对数据日志文件进行有损压缩的方法和系统与流程
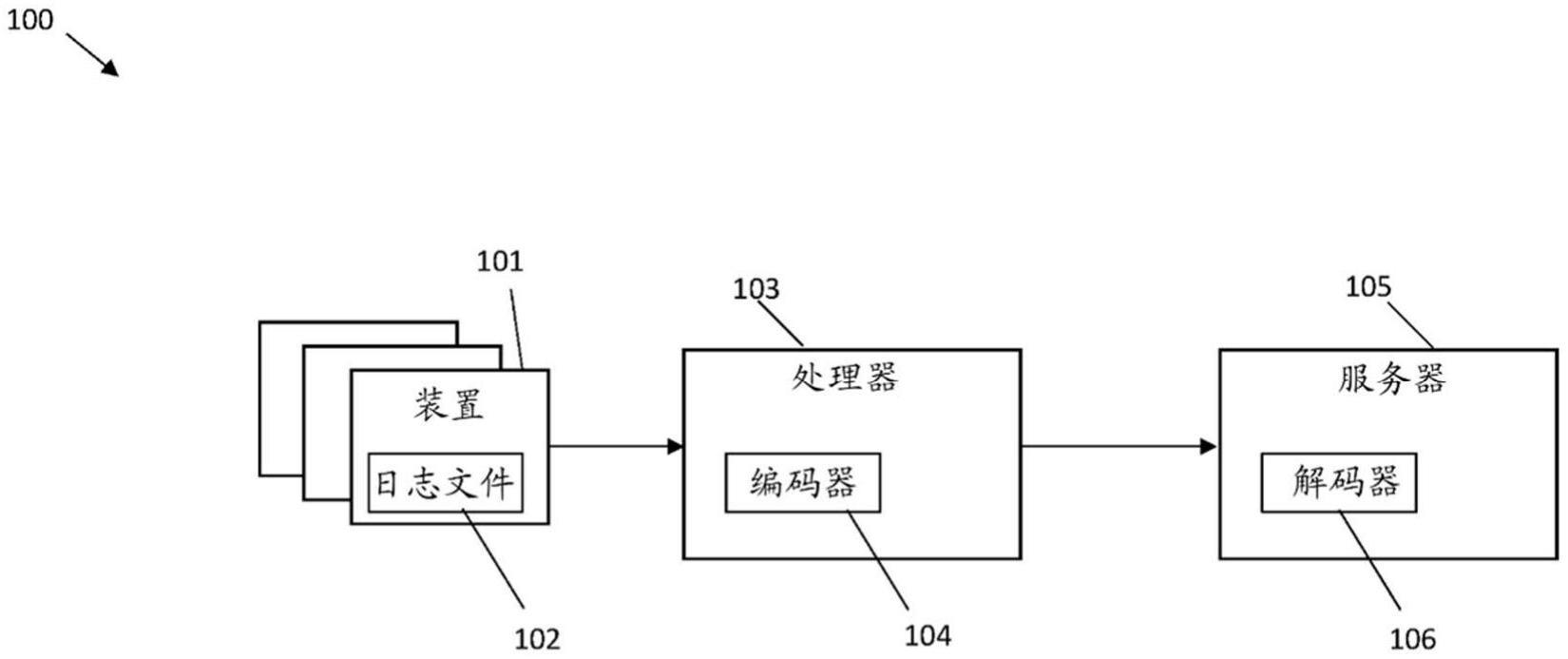
本公开在其一些实施方案中涉及日志文件压缩,并且更具体地但不排他地涉及数据日志文件的有损压缩。
背景技术:
1、数据压缩是使用比原始表示更少的位数对信息进行编码的过程。有两种类型的压缩。第一种类型是无损压缩,其通过标识和消除统计冗余来减少信息表示。在无损压缩中,不会丢失任何信息。然而,第二种类型是有损压缩。在有损压缩中,通过移除不必要的信息或不太重要的信息来减少信息。移除的信息会丢失并且通常无法重建。有损压缩对于图像文件和语音和/或话音文件(例如联合图像专家组(jpeg)和运动图像专家组第3层音频(mp3))来说是常见的。然而,对于文本文件来说,有损压缩很少使用,并且所有已知的文本压缩方法都是无损压缩,例如zip方法、lempel ziv welch(lz压缩)等。
2、执行数据压缩的装置通常被称为编码器,而执行所述过程的逆过程(即解压缩)的装置被称为解码器。
3、数据压缩可以显著减少文件占用的存储量。例如,在2:1的压缩比下,20兆字节(mb)的文件占用10mb的空间。由于压缩,管理员在存储上花费的金钱和时间更少。
4、压缩减少存储硬件(优化备份存储性能)、数据传输时间,并且有助于在带宽有限的通道上传输数据。随着数据持续呈指数级增长(例如大数据领域),压缩发挥着重要作用,并成为数据缩减的重要方法。
技术实现思路
1、本公开的一个目的是描述用于通过创建向量来利用有损压缩有效地压缩数据日志文件的系统和方法,所述向量对与数据日志文件中的行匹配的唯一值进行编码。
2、本公开的另一个目的是描述一种用于通过分析创建的向量来检测数据日志文件中的异常的方法,所述创建的向量对与数据日志文件中的行匹配的唯一值进行编码。
3、上述和其他目的通过独立权利要求的特征来实现。根据从属权利要求、说明书和附图,另外的实施方式形式是显而易见的。
4、在一个方面,本公开涉及一种用于数据日志文件压缩的方法。所述方法包括:利用至少两个级别的层次聚类对多个数据日志文件中的多行中的每一行进行分类,包括标识在多个数据日志文件的多行中重复的多个字符串;创建使多个字符串中的每一个与唯一值匹配的表;创建向量,所述向量使用所述表来对与多个字符串中的每一个匹配的唯一值进行编码;根据对多行的分类来为向量中的编码的唯一值中的每一个分配安全相关性分数;以及选择编码的唯一值的子集,使得根据每个唯一值的安全相关性分数来对向量中的编码的唯一值进行过滤。
5、至少两个级别的层次聚类的使用使得能够在字符串属于不同集群时使用相同的唯一值来表示不同的字符串。与诸如lempel–ziv(lz)压缩等标准压缩算法相比时,这减小了经压缩文件的熵。
6、选择编码的唯一值的子集使得能够过滤日志文件中不太重要的字符串。可以根据所实施的系统的不同需要来控制过滤,并且可以相应地确定输出压缩文件的大小。
7、在第一方面的另外的实施方式中,所述方法还包括将向量发送到检测器,以根据对向量的分析来检测多个数据日志文件中的异常行为。
