自动推荐内容的制作方法
本申请是申请号为201380017911.9、申请日为2013年02月21日、发明名称为“自动推荐内容”的发明专利申请的分案申请。
本发明涉及自动推荐,更具体地,涉及一种用来向用户自动推荐内容的系统。
背景技术:
已经日益常见的是,将诸如视频资产之类的内容在网络上传送给用户。电影、电视剧、家庭视频、做法视频、及音乐视频仅仅是视频资产的类型的少量例子,这些视频资产当前在互联网、电话网络、内部网络、有线连接等上提供。在网络上已经得到的视频资产可在整个视频资产已经下载之后或者随着视频资产正在传送(传输)而播放。
鉴于适于消费的视频资产过多,已经日益重要的是帮助用户识别最可能使他们感兴趣的那些视频资产。例如,关于向用户推荐用户高度感兴趣的十部视频的系统,比关于仅仅提供在百万较小兴趣视频中搜索这相同十部视频的工具的系统,用户将具有好得多的体验。
各种手段已经用来向用户推荐视频资产,这些手段各自具有一定缺陷。例如,一种“趋势”手段是保持跟踪哪些视频资产由整体的用户人口最多地消费,并且将那些消费最多的视频资产推荐给所有用户。另一种趋势手段是保持跟踪那些视频在整个用户人口中当前正经历一波兴趣,并且将这些视频推荐给所有用户。这些“一只鞋子适合所有人”的趋势手段,对于具有与平均用户相对应的兴趣的用户还可以,但不是对于所有用户都适用。
“视频到视频(video-to-video)”手段是向每个用户推荐与该用户刚刚消费的视频资产共同具有某些内容的视频资产。例如,在用户已经消费电影x之后,可以向用户呈现:与电影x呈相同种类的、具有与电影x相同的主要演员的、具有与电影x相同的导演的、来自与电影x相同的时期的等等的电影的推荐。“视频到视频”手段当用户具有狭窄范围的兴趣时还可以,但当用户对于特定类型的视频已经变得满足并且用户现在想消费不同的视频时,不太适用。
用来推荐视频资产的“用户到视频(user-to-video)”手段涉及相对于时间监视用户的资产消费行为。基于用户的视频消费历史,可以得出用户的一般兴趣。这些得出兴趣然后可以用来识别用户可能感兴趣的其它视频,这些其它视频可以作为推荐而供给。用户到视频手段可以适用,只要用户的消费历史准确地反映用户的当前兴趣。然而,如果用户不具有充足的历史,或者用户当前感兴趣的是与用户过去消费的视频不同的某些视频,则基于用户到视频的推荐就不是特别有用。
本文中描述的手段是可实现的手段,但不一定是以前已经想到或实现的手段。因此,除非另外指示,否则不应该假定:本文中描述的手段的任一种仅仅因为它们在本部分中被描述而看作现有技术。
附图说明
在附图中:
图1是根据本发明实施例的方块图,该方块图表明机器学习引擎如何可以用来预测对于视频的兴趣分数;
图2是根据本发明实施例的方块图,该方块图表明各种类型的元数据,这些元数据可以由推荐系统保持;
图3是根据本发明实施例的方块图,该方块图表明对于模型调谐参数的不同值,多个分数如何可以供给到机器学习引擎中;
图4是根据本发明实施例的方块图,该方块图表明产生多个不同分数分量、和基于目的而组合分量分数;及
图5是根据本发明实施例的计算机系统的方块图,该计算机系统可以用来实施视频推荐系统。
具体实施方式
如下描述中,为了解释的目的,叙述多个具体细节,以便提供本发明的彻底理解。然而,显然,可以实践本发明而不用这些具体细节。其它情况下,熟知结构和装置以方块图形式表示,以便避免不必要地使本发明模糊。
一般概要
提供向用户推荐视频资产的技术,其中对于每个候选视频预测向用户推荐该候选视频可能满足目的的程度。在所述目的是用户约定的情况下,预测可以指示用户可能对该候选视频感兴趣的程度。根据本发明的一个方面,训练机器学习引擎既供给有协作过滤(collaborativefiltering,cf)参数值,又供给有基于内容的过滤(content-basedfiltering,cbf)参数值。基于输入参数值,机器学习引擎产生机器-学习分数(“ml分数”),该机器-学习分数反映向用户推荐特定视频将满足特定目的的程度。在所述目的是满足用户的观看兴趣的情况下,ml分数是特定用户可能对观看视频多么感兴趣的预测。
为了解释说明,对其产生ml分数的用户这里称作“目标用户”,并且对其产生ml分数的视频这里称作“目标视频”。在一个实施例中,对于在一组候选视频中的每个视频产生的ml分数,作为从候选视频中选择哪些视频推荐给目标用户的基础。
当产生ml分数时,每个输入参数影响ml分数的程度可能变化。例如,最近添加到收集库中的视频可能不具有显著量的消费历史。因此,与消费历史有关的参数对于ml分数具有比视频本身的特征(例如,长度、题材、标签)更小的影响。另一方面,对于具有长消费历史的视频,与消费历史有关的参数对于ml分数可能具有较显著的影响。一个实施例中,机器学习引擎产生ml分数以及哪些特征对ml分数具有最大肯定影响的指示。基于这种信息,关于每种视频推荐,可以向用户提供为什么正将该特定视频推荐给他们的解释。
视频到视频推荐
视频到视频推荐是指基于用户对特定视频的兴趣的指示的视频推荐。例如,如果用户已经观看、浏览、或高度评价特定视频,则可以假定:用户对该特定视频有兴趣。基于该兴趣,推荐系统可以向用户推荐其它视频。为了说明,用户已经指示对其感兴趣的视频这里称作“比较”视频。
使用机器学习将协作过滤与基于内容的过滤相结合
参照图1,它表明使用训练机器学习引擎102来产生候选视频资产的ml分数150的系统。机器学习引擎102基于输入馈送106产生ml分数150,该输入馈送106特定于用户/视频组合。输入馈送106包括几种类型的输入参数。在表明的实施例中,输入馈送106包括协作过滤(cf)输入108、基于内容的过滤(cbf)输入110、以及其它输入112。这些输入的每一种将在以后更详细地描述。
协作过滤(cf)输入
协作过滤输入108是与用户观点或行为有关的任何输入。协作过滤基于如下假定:关于一种东西具有类似观点的两个人关于另一种东西可能具有类似观点。在预测用户对视频资产的兴趣的情形中,协作过滤假定:如果目标用户已经与另一个用户喜欢观看相同视频的几个,那么目标用户可能喜欢观看其它用户喜欢了的、但目标用户还未看过的视频。
关于用户的观点的信息可以按各种方式得到或得出。例如,用户感兴趣的视频类型隐含地反映在用户的视频观看历史中。因而,协作过滤输入108可以包括关于目标用户的视频观看历史、与目标用户类似的用户的观看历史、及/或整个观众人群的观看历史的数据。
