用于使得处理器能够生成流水线控制信号的方法和装置与流程
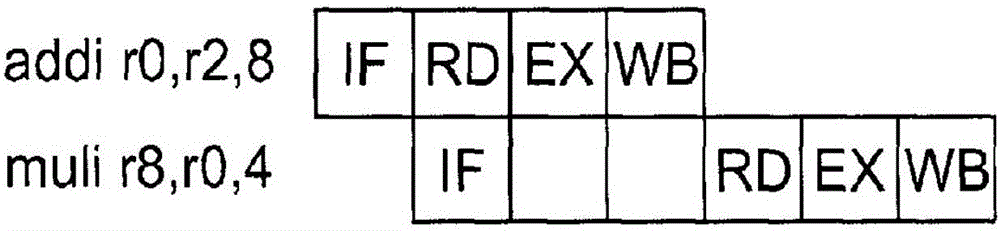
本申请要求2014年11月12日提交的美国实用新型专利申请号14/539,104的权益,该实用新型专利申请要求2014年2月6日提交的美国临时专利申请号61/936,428的权益,其公开内容通过引用而被整体包含于此。
技术领域
本公开的实施例涉及用于在微处理器环境中处理指令的方法和装置。更具体地,所述实施例涉及用于使得依赖关系信息、并行性信息和性能优化能够被编码在指令序列中的方法和装置。处理器可以对该信息进行解码并采用其来生成流水线控制信号,而无需复杂的指令间依赖关系检查硬件。
背景技术:
顺序指令流中的一组处理器指令内的指令据说当处理器指令的输入值不是由该组内的其他处理器指令生成时是相互独立的。换言之,无论该组处理器指令内的指令是按次序顺序地评估还是并行地评估还是以乱序方式评估,指令流的执行的结果输出保持不变。
由于独立的指令可以按照任何次序评估,因此这些独立指令的执行中的潜在重叠被称为指令级并行性(ILP)。ILP可被定义为处理器指令可被同时评估的程度的度量。
限制指令流中的ILP的因素是指令之间的数据依赖关系和控制依赖关系。当前处理器架构试图通过采用诸如动态指令调度、静态指令调度和多指令发布之类的微架构技术来减轻这些依赖关系的影响。动态指令调度技术在通用处理器的领域中已被广泛使用。然而,由于实时和功率约束,嵌入式系统领域中的处理器具有通常使用的静态指令调度技术。
评估流水线微架构中的指令的处理器通常进行相同的处理阶段。图1示出了可由典型的流水线处理器采用的指令级的集合。第一指令addi执行寄存器r2的内容与立即值8的加法。在第一级(IF)中,指令可被从存储器取回并被解码。在第二级(RD)中,操作数可被从寄存器文件读取。在第三级(EX)中,加法可被执行。最终,在第四级(WB)中,结果可被写回到位置r0处的寄存器文件中。流水线阶段(IF、RD、EX和WB)中的每个通常在时钟边界上执行。第二指令muli可被在第二时钟周期上开始而不需要附加硬件。第二指令的处理可以与第一指令重叠,因为在RD级中不需要IF级所需的资源。IF、RD、EX和WB级可以是共享的,但是在时间上变换。
图2示出了图1的流水线实施方式的复杂化。在该示例中,muli指令需要通过addi指令计算的结果作为操作数。由于写回(WB)阶段尚未发生,因此该处理必须暂停并且等待执行完成。muli为了其操作数变得可用而必须等待的空周期通常称为流水线中的“气泡”。
典型的通用处理器使用复杂的依赖关系检查硬件来动态地判定解码后的指令是否与当前在流水线中执行的指令有指令间依赖关系。该硬件有时被称为互锁硬件。如果依赖关系被检测到(也称为危险),则指令发布被暂停直到依赖的指令完成执行并且依赖关系被分解为止。应当注意到,如果处理器能够将来自当前指令的EX级的结果直接转发到下一个指令的EX级,则流水线中将没有气泡形成。这被称为旁路或者有时称为结果转发。
典型的嵌入式处理器可以采用裸露的流水线,其中编程者或者编译器负责通过在执行之前调度指令以使得所有指令间依赖关系被满足来保证代码正确地执行。这种在编译时调度指令的方式被称为静态调度。在静态调度并且没有互锁硬件的情况下,NOP(无操作)指令可能需要被插入到指令流中以使得在寄存器文件被读取之前适当数目个周期过去。
无论指的是具有动态硬件互锁的通用处理器还是具有可视流水线的嵌入式处理器,流水线的重叠指令执行可被称作垂直并行性。
另一类型的并行性可被称作水平并行性。利用水平并行性,如果不存在依赖关系则多个独立操作可被同时执行。这经常是数字信号处理代码和高性能计算程序的情况。
如果这些多个独立操作对不同的数据元素进行相同操作,则该类并行性有时被称作数据级并行性。利用数据级并行性的处理器可以执行进行相同操作的单个指令。当对多个元素同时进行相同操作时,这经常被称作向量/SIMD操作。向量操作是单指令多数据(SIMD)操作的子集,但是对于许多种类的算法,它们是等价的。相比之下,标量处理器上的指令对单个数据元素进行操作。图3是向量/SIMD处理器的简化的电路图。
处理器可以通过在单个时钟周期中同时发布多个独立指令来利用水平并行性。多发布处理器基本有两种:超标量处理器和VLIW处理器。这两类之间的基本差异是指令间依赖关系被分解以及指令被发布以供执行的方式。
在超标量架构中,指令间危险在运行时被以硬件动态地检测。一旦依赖关系被分解,则一个或多个指令被动态地发布。当前的通用处理器通常是推测性超标量处理器,其每个时钟周期发布变化数目的指令、以硬件进行指令间危险检测、一旦依赖关系被分解则动态地发布指令、进行乱序指令执行接着是按次序提交、并且进行指令流的推测性执行以减轻控制依赖关系的影响。
相比之下,VLIW和裸露的流水线架构通常发布被格式化为一个大指令的固定数目的操作。指令调度被在编译时静态地进行或者通过编程者进行。该途径依赖编译器或编程者来识别危险和调度操作,因为该实施方式不包含用来明确地检查危险的硬件。嵌入式处理器和数字信号处理器通常使用超长指令字(VLIW)技术。
VLIW途径同时执行指令内的所有操作。作为细化,架构已经采用VLIW指令字段内的一个或多个位来明确指示并行性。这允许指令内的操作的执行被串行地发布而非并行地发布。