8、在第一方面的另外的实施方式中,所述方法还包括用于生成用于数据日志文件压缩的模型的计算机实施的方法。所述计算机实施的方法包括:接收由一个或多个电气部件创建的多个日志文件;用多个日志文件训练至少一个模型以对多个日志文件中的多行中的每一行进行分类并根据对多行中的每一行的分类来为多行中的每一行分配安全相关性分数;以及输出至少一个模型以用于对多个日志文件中的多行中的每一行进行分类,并基于由一个或多个其他电气部件创建的新日志文件,根据对多行中的每一行的分类来为多行中的每一行分配安全相关性分数。
9、在第一方面的另外的实施方式中,训练至少一个模型还包括从每个重复的字符串中提取字符串参数并将字符串参数存储在单独文件中。
10、在第一方面的另外的实施方式中,至少两个级别的层次分类是根据以下各者进行的:
11、基于创建日志行的所述日志文件的所述电气部件的粗略聚类;以及
12、根据所述日志行与其他日志行的内容相似性进行的精细聚类。
13、精细聚类还可以被实施为层次聚类,这进一步减小了经压缩文件的熵。
14、在第一方面的另外的实施方式中,所述方法还包括利用二进制压缩算法来压缩与多个字符串匹配的唯一值的所选子集。
15、在第一方面的另外的实施方式中,所述方法还包括用于执行用于数据日志文件压缩的模型的计算机实施的方法,所述计算机实施的方法包括:
16、从一个或多个电气部件接收多个日志文件;
17、执行至少一个模型以对所述多个日志文件中的多行中的每一行进行分类,并根据对所述多行中的每一行的所述分类为所述多行中的每一行分配安全相关性分数;以及
18、基于对所述至少一个模型的所述执行的输出,对所述多个日志文件中的多行中的每一行进行分类,并根据对所述多行中的每一行的所述分类来为所述多行中的每一行分配安全相关性分数。
19、在第一方面的另外的实施方式中,对向量的分析是通过监督机器学习算法来进行的,所述监督机器学习算法用标记的恶意和良性行为的日志行进行训练,以检测其他日志行中的恶意行为。
20、在第一方面的另外的实施方式中,监督机器学习算法是以下列表中的成员:决策树、神经网络和支持向量机(svm)。
21、在第一方面的另外的实施方式中,对创建的向量的分析是通过无监督机器学习算法进行的,所述无监督机器学习算法用未标记的日志行进行训练以从其他日志行的正常行为中检测异常行为。
22、在第一方面的另外的实施方式中,无监督机器学习算法是以下列表中的成员:一类支持向量机(svm)或自动编码器。
23、在第一方面的另外的实施方式中,数据日志文件是车辆数据日志文件。
24、在第一方面的另外的实施方式中,表是散列表。
25、在第一方面的另外的实施方式中,对向量的分析指示安全威胁。
26、在第二方面,本公开涉及一种用于数据日志文件解压缩的方法。所述方法包括:接收具有多个唯一值的经编码文件,其中每个唯一值表示多个字符串中的一个字符串;根据使多个唯一值中的每一个与多个字符串中的每一个字符串匹配的表来对经编码文件进行解码;以及将多个字符串中的每一个与存储在单独文件中的多个字符串中的每一个的参数组合,以重建在编码之前经编码文件的原始行。