假定具有类似人口统计特性的用户将具有类似视频观看兴趣,协作过滤输入108也可以包括人口统计信息。这样的人口统计信息可以包括例如用户的年龄、性别、地理位置、收入阶层等等。协作过滤输入108也可以包括用户通过例如填写视频爱好调查或评价以前观看视频而已经清晰识别的兴趣。
在视频到视频推荐的情形中,cf输入108可以明确地指示用户行为,因为它与比较视频/目标视频对(“视频对”)有关。下文详细地描述对于视频对可以保持的各种类型的cf度量的例子。
在图1中表明的实施例中,机器学习引擎102既被提供原始cf特征120,又被提供由cf分析器118基于原始cf特征产生的cf分数124。cf分数是由cf分析器118对将目标视频提供给用户将满足目的的程度的预测,该cf分析器118实施协作过滤算法。为了说明清楚,将假定:所述目的是满足目标观众的观看兴趣。然而,如下文将更详细描述的那样,所述目标目的可以是除满足观众的兴趣之外的某些东西,或者可以是满足观众的兴趣和一个或多个其它目的的组合。
如图1显而易见的,代之以简单地将cf分数124用作目标用户对目标视频的兴趣的预测,cf分数124仅是馈送到机器学习引擎102中以产生ml分数150的几个输入之一。终究,机器学习引擎102确定cf分数124在产生ml分数150时应该加权多重,该ml分数150被用作选择要推荐那些视频的基础。
基于内容的过滤(cbf)输入
基于内容的过滤输入110是与目标视频的内容与其它视频的内容多么类似有关的任何输入。为了说明清楚,将描述产生视频到视频推荐的实施例。因而,基于内容的过滤输入聚焦在视频对之间的相似性,该视频对包括目标视频和比较视频。然而,在可选择实施例中,基于内容的过滤输入110可以包括用于任何数量的其它视频(如目标用户最近观看、浏览、或评价的视频组)的特征信息。
如以上提到的那样,比较视频典型地是目标用户已经指示对其的兴趣的视频。例如,比较视频可以是目标用户最近观看的、或对其目标用户最近给出高度评价的视频。
类似于协作过滤输入108,基于内容的过滤输入110也包括从原始输入得出的分数。具体地,基于内容的过滤输入110包括原始cbf特征126、和cbf分数130,该cbf分数130由cbf分析器128基于原始cbf特征126而产生。原始cbf特征126可以包括与目标视频和比较视频有关的任何数量的特征。例如,原始cbf特征126可以包括诸如标题、题材、持续时间、演员、关键字、标签等等之类的特征。
cbf分数130是目标视频与比较视频多么相似的估计。推定地,cbf分数130越高,在目标视频与比较视频之间的相似性越大。尽管一些系统使用cbf分数作为用来选择待推荐的视频的唯一基础,但在图1中表明的实施例中,cbf分数130仅仅是馈送到机器学习引擎102的多个输入参数之一。在得出ml分数150时,给予cbf分数130的实际权重将基于到机器学习引擎102的其它输入和训练组(借助于该训练组,训练机器学习引擎102)而变化。
到机器学习引擎的其它输入
其它输入112的类型和性质实际上没有限制,这些其它输入112可以馈送到机器学习引擎102,以提高ml分数150的准确度。例如,其它输入可以包括每天要给予推荐的时间、每周要给予推荐的周几、目标用户的连接速度等。
机器学习(ml)分数
基于协作过滤输入108、基于内容的过滤输入110及任何数量的其它输入112,机器学习引擎102产生ml分数150。ml分数150的值是将目标视频提供给用户将多好地满足特定目的或目的组的预测。在所述目的是用户约定的实施例中,ml分数150是目标用户将对观看目标视频具有多大兴趣的预测。
对于在一组候选视频中的每个视频,重复产生ml分数的过程。基于它们的相应ml分数,将目标用户可能对其具有最大兴趣的候选视频选择成呈现给目标用户作为推荐视频。
按图1表明的方式将协作过滤(cf)与基于内容的过滤(cbf)相组合,可享有每种技术的优势。具体地说,将由cf/cbf分析器产生的判断、与来自cf/cbf的原始特征一起直接暴露于机器学习引擎102。使机器学习引擎102接触到原始特征可以提供几个好处。
首先,将原始特征与cf/cbf分数一起提供给ml系统,允许ml系统分别基于来自cf和cbf的信号强度而组合分数。就是说,给予cf/cbf分数的相对权重将基于馈送到ml系统的其它输入逐个迭代而变化。例如,对于不具有足够行为数据的新电影,cf的信号强度很弱。因此,ml系统当产生ml分数时将把较小权重给予cf分数。因此,在ml分数中强调基于内容的特征。随着视频由更多人观看,行为数据将增加,当产生ml分数时,由ml系统给予cf分数的权重也将增加。
第二,暴露原始cbf特征允许ml系统基于历史cf和cbf学习全体而有效地解决新内容问题。例如,ml系统可学习到,共享诸如‘a’、‘the’之类的关键字的视频不一定相关,而共享诸如‘football’、‘49ers’之类的关键字的其它视频可能指示较强关系。因此,当产生ml分数时,弱的非特定字所导致的很高的cbf分数被机器学习引擎102给予较小权重;当产生ml分数时,高度特定字所导致而很高的cbf分数被ml系统给予较大权重。
可解释的推荐
根据一个实施例,除向目标用户呈现一组一个或多个推荐视频之外,推荐系统也向该用户呈现关于为什么视频的每个正被推荐的信息。具体地,在一个实施例中,机器学习引擎102提供输出152,该输出152指示最肯定地影响每个ml分数150的特征。例如,输出152可以指示,目标视频因为cf分数124很高,并且基于其它输入,cf分数124在ml分数150的产生中被重重地加权,而接收了高ml分数150。另一方面,用于目标视频的输出152可以指示,cbf分数很高,并且基于其它输入,cbf分数在ml分数150的产生中被重重地加权。这些仅是对于视频的ml分数可具有强烈肯定影响的特征类型的两个例子。
基于由输出152指示的、最肯定地影响ml分数150的特征,推荐系统可以选择对于为什么将对应视频推荐给了目标用户(即,为什么ml分数150高得足以证明推荐目标视频是正确的)的“解释”。例如:
·如果cbf分数130很高,并且由机器学习引擎102重重地加权,那么可以向用户呈现解释“这个视频类似于x”(其中,x是比较视频)。
·如果cf分数124很高,并且由机器学习引擎102重重地加权,那么可以向用户呈现解释“x的观众常常观看这个视频”(其中,x是比较视频)。