如在M.Moudgill、J.Glossner、S.Agrawal和G.Nacer的2008年10月的华盛顿哥伦比亚特区的软件定义无线电技术论坛(SDR论坛'08)的会议论文集中的“The Sandblaster 2.0Architecture and SB3500Implementation”中描述的,Sandbridge Sandblaster SB3500微处理器使用其3操作复合指令束内的称为“串行位”的单个位来指示指令束内的操作是否需要被顺序地执行。如果设置了串行位,则束内的操作被串行地执行。如果未设置串行位,则操作必须并行地执行。如果操作之一是设置了串行位的采取分支,则剩余操作不被执行。
如在2010年7月的德州仪器的文献号:SPRU732J的“TMS320C64x/C64x+DSP CPU and Instruction Set–Reference Guide”(在下文中称为“德州仪器”)中描述的原始德州仪器TI C6201微处理器需要为每个VLIW指令取回256位。德州仪器将这些256位指令称为取回分组。德州仪器将操作字段再分为德州仪器称为指令的单独的32位字段。该取回分组内的这些操作的执行部分地由每个“指令”中的称为“p位”的位控制。p位判定指令是否将被与另一个指令并行地执行。如果指令i的p位是1,则指令i+1将被与指令i(在相同周期中)并行地执行。如果指令i的p位是0,则指令i+1被在指令i之后的周期中执行。VLIW取回分组内的p位模式允许以完全并行、完全串行或者部分串行方式执行指令。
如在IBM650计算机中最初引入的指令链接意味着当前指令包含下一指令地址,如在Gerrit A.Blaaw和Frederick P.Brooks,Jr.的1997年2月的第一版的Addison Wesley出版社的“Computer Architecture:Concepts and Evolution”(在下文中称为“Blaaw”)中描述的。在原始的TI设计中,如果执行分组跨过取回分组边界,则该执行分组需要被放置在下一个取回分组中,而当前分组被用NOP填充。后来的版本放松了该约束,但是仍然要求总并行长度是8。在后来的修订中,允许分支到执行分组的中间;然而,更低地址处的所有指令被忽略,并且在一些情况下,这可能产生错误结果。P位仅被用于并行或串行指令发布,不对依赖关系进行编码,并且不生成任何流水线控制。
题为“Compiler-controlled dynamic instruction dispatch in pipelined processors”的美国专利6,260,189描述了将代码块内的流水线依赖关系编码在代码块中的流水线依赖关系字段中的技术。编译器或编程者需要识别多个指令中的流水线依赖关系,诸如写后读(RAW)危险、写后写(WAW)危险、读后写(WAR)危险或者预测危险。这些指令被一起分组到具有与代码块相关联的流水线依赖关系字段的代码块中,流水线依赖关系字段指示代码块中的流水线依赖关系(如果有的话)的类型。如果未在给定代码块中识别出危险,则该块内的指令可以在没有暂停或其他校正措施的情况下被执行。如果在给定代码块中检测到一个或多个危险,则处理器仅实施如在流水线依赖关系字段中指定的在给定代码块中实际存在的危险所需的那些暂停或其他校正措施,从而避免在使用传统技术时可能导致的性能退化。
图4A和图4B示出了两个不同代码块的流水线依赖关系字段的示例。图4A中的代码块具有RAW依赖关系并且流水线依赖关系字段指出这点。图4B中的代码块没有任何数据或预测依赖关系。
技术实现要素:
通过提供使得处理器能够高效地确定并行性、指令间依赖关系和性能优化的方法和装置解决了上述问题并在本领域中实现了技术解决方案。该信息可被采用来生成流水线处理器中的必需的流水线控制信号,而不需要复杂的硬件。依赖关系信息和并行性信息被编码在指令流中的位序列中并且编码后的位被跨指令序列分发。该指令序列是基于处理器的发布宽度来分组的。从每个指令分配每个指令中的称为链接位的单个位。该位序列是利用依赖关系信息和并行性信息来编码的。
描述了对链接位进行解码的装置。根据处理器实施方式,处理器采用这些链接位来并行地且以减少的延迟执行来自多组链接指令的尽可能多的指令。链接位明确地对指令间依赖关系和组间依赖关系两者进行编码,而无须完全解码所述指令。这消除了对检查并满足流水线处理器架构中的指令间依赖关系的复杂硬件互锁的需要。
描述了一种方法和装置,其中编译器或编程者识别并行性和指令间依赖关系并且使用分布于若干指令的指令格式的单个位来编码该信息。这可被称作指令链接。处理器然后在运行时重新汇编这些位以确定指令流内的指令间依赖关系和并行性。该信息被处理器采用来生成用来改进执行时间或暂停流水线以满足指令间依赖关系的必需的流水线控制信号,而无需复杂的依赖关系检查硬件、长指令序列或者复杂发布逻辑。诸如旁路信息之类的其他类型的性能优化可被编码为链接位。本公开的示例使得静态发布处理器能够在保持静态发布处理器的低硬件复杂度和低功率的同时实现动态发布处理器的性能。本公开的示例展示了适应于可以在单个时钟周期中发布多个指令的处理器的技术的可扩展性。
附图说明
根据结合附图考虑而在下面呈现的并且其中相似的附图标记指代类似元素的示例的具体实施方式,可以更容易地理解本发明。
图1示出了可被典型流水线处理器采用的指令级的集合。