27、在第三方面,本公开涉及一种用于日志压缩的设备,所述设备包括至少一个处理器,所述至少一个处理器被配置为执行用于进行以下操作的代码:
28、利用至少两个级别的层次聚类对多个数据日志文件中的多行中的每一行进行分类,包括标识在所述多个数据日志文件的所述多行中重复的多个字符串;
29、创建使所述多个字符串中的每一个与唯一值匹配的表;
30、创建向量,所述向量使用所述表对与所述多个字符串中的每一个匹配的所述唯一值进行编码;
31、根据对所述多行的所述分类来为所述向量中的所述编码的唯一值中的每一个分配安全相关性分数;以及
32、选择所述编码的唯一值的子集,使得根据每个唯一值的所述安全相关性分数来对所述向量中的所述编码的唯一值进行过滤。
33、在第四方面,本公开涉及一种用于数据日志文件解压缩的设备,所述设备包括至少一个处理器,所述至少一个处理器被配置为执行用于进行以下操作的代码:
34、接收具有多个唯一值的经编码文件,其中每个唯一值表示多个字符串中的一个字符串;
35、根据使所述多个唯一值中的每一个与所述多个字符串中的每个字符串匹配的表来对所述经编码文件进行解码;
36、将所述多个字符串中的每一个与存储在单独文件中的所述多个字符串中的每一个的参数组合,以重建在编码之前所述经编码文件的原始行。
37、在第五方面,本公开涉及一种在存储用于执行用于数据日志文件压缩的方法的指令的非暂时性计算机可读存储介质上提供的计算机程序产品,包括:
38、利用至少两个级别的层次聚类对多个数据日志文件中的多行中的每一行进行分类,包括标识在所述多个数据日志文件的所述多行中重复的多个字符串;
39、创建使所述多个字符串中的每一个与唯一值匹配的表;
40、创建向量,所述向量使用所述表对与所述多个字符串中的每一个匹配的所述唯一值进行编码;
41、根据对所述多行的所述分类来为所述向量中的所述编码的唯一值中的每一个分配安全相关性分数;以及
42、选择所述编码的唯一值的子集,使得根据每个唯一值的所述安全相关性分数来对所述向量中的所述编码的唯一值进行过滤。
43、在第六方面,本公开涉及一种在存储用于执行用于数据日志文件解压缩的方法的指令的非暂时性计算机可读存储介质上提供的计算机程序产品,包括:
44、接收具有多个唯一值的经编码文件,其中每个唯一值表示多个字符串中的一个字符串;
45、根据使所述多个唯一值中的每一个与所述多个字符串中的每个字符串匹配的表来对所述经编码文件进行解码;
46、将所述多个字符串中的每一个与存储在单独文件中的所述多个字符串中的每一个的参数组合,以重建在编码之前所述经编码文件的原始行。
47、除非另外定义,否则本文使用的所有技术术语和/或科学术语具有与本公开所属领域的普通技术人员通常所理解的相同的含义。虽然可以在本公开的实施方案的实践或测试中使用与本文描述的方法和材料类似或等效的方法和材料,但在下文描述示例性方法和/或材料。如有冲突,以专利说明书(包括定义)为准。另外,材料、方法和示例仅为说明性的,而无意一定是限制性的。
- 还没有人留言评论。精彩留言会获得点赞!