·如果其它输入112指示目标视频在整个观众人群中是最多观看视频之一,并且这个特征对于ml分数150具有显著影响,那么可以向用户呈现解释:“这个视频在所有用户中是最多观看视频之一”。
·如果其它输入112指示目标视频当前经历兴趣提升,并且这个特征对于ml分数150具有显著影响,那么可以向用户呈现解释“这个视频当前正经历显著的兴趣爆发”。
这些仅是可能向用户呈现的实际非限制数量的解释的例子,以向用户解释为什么正推荐目标视频。尽管这些例子是非常一般的,但实际解释可能是非常具体的。例如,除指示“这个视频类似于x”之外,解释可以列举与x类似的视频的各个方面(例如,题材、演员、主题、标签、持续时间、音乐分数等)。
对于推荐系统的度量
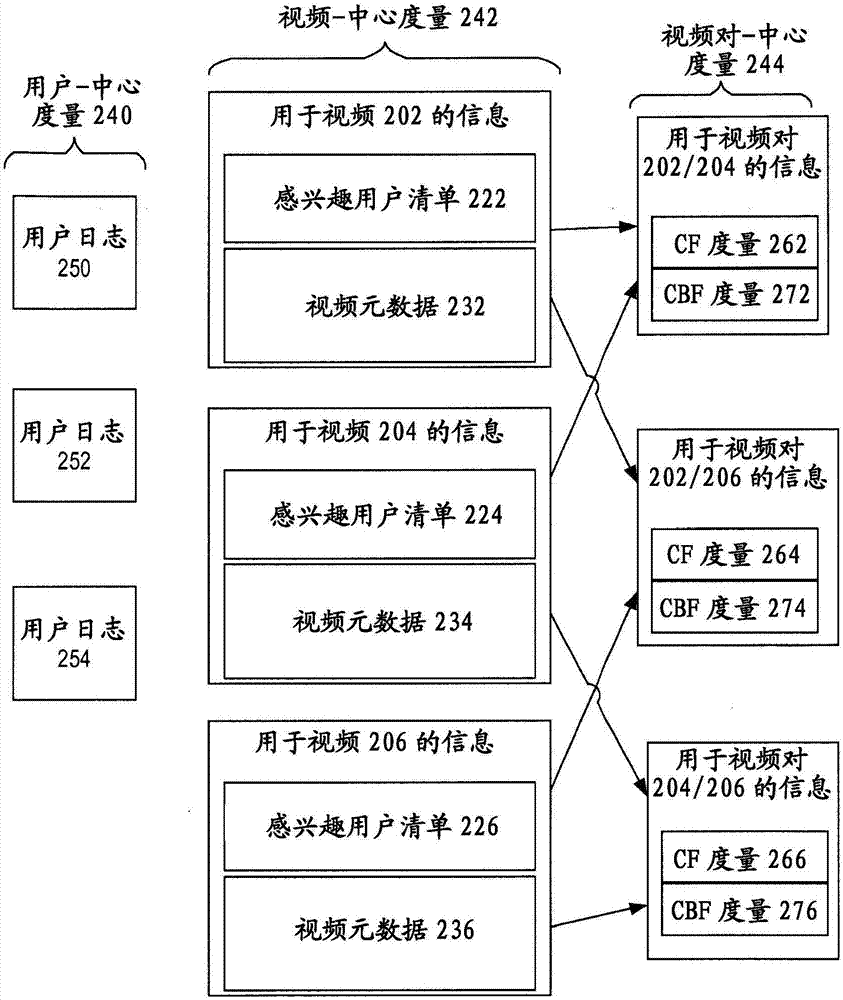
如以上提到的那样,协作过滤输入108可以包括关于视频消费者的观看行为的信息。观看行为反映在原始cf特征120中,这些原始cf特征120既馈送到cf分析器118,又馈送到机器学习引擎102。为了得到cf特征,推荐系统可以处理来自播放器日志(具有丰富的行为信息)的用户-中心度量,以最终产生视频对-中心度量,这些视频对-中心度量可包括在到机器学习引擎102的输入馈送106中。
参照图2,它是根据本发明实施例的方块图,方块图表明可以由推荐系统保持的各种类型的度量。度量可以包括用户-中心度量240、视频-中心度量242、及视频对-中心度量244。
用户-中心度量
就用户-中心度量240而论,推荐系统为每个用户保持用户日志。用户的用户日志指示哪些视频用户已经观看、或表现出兴趣。图2表明三个用户日志250、252及254。
根据一个实施例,除列出用户已经表现出兴趣的视频之外,用户日志也指示由用户动作指示的兴趣量、和指示何时表现出兴趣的时间戳。根据一个实施例,用户对视频表现出的兴趣量由“强度”值代表,该“强度”值与视频列表一起存储在用户日志中。
强度值可以由各种因素确定,如用户与视频具有的相互作用的类型而确定。例如,观看了视频的用户比仅仅浏览视频的用户对视频表现出更大兴趣。每种类型的相互作用内,强度值可能受其它因素影响。例如,给视频五星评价的用户比给视频三星评价的用户对视频具有更强烈的兴趣。作为另一个例子,观看整个视频的用户比仅仅观看视频的第一半的用户具有更强烈的兴趣。因而,“已观看视频的百分比”可以是确定用户的兴趣强度的因素。作为又一个例子,重复地观看视频的用户比观看视频一次的用户具有更强烈的兴趣。
视频-中心度量
推荐系统处理用户日志,并且对于为每个视频保持的视频-中心度量242进行对应更新。在图2表明的实施例中,推荐系统保持用于三个视频202、204及206的信息。对于每个视频,由推荐系统保持的信息包括用户清单,这些用户已经表现出对于视频的兴趣。视频202、204及206的“感兴趣用户清单”分别表明为清单222、224及226。在一个实施例中,这些清单包括条目、时间戳、及强度值,这些条目的每一个识别用户,这些强度值指示在由时间戳指示的时间、用户对视频表现出多么强烈的兴趣。
除感兴趣用户清单222、224及226之外,为视频的每一个保持视频元数据。为每个视频保持的视频元数据可以包括关于视频的任何数量和类型的信息,如持续时间、创建日期、标签、标题、关键字、语言等。常常是,用于给定视频的初始视频元数据由视频的生产者提供(例如,标题、演员、语言),或者从视频本身得出(例如,持续时间、编码格式)。然而,在一些出版环境中,用于视频的元数据可能相对于时间而变化或增加。例如,随着更多用户观看视频,用户标签可以添加到视频上。作为另一个例子,视频的观看数量和评价可能随着用户观看和评价视频而正连续地变化。在图2表明的实施例中,用于视频202、204及206的元数据分别表明为视频元数据232、234及236。
视频对-中心度量
视频对-中心度量244是与一对视频有关的度量。例如,图2表明对于视频对202和204的度量、对于视频对202和206的度量、及对于视频对204和206的度量。在图2表明的实施例中,对于每个视频对,度量包括cf度量和cbf度量。
一般地,对于视频对的cf度量是用来预测观看该对中的一个视频的用户也将观看该对中的另一个视频的可能性的度量。因而,cf度量262是用来预测观看视频202和204之一的用户也将观看视频202和204的另一个的可能性的度量。类似地,cf度量264是用来预测观看视频202和206之一的用户也将观看视频202和206的另一个的可能性的度量。最后,cf度量266是用来预测观看视频204和206之一的用户也将观看视频204和206的另一个的可能性的度量。
一个实施例中,对于每个视频对的cf度量至少包括:
·所有用户对于在视频对中的每个视频花费的总时间
·各个用户对于视频对花费的最小时间之和
·对于观看了该对中的两个视频的用户,在观看两个视频之间过去了多长时间
·用户的分布(将视频由一个人观看100次与视频由100个不同的人各自观看一次进行区分)
·观看视频对的每个用户观看的视频的分布(指示观看这个视频的用户是否往往会观看多个视频、或少量视频)
·该对的每个视频如何相对于其它视频而“可发现”(例如,将例如频繁地出现在相同页或列表上的视频与很少出现在相同页或列表上的视频区分开)。
对于视频对的cf度量可以从为该对中的每个视频保持的感兴趣用户清单得出。例如,所有用户对于在202/204视频对中的每个视频花费的总时间可以基于在清单222和224中的信息而确定。类似地,cf度量264可以从清单222和226得出。同样,cf度量266可以从清单224和226得出。
当视频对中的视频之一是目标视频,并且视频对中的另一个视频是比较视频时,对于视频对的cf度量可以被包括在用来产生ml分数的原始cf特征120中。具体地,为了确定将视频x推荐给特定用户将实现目的的程度,其中该特定用户已经表现出对于视频y的兴趣,对于视频x/y对的cf度量可以既馈送到cf分析器118,又馈送到机器学习引擎102。cf分析器118可能基于这些cf度量产生cf分数124。cf分数124可能馈送到机器学习引擎102,并且机器学习引擎102可能至少部分地基于这些cf度量确定将多大权重给予cf分数124。