图2示出了图1的流水线实施方式的复杂化。
图3是向量/SIMD处理器的简化的电路图。
图4A和图4B示出了两个不同代码块的流水线依赖关系字段的示例。
图5示出了两个独立指令的示例,每个指令具有为链接信息预留的对应位。
图6示出了本公开的示例可以操作于的用于解码链接的指令的多线程计算机处理器内的硬件线程单元的一个示例。
图7示出了本公开的示例可以操作于的用来从指令组中的指令提取链接位、解码所提取出的链接位并且生成流水线控制信号的链接位解码装置。
图8是例示出用于在不检查在指令序列中编码的底层指令的情况下使得依赖关系信息、并行性信息和性能优化能够被解码的方法的示例的流程图。
图9示出了用来展示典型的单发布流水线处理器中的链接的预优化代码的示例。
图10示出了通过尽可能早地移动所有独立指令对图9的循环内的指令重新排序的优化的汇编语言代码的示例。
图11示出了具有根据上面在图6和图7中讨论的单发布流水线处理器的语义配置的链接位的图10的代码。
图12示出了使用图11中的指令流的指令链接的图6和图7中的单发布处理器的执行快照。
图13示出了双发布流水线处理器的指令链接语义的集合的一个示例。
图14示出了双发布流水线处理器的指令链接的一个示例。
图15示出了图14中的双发布指令流的执行快照的一个示例。
图16示出了3发布处理器中的指令链接的语义的一个示例。
图17示出了针对用于图9中示出的示例代码的3发布流水线处理器配置的指令链的一个示例。
图18示出了图17中的3发布指令流的执行快照的示例。
图19示出了4发布处理器的指令链接语义的集合的一个示例。
图20示出了例示出对强制并行性的需要的4发布处理器的预优化代码的示例。
图21示出了4发布处理器的重新排序的优化代码的一个示例。
图22示出了针对用于图21中示出的示例代码的4发布流水线处理器配置的指令链的一个示例。
图23示出了图22中的4发布指令流的执行快照的一个示例。
图24是例示出用于使得能够使用编译器将依赖关系信息、并行性信息和性能优化编码在指令序列中的方法的示例的流程图。
图25以计算机系统的示例形式例示出机器的图示表示,其中用于使该机器进行本文中所讨论的方法中的任意一种或多种方法的指令集合可被执行。
将会理解,附图是为了例示出本发明的概念的目的并且可能不是成比例的。
具体实施方式
指令链接每个指令采用一个位(在下文中称作“链接位”)来指示处理器指令序列中的并行性和指令间依赖关系两者。如本文中所使用的,指令指的是具有操作和操作数短语的可独立寻址的单元(参见Blaaw,第128页)。多个指令可被分组在一起以形成可被一起取回的指令组。在运行时,处理器重新汇编来自指令组中的指令的链接位以高效地对指令流内的依赖关系和并行性进行解码,而无须对单独指令进行解码。该信息可被采用来为指令发布生成必需的流水线控制信号,从而消除对流水线处理器架构中的NOP指令或复杂的指令间依赖关系检查硬件的需要。该过程可以与诸如长加载流水线暂停、分支分解和其他长延迟操作之类的对编程者不可见的流水线影响共存。因为每个指令是可独立寻址的,因此可允许跳到指令组的中间。然而,当跳到指令组的中间时,整个组的依赖关系位需要为了链接位解码而被重构。如果编译器分析指令依赖关系并且生成链接位,则编程者实际上未看见任何流水线影响并且可以对机器编程而不考虑危险。
虽然可能可以定义要与不同处理器实施方式兼容的链接位的集合,但是对于大多数实施方式,链接位可以是依赖于实施方式的:它们的语义仅在它们被编程用于的处理器上可被解释。在示例中,单发布流水线处理器可以只具有一个链接位的两个解释。“0”值指代无链接而“1”值指代指令可被与下一个指令链接。因此,在单发布流水线处理器中,链接位可以仅指示指令是否独立以及有还是没有危险。在另一个示例中,链接位的逻辑可被颠倒以将“0”解释为指代链接而将“1”解释为指代无链接。
图5示出了两个独立指令502、504的示例500,指令502、504中的每个具有为链接信息预留的对应位506、508。乘法指令502的链接位506被设置为1,因为加法指令504是独立的并且可被并行地执行。任意数目的位可以基于特定处理器的能力而被链接在一起。
通过采用链接,可跨指令序列编码依赖关系。在另一个示例中,3发布机器可以采用三个链接位(每个指令一个)来编码8种可能的依赖关系类型。在此意义上,链接可被扩展为多组指令。例如,从三个指令的链接位解码出的“000”可被解释为当前组内的所有指令未被链接并且下一组指令不可与当前组指令链接。
在一个示例中,在多发布处理器中,可以为组间并行性预留链接位中的一个以指示当前组指令之后的下一组指令是否包含与当前组指令的任何控制或数据依赖关系。如果不存在依赖关系,则下一组指令可被与当前组指令并发地沿着流水线向下发布,而没有任何流水线暂停。指令组内的其他链接位可以描述组内并行性信息,其指示当前指令组中的指令之间的并行性和依赖关系。
链接位还可以编码性能改进技术,诸如通知处理器使用旁路值而非从寄存器文件再次读取它。在一些情形下,这可以减少通过处理器消散的功率。
有利地,并行性和依赖关系两者可被跨指令组编码。可以采用链接位来编码指令间依赖关系、组间依赖关系和性能优化,指令间依赖关系、组间依赖关系和性能优化在执行期间帮助快速地生成流水线处理器中的必需的流水线控制信号,从而消除对复杂的依赖关系检查硬件的需要。
