为:处理器为inteli75930kcpu,主频为3.5ghz,内存16gb。
本发明的仿真实验的软件平台为:windows7操作系统,microsoftvisualc++6.0,matlab2017。
本发明仿真实验所使用的噪声扰动分别为高斯噪声和均匀噪声,在加性高斯白噪声信道下,利用sfdp译码对码率为1/2长度为204的16元ldpc码c1和码率为1/2长度为384的64元ldpc码c2进行仿真,译码分别采用现有的sfdp译码方法和本发明提出的n-sfdp译码方法。
2.仿真内容及其结果分析:
本发明仿真实验是采用本发明和一个现有技术(基于预测的多元ldpc码符号翻转译码sfdp方法)分别进行了三个仿真实验:
实验一,采用本发明和现有技术方法分别对针对码率为1/2长度为204的16元ldpc码c1在snr=5.0db时进行仿真,获得译码结果对比图,如图2所示。
实验二,采用本发明和现有技术方法分别对针对码率为1/2长度为204的16元ldpc码c1进行仿真,获得译码性能对比图和译码收敛速度对比图,如图3所示。
实验三,采用本发明和现有技术方法分别对针对码率为1/2长度为384的64元ldpc码c2进行仿真,获得译码性能对比图和译码收敛速度对比图,如图4所示。
在仿真实验中,采用的一个现有技术是指:
qinhuang等人在其发表的论文“symbolflippingdecodingalgorithmsbasedonpredictionfornon-binaryldpccodes”(ieeetrans.commun.,2017,65,(5),pp.1913-1924.)中提出了一种基于大数逻辑预测的多元低密度奇偶校验ldpc码的符号翻转译码sfdp(symbolflippingdecodingalgorithmbasedonprediction)方法。
下面结合图2对本发明的效果做进一步的描述。
图2是本发明与现有方法针对码c1在snr=5.0db时译码结果对比图。图2表示针对码c1,在snr=5.0db时,现有技术sfdp译码方法与本发明引入均匀噪声扰动时n-sfdp译码方法的译码结果对比图。图2中的横坐标表示码c1在16元有限域内译码错误符号的位置索引,对应的位置索引范围为[0,203],纵坐标表示由两种译码方法得到的码字中错误符号的硬判决值。图2中以实心圆圈标识的点表示现有方法sfdp译码方法译码得到的码字中的错误符号。图2中以正方形标识的点表示本发明提出的n-sfdp译码方法针对码c1在snr=5.0db时译码得到的码字中的错误符号。
由图2可以看出,现有方法的sfdp译码方法针对码c1在snr=5.0db时译码得到的码字中错误符号的硬判决值大多数为{1,2,4,8},它们对应的二进制表示分别为(1)16=(0001)2,(2)16=(0010)2,(4)16=(0100)2,(8)16=(1000)2,这四个值的二进制汉明权重都是1。这说明当汉明权重比较小的符号被翻转为其他符号时,现有方法的sfdp译码方法容易陷入局部错误集。本发明提出的n-sfdp译码方法针对码c1在snr=5.0db时译码得到的码字中仅有一少部分错误符号。图2说明了随机噪声对sfdp译码方法纠错能力的影响,翻转度量的噪声扰动可以有效纠正陷入局部错误集的符号。
下面结合图3对本发明的效果做进一步的描述。
图3(a)是本发明与现有方法针对码c1的译码性能对比图。图3(a)表示现有技术sfdp译码方法与本发明引入不同噪声扰动时n-sfdp译码方法的误比特率ber性能对比图。n-sfdp译码引入的噪声分别为高斯噪声和均匀噪声。图3(a)中的横坐标表示信噪比snr,纵坐标表示误比特率ber。图3(a)中以三角形标识的曲线表示现有技术的sfdp译码方法针对码c1的误比特率ber性能。图3(a)中以五角星标识的曲线表示本发明提出的n-sfdp译码方法引入高斯噪声时针对码c1的误比特率ber性能。图3(a)中以米字形标识的曲线表示本发明提出的n-sfdp译码方法引入均匀噪声时针对码c1的误比特率ber性能。
由图3(a)可以看出,与现有技术的sfdp译码方法相比,本发明提出的n-sfdp译码方法引入不同噪声扰动时可以明显提高译码性能,尤其是在高信噪比区域下。如误比特率ber≈10-6时,与现有技术的sfdp译码方法相比,本发明提出的n-sfdp译码方法在引入高斯噪声时可以获得0.95db的信噪比增益,引入均匀噪声时可以获得0.9db的信噪比增益。
由图3(a)可以看出,与现有技术的sfdp译码方法相比,本发明提出的n-sfdp译码方法引入不同噪声扰动时可以在高信噪比区域下降低错误平层。如误比特率ber≈10-7时,现有技术的sfdp译码方法存在错误平层,而本发明提出的n-sfdp译码方法在引入高斯噪声或者均匀噪声时并没有明显的错误平层。