除cf度量之外,对于每个视频对的视频对-中心度量包括cbf度量。视频对的cbf度量是一般指示在视频对中的视频的内容是多么相似的度量。例如,视频对的cbf度量可以指示视频共同有多少标签、视频共有哪些元数据(例如,演员、导演、关键字)等。在图2表明的实施例中,用于视频对202/204、202/206及204/206的cbf元数据分别表示成cbf度量272、274及276。
根据一个实施例,当视频对中的视频之一是目标视频,并且视频对中的另一个视频是比较视频时,对于视频对的cbf度量可以被包括在用来产生ml分数的原始cbf特征126中。具体地,为了确定视频x与用户已经表现出对其的兴趣的视频y相似的程度,对于视频x/y对的cbf度量可以既馈送到cbf分析器128,又馈送到机器学习引擎102。cbf分析器128可能基于这些cbf度量产生cbf分数130。cbf分数130可能馈送到机器学习引擎102,并且机器学习引擎102可能至少部分地基于这些cbf度量确定将多大权重给予cbf分数130。
行为数据的增量更新
对于尽可能准确的ml分数150,用来产生ml分数150的原始cf特征120应该尽可能是当前的。然而,视频观看人群越大,越难以保证用于全部候选视频的原始cf特征120保持一直是新的。
例如,假定视频收集库具有百万个视频资产,在任何给定时间,数万观众正在观看视频。这些条件下,观看行为信息的量可能是巨大的。更新行为数据的一种手段可能是实时地收集用户-中心度量,并且在每个周末,对于视频-中心度量242、和然后对于视频对-中心度量244进行批量更新。然而,这样一种手段可能导致由推荐系统使用比较陈旧的视频-中心度量242和视频对-中心度量244。
为了避免由推荐系统使用陈旧视频-中心度量242和视频对-中心度量244,提供技术来增量地保持视频-中心度量242和视频对-中心度量。根据一个实施例,推荐系统增量地将新用户行为数据折合到用户历史中,该用户历史按元组(tuple)形式(用户、视频、强度)概括全部历史观看行为。另外,推荐系统将新信息与旧信息区分开,并且只更新具有新用户活动的视频对的视频对-中心度量244。
具体地,在一个实施例中,对于特定视频的视频-中心cf度量仅响应对于特定视频的新兴趣表达而更新。类似地,对于特定视频对的视频对-中心度量,仅响应对于属于视频对的至少一个视频的新兴趣表达而更新。因为多个视频经历长时段,这些长时段期间没有用户表达兴趣,所以减少需要重新计算的视频-中心度量的百分比,由此降低为实时地保持视频-中心度量242和视频对-中心度量244一直为新所需要的处理。
视频元数据的增量更新
类似于cf度量,重要的是,每个视频的以及视频对的cbf度量保持一直是新的,因为这些度量对ml分数具有影响,这些ml分数用作选择待推荐的视频。为了按有效方式保持cbf度量一直是新的,推荐系统使用的基于内容的管线也增量地保持。例如,在一个实施例中,吸收到推荐系统中的新视频和关于视频的元数据一旦可得,视频就立即成为可推荐的。
在一个实施例中,实施基于内容的管线,从而只有当新视频和现有视频共享共同元数据时,才将新视频与新视频和现有视频比较。在一个实施例中,推荐保持(特征名称、特征值)对于(时间戳、视频、视频元数据)映射。这样的实施例中,基于内容的管线可以包括如下逻辑步骤:
·产生(特征名称、特征值)对于(时间戳、视频、视频元数据)映射,并且将新视频折合到全局表中
·对包含相同(特征名称、特征值)的视频进行分组
·为每组产生视频对。
·聚集视频对。为每个对计算成对距离。
当视频对中的视频之一是目标视频,并且视频对中的另一个视频是比较视频时,这个成对距离可以是馈送到机器学习引擎102的cbf分数。因为性能原因,推荐系统可以检查时间戳,并且将新视频与新视频、和新视频与旧视频(但不是旧视频与旧视频)相比较。
在一个实施例中,关于目标视频馈送到机器学习引擎102的原始cbf特征126反映对于该目标视频的当前视频-中心度量242、和对于包括该视频和比较视频的视频对的当前cbf度量。这在与任何给定视频相关联的视频元数据可相对于时间显著变化(例如,将新标签添加到视频上)的环境中特别重要。
如以上提到的那样,在一个实施例中,当视频对中的第二视频添加到收集库上时,对于该视频对的cbf度量被创建,并且仅响应在视频对中的任一视频的视频元数据的变化才更新。例如,假定在将视频204添加到收集库上时,视频202在视频收集库中存在。响应视频204添加到收集库上,基于对于视频202的视频元数据232和对于视频204的视频元数据234,可以初始创建对于视频对202/204的cbf度量272。
一旦产生,cbf度量272就保持不变,直到对于视频202或视频204的视频元数据被改变。这样一种变化(例如,标签被添加到视频对中的视频之一)触发对于对的cbf度量272的重新计算。由于每个视频可能属于多个视频对,所以对一个视频的视频元数据的更新可能触发对于多个视频对的cbf度量的重新计算。例如,对于视频202的视频元数据232的更新可能触发视频对202/204的cbf度量272的重新计算、和视频对202/206的cbf度量274的重新计算。
重新计算视频对的分数
尽管在图2未表明,每个视频对的视频对-中心度量244也可以包括预先计算cf分数和预先计算cbf分数。具体地,代之以在需要视频推荐时产生对于视频对的cf和cbf分数,这些分数可以在更新底层视频对度量时预先计算。因此,需要视频推荐时,预先计算分数可以简单地从存储中读出,并且馈送到机器学习引擎102。在推荐(询问)时和在电影信息更新时进行这种计算之间存在权衡。一般指导原理是利用它们的相对频率、以及如何尽可能不频繁地进行计算。
例如,视频对202/204的cf分数124基于cf度量262。cf度量262响应用户对视频202或视频204的兴趣的指示而更新。响应用户兴趣的指示,可以更新cf度量262,并且通过将更新的cf度量262馈送到cf分析器118中,可以对于视频对202/204产生cf分数124。当使用机器学习引擎102基于视频对202/204产生ml分数150时,这个预先计算cf分数然后可以简单地读取,而不是重新计算。
类似地,视频对202/204的cbf分数130基于cbf度量272。cbf度量272响应对于对视频202或视频204的视频元数据的更新而更新。响应这样的元数据更新,可以更新cbf度量272,并且通过将更新的cbf度量272馈送到cbf分析器128中,可以对于视频对202/204产生cbf分数130。当使用机器学习引擎102基于视频对202/204产生ml分数150时,这个预先计算cbf分数130然后可以简单地读取,而不是重新计算。