图6示出了本公开的示例可以操作于的用于解码链接的指令的多线程计算机处理器600内的硬件线程单元的一个示例。在示例中,多线程处理器600可包括多个硬件线程单元602a-602n。硬件线程单元602a-602n中的每个可包括程序计数器(PC)603、指令存储器604、指令解码器606(标记为“控制”)、寄存器文件608、包括算数逻辑单元(ALU)610a-610n的一个或多个流水线执行单元以及数据存储器612。
在一个示例中,可以从指令存储器604读取并解码“多组”指令,并且可以采用解码后的信息来生成退出控制块606的控制信号,控制块606控制数据路径和流水线的操作。可以将直接寄存器引用传送到寄存器文件608(标记为寄存器608)并且可以将包含在寄存器文件608内的数据传送到一个或多个算数逻辑单元(ALU)610a-610n(其在示例中可包括指令流水线和执行单元(未示出))。可以将存储在数据存储器612中的操作的结果写回到寄存器文件608。可以更新程序计数器(PC)603并且可以从指令存储器604取回下一指令。计算机处理器600的完整描述可以在“www.cise.ufl.edu/~mssz/CompOrg/CDA-proc.html”处找到,其通过引用整体并入于此。
本领域技术人员将认识到,在一个示例中,多线程处理器600的元件603-612中的一个或多个可被跨硬件线程单元602a-602n共享。例如,当元件603-612中的一个或多个不表示处理器状态时,元件603-612(例如,一个或多个算术逻辑单元(ALU)610、指令存储器(I高速缓存)604、数据存储器612等)中的一个或多个可被在硬件线程单元602a-602n之间共享。相反地,在示例中,元件603-612中的表示处理器状态的任何元件需要针对硬件线程单元602a-602n中的每个而被复制。
图7示出了本公开的示例可以操作于的用来从指令组706中的指令704a-704n提取链接位702、对提取出的链接位702进行解码并且生成流水线控制信号的装置700的一个示例。在一个示例中,装置700可被实施在和如图6中的控制块606所示的其他控制信号一样的流水线级中。在另一个示例中,装置700可被更早地实施在流水线级中以简化信息的解码。在图7中,链接位解码器708可被配置为对从提取出的链接位702接收到的编码后的链接位组合的语义进行解码并且可被配置为为指令发布控制器710生成适当的控制。例如,指令发布控制器710可以使用控制信号714来控制指令组内的指令的(串行、并行或者部分并行)发布,或者指令发布控制器710可以使用控制信号716来控制下一指令组的发布。指令发布控制器710可被配置为接收来自链接位解码器708的命令并且可生成流水线控制信号来暂停流水线级718a-718n(例如包括流水线时钟724a-724n、流水线级逻辑726a-726n和对应的寄存器728a-728n)中的指令发布,如有必要的话。流水线状态监视器720可被配置为监视当前在流水线级718中执行的指令并且向指令发布控制器710提供反馈722以在暂停之后重新开始指令发布。本公开的示例中的不同于VLIW和可视流水线设计的重要考虑在于生成流水线控制,以使得编译器或编程者看不到任何流水线影响。
图8是例示出用于在不检查编码在指令序列中的底层指令的情况下使得依赖关系信息、并行性信息和性能优化能够被解码的方法800的示例的流程图。方法800可以由图6中的计算机处理器600进行,并且在一个示例中可包括图7中的装置700(例如,电路、专用逻辑、可编程逻辑、微代码等等)。
如在图8中示出,在方框805处,计算机处理器600的链接位解码器700接收指令流。在方框810处,装置700的链接位解码器708从该指令流中选择一组指令(例如,指令组706中的指令704a-704n)。在方框815处,链接位解码器708从指令流704a-704n的每个指令(例如,704a-704n)提取指定位702以产生链接位702的序列。在方框820处,链接位解码器708对链接位702的序列进行解码。在方框825处,链接位解码器708基于解码后的链接位702的序列来识别选中的一组指令(例如,指令组706中的指令704a-704n)之中的两个或更多个指令之间的零或更多依赖关系。在示例中,选中的一组指令704a-704n之中的两个或更多个指令之间的识别出的依赖关系可以是控制依赖关系或者数据依赖关系。
在方框830处,链接位解码器708基于选中的一组指令(例如,指令组706中的指令704a-704n)之中的两个或更多个指令之间的识别出的零或更多依赖关系来输出控制信号以使一个或多个流水线级718执行选中的一组指令(例如,指令组706中的指令704a-704n)。在不对选中的一组指令(例如,指令组706中的指令704a-704n)中的任何指令进行解码的情况下,链接位702的序列可被链接位解码器708解码。
在示例中,解码后的链接位702的序列中的剩余位可以向指令发布控制器710指示选中的一组指令704a-704n中的两个或更多个指令可被流水线级718并行地执行。在另一个示例中,解码后的链接位702的序列中的剩余位可以向指令发布控制器710指示选中的一组指令704a-704n中的两个或更多个指令可被流水线级718串行地执行。在另一个示例中,解码后的链接位702的序列中的剩余位可以向指令发布控制器710指示选中的一组指令704a-704n中的两个或更多个指令必须被流水线级718并行地执行。在另一个示例中,解码后的链接位702的序列中的剩余位可以向指令发布控制器710指示选中的一组指令可被流水线级718部分并行以及部分串行地执行。