图3(b)是本发明与现有方法针对码c1的译码收敛速度对比图。图3(b)表示现有技术sfdp译码方法与本发明引入不同噪声扰动时n-sfdp译码方法对应不同误比特率ber性能的平均迭代次数(averagenumberofiterations,anis)对比图。n-sfdp译码引入的噪声分别为高斯噪声和均匀噪声。图3(b)中的横坐标表示误比特率ber,纵坐标表示平均迭代次数anis。图3(b)中以三角形标识的曲线表示现有技术的sfdp译码方法针对码c1的平均迭代次数anis。图3(b)中以五角星标识的曲线表示本发明提出的n-sfdp译码方法引入高斯噪声时针对码c1的平均迭代次数anis。图3(b)中以米字形标识的曲线表示本发明提出的n-sfdp译码方法引入均匀噪声时针对码c1的平均迭代次数anis。
由图3(b)可以看出,与现有技术的sfdp译码方法相比,在相同的误比特率ber性能下,本发明提出的n-sfdp译码方法引入高斯噪声或者均匀噪声时译码的平均迭代次数都比较高。但本发明提出的n-sfdp译码方法可以在低误比特率ber值下明显降低信噪比snr,也就是当译码方法处于相似的计算复杂度时,本发明提出的n-sfdp译码方法通常会有更低的误比特率ber性能。如当平均迭代次数等于30时,现有技术的sfdp译码方法的误比特率ber约等于10-5,而本发明提出的n-sfdp译码方法引入不同噪声时误比特率ber都可以降低到约等于10-7。
下面结合图4的仿真图对本发明的效果做进一步的描述。
图4(a)是本发明与现有方法针对码c2的译码性能对比图。图4(a)表示现有技术sfdp译码方法与本发明引入不同噪声扰动时n-sfdp译码方法的误比特率ber性能对比图。n-sfdp译码引入的噪声分别为高斯噪声和均匀噪声。图4(a)中的横坐标表示信噪比snr,纵坐标表示误比特率ber。图4(a)中以三角形标识的曲线表示现有技术的sfdp译码方法针对码c2的误比特率ber性能。图4(a)中以五角星标识的曲线表示本发明提出的n-sfdp译码方法引入高斯噪声时针对码c2的误比特率ber性能。图4(a)中以米字形标识的曲线表示本发明提出的n-sfdp译码方法引入均匀噪声时针对码c2的误比特率ber性能。
由图4(a)可以看出,与现有技术的sfdp译码方法相比,本发明提出的n-sfdp译码方法引入不同噪声扰动时可以提高译码性能,尤其是在高信噪比区域下。如误比特率ber≈10-6时,与现有技术的sfdp译码方法相比,本发明提出的n-sfdp译码方法在引入高斯噪声时可以获得0.6db的信噪比增益,引入均匀噪声时可以获得0.5db的信噪比增益。
图4(b)是本发明与现有方法针对码c2的译码收敛速度对比图。图4(b)表示现有技术sfdp译码方法与本发明引入不同噪声扰动时n-sfdp译码方法对应不同误比特率ber性能的平均迭代次数anis对比图。n-sfdp译码引入的噪声分别为高斯噪声和均匀噪声。图4(b)中的横坐标表示误比特率ber,纵坐标表示平均迭代次数anis。图4(b)中以三角形标识的曲线表示现有技术的sfdp译码方法针对码c2的平均迭代次数anis。图4(b)中以五角星标识的曲线表示本发明提出的n-sfdp译码方法引入高斯噪声时针对码c2的平均迭代次数anis。图4(b)中以米字形标识的曲线表示本发明提出的n-sfdp译码方法引入均匀噪声时针对码c2的平均迭代次数anis。
由图4(b)可以看出,与现有技术的sfdp译码方法相比,在相同的误比特率ber性能下,本发明提出的n-sfdp译码方法引入高斯噪声或者均匀噪声时译码的平均迭代次数都比较高。但本发明提出的n-sfdp译码方法可以在低误比特率ber值下明显降低信噪比snr,也就是当译码方法处于相似的计算复杂度时,本发明提出的n-sfdp译码方法通常会有更低的误比特率ber性能。如当平均迭代次数等于40时,现有技术的sfdp译码方法的误比特率ber约等于10-5,而本发明提出的n-sfdp译码方法引入不同噪声时误比特率ber都可以降低到约等于10-7。
以上仿真实验表明:本发明方法利用随机噪声对翻转度量的噪声扰动,能够有效纠正陷入局部错误集的符号,尤其是在高信噪比区域下,利用引入不同噪声扰动,能够明显提高译码性能,获得信噪比增益,利用引入不同噪声扰动,能够在高信噪比区域下降低错误平层,使得在相同的误比特率ber性能下译码的平均迭代次数较高,解决了现有技术方法中译码复杂度较高,或者译码性能低,在高信噪比区域下会出现错误平层,在中高信噪比情况下易陷入局部陷阱集的问题,是一种非常实用的多元ldpc码噪声增强的符号翻转译码方法。
- 还没有人留言评论。精彩留言会获得点赞!