选择对其保持度量的视频对
理论上,对于收集库中的每两个视频组合可以保持视频对-中心度量244。对于收集库中的每个可能视频对,保持视频对-中心度量可能导致n×(n-1)不同组的视频对-中心度量,其中n是收集库中的视频数量。尽管对于小收集库容易实现保持多组的视频对-中心度量,但它对于极大收集库是不切实际的。
因此,根据实施例,在认为视频与给定视频足够相似之前,视频必须通过与给定视频的“配对试验”,以证明对于视频和给定视频的视频对保持视频对-中心度量是正确的。相对于特定视频通过配对试验的视频这里称作对于该特定视频的“配对视频组”。因而,在一个实施例中,对于任何给定视频对(视频x/视频y),如果且只有如果y在视频x的配对视频组中,才保持视频对-中心度量244。
配对试验例如可以是,视频必须共享如下特性的任一个:题材、演员、导演。这仅是实际上非限制类型的配对试验的一个例子,这些配对试验可以用来确定对于特定视频对是否保持视频对-中心度量。配对试验越严格,对其保持视频对-中心度量244的视频对越少,因此保持视频对-中心度量244的开销越低。
然而,如果配对试验太严格,那么推荐系统可能不能进行有用的一些推荐。例如,如果视频x不在视频y的配对视频组中,那么当视频y是比较视频,即使视频y的大多数观众实际上可能喜欢观看视频x,视频x也不可能由推荐系统推荐。
配对试验可以是任意复杂的。例如,试验可以具有诸如如下之类的规则:
·如果视频x具有n或更好的评价,那么自动地认为视频x满足与全部视频有关的配对试验。
·如果视频x具有小于n次观看、但大于m次观看的评价,那么认为视频x满足与共有如下之一的视频有关的配对试验:题材、演员、导演。
·如果视频x具有小于m次观看,那么认为视频x满足与相同题材的视频有关的配对试验。
这些规则中,视频的评价确定那些通过配对试验所必须满足的条件。然而,在可选择配对试验中,用于配对的作用条件可以基于其它因素而变化。
代之以使用配对试验来确定是否存储对于视频对的任何视频对-中心度量,配对试验可以用来确定对于视频对是否应该保持特定类型的视频对-中心度量。例如,对于在收集库中的所有视频对可以保持cf度量,而仅对于通过配对试验的视频对保持cbf度量。可选择地,对于在收集库中的所有视频对可以保持cbf度量,而仅对于通过配对试验的视频对保持cf度量。
在又一个实施例中,对于每种类型的视频对-中心度量可以有不同的配对试验。例如,如果视频对中的两个视频都具有超过一定阈值的评价,则推荐系统可以存储对于视频对的cf度量。同时,如果视频对共有至少一个显著特征(例如,试样、演员、导演),则推荐系统可以存储对于视频对的cbf度量。在这样的实施例中,对于一些视频对的视频对-中心度量244可以既包括cf度量,又包括cbf度量,对于其它视频对,可以只有cf度量或cbf度量,而不是两者。
基于配对视频组的视频到视频推荐
根据一个实施例,当给定视频到视频推荐时,推荐系统只对于用户对其已经表达兴趣的视频的配对视频组中的视频产生ml分数。例如,假定用户刚刚结束观看视频x。为了推荐用户观看的下个视频,机器学习引擎102对于视频x的配对视频组中的每个视频,产生ml分数150。
这个例子中,视频x的配对视频组中的每个视频的原始cf特征120可能包括对于视频对的cf度量,该视频对包括该视频和视频x。这些原始cf特征120可能馈送到cf分析器118,以产生cf分数124,该cf分数124预测视频x的观众可能对观看目标视频有多大兴趣。
类似地,原始cbf特征126可能包括对于视频对的cf度量,该视频对包括该视频和视频x。这些原始cbf特征126可能馈送到cbf分析器128,以产生cbf分数130,该cbf分数130预测视频x与目标视频多么相似。
如在图1表明的那样,原始特征120和126和其它输入112、与分数124和130一起馈送到机器学习引擎102,以使机器学习引擎102能够确定将多大权重给予分数124和130的每一个。基于确定权重,机器学习引擎102对于目标视频产生ml分数150。
在对视频x的配对视频组中的所有视频重复这个过程之后,对于该视频产生的ml分数被用作确定要推荐视频中的哪个的基础。
衰减因数
一般地,用户的最近动作比由用户在较远过去采取的动作更多地指示用户的当前兴趣。因此,产生cf分数124时,cf分析器118可以应用“衰减”因数,该“衰减”因数基于行为多近发生而调整给予用户行为度量的权重。
例如,为了产生cf分数124的目的,cf分析器118可以将指示用户观看视频对的两个视频的数据,在用户观看两个视频之后立即给予100%权重,一周后给予80%权重,两周后给予60%权重。用户行为的远近可以由用户日志中捕获的时间戳确定。
衰减因数越高,给予较旧行为的权重越低。相反,衰减因数越低,给予较旧行为的权重越高。高衰减因数的例子可能例如将100%权重给予当前行为,将10%权重给予一周旧的行为,对于多于两周旧的行为不给予权重。
改变cf分析器118使用的衰减因数影响由cf分析器118产生的cf分数124。例如,假定多个用户在两周前已经观看了特定视频对,但少量用户在上周观看了同一视频对。这些条件下,高衰减因数的使用可能导致低cf分数124,因为很小权重可能给予较旧观看信息。另一方面,低衰减因数的使用可能导致高cf分数124,因为旧使用信息可能具有对于cf分数124的显著影响。
不幸地,没有所有情形下都产生最佳结果的衰减因数。例如,对于来自高观看视频的发行者的视频使用高衰减因数可能产生cf分数124,这些cf分数124准确地预测观看在视频对中的一个视频的用户是否可能对观看在视频对中的另一个视频感兴趣。高衰减因数的使用可能对这样类型的视频是最佳的,因为最近观看活动的量足以产生准确预测。因此,旧行为数据可相应地打折。
另一方面,对于其视频较不频繁地被观看的发行者的视频,使用低衰减因数可能产生更准确的cf分数124。这样的情况下使用低衰减因数可能需要保证,cf分数124基于有用的足够行为数据。因而,在这个例子中,独立于衰减因数的输入参数(视频发行者)可以将如下指示给予机器学习引擎102:哪种衰减因数可能更适当地用在任何给定情形下。