在示例中,要放置在选中的一组指令704a-704n中的指令的数目可以基于处理器600的发布宽度。
在上面的示例中,链接位解码器708可被配置为使用链接位702来识别选中的一组指令内的组内依赖关系。因此,在方框835处,链接位解码器708可将选中的一组指令704a-704n和相关联的链接位702划分为第一组指令和第二组指令以识别(例如,组之间的)组内依赖关系。
在方框840处,链接位解码器708可以基于解码后的链接位702的序列来识别从指令流选择的第一组指令中的指令和第二组指令中的指令之间的零或更多依赖关系。在方框845处,链接位解码器708可以基于第一组指令中的指令和第二组指令中的指令之间的识别出的零或更多依赖关系来输出控制信号以使一个或多个流水线级718执行第二组指令。在示例中,解码后的链接位702的序列中的一位可指示第一组指令可被与第二组指令并行地执行。第一组指令中的一个或多个指令和第二组指令中的一个或多个指令之间的识别出的依赖关系可以是控制依赖关系或者数据依赖关系。
在示例中,解码后的链接位702的序列中的一个或多个位可以可操作来优化处理器600的性能。在示例中,解码后的链接位702的序列可以可操作来起用于流水线级718的流水线控制信号的作用。
单发布流水线处理器
链接的最简单情况是如果没有指令间依赖关系则可以每个时钟周期发布一个指令的单发布流水线处理器。如在图2中针对典型的流水线处理器所示,如果存在指令间依赖关系,则流水线必须暂停直到依赖关系被分解为止。如果链接位被设置为“1”,则这是下一指令与当前指令链内的任何指令没有控制或数据依赖关系的指示。因此,指令可被立即发布。如果链接位被设置为“0”,则这是下一指令与当前指令链内的至少一个指令有控制和/或数据依赖关系的指示。因此,该指令的执行在当前链中的所有指令完成执行并且退出流水线之前无法开始。
图9示出了用来展示典型的单发布流水线处理器中的链接的预优化代码的示例。图9以C语言和汇编语言两者示出了实施示例循环,该示例循环使尺寸为NUM的两个源数组(寄存器中的指针src1、src2)相乘并且将结果存储到目标数组(寄存器中的指针dst)中。该代码还在存储器位置mac中累积相乘结果。
在序言中,代码使用存储—更新指令(stwu)在(通过堆栈指针寄存器r1所指向的)堆栈上预留空间、保存暂存寄存器的值、加载mac的初始值并且清除计数寄存器cnt中的值。在循环内,代码加载需要被相乘并累积的源值、进行相乘累积并且保存来自相乘和累积操作的结果。如果比较值相等则cmp指令将flg设置为0,或者如果比较是不相等则将其设置为1。如果flg等于1则jc指令跳回到循环中。在结尾中,代码将原始值从堆栈恢复到暂存寄存器中、释放堆栈上的预留空间并且使用j指令无条件地退出过程。
图10示出了通过在代码中尽可能早地移动所有独立指令来重新排序图9的循环内的指令的优化的汇编语言代码的示例。
图11示出了具有根据上面在图6和图7中讨论的单发布流水线处理器的语义而配置的链接位的图10的代码。例如,因为第二指令依赖于由第一指令生成的寄存器r1的值,因此指令1的链接位被设置为0。因为指令3与当前指令链中的指令没有依赖关系并且可被并行地执行,因此指令2的链接位被设置为1。因为下一指令(指令9)与在当前指令链中的指令6具有写后读依赖关系,因此指令8的链接位被设置为0。
图12示出了使用图11中的指令流的指令链接的图6和图7中的单发布处理器的执行快照。可以每一个时钟周期发布一个指令,除非从链接位检测到依赖关系(链接位为0)。每当链接位为0时,下一指令不被发布并且指令发布流水线被暂停nx周期,直到所有的执行指令完成为止。这消除了处理器流水线中对互锁硬件的需要。一旦来自当前指令链的执行指令完成,则来自新指令链的暂停的指令可被发布。
在图12中,暂停周期被添加到暂停的指令的时钟周期计数以指示指令为了被发布而等待的周期的数目。例如,指令1在一个时钟周期中被发布。由于指令1的链接位是0,因此指令2在下一时钟周期中不能被发布。流水线被暂停n1个时钟周期直到指令1完成执行为止。指令2在暂停之后的一个时钟周期被发布,并且因此指令2在1+n1之后已被发布。指令18中的诸如jc之类的分支指令将使流水线清空(flush)。因此,无论分支是被采取(指令7)还是未被采取(指令19),分支之后的指令在其可以被发布之前将必须等待n5个时钟周期。当第一次进入循环时,指令7的发布仅花费一个时钟周期,而在重新进入期间,其花费1+n5个时钟周期。
双发布流水线处理器
双发布流水线处理器可被配置为如果不存在指令依赖关系则每一个周期发布两个指令(指令组)。如果指令组之间存在依赖关系,则流水线被暂停直到该依赖关系被分解为止。如果指令组内存在依赖关系,则指令组内的指令被串行地发布,即,第一指令被发布并且在第一指令完成执行并且退出流水线之前第二指令被暂停。
指令组中的每个指令都具有链接位。因此,在双发布处理器中,每个指令组有两个链接位可用,并且因而4种场景可被编码。在示例中,一个链接位可被用来指示垂直并行性(组间并行性)并且第二链接位可被用来指示水平并行性(组内并行性)。
图13示出了双发布流水线处理器的指令链接语义的集合的一个示例。链接位i1和i2可被分别从指令组中的第一和第二指令得到。链接位i1是组内并行性位。如果组内并行性位是1,则组中的第二指令可被与组中的第一指令并行地发布。如果组内并行性位是0,则在第一指令已经完成执行之前第二指令必须等待。链接位i2是组间并行性位。如果组间并行性位是1,则下一执行组可以在当前执行组之后在下一时钟周期中进入流水线。如果组间并行性位是0,则在当前执行组已经完成执行之前下一执行组必须等待。
图14示出了双发布流水线处理器的指令链接的一个示例。图14使用图9中示出的示例代码来指示双发布流水线处理器的可能的指令链配置。图15示出了图14中的双发布指令流的执行快照的一个示例。如果链接位指示无依赖关系,则每一个时钟周期可以发布两个指令。在第一指令组中,组内并行性位被设置为0以指示组中的指令内的依赖关系。这使得指令1被发布并且在指令1在n1个周期中完成执行之前暂停指令2。第二指令组使组内并行性位被设置为1,并且因此指令3和指令4被一起发布。第二指令组的组间并行性位也被设置为1,并且因此第三指令组在没有任何流水线暂停的情况下被沿着流水线向下发布。第四指令组的组间并行性位被设置为0,从而在当前链中的所有指令完成执行之前暂停第五组的指令发布。在指令7处重新进入循环导致不同数目的暂停周期,因为循环结尾处的分支指令(指令18)可能使流水线清空所有执行指令。
3发布流水线处理器
如果不存在指令依赖关系,则3发布流水线处理器可以每一个周期发布三个指令(指令组)。如果指令组之间存在依赖关系,则流水线被暂停直到依赖关系被分解为止。如果指令组内存在依赖关系,则指令组内的指令如通过链接位所指示的被串行地发布或者部分并行地发布。指令组中的每个指令都具有单个链接位。因此,在3发布处理器中,每个指令组有三个链接位可用,从而产生8种语义组合。一个链接位可被用来指示(跨指令组的)垂直并行性并且其他两个链接位可被用来指示(指令组内的)水平并行性。
图16示出了3发布处理器中的指令链接的语义的一个示例。图16中指示的链接位组合的指令链接的语义的示例在水平并行性中提供了最大灵活性。图16中的x的值指示链接位可以是0或1。链接位i1、i2和i3可被分别从指令组中的第一、第二和第三指令得到。链接位i1和i2是组内并行性位t。如果i1或i2是1,则组中的下一个指令可被与组中的当前指令并行地发布。如果i1或i2是0,则在当前执行的指令已经完成执行之前下一指令必须等待。链接位i3是组间并行性位。如果i3是1,则下一执行组可以在当前执行组之后在下一时钟周期中进入流水线。如果i3是0,则在当前执行组已经完成执行之前下一执行组需要等待。
如果水平并行性中的充分灵活性并非必需,则两个链接位可能足够来对垂直和水平并行性进行编码(所有三个指令被一起发布或不一起发布)。第三链接位可被用来对附加信息进行编码。
图17示出了针对用于图9中示出的示例代码的3发布流水线处理器配置的指令链的一个示例。图18示出了图17中的3发布指令流的执行快照的示例。如在图18中示出,执行遵循如在图16中描述的指令组内的3链接位的语义。如果组间并行性位(i3)如指令12和指令13之间的情况一样被设置为0,则跨指令组的指令发布被暂停。组内的指令也基于组内并行性位(i1,i2)而被以完全并行、部分并行或者完全顺序的方式发布。
4发布流水线处理器
如果不存在指令依赖关系,则4发布流水线处理器每一个周期发布四个指令。如果指令组之间存在依赖关系,则流水线可被暂停直到依赖关系被分解为止。如果指令组内存在依赖关系,则指令组内的指令可以如链接位所指示被串行地发布或者部分并行地发布。
指令组中的每个指令都具有单个链接位。因此,在4发布处理器中,每个指令组有四个链接位可用,从而产生16种语义组合。一个链接位可被用来指示(跨指令组的)垂直并行性并且其他三个链接位可被用来指示水平执行(在指令组内执行指令)的其他可能性。
图19示出了4发布处理器的指令链接语义的集合的一个示例。图19中的x的值指示链接位可以是0或1。链接位i1、i2、i3、i4可以分别从指令组中的第一、第二、第三和第四指令得到。链接位i4是组间并行性位。如果i4是1,则下一执行组可以在当前执行组之后在下一时钟周期中进入流水线。如果i4是0,则在当前执行组已经完成执行之前下一执行组必须等待。链接位i1、i2和i3可被用来指示组内并行性。在示例中,链接位i1、i2和i3的一些组合指示组中的指令内的可能的并行性(001x、010x、011x、100x)并且其他组合指示组中的指令内的强制并行性(101x、110x、111x)。可能的并行性揭示了可用的并行性,但是处理器可以使用它或者可以不使用它。无论指令是并行地执行还是顺序地执行,结果保持不变。强制并行性指示指令必须被并行地执行以获得期望的结果。
图20示出了例示出对强制并行性的需要的4发布处理器的预优化代码的示例。图20以C语言和汇编语言两者示出了示例循环,该示例循环交换尺寸为NUM的数组(寄存器中的指针src)中的偶元素和奇元素。如在示例中示出,C代码使用变量tmp_swap来完成交换。当被转换为汇编时,tmp_swap将变成用于交换的临时寄存器。