代之以试图推测哪种衰减因数对于每个视频对可能产生最准确cf分数124,提供这样的实施例,对每个视频对将多个cf分数馈送到机器学习引擎102中,其中每个cf分数通过使用不同的衰减因数而产生。这样的实施例表明在图3。
参照图3,它表明推荐系统,该推荐系统中,机器学习引擎102被提供cf输入308,这些cf输入308包括三个不同cf分数324、326、328。cf分数324、326及328基于相同的原始cf特征120,但通过使用三个不同的衰减因数314、316及318而产生。基于在输入馈送306中的其它特征(如视频生产者),机器学习引擎102确定cf分数的哪个应该对ml分数150具有较大影响。
例如,如果原始cbf特征126指示在视频对中的视频是关于来自特定发行者的高度观看当前新闻事件,则机器学习引擎102可以将较大权重给予cf分数,该cf分数基于高衰减因数。另一方面,如果原始cbf特征126指示在视频对中的视频是来自另一个发行者的很少看到的经典电影,则机器学习引擎102可以将较大权重给予cf分数,该cf分数基于低衰减因数。
尽管在图3表明的实施例中,使用三个不同的衰减因数,但使用的衰减因数的实际数量可以随实施变化。例如,一个实施例对于任何给定视频对可以产生二十个cf分数,其中,二十个cf分数的每一个基于不同的衰减因数。如将在下面更详细解释的那样,这种技术不限于衰减因数,也可以供任何数量的其它参数使用。
机率-比值截止
当模型用来产生预测时,模型使用基于假设的某些“模型调谐参数”。以上讨论的衰减因数是这样一种模型调谐参数的例子。例如,使用衰减因数的模型-该衰减因数将给予动作的权重在一周之后减小50%,假定过去动作预测未来动作的能力在一周之后下降50%。
衰减因数仅是模型调谐参数的一个例子,这些模型调谐参数可以由模型使用,这些模型在cf和cbf分析器中实施。除衰减因数之外,由cf分析器采用的模型可以例如使用机率-比值截止阈值(odds-ratiocut-offthreshold),来减小当预测两个视频是否实际上彼此有关时,由高度流行视频引起的虚假-肯定(false-positives)的数量。
机率-比值截止可以用来解决如下问题:极流行视频可能由如此多的用户观看,从而这些用户观看除极流行视频之外的一些其它视频的事实,并不是其它视频与极流行视频有关的准确指示。为了避免预测极流行视频与它们对其无关的其它视频有关,由cf分析器118使用的模型可以通过计算两个视频独立同现在用户观看日志中的机率(而非依赖地同时出现),确定两个视频是否有关。如果两个视频独立同现的机率大于由模型使用的机率-比值截止(例如,50%),那么假定:两个视频实际上不是彼此有关的。
如关于衰减因数那样,模型使用的机率-比值截止(a)影响预测,和(b)所基于的假设不可能始终保持真实。例如,一些情况下,两个视频,即使统计学指示有55%的机会它们独立同现在用户日志中,也可能是高度相关的。这种情形下,使用60%机率-比值截止,可能已经使模型预测到所述视频事实上是相关的。
另一方面,两个视频,即使统计学指示有45%的机会它们独立同现在用户日志中,也可能是不相关的。这种情形下,使用40%机率-比值截止可能已经使模型预测到视频不相关。
标准化因数
标准化因数是可以由一些模型使用的模型调谐参数的另一个例子。标准化因数一般试图基于用户的整体观看行为将分数标准化。例如,用户a和b都观看了视频对(v1、v2)50分钟。然而,用户a只观看了视频v1和v2,而用户b观看了数百个其它视频。用户b具有关于视频对的较分散注意力。对于视频v1和v2的相关度来自用户a的赞同应该比来自用户b的赞同重要。这与web页排序中使用的pagerank是相同精神,这里,给予引出链路的权重部分取决于每个网页可能具有的引出链路的数量。
使用不同模型调谐参数的并行计算
因为模型对于模型调谐参数(例如,衰减因数、标准化因数、机率-比值截止等)使用的值所基于的假设并不是对于所有情形都真实,所以提供这样实施例,将不同模型调谐参数值组合的分数并行地馈送到机器学习引擎102。
例如,图3表明将三个cf分数324、326、328并行地馈送到机器学习引擎102,这三个cf分数324、326、328的每一个与不同的衰减因数值相关联。可选择实施例中,对于几个(衰减因数、标准化因数、机率-比值截止)值组合的每一个可产生一个cf分数。例如,实施例可以使用对于衰减因数(x、y、z)的三个不同值、和两个不同机率-比值截止阈值(a、b)。这样的实施例中,机器学习引擎102可并行地被提供六个cf分数,对于模型调谐参数值组合(x、a)、(x、b)、(y、a)、(y、b)、(z、a)、(z、b)的每种一个。
尽管这个例子中使用衰减因数和机率-比值截止阈值的模型调谐参数,但对于任何类型和数量的模型调谐参数,可以使用相同的并行-分数-产生技术。例如,特定cf分析器可以使用这样模型,该模型采用四个不同的模型调谐参数。对于每个模型调谐参数,可能有待试验的三个可行值。这样的实施例中,有模型调谐参数值的81种不同组合。因而,可以将81个cf分数(对于每种模型调谐参数值组合一个)并行地馈送到机器学习引擎102中。
如关于以上给出的衰减因数例子那样,在产生ml分数时,给予cf分数的每一个的权重至少部分地基于由机器学习引擎102接收的其它输入。如在图3指示的那样,这些其它输入包括原始cf特征120、原始cbf特征126、cbf分数130及任何数量的其它输入112。
灵活的对象函数
当用在视频到视频推荐的情形时,机器学习引擎102产生ml分数,这些ml分数预测用户给定他/她已经观看视频a(比较视频)而将观看视频b(目标视频)的概率。实际中,有发行者想优化实现的多个目标。目标的例子包括但不限于:
·增加总电影观看时间
·增加每个用户观看的视频数量
·增加用户花在观看每个(推荐)视频上的总分钟
·增加来自每次视频观看的广告收入
·增大影响范围
·增加每部电影的收入
为了解决这种挑战,提供这样实施例,其中预测被初始地反映在几个不同的子分量中。分量可以包括例如:
·p(b|a)-用户给定他/她观看了a而可能喜欢观看b的概率
·r(b)-来自b的每次观看的期望收入(*未来工作)
·p(ad|u,b)-观看b的用户u将点击广告的概率
使用机器学习引擎产生这些分量的每一个的分数之后,分量分数然后可以基于特定组的目标而组合,以产生合成ml分数,该合成ml分数用作选择要推荐哪些候选视频的基础。
图4是机器学习引擎402的方块图,该机器学习引擎402已经训练成产生ml分量分数404、406及408,这些ml分量分数404、406及408由基于目标的分量组合器410组合,以基于规定目标430产生合成ml分数440。这个例子中,ml分量分数404、406及408可以与以上描述的目标函数p(b|a)、r(b)、及p(ad|u,b)相对应。当产生合成ml分数440时,由基于目标的分量组合器410给予各个分量分数的权重是基于馈送到基于目标的分量组合器410的目标信息430。
例如,假定目标430指示用户约定显著地比收入重要,并且收入稍微比广告重要。基于这样的目标信息430,基于目标的组合器410可以将分量分数404、406及408分别按0.6、0.25及0.15加权。
尽管机器学习引擎402表明成单个引擎,机器学习引擎402可以实施成三个不同引擎,这三个不同引擎的每一个训练成产生不同的ml分量分数。分量分数的实际数量、和基于目标的分量组合器410当产生合成ml分数440时如何将权重赋予这些分数,可以随实施而变化。例如,单个推荐系统可以产生数十个ml分量分数,这些ml分量分数的每一个反映基于不同目标函数的预测。基于目标的分量组合器410可以基于目标信息430按各种方式组合这些ml分量分数。
在一个实施例中,基于目标的分量组合器410被提供多组目标,并因此产生多个合成ml分数。这样的实施例中,每个视频对组合可能具有多个合成ml分数,并且为确定是否推荐视频而使用的实际ml分数可能基于给出推荐时有效的目标。
在分量分数之间交替
为了给出满足某组目的的推荐,可以将分量分数组合成合成ml分数440,该合成ml分数440用作确定要推荐哪些候选视频的基础。在可选择实施例中,不产生合成ml分数440。代之以,当给出推荐时,推荐系统在分量分数中的哪些要用作基础之间交替,所述基础用来确定待推荐的视频。
例如,代之以通过将ml分量分数404、406及408分别给予0.6、0.25及0.15的权重而产生合成ml分数440,推荐系统可以在60%的时间给出基于ml分量分数404的、在25%的时间给出基于ml分量分数406、及在15%的时间给出基于ml分量分数408的推荐。如关于产生合成ml分数440的实施例那样,在ml分量分数之间交替的实施例基于正给出推荐时有效的目标这样做。
根据一个实施例,在ml分量分数之间交替的模式不必是均匀的。例如,推荐系统可以在用户-中心基础上进行交替,其中初始向用户提供基于ml分量分数的推荐,该ml分量分数预测用户约定。只有在向用户已经呈现几个推荐之后,这几个推荐聚焦在用户约定上,推荐系统才可能开始提供基于其它目标函数(如收入最大化)的一些推荐。如果当呈现收入最大化推荐时的用户行为指示,用户约定已经降落在特定阈值下面,则推荐系统可以切换回提供基本上或仅基于与用户约定有关的分量分数的推荐。
有限度探查
根据一个实施例,随着向用户推荐视频,捕获用户行为,并且该用户行为用来更新由推荐系统使用的元数据,如以上描述的那样。然而,只要向用户始终呈现“最佳”视频推荐(例如,具有最高ml分数的视频),就不能收集关于用户如何对“非最佳”推荐反应的行为数据。在不收集关于对非最佳推荐的用户反应的信息的情况下,当未被推荐的视频应该被推荐时,推荐系统将难以校正自身。
例如,假定视频a对于视频b的观众可能是很有兴趣的。然而,在没有对于视频a的任何观看历史的情况下,机器学习引擎102对于视频对a和b产生低ml分数。由于低ml分数,视频a可能不推荐给视频b的观众,所以视频b的很少观众可能观看视频a。因此,对于视频对a和b的ml分数可能保持很低。
为了避免这样的问题,定期地将非最佳推荐呈现给用户,对于非最佳推荐可以收集行为数据。呈现非最佳推荐称作“探查”,因为它向用户呈现在视频组外的推荐,该视频组通常可能向用户呈现。然而,太多探查、或在错误情况下的探查可能将用户体验降级到不可接受的程度。
因此,根据一个实施例,推荐系统对探查施加约束条件。具体地,探查按如下方式进行:有限度探查对视频推荐目标具有的不利影响。例如,推荐系统可以定期地将视频的选择随机化以推荐给用户。然而,可以约束随机选择,其中从进行随机选择的池中排除那些不利影响预计在一定阈值以上的任何视频。
例如,在探查期间,进行随机选择的视频池可能只包括这样的视频,这些视频相对于比较视频具有高于某一阈值x的cf分数、或高于某一阈值y的cbf分数、或高于某一阈值z的ml分数。置于视频选择池上的专门约束规则可能是任意复杂的。例如,如果(对于任何衰减因数的cf分数>x)或者(ml分量分数的任一个>y)并且(合成ml分数>z),则视频可能具有进入选择池的资格。
根据一个实施例,多臂老虎机(multi-armedbandit)技术由视频推荐用来学习在探查选择过程中的每个变量对当前目标的实现具有的影响,并且调整预测具有最小不利影响的变量。例如,关于ε-贪婪策略(epsilon-greedystrategy),对于尝试的比例1-ε选择由ml系统(最好杠杆)推荐的视频,并且对于比例ε选择(以均匀概率)属于其它池(高于某一阈值的随机、趋势cbf分数)的视频。典型参数值可能是ε=0.1,但这可依据环境和偏好大大地变化。
运行时间性能增强
当使用这里描述的技术提供视频推荐时,可以使用各种运行时间性能增强。例如,一些实施例当将用户点击数据(非常小)与特征(比较庞大)联合以产生到机器学习系统的训练输入时,可以使用bloom过滤器。具体地,在一个实施例中,使用用户点击数据建立bloom过滤器,并且过滤器用来滤除全部不相关的cf和cbf特征,这些不相关的cf和cbf特征没有与它们相关联的点击数据。这对于诸如hadoop之类的数据处理系统特别有用,在这些数据处理系统中,对于各种表不建立索引。
视频推荐系统可以使用的另一种运行时间增强涉及非对称联合。具体地,当联合cbf特征和cf特征时,非对称联合可以利用如下事实:对于新内容,存在有限的行为数据。在一个实施例中,将特征依据它们产生的时间组织在不同的存储桶中。推荐系统只将cbf特征与在最后几个小时产生的cf特征相联合。这显著地减小为机器学习系统产生训练和试验数据所需要的时间。
硬件概要