然而,如果目标是减少需要被采用的寄存器的数目,则汇编代码可以利用多发布流水线架构来消除临时寄存器。如果两个指令被并行发布,则它们都在流水线中的寄存器读取级处读取它们的源寄存器的内容并且在流水线中稍后的写回级处写回结果。因此,可以通过并行发布两个移动指令在没有临时寄存器的情况下完成交换操作,所述两个移动指令两者一起读取它们的源寄存器的内容并且然后在流水线中的稍后阶段处一起写回交换后的值。然而,这将仅在两个指令被并行地执行的情况下工作。如果被顺序地执行,则结果将是不正确的。
在序言中,代码在(通过堆栈指针寄存器r1所指向的)堆栈上预留空间、保存暂存寄存器的值并且清除计数寄存器cnt中的值。在循环内,代码加载需要被交换的源值、进行交换操作并且将结果保存回到源数组内。注意到循环内的两个mov操作仅在它们被并行地执行的情况下直接交换寄存器12和寄存器13的内容。如果比较值相等,则cmp指令将flg设置为0,或者如果比较是不相等,则将其设置为1。如果flg等于1,则jc指令跳回到循环内。在结尾中,代码将原始值从堆栈恢复到暂存寄存器内、释放堆栈上的预留空间并且使用j指令无条件地退出过程。
图21示出了4发布处理器的重新排序的优化代码的一个示例。图21示出了已经通过将独立指令移动到期望位置而进行的循环内的指令的重新排序。
图22示出了针对用于图21中示出的示例代码的4发布流水线处理器配置的指令链的一个示例。如先前指示的,链接位i4指示组间并行性。例如,第一指令组使链接位i4设置为0,这指示在第二指令组可被发布之前第二指令组需要等待直到第一指令组已经完成执行为止。第三指令组使链接位i4设置为1,这指示第四指令组可被与指令组3并行地发布。此外,注意到循环在指令处开始,该指令是第一组中的第四个指令。这指示允许跳到指令组的中间。第二指令组的链接位组合是1、1、0、0。链接位i1、i2和i3被设置为1、1、0,其语义与图19中的那些一样在于指令组中的指令1、2、3必须被并行发布。这保证了由指令6和指令7进行的交换操作被正确完成。最后一个指令组为了完整性在退出指令之后已被用nop指令填充。
图23示出了图22中的4发布指令流的执行快照的一个示例。在图23中,执行遵循如在图19中描述的指令组内的4链接位的语义。如果组间并行性位(i4)被设置为0,则跨指令组的指令发布被暂停。组内的指令如由链接位i1、i2和i3所指示而被执行。指令6和指令7被并行地执行以得到期望的交换结果。
在一个示例中,编程者可以识别计算机程序中的多组指令之间的依赖关系。计算机编程者然后可采用编程技术来允许编译器使用链接位将识别出的依赖关系编码到可执行代码中,在图6和图7的计算机处理器中可以采用所述链接位。在另一个示例中,编程者可能不直接识别前述依赖关系,而是编译将由图6和图7的计算机处理器执行的程序,其中编译器识别依赖关系并且使用链接位来编译可执行代码。
图24是例示出用于使得能够使用编译器将依赖关系信息、并行性信息和性能优化编码在指令序列中的方法2400的示例的流程图。方法2400可以例如由图6和图7中的计算机处理器进行、由下面在图25中描述的计算机处理器进行或者由其他类型的计算机处理器进行,并且可包括硬件(例如,电路、专用逻辑、可编程逻辑、微代码等等)、软件(例如,在处理设备上运行的指令)或其组合。在一个示例中,方法2400可以由图25中的计算机处理器的编译器2550进行。
如在图24中示出,为了允许使得依赖关系信息、并行性信息和性能优化能够被编码在指令序列中,在方框2405处,在处理器2502上执行的编译器2550接收指令流。在方框2410处,编译器2550从指令流中选择一组指令。
在方框2415处,编译器2550识别选中的一组指令之中的零或更多指令流依赖关系。在方框2420处,编译器2550利用选中的一组指令之中的零或更多依赖关系对每个指令中的一位进行编码以产生编码后的链接位序列。
在一个示例中,编码后的链接位序列可指示选中的一组指令中的两个或更多个指令可被并行地执行。在另一个示例中,编码后的链接位序列可指示选中的一组指令中的两个或更多个指令必须被串行地执行。在另一个示例中,编码后的链接位序列可指示选中的一组指令中的两个或更多个指令必须被并行地执行。在另一个示例中,编码后的链接位序列可指示选中的一组指令可被部分并行以及部分串行地执行。
在示例中,编译器要放置在选中的一组指令中的指令的数目可以基于将在其上执行选中的一组指令的处理器(例如,处理器600)的发布宽度。
在示例中,编译器可将选中的一组指令内的两个或更多个指令之间的依赖关系识别为控制依赖关系或者数据依赖关系。
在示例中,编码后的链接位序列中的一个或多个位可以可操作来优化可执行程序的性能。编码后的链接位序列可以可操作来起流水线控制信号的作用。
在方框2425处,编译器2550可将选中的一组指令划分成第一组指令和第二组指令。在方框2430处,编译器2550可以识别第一组指令与第二组指令之间的零或更多指令流依赖关系。在方框2435处,编译器2550可以利用第一组指令与第二组指令之间的零或更多指令流依赖关系对编码后的链接位序列进一步进行编码。在示例中,编码后的链接位序列中的一位可以指示第一组指令可被与第二组指令并行地执行。