根据一个实施例,这里描述的技术由一个或多个专用计算装置实施。专用计算装置可以硬-连线以执行各技术;或者可以包括数字电子装置,如一个或多个应用程序-专门集成电路(asic)或现场可编程门阵列(fpga),这些数字电子装置不变地编程以执行各技术;或者可以包括一个或多个通用硬件处理器,这些通用硬件处理器编程成,按照在固件、存储器、其它存储装置、或组合中的程序指令执行各技术。这样的专用计算装置也可以将定制硬-连线逻辑装置、asic或fpga与定制编程组合以完成各技术。专用计算装置可以是台式计算机系统、可携带计算机系统、手持装置、联网装置或任何其它装置,该其它装置包括硬-连线和/或程序逻辑装置以实施各技术。
例如,图5是方块图,方块图表明计算机系统500,在该计算机系统500上可以实施本发明的实施例。计算机系统500包括用来通信信息的总线502或其它通信机构、和硬件处理器504,该硬件处理器504与总线502相联接用来处理信息。硬件处理器504可以是例如通用微处理器。
计算机系统500也包括主存储器506,如随机存取存储器(ram)或其它动态存储装置,该主存储器506联接到总线502上,用来存储信息和待由处理器504执行的指令。主存储器506也可以在待由处理器504执行的指令的执行期间,用来存储临时变量或其它中间信息。这样的指令当存储在对于处理器504可访问的非暂时存储介质中时使计算机系统500变成专用机器,该专用机器定制成,执行在指令中规定的操作。
计算机系统500还包括只读存储器(rom)508或其它静态存储装置,该只读存储器(rom)508或其它静态存储装置联接到总线502上,用来存储用于处理器504的静态信息和指令。提供诸如磁盘或光盘之类的存储装置510,并且联接到总线502上用来存储信息和指令。
计算机系统500可以经总线502联接到显示器512上,如联接到阴极射线管(crt)上,用来向计算机用户显示信息。包括字母数字和其它键的输入装置514联接到总线502上,用来将信息和命令选择通信到处理器504。另一种类型的用户输入装置是光标控制装置516,如鼠标、跟踪球、或光标方向键,用来将方向信息和命令选择通信到处理器504,并且用来控制在显示器512上的光标运动。这种输入装置典型地在两根轴-第一轴(例如x)和第二轴(例如y),中具有两个自由度,这允许装置指定在平面中的位置。
计算机系统500可以使用定制硬-连线逻辑装置、一个或多个asic或fpga、固件及/或程序逻辑装置实施这里描述的技术,该程序逻辑装置与计算机系统相组合使计算机系统500是或将其编程为专用机器。根据一个实施例,这里的技术由计算机系统500响应处理器504而执行,该处理器504执行在主存储器506中包含的一个或多个指令的一个或多个序列。这样的指令可以从另一种存储介质,如存储装置510,读取到主存储器506中。在主存储器506中包含的指令序列的执行使处理器504执行在这里描述的过程步骤。在可选择实施例中,硬-连线电路可以用来代替软件指令或者与它们组合。
这里所使用的术语“存储介质”是指任何非暂时介质,这些非暂时介质存储数据和/或指令,这些数据和/或指令使机器按特定方式操作。这样的存储介质可以包括非易失介质和/或易失介质。非易失介质包括例如光盘或磁盘,如存储装置510。易失介质包括动态存储器,如主存储器506。普通形式的存储介质包括例如软盘、柔性盘、硬盘、固态驱动器、磁带、或任何其它磁性数据存储介质、cd-rom、任何其它光学数据存储介质、具有孔的模式的任何物理介质、ram、prom、及eprom、flash-eprom、nvram、任何其它存储器芯片或盒。
存储介质与传输介质不同,但可以与传输介质一起使用。传输介质参与在存储介质之间传送信息。例如,传输介质包括同轴电缆、铜导线及光学纤维,包括导线,这些导线包括总线502。传输介质也可采取声波或光波的形式,如在无线电波和红外数据通信期间产生的那些波。
为了执行将一个或多个指令的一个或多个序列传送到处理器504时,可能涉及各种形式的介质。例如,指令可能初始携带在远程计算机的磁盘或固态驱动器上。远程计算机可将指令加载到其动态存储器中,并且使用调制解调器在电话线上发送指令。计算机系统500的本地调制解调器可在电话线上接收数据,并且使用红外收发器将数据转化成红外信号。红外检测器可接收在红外信号中携带的数据,并且适当电路可将数据放置在总线502上。总线502将数据传送到主存储器506,处理器504从该主存储器506中检索指令并且执行指令。主存储器506接收的指令可以在由处理器504的执行之前或之后选择性地存储在存储装置510上。
计算机系统500也包括联接到总线502上的通信接口518。通信接口518提供联接到网络链路520上的双向数据通信,该网络链路520连接到本地网络522上。例如,通信接口518可以是集成服务数字网络(isdn)卡、有线调制解调器、卫星调制解调器、或将数据通信连接提供给对应类型的电话线的调制解调器。作为另一个例子,通信接口518可以是将数据通信连接提供给兼容lan的局域网(lan)卡。也可以实施无线链路。在任何这样的实施中,通信接口518发送和接收电信号、电磁信号或光学信号,这些信号携带数字数据流,这些数字数据流代表各种类型的信息。
网络链路520典型地提供通过一个或多个网络到其它数据装置的数据通信。例如,网络链路520可以提供通过本地网络522到主计算机524、或到数据设备的连接,该数据设备由互联网服务提供商(isp)526操作。isp526又提供通过全世界包数据通信网络的数据通信服务,该全世界包数据通信网络现在通常称作“互联网”528。本地网络522和互联网528两者都使用携带数字数据流的电信号、电磁信号或光学信号。通过网络的信号和在网络链路520上并通过通信接口518的信号是传输介质的示范形式,这些信号将数字数据传送到计算机系统500并且从其传送数字数据。
计算机系统500可通过网络(一个或多个)、网络链路520及通信接口518发送消息和接收数据,包括程序代码。在互联网例子中,服务器530可能通过互联网528、isp526、本地网络522及通信接口518传输对于应用程序的要求代码。
接收代码随着它被接收、和/或存储在存储装置510、或用于以后执行的其它非易失存储装置中,可以由处理器504执行。
以上说明书中,参照随实施可能变化的多个具体细节,已经描述了本发明的实施例。说明书和附图相应地要按说明性而不是限制性意义对待。本发明的范围、和由本申请人打算是本发明的范围的内容的唯一和排它指示是权利要求组的文字和等效范围,该范围从本申请按这样的权利要求发布的具体形式而发布,包括任何以后校正。
- 还没有人留言评论。精彩留言会获得点赞!