图25以计算机系统2500的示例形式例示出机器的图示表示,其中可以执行用于使该机器进行本文中所讨论的方法中的任意一种或多种方法的指令集合。在一些示例中,机器可被连接(例如,联网)到LAN、内联网、外联网或因特网中的其他机器。机器可以按客户端—服务器网络环境中的服务器机器的能力来操作。机器可以是个人计算机(PC)、机顶盒(STB)、服务器、网络路由器、交换机或网桥,或者能够执行指定将由该机器采取的动作的(顺序的或其他方式的)指令集合的任何机器。此外,虽然仅例示出单个机器,但还应将术语“机器”理解成包括单独地或共同地执行一组(或多组)指令以进行本文中所讨论的方法中的任意一种或多种方法的机器的任意集合。
示例计算机系统2500包括处理设备(处理器)2502、主存储器2504(例如,只读存储器(ROM)、闪存、诸如同步DRAM(SDRAM)之类的动态随机存取存储器(DRAM))、静态存储器2506(例如,闪存、静态随机存取存储器(SRAM))和数据存储设备2516,它们经由总线2508相互通信。
处理器2502表示一个或多个通用处理设备,诸如微处理器、中央处理单元等等。更具体地,处理器2502可以是复杂指令集计算(CISC)微处理器、精简指令集计算(RISC)微处理器、超长指令字(VLIW)微处理器、或实施其他指令集的处理器或实施指令集的组合的处理器。处理器2502还可以是一个或多个专用处理设备,诸如专用集成电路(ASIC)、现场可编程门阵列(FPGA)、数字信号处理器(DSP)、网络处理器等等。编译器2550可由被配置为进行本文中所讨论的操作和步骤的处理器2502执行。
计算机系统2500进一步可以包括网络接口设备2522。计算机系统2500还可以包括视频显示单元2510(例如,液晶显示器(LCD)或阴极射线管(CRT))、字母数字输入设备2512(例如,键盘)、光标控制设备2514(例如,鼠标)和信号发生设备2520(例如,扬声器)。
驱动单元2516可包括计算机可读介质2524,在计算机可读介质2524上存储有体现本文中所描述的方法或功能中的任意一种或多种的一组或多组指令(例如,将由编译器2550编译的指令)。将由编译器2550编译的指令还可以在其由计算机系统2500执行期间完全或者至少部分地驻留在主存储器2504和/或处理器2502内,主存储器2504和处理器2502还构成计算机可读介质。将由编译器2550编译的指令进一步可以经由网络接口设备722通过网络2526被发送或接收。
虽然在示例中计算机可读存储介质2524被示为单个介质,但是术语“计算机可读存储介质”应当被理解为包括存储一组或多组指令的单个非暂态介质或多个非暂态介质(例如,集中式或分布式数据库和/或相关联的高速缓存和服务器)。还应将术语“计算机可读存储介质”理解成包括能够存储、编码或运载用于由机器执行的指令集合并且使机器进行本公开的方法中的任意一种或多种的任何介质。应相应地将术语“计算机可读存储介质”理解成包括但不限于固态存储器、光介质和磁介质。
在以上的描述中,已经阐述了许多细节。然而,对于受益于本公开的本领域普通技术人员而言明显的是,本公开的示例可以在没有这些具体细节的情况下实行。在一些情况下,以框图形式而非详细地示出了公知的结构和设备,以避免使说明书模糊。
具体实施方式的一些部分根据算法和对计算机存储器内的数据位的操作的符号表示而呈现。这些算法描述和表示是由数据处理技术领域的技术人员使用来将他们的工作的实质最有效地传达到本领域的其他技术人员的手段。算法在这里,并且一般被认为是导致所期望的结果的步骤的自洽序列。步骤是需要物理量的物理操纵的那些步骤。通常,尽管不一定,这些量采取电信号或磁信号的形式,所述电信号或磁信号能够被存储、传递、组合、比较以及以其他方式操纵。已经证实主要由于公共使用的原因,将这些信号称为位、值、元素、符号、字符、术语、数字有时是方便的。
然而,应当记住,所有这些和类似的术语要与适当的物理量相关联,并且仅仅是应用于这些量的方便的标记。除非以其他方式特别声明,如从上面的讨论明显的是,认识到贯穿本说明书,利用诸如“接收”、“写”、“保持”等术语的讨论指的是计算机系统或类似的电子计算设备的动作和/或处理,所述处理操纵在计算机系统的寄存器和存储器内被表示为物理(例如,电子)量的数据,并将其转换为类似地被表示为计算机系统存储器或寄存器或其他这样的信息存储装置、传输或显示设备内的物理量的其他数据。
本公开的示例还涉及用于进行本文中的操作的装置。可以为了所需目的而专门构造该装置,或者该装置可包括通用计算机,该通用计算机被存储在计算机中的计算机程序选择性地激活或重新配置。这种计算机程序可被存储在计算机可读存储介质中,诸如但不限于任意类型的盘,包括软盘、光盘、CD-ROM和磁光盘、只读存储器(ROM)、随机存取存储器(RAM)、EPROM、EEPROM、磁或光卡或者适合于存储电子指令的任意类型的介质。
本文中所呈现的算法和显示并不内在地与任何特定的计算机或其它装置相关。各种通用系统可被与根据本文中的教导的程序一起使用,或者证实可以方便地构造更专用的装置来进行所需的方法步骤。多种这些系统的示例结构根据本文中的描述而出现。另外,本公开并非参考任何特定的编程语言而描述。将认识到,可以使用多种编程语言来实施如本文中所描述的本公开的教导。
将会理解的是,上面的描述旨在是例示性而非限制性的。在阅读并理解上面的描述之后,许多其他示例对于本领域技术人员将是明显的。因此,本公开的范围应当参照所附的权利要求连同这些权利要求所享有的全部等同范围来确定。
- 还没有人留言评论。精彩留言会获得点